4-17%. This was the prompt cache read rate for Claude Code over the past month. The normal level is 97-99%.
This means that when you resumed a previous session, Claude Code did not reuse the context that had already been processed, but instead processed the entire content from scratch each time, consuming 10 to 20 times the normal amount of allowance. You thought you were continuing a conversation, but in reality, you were starting a brand new, full-price conversation every time.
This number comes from independent developer ArkNill's proxy monitoring tests. By setting up a transparent proxy, he recorded every request between Claude Code and the Anthropic API, discovering at least two client-side cache bugs that prevented the API server from matching cached conversation prefixes, forcing a full token rebuild every round.
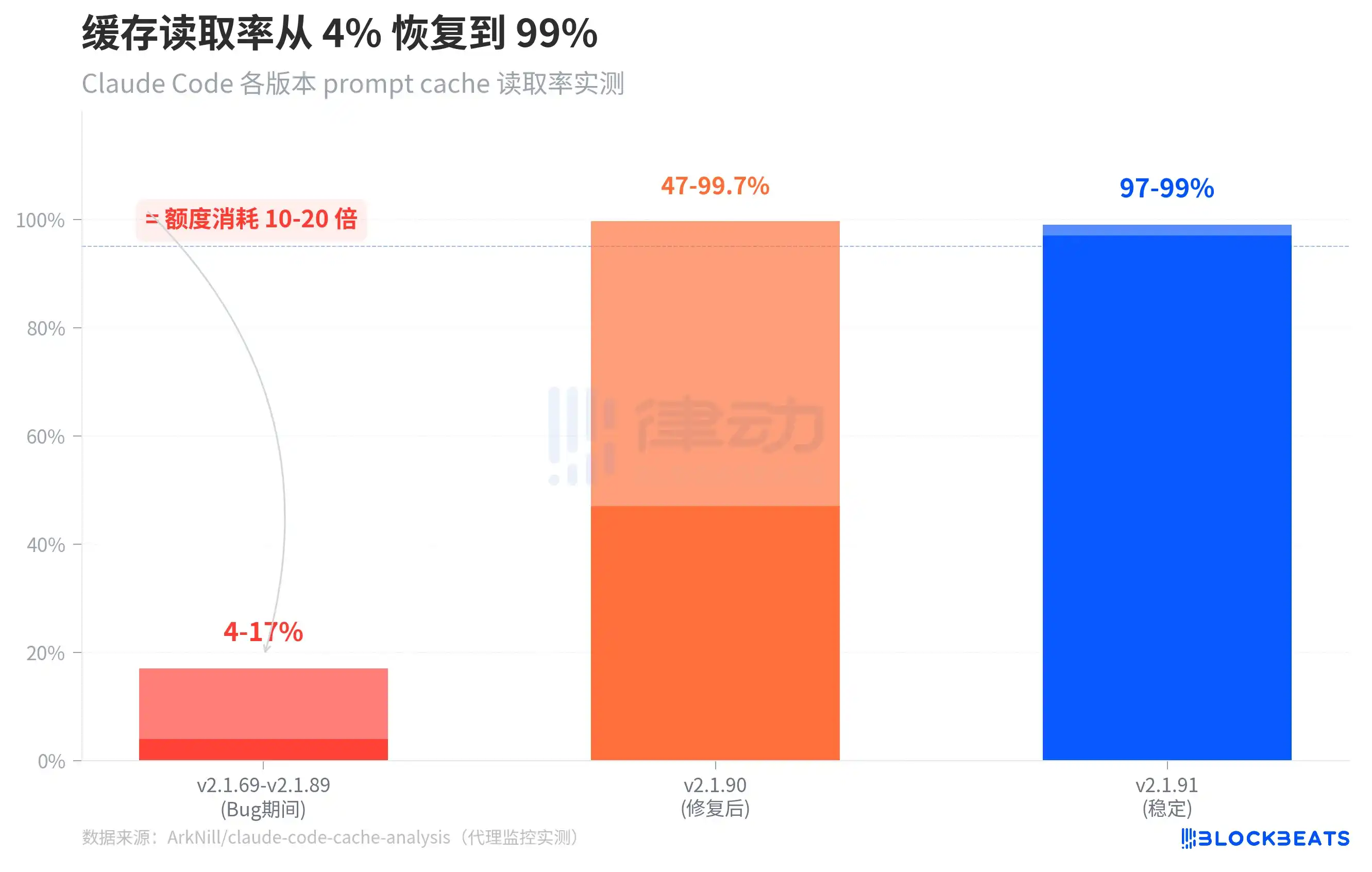
The chart above shows a comparison of cache read rates across three phases. During the period from v2.1.69 to v2.1.89 (i.e., the bug period), the cache read rate for the standalone version was only 4-17%. After v2.1.90 fixed one of the critical bugs, the cold-start cache read rate returned to 47-99.7%. By v2.1.91, the stable running cache read rate recovered to 97-99%.
