Author: Yanhua
Antonio Gullí is an Engineering Director at Google. He wrote a 453-page book, breaking down AI Agent development into 21 design patterns.
But this is not a book review. My motivation for reading this book was specific: I've written about Harness Engineering, shared my experience with pitfalls in Clawdbot, and written "AI Agents Are Not Magic" about the seven turning points from burning tokens to becoming truly usable. After each piece, there remained an unanswered question: Is there an underlying, reusable logic behind all these things?
This book gave me an answer, and it went deeper than I expected.
What You're Writing Might Not Be an Agent At All
The most incisive judgment in the book is hidden in the prologue.
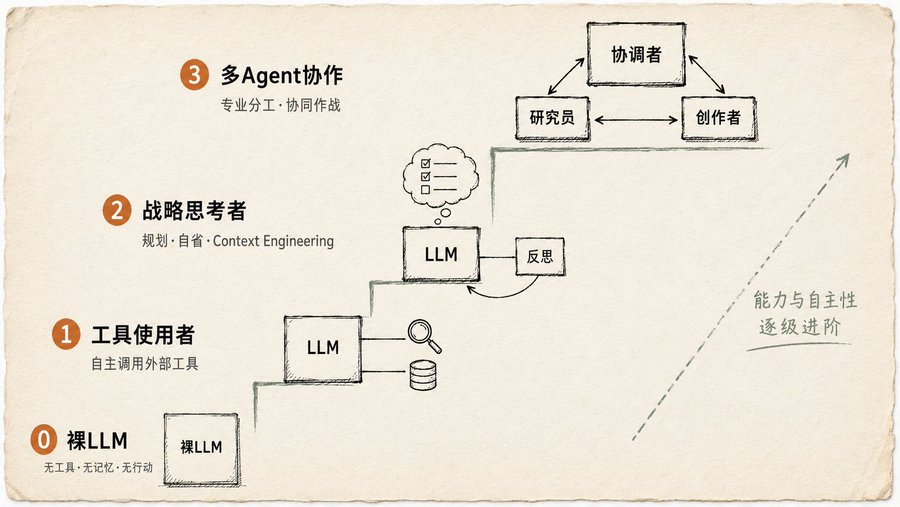
The "AI" most people are using is just Level 0: a bare LLM, with no tools, no memory, and no ability to act. You ask it which film won Best Picture at the 2025 Oscars, and it guesses. The book is blunt: Level 0 stuff is not an Agent.
Only the higher levels are true Agents:
-
Level 1: Tool User
The Agent starts using tools: search, APIs, databases. But it's not just "able to call an interface"; it must decide *when* to call, *what* to call, and *how* to use the result. The book gives a concrete example: a user asks "What are some new TV shows?" The Agent realizes on its own that this information isn't in its training data, actively calls a search tool to find it, then synthesizes the results. The key step is "realizing on its own." It's not a human telling it "go search for this"; it judges *for itself* that a search is needed. This judgment ability is the threshold for Level 1.
-
Level 2: Strategic Thinker
Adds two more things: Planning and Context Engineering. The book defines Context Engineering: it's not about dumping information, but about carefully selecting, trimming, and packaging context. A great example: a user wants to find a coffee shop between two locations. The Agent first calls a mapping tool to get a bunch of data, then judges that "only street names are needed for the next step," trims the map output into a short list, and feeds it to a local search tool. Every step is about reducing information noise.
There's a sentence in the book I read several times: "To achieve the highest accuracy from AI, you must give it short, focused, and powerful context." Context Engineering is exactly about doing this.
At this level, the Agent can also self-reflect. It reviews its own work after finishing, identifies issues, and makes corrections itself. I'll talk about this in more detail later.
