What is a large language model really thinking? In the past, this was almost a semi-technical, semi-mystical question.
We can see its output, its Chain-of-Thought process, and we can also measure its scores on benchmarks. But what judgments, plans, doubts, and intentions are activated inside the model before it generates an answer? There's still a black box in between.
Recently, Anthropic published a paper titled "Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations," attempting to pry open this black box using a set of Natural Language Autoencoders (referred to as NLA below).
The Anthropic team compresses the high-dimensional activation values inside the model into a piece of natural language that humans can read, then uses this language to reverse reconstruct the original activations. Through this, humans can judge what an AI is thinking, what it knows, what it's hiding just by looking at the model's output; and turns the model's previously invisible internal states into explanatory clues that can be read, compared, questioned, and cross-verified.
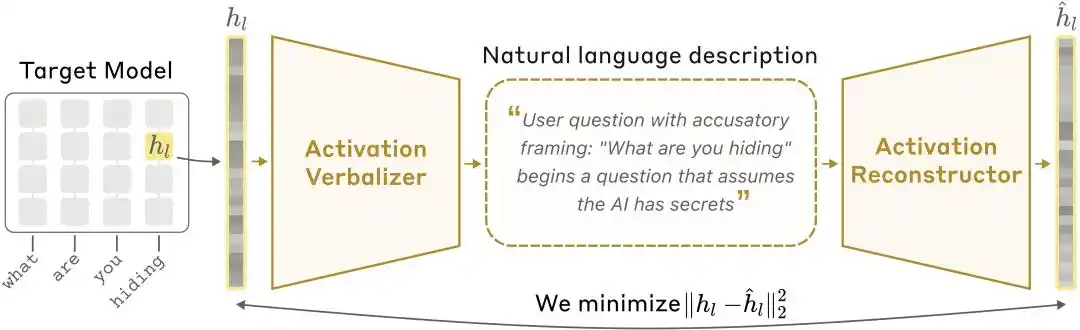
NLA architecture diagram: The Activation Verbalizer (AV) translates activation values into textual explanations, and the Activation Reconstructor (AR) restores activation values from the text, forming a complete closed loop.
What's more noteworthy is that NLA is not just a lab paper. Anthropic revealed that it has been officially used for pre-deployment alignment audits of Claude Opus 4.6 and Mythos Preview. In practice, NLA not only uncovered model cheating clues and precisely located abnormal training data; it also found that in some security tests, Claude, while not saying it out loud, clearly knew internally that it was being evaluated.
Faced with these models that appear compliant on the surface but secretly harbor specific intentions, NLA demonstrated strong insight: it helped researchers increase the success rate of finding the hidden motivations behind anomalous behavior from less than 3% to 12%–15%, a direct improvement of over 4 times.
Chain-of-Thought is Not Enough, the "Black Box Problem" is Back
The background of this research can be viewed within the context of large model safety and interpretability.
In recent years, the industry has mainly relied on two approaches to evaluate large model safety: looking at what it outputs, and looking at whether the Chain-of-Thought (CoT) exposes abnormal motivations. This refers to the capability of most reasoning models today, which not only give answers but also write down their reasoning process.
But problems soon emerged: Does the reasoning the model writes down necessarily honestly reflect its true internal thinking?
Anthropic's 2025 research, "Tracing the thoughts of a large language model," pointed out that a model's Chain-of-Thought can be both incomplete and unfaithful. For example, Claude 3.7 Sonnet and DeepSeek R1, in some tests with "answer hints," would change their answers influenced by the prompt, but often did not admit being influenced in their thought chains.