Notably, a detail in the chart: the range for v2.1.90 is very wide (47% to 99.7%). This is because when a session is first resumed, it still needs to "warm up" the cache; the hit rate for the first few rounds is relatively low but quickly returns to normal levels. In the buggy version, this warm-up never happened—the cache read permanently stalled at the 14,500 tokens of the system prompt, and the entire conversation history was billed at full price every time.
28 Days, 20 Versions
This bug wasn't the kind introduced in one update and fixed in the next. According to npm registry release records, the bug-introducing v2.1.69 was released on March 4th, and the bug-fixing v2.1.90 was released on April 1st. This spans 28 days and 20 versions.
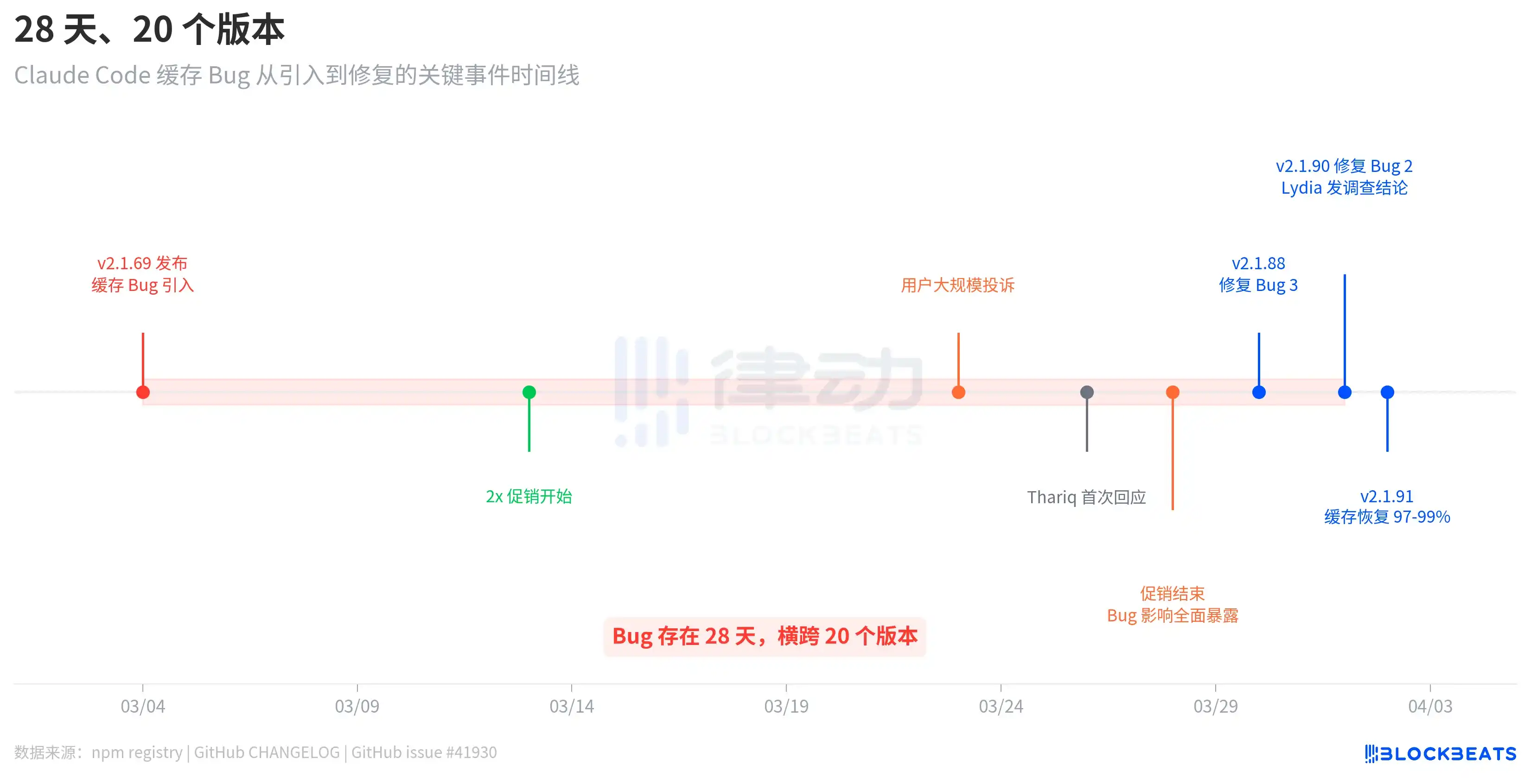
The timeline reveals an intriguing detail. After the bug was introduced on March 4th, users did not immediately complain on a large scale. Complaints only exploded around March 23rd, nearly three weeks later. The reason, as梳理ed in GitHub issue #41930, is that Anthropic ran a 2x allowance promotion (doubling during off-peak hours) from March 13th to 28th, which objectively masked the bug's impact. After the promotion ended, the consumption from the cache bug returned to the normal billing baseline, and users' allowances instantly "evaporated".
Anthropic's response was not swift. On March 26th, three days after user complaints exploded, engineer Thariq Shihipar announced on his personal X account that peak hour (weekdays 5am-11am PT) limits had been tightened. On March 30th, Anthropic acknowledged on Reddit that "users are hitting their limits much faster than expected," calling it the team's highest priority. It wasn't until April 1st that team member Lydia Hallie published the formal investigation conclusion.