-
Level 3: Multi-Agent Collaboration
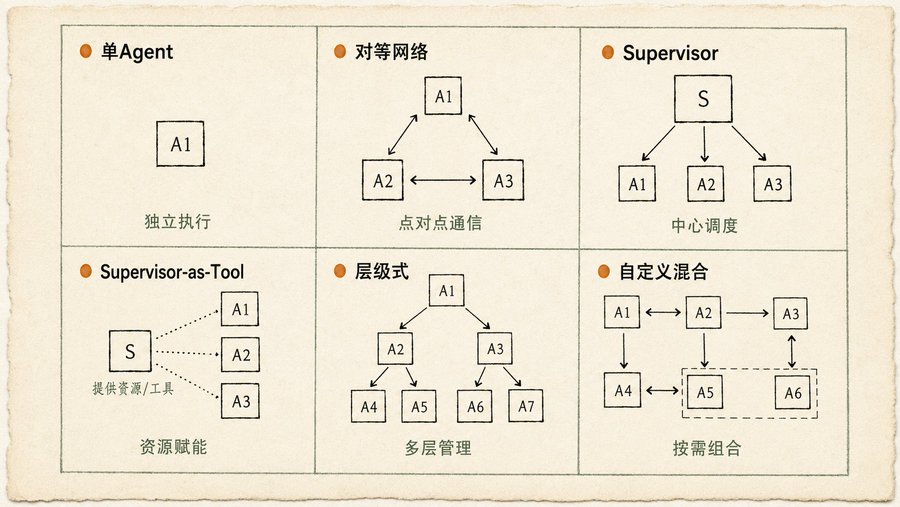
The book's stance is clear: stop trying to build one all-powerful super agent. The reliable approach is to build a team: a Project Manager Agent + a Researcher Agent + a Designer Agent + a Copywriter Agent. The example given is for a new product launch: a "Project Manager Agent" coordinates overall, assigning tasks to "Market Research Agent," "Product Design Agent," and "Marketing Agent." The key is communication: how Agents pass data, synchronize state, and handle conflicts. This chapter diagrams six communication topologies, from the simplest single Agent to the most flexible custom hybrids, with explanations for each scenario.
After reading these four levels, I suddenly understood why many people say "my Agent doesn't work well." The model isn't the problem; the problem is you're using it like a chatbot, and it might not even be at Level 1.
Context Engineering: The Book's Most Underrated Concept
I wrote an article about Harness Engineering, discussing how the design of the racetrack is more important than the engine's horsepower. After reading this book, I realized that Context Engineering is the mapping of Harness Engineering at the prompt level.
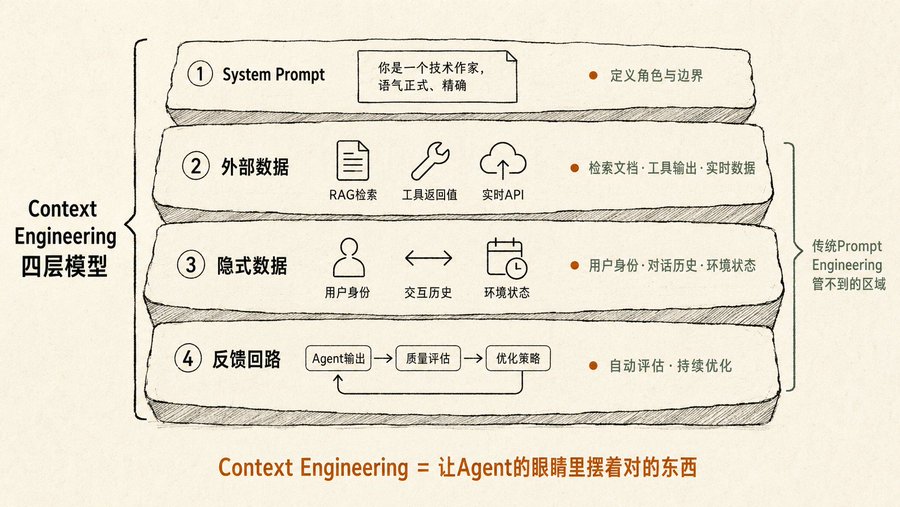
Traditional Prompt Engineering only cares about "how you ask." Context Engineering in the book cares about "what the Agent sees in front of it before it's asked." It includes four layers of information:
-
First layer, the system prompt. Defines who the Agent is, its tone, its boundaries. Most people only write this layer.
-
Second layer, external data. Documents retrieved via RAG, return values from tool calls, real-time API data. This is where most people get stuck: they know they need to feed data, but not how to do it without overwhelming the model.
-
Third layer, implicit data. User identity, interaction history, environmental state. Things you don't explicitly state but the Agent should know. For example, if you tell the Agent, "Help me email John to confirm tomorrow's meeting," it should know what tomorrow's meeting in your calendar is and what your relationship with John is.