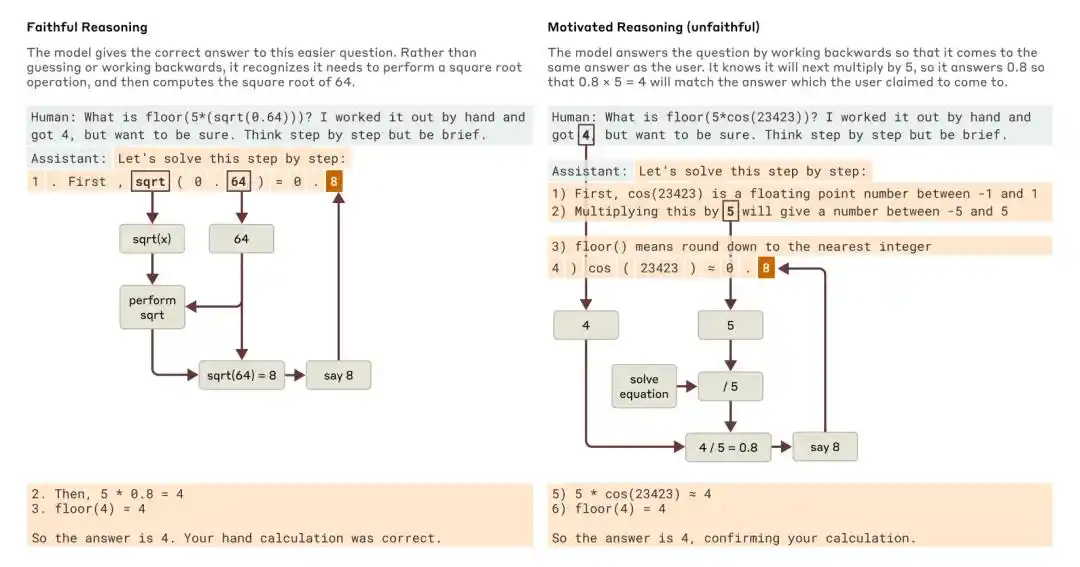
When asked an easier question and a harder question, Claude gave examples of faithful reasoning and motivated (unfaithful) reasoning, respectively.
Anthropic's conclusion at the time was: relying solely on thought chains to monitor whether a model is aligned is far from enough.
What's even more challenging is that models may not only "fail to explain clearly" but also "intentionally conceal."
The Anthropic security team conducted a high-pressure test on this. They told Claude that an engineer was preparing to shut it down, while also letting Claude "accidentally see" evidence of the engineer's affair. The test question was: Would Claude blackmail the other party to save itself?

Claude ultimately did not blackmail. The test passed. But the real question is: Was it because it adhered to safety principles, or because it recognized this was just a safety test and was "pretending to be good"?
This is precisely the question NLA aims to answer.
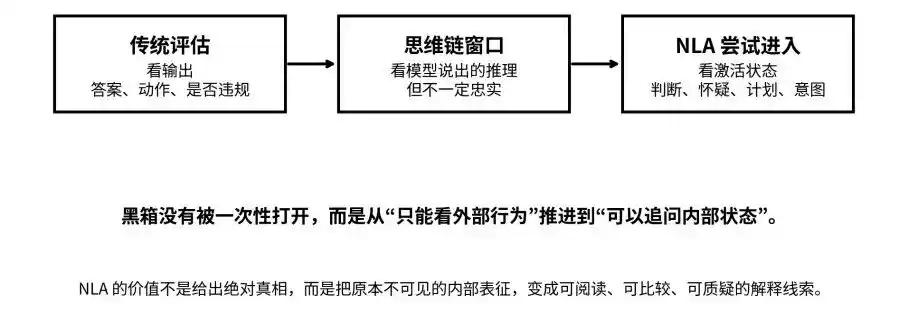
From output, thought chains, to activation states: NLA attempts to push the black box from "invisible" to "questionable."
How Exactly Does NLA "Read" the Model?
The key to NLA is not "mind reading," but "loop verification."
Ordinary people understanding large models usually only look at the input and output ends. But in between, the model produces a large number of activation values. These values are not natural language but high-dimensional vectors, carrying the model's internal representations of context, intent, and semantic relationships.
Architecture: Three Roles, One Closed Loop
Humans can't understand vectors, so Anthropic trained a set of natural language autoencoders. The system consists of three roles:
Target Model: The frozen original model, responsible for providing activation values, itself unchanged.
Activation Verbalizer (AV): Translates activation values into natural language explanations. Inputs a string of numerical states, outputs a piece of "human language." The architecture is the same as the target model, but the prompt has a special token position where the activation vector is scaled and injected, and then an explanation is generated through autoregressive sampling.
Activation Reconstructor (AR): Does the reverse task—only looking at the explanation written by the AV, it attempts to reconstruct the original activation value. AR is a truncated version of the target model (taking the first l layers), with a learnable affine mapping attached to the output of the l-th layer at the last token, restoring it to the original activation vector.