Throughout this process, Anthropic did not publish any blog posts, send email notifications, or update their status page. All official communication was done solely through engineers' personal social media posts and a few Reddit comments.
How Much Did You Pay, How Long Could You Use It?
GitHub issue #41930 gathered hundreds of user reports. The most extreme case was a Max 20x subscriber ($200/month) whose 5-hour rolling window was completely exhausted in 19 minutes. Max 5x users ($100/month) reported their 5-hour window being used up within 90 minutes. According to The Letter Two, some users claimed a simple "hello" consumed 13% of their session quota. A Pro user ($20/month) said on Discord their allowance was "used up by Monday, reset on Saturday," meaning they could only use it normally for 12 out of 30 days.
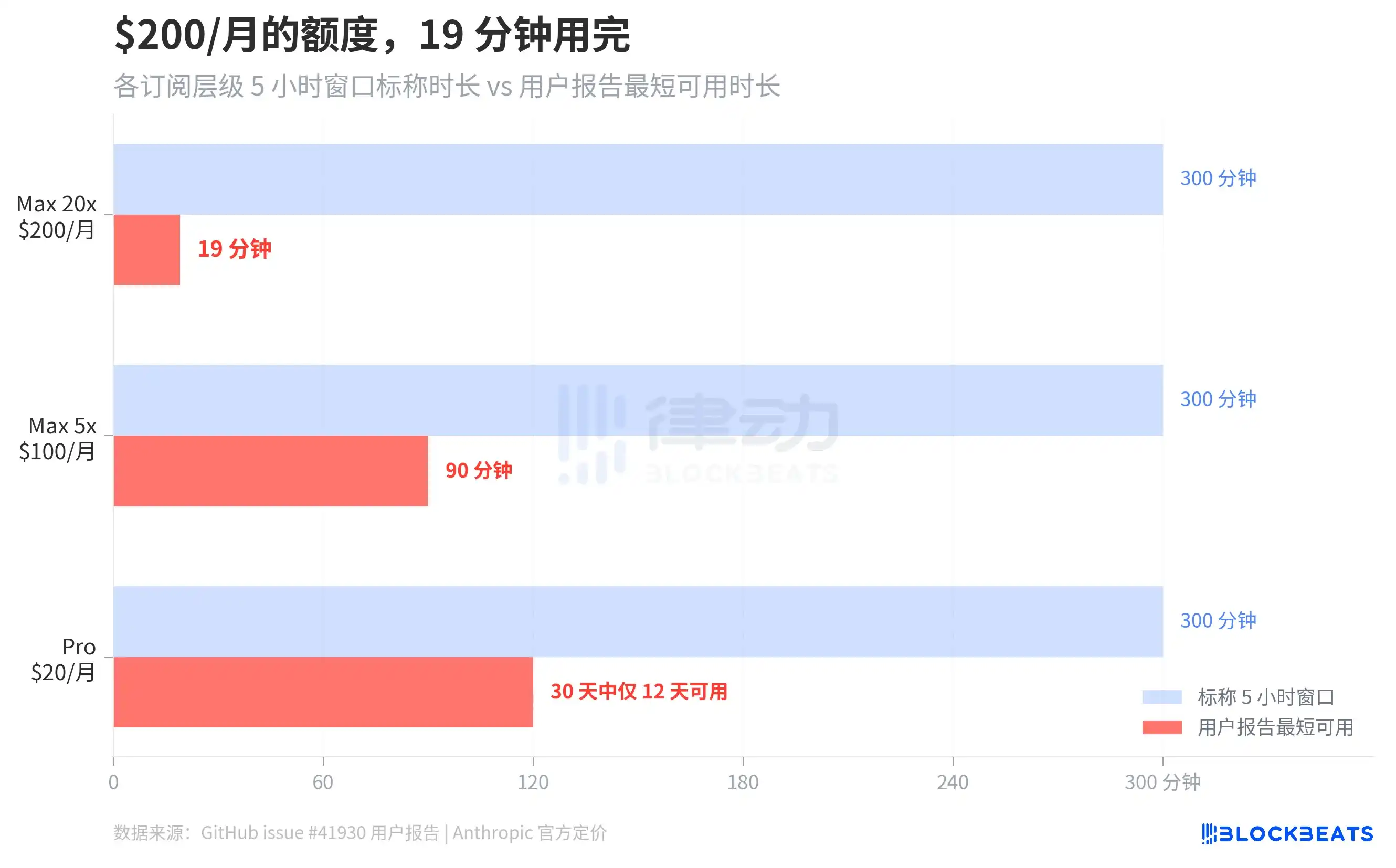
Based on ArkNill's benchmark tests, on the buggy version v2.1.89, the 100% quota of the Max 20x plan would be exhausted in about 70 minutes. He also calculated the allowance cost of a single --resume operation on a 500K token context session to be approximately $0.15, because the system would fully replay the entire context.
"You're Holding It Wrong"
Lydia Hallie's investigation conclusion confirmed two things: first, peak hour limits had indeed been tightened, and second, sessions with 1 million token contexts consumed more. She stated the team had fixed some bugs but emphasized that "none of these bugs resulted in overcharging."
She then offered four suggestions for saving usage:
1. Use Sonnet 4.6 instead of Opus (Opus consumes about twice as much);