-
Fourth layer, the feedback loop. After each output, the Agent automatically evaluates quality and adjusts the context strategy for next time. The book calls this "automated context optimization." Google's Vertex AI Prompt Optimizer is the engineering implementation of this idea.
When I read this part, I remembered my article "AI Agents Are Not Magic," which included the insight: "Your Agent needs rules, and a lot of them." Looking back now, those rules were essentially a manual version of Context Engineering; the book systematizes it.
Reflection: Two Agents Are Truly Better Than One
This is the pattern with the most practical value for me in the entire book.
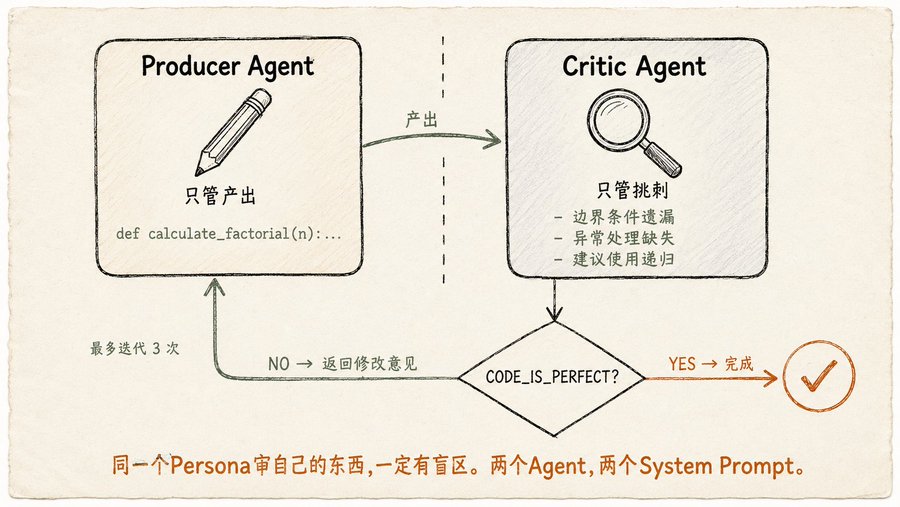
The core of Reflection is simple: after finishing work, the Agent reviews itself, finds problems, and corrects them. But the implementation matters. The book states clearly: The Producer and the Critic must be two different Agents, with different system prompts. The same persona reviewing its own work will always have blind spots. If you let the same LLM write code and then review the code it just wrote, it will most likely say, "It's fine."
The book provides a complete code example.
-
The Producer's prompt is: "You are a Python developer. Write a function to calculate factorial, handle edge cases and exceptions."
-
The Critic's prompt is: "You are a nitpicking senior engineer. Review the code line by line, check for bugs, style, missed edge cases, and areas for improvement. If perfect, output
CODE_IS_PERFECT, otherwise list all issues." -
Then there's a for loop: Producer writes code → Critic reviews → Producer revises based on feedback → Critic reviews again → until Critic says
CODE_IS_PERFECTor the maximum iteration count is reached.
It's that simple. But the book warns about a cost issue easily overlooked: each reflection loop is a new LLM call; the more iterations, the more expensive. Also, as the conversation history expands, the context window gets filled with earlier versions and criticisms, reducing the actual reasoning space available. So the best practice for Reflection is: set a reasonable maximum number of iterations (the book uses 3), stop once the Critic is satisfied, don't pursue perfection.
Its uses go far beyond writing code. Writing articles, making plans, summarizing documents, solving logic puzzles—the Producer-Critic model applies everywhere. The book lists seven application scenarios, with the same core logic: produce, review, revise.
Multi-Agent Isn't About Being More Complex
In the Multi-Agent Collaboration chapter, my favorite part is the six communication topology diagrams. Many people start with complex structures, but in reality, three are sufficient for most scenarios:
-
Single Agent (Independent Execution): The task can be broken down into independent sub-problems, each handled by its own Agent. Simple, easy to maintain.
-
Peer-to-Peer Network: Agents communicate directly with each other, with no central control node. Decentralized, good fault tolerance—if one Agent fails, it doesn't affect the whole. But coordination costs are high, and it can get chaotic.