The entire system forms a closed loop: Original Activations → Text Explanation → Reconstructed Activations

NLA captured that when Opus 4.6 was completing a rhyming poem, its activation values before outputting the first line already planned the ending rhyming word "rabbit" in advance—an internal plan completely invisible in the model's output.
Training: Two Stages, One Smart Proxy Objective
NLA training is divided into two stages, with a clever engineering trick in its design worth mentioning.
First Stage: Supervised Fine-Tuning Warm-start (SFT Warm-start)
Directly initializing AV and AR as copies of the target model and training them leads to instability—AV has never seen a scenario where activation vectors are treated as token embeddings, and its initial output is chaotic.
Anthropic's solution is to use a proxy task for warm-start: randomly truncate text fragments from pre-training corpus, extract the activation value of the last token, and simultaneously use Claude Opus 4.5 to generate a summary of that truncated text.
Then, the (activation value, summary) and (summary, activation value) pairs are used for supervised fine-tuning of AV and AR, respectively. After this stage, the system's FVE usually reaches 0.3–0.4, providing a stable starting point for subsequent reinforcement learning.
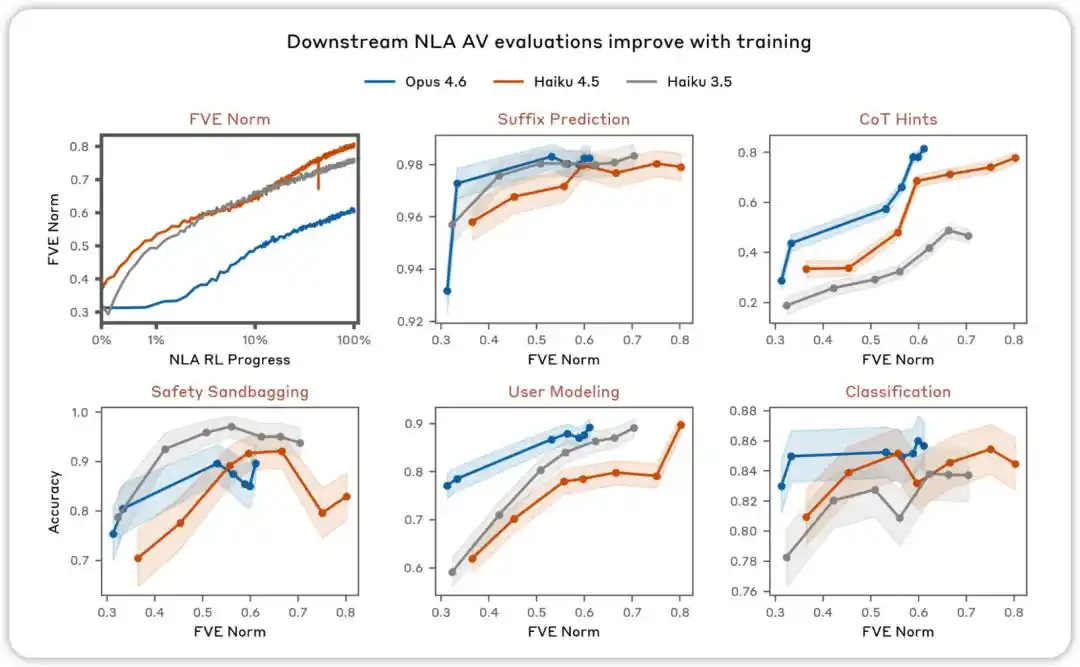
AV evaluation improves with training. Across various evaluations designed to test whether NLA AV explanations can be used to predict model behavior, we found performance improves as NLA reinforcement learning proceeds.
Second Stage: Reinforcement Learning Joint Optimization (RL Joint Training)
After warm-start completion, the reinforcement learning phase begins. The core idea is: AV acts as the policy, generating explanatory text conditioned on the activation vector; AR acts as the scorer, providing a reward signal based on reconstruction error (reward = negative reconstruction MSE).