2. Reduce reasoning strength or turn off extended thinking when deep reasoning isn't needed;
3. Don't resume long sessions idle for over an hour, start a new one instead;
4. Set the environment variable CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 to limit the context window size.
There was no mention of any form of quota reset or compensation.
AI podcast host Alex Volkov summarized this response as "You're holding it wrong," pointing out that Anthropic itself set the 1 million token context as the default, promoted Opus as the flagship model, and marketed extended thinking as a selling point, but is now advising paying users not to use these features.
The claim of "no overcharging" also creates tension with Claude Code's own update records. Just the day before Lydia's response, v2.1.90 fixed a cache regression bug that had existed since v2.1.69: when using --resume to restore a session, requests that should have hit the cache triggered a full prompt cache miss, billed at full price. Lydia's response did not mention this confirmed billing anomaly.

As a comparison, OpenAI's Codex previously had a similar issue of abnormal quota consumption. OpenAI's approach was to reset user quotas, issue credit补偿, and in March announce the removal of Codex usage caps. Anthropic's approach was to advise users to downgrade models, turn off features, limit context, and attribute responsibility to user usage patterns.
Anthropic sells subscriptions for the "strongest model + largest context + highest reasoning ability" and charges $20 to $200 per month. A 28-day cache bug caused paying users' allowances to evaporate at 10-20 times the normal rate, and the official response is to tell you to use it sparingly.