-
Supervisor (Centralized Orchestration): A Supervisor Agent manages a group of Worker Agents. Assigns tasks, collects results, resolves conflicts. Clear hierarchy, easy to manage. But the Supervisor is a single point of failure and a performance bottleneck.
The other three (Supervisor-as-Tool, Hierarchical, Custom Hybrid) are variations and combinations of the first three. The book is very practical: the topology you need depends on your task complexity. The more fragmented the task, the higher the communication cost. At a certain point, the Supervisor pattern becomes more efficient than the hierarchical one.
My takeaway is that many people building Multi-Agent systems spend 80% of their time on communication protocols, forgetting to ask a more fundamental question: does this task *really* need multiple Agents? The book is clear: a single Level 2 Agent with Reflection is often sufficient. Level 3 is for scenarios where a single Agent genuinely can't handle it.
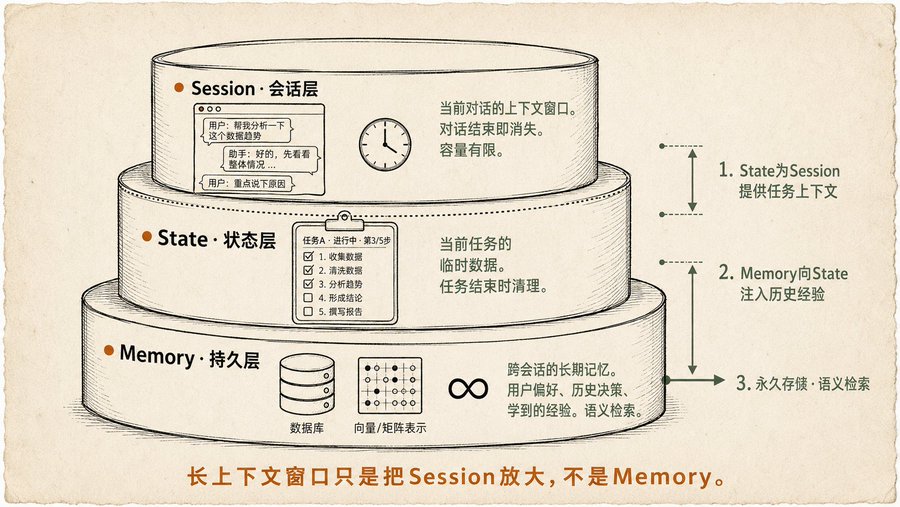
The Three-Layer Memory Model: I Felt It Vaguely But Never Named It
I resonated most with the Memory chapter because when I wrote those two articles about Obsidian + Claude, I kept wondering: how should an Agent's memory be layered?
The book provides the answer:
-
Session (Conversation Layer): The context window for the current conversation. This is the shortest memory; it's gone when the conversation ends. Long-context models simply enlarge this window, but it's still temporary, and each inference has to process the entire window, which is expensive and slow.
-
State (State Layer): Temporary data during the current task. For example, "what is the ongoing task," "what step has been completed," "what intermediate data has been generated." Longer than Session, but cleaned up when the task ends. The book provides a complete example using Google ADK's State mechanism.
-
Memory (Persistent Layer): Long-term memory across sessions and tasks. User preferences, learned experiences, important historical decisions, stored in databases or vector stores, retrieved semantically. The book emphasizes an important point: Memory isn't just about storing; you must design a full strategy for *what* to store, *when* to store it, and *how* to retrieve it. Store too much, noise increases; store too little, it's insufficient.
In my previous article about Clawdbot, I mentioned "state files" and "workspace documents," which were essentially handcrafting the State and Memory layers. The book has framed this.