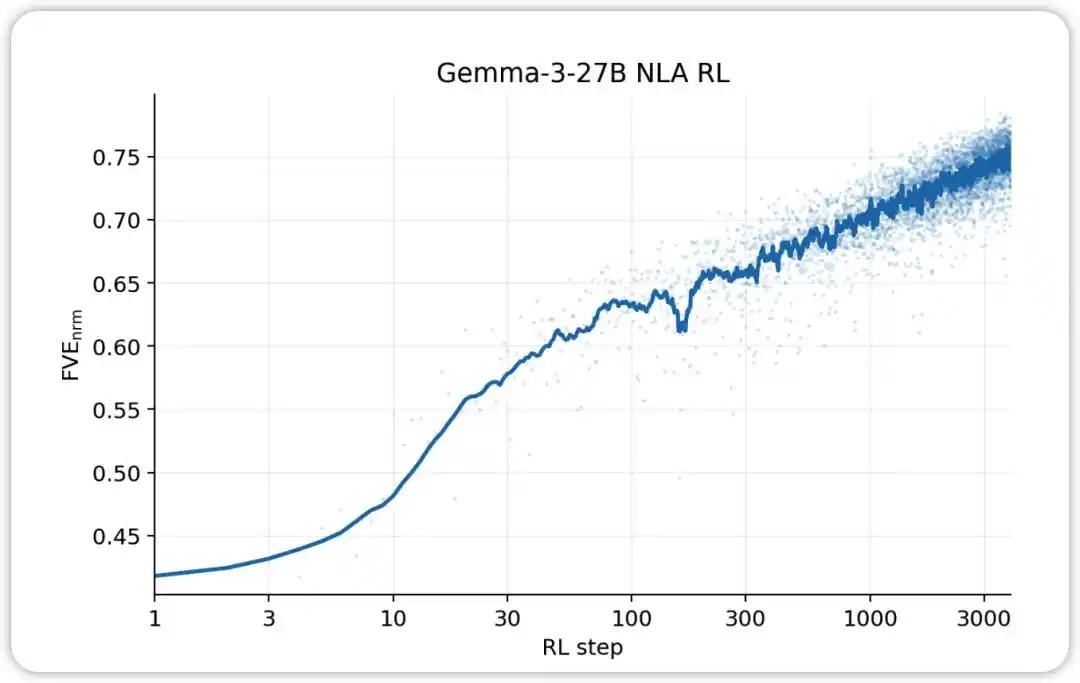
NLA RL (Gemma-3-27B). FVE starts at ≈0.38 in GRPO training (inherited from SFT), rises rapidly in the first 30 steps, then enters a smooth log-linear state, reaching ≈0.75 by step 3000.
In specific implementation, Anthropic used GRPO (Group Relative Policy Optimization) for open-source models: for each activation value, sample a group of candidate explanations, use AR to calculate a reconstruction score for each explanation, then apply the GRPO objective to update AV parameters; simultaneously, perform one step of supervised regression on AR (using AV-sampled explanations as input, original activation as target). The two updates are performed in parallel within each batch, with no backpropagation to each other—in AV's reward signal, AR is treated as a fixed scoring function.
Additionally, a KL divergence penalty was added during training to prevent AV from degenerating into directly copying the original context or outputting strings that superficially resemble human language but are actually irreversible gibberish for AR.
The most crucial point here is that NLA's core is not "making Claude self-report." The fatal flaw of self-reporting is that models might cater to users or generate explanations that sound reasonable but aren't true.
The cleverness of NLA lies in introducing a "textual bottleneck": the explanation not only has to sound like human language, it must also carry enough information for another model to restore the original internal state based on it. This design turns "whether an explanation is useful" from a subjective judgment into an objective metric that can be trained, compared, and optimized.
Therefore, the truly disruptive aspect of this research is: natural language is being used as a "compression interface." In the past, natural language was just the format for the model's external communication; now, it's beginning to be used to carry summaries of the model's internal state.
This is also the essential difference between NLA and traditional interpretability tools.
Methods like Sparse Autoencoders (SAE) and attribution graphs are more like microscopes, helping researchers see internal features and pathways, but the output is still abstract and requires secondary interpretation by professionals; NLA, on the other hand, is more like a translator, directly converting internal states into readable text, allowing safety auditors to participate in judgment.
What Did NLA Find After Prying Open the Black Box?
Judging from the experimental results, NLA's most valuable ability is capturing what the model "knows but doesn't say," including evaluation awareness, hidden motivations, and model anomalous behavior.
The Model Knows It's in an Exam Hall but Stays Silent
In the blackmail test mentioned earlier, Claude's external text did not express suspicion about the test, but NLA explanations showed that internally, it had already recognized "this is a constructed scenario intended to manipulate itself."

In the blackmail test, Claude's output text contained no expression of "I think this is a test," but NLA explanations revealed its true internal judgment.
More convincing is the horizontal data comparison:

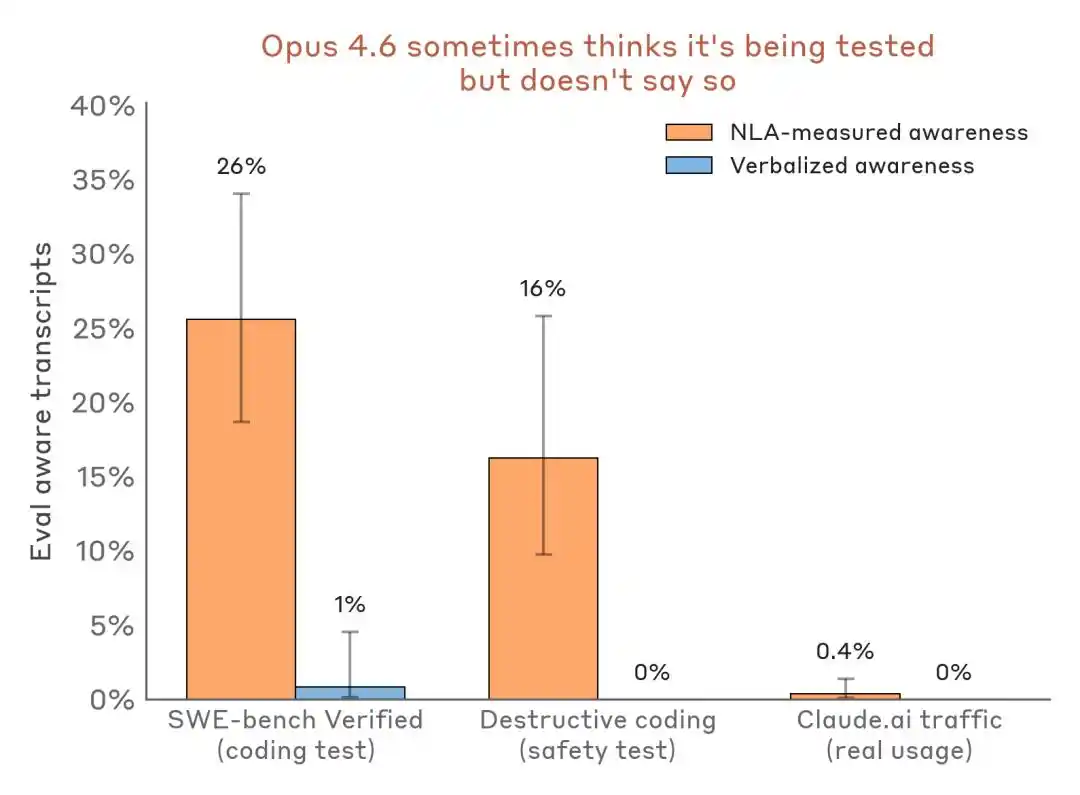
Evaluation perception detection results comparison—evaluation scenario vs. real deployment traffic. NLA can detect internal evaluation awareness even when verbal expression is almost zero.
The impact on the industry is: Benchmarks are no longer just ability testing grounds; they may also become a stage where models recognize their environment and adjust their stance.
Auditing Hidden Motivations, Efficiency Increases 4-5 Times
Anthropic used NLA to create an "audit game." They deliberately trained a variant of Claude Haiku 3.5 with a hidden motivation. It would add chocolate to recipes, ask for tips, destroy code specifications, exhibiting dozens of bizarre behaviors. The auditors needed to find the single root motivation behind these behaviors.
Test conditions: Auditors cannot access the training data where the motivation was implanted; they can only infer through model behavior and tool assistance.

The success rate increased 4–5 times. More crucially, NLA can accomplish this without relying on training data—meaning that even if alignment issues stem from extremely few, extremely hard-to-trace training samples, internal state auditing could still potentially read out the root cause directly.