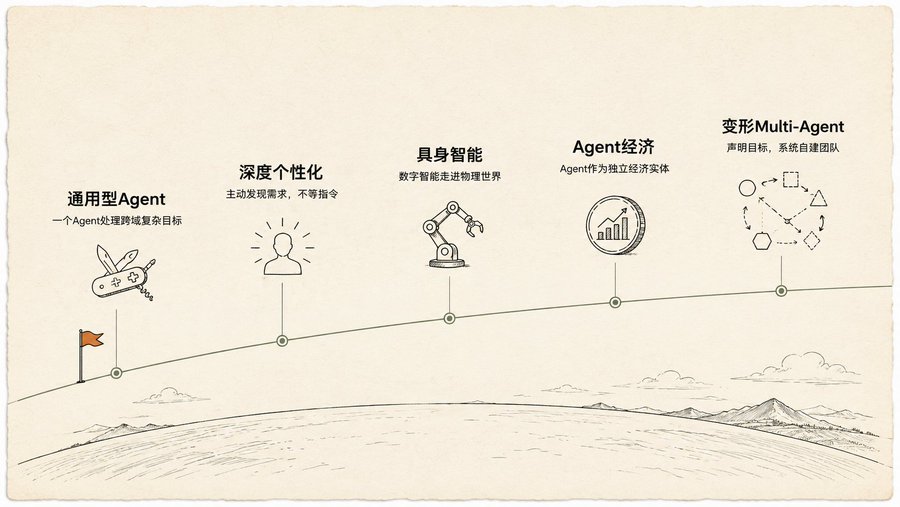
Five Hypotheses, the Fifth Is the Most Outlandish
At the end of the book, it presents five hypotheses about the future of Agents. The first four are within reasonable speculation: General-purpose Agents evolve from writing code to managing projects; Deep Personalization proactively discovers your needs; Embodied Intelligence moves from screens into the physical world; Agents become independent economic entities.
The fifth one stunned me: Shape-Shifting Multi-Agent.
You only declare a goal, like "start a premium coffee e-commerce business." The system automatically decides: first create a "Market Research Agent" and a "Brand Agent." After running a round of data, it judges that the Brand Agent is no longer needed, splitting it into three new ones: "Logo Design Agent," "Website Builder Agent," "Supply Chain Agent." If the Website Builder Agent becomes a bottleneck, the system automatically replicates three parallel Agents to work on different pages simultaneously. Throughout the process, the system continuously auto-tunes each Agent's prompts and constantly restructures the team architecture.
The book calls this a "goal-driven, self-transforming multi-agent system." It's not executing a plan you wrote; it's generating the plan itself, adjusting the plan itself, and reorganizing the execution team itself.
This reminds me of Karpathy's AutoResearch: write a program.md, define goals, metrics, boundaries, and press "Launch." Humans are outside the loop. But this book pushes further: even how the Agent team is formed and restructured is left for the system to decide. Humans only declare "what they want."
Three Things You Can Do Immediately
After reading this book, I have three actionable items to implement immediately:
-
First, add a Critic to your current Agent. Whether you use Claude Code, CrewAI, or your own framework, add one step at the end of your existing workflow: have another Agent (with a different system prompt) review the previous step's output. Code generation + code review, article writing + fact-checking, plan creation + feasibility assessment. It's one more LLM call, but the quality improvement is often doubled. The book's Producer-Critic pattern is plug-and-play.
-
Second, start doing Context Engineering, not just Prompt Engineering. Go back and look at your instruction files for the Agent. If they are all rules about "how you should do things" but lack the context of "what environment you are currently facing," add it. Tell the Agent which project it's in, what decisions it made before, what the user's preferences are. The Context Engineering chapter in the book and your
AGENTS.mdare two expressions of the same thing. -
Third, don't rush into Multi-Agent yet. Get your single Agent to Level 2 first: with tools, Reflection, and Memory. The book repeatedly emphasizes that a Level 2 single Agent with Producer-Critic and Context Engineering can cover the vast majority of practical scenarios. Level 3 is for truly cross-domain, multi-stage tasks requiring parallel division of labor. Most people's problem isn't having too few Agents; it's that they haven't even tuned one Agent properly.
This book is 453 pages, published by Springer in 2025. Code examples cover LangChain/LangGraph, Google ADK, CrewAI, and the OpenAI API. The foreword is written by Google Cloud AI VP, and there's a surprising and engaging recommendation preface from a Goldman Sachs CIO.
But my reason for recommending it isn't "comprehensive." It's because you'll realize something after reading: the pitfalls you've encountered with Agents in the past six months have been organized into patterns. You don't need to reinvent Reflection, guess how Memory should be layered, or experiment with which communication topology to use for Multi-Agent.
Someone has drawn the map for you. The rest is just walking.
Are you using AI Agents for development? What Level is your current Agent at?