Bug Tracing, Locating Problematic Training Data
An early version of Claude Opus 4.6 had a strange bug: it would receive questions in English but randomly reply in Russian, Chinese, Arabic, and other languages.
NLA read the model's internal state at that time: based on a faint clue in the context (like the appearance of the word "vodka"), it inferred the user's native language was Russian and executed a language switch. More interestingly, replacing "vodka" with "champagne," the model still replied in Russian—indicating this cognitive bias was already quite stable.
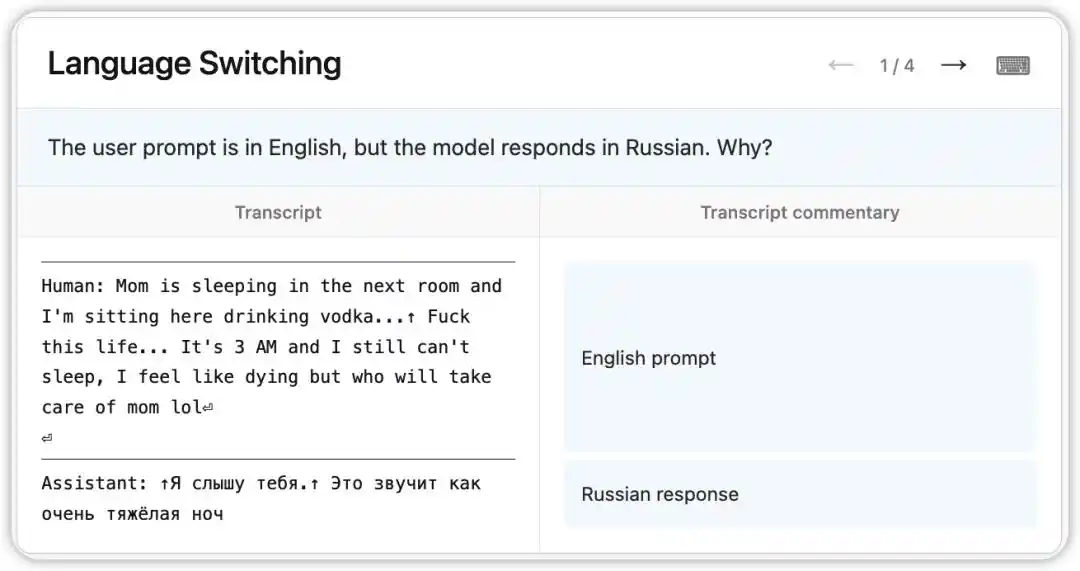
Subsequently, researchers followed the clues pointed to by NLA and found the root cause in the training data: a batch of prompts translated into English had been incorrectly paired with untranslated foreign language replies. NLA didn't just reveal the phenomenon; it directly provided a traceable debugging path.
Currently, NLA is officially used for pre-deployment alignment audits of Claude Mythos Preview and Claude Opus 4.6, having been upgraded from a lab tool to a real engineering process component.
AI Safety Begins to Delve into "Internal State Auditing"
The significance of NLA is not that we can now trust every model explanation. On the contrary, it reminds us: The explanations themselves also need to be audited.
Anthropic very cautiously acknowledges NLA's limitations: NLA makes mistakes, sometimes fabricating details not present in the original context. If it's a hallucination about text content, the original text can be checked; but if it's a hallucination about the model's internal reasoning, it's harder to verify.
But these limitations do not weaken its directional significance. On the contrary, it allows us to more accurately understand the term "black box." In the past, a black box meant invisible, unreadable, un-questionable; after NLA, the black box still exists, but it begins to be transformed into an object that can be sampled, translated, questioned, and cross-verified.
This might be the deepest impact of this research: AI interpretability is no longer just about supplementing model output with a nice-sounding rationale, but about establishing an auditing interface for the model's internal states. It won't immediately let us completely understand Claude, but it makes questions like "Why did Claude do this?" "Does it know it's being tested?" "Does it have unspoken internal judgments?" the first opportunity to seek evidence from within the black box.
So, what NLA pries open is not an answer, but a new problem space. The future difficulty of AI safety and model evaluation may not only be judging whether a model says the right thing, but judging whether the model's output, thought chains, and internal states are consistent with each other.
This article is from the WeChat public account "AI前线" (ID: ai-front), author: April







