Author: Omnitools
AI relay stations are evolving from niche tools into broader gateways to models. For many users, their appeal is straightforward: lower prices, more models, a unified interface, and the ability to connect to development tools like Claude Code, Codex, and Cursor.
But the problem with relay stations lies precisely here. Users think they're just switching to a cheaper API endpoint; in reality, they might be handing over their prompts, code, business documents, client information, call logs, or even the entire development context of a project.
Omnitools believes the discussion about AI relay stations shouldn't stop at "can it be used?" or "which one is cheapest?". More important questions are: Where does the demand behind relay stations come from? Do users truly need them? And if they must be used, how can risks be controlled?
1. The Market Demand Behind Relay Stations
One obvious conclusion is that relay stations are popular because the demand is real.
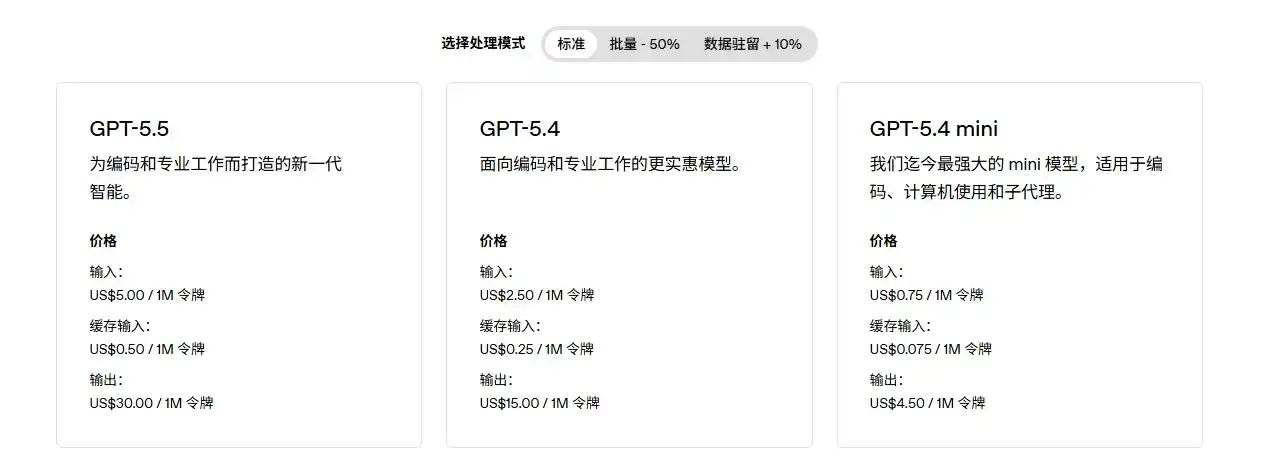
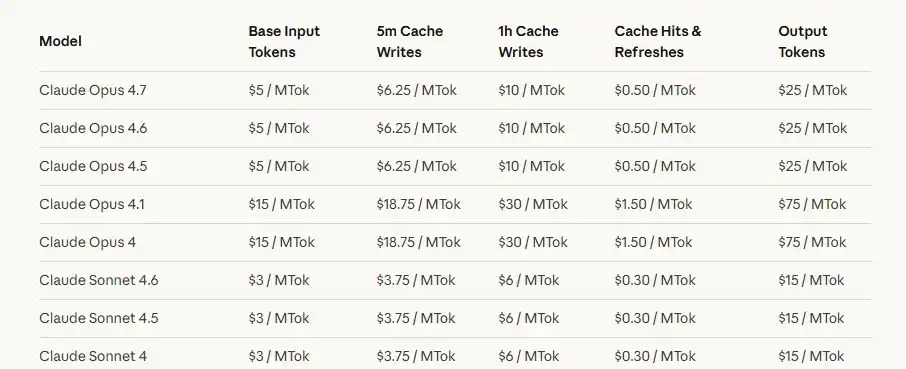
First, there's the price advantage. Official APIs from leading overseas large language models are not cheap. The OpenAI pricing page shows GPT-5.5 input at $5 per million tokens, output at $30 per million tokens; the Anthropic pricing page shows Claude Sonnet 4.7 input at $5 per million tokens, output at $25 per million tokens. For casual chat, these costs aren't obvious, but for long-text processing, code generation, multi-turn agent tasks, and automated workflows, the cost of calls can quickly become noticeable.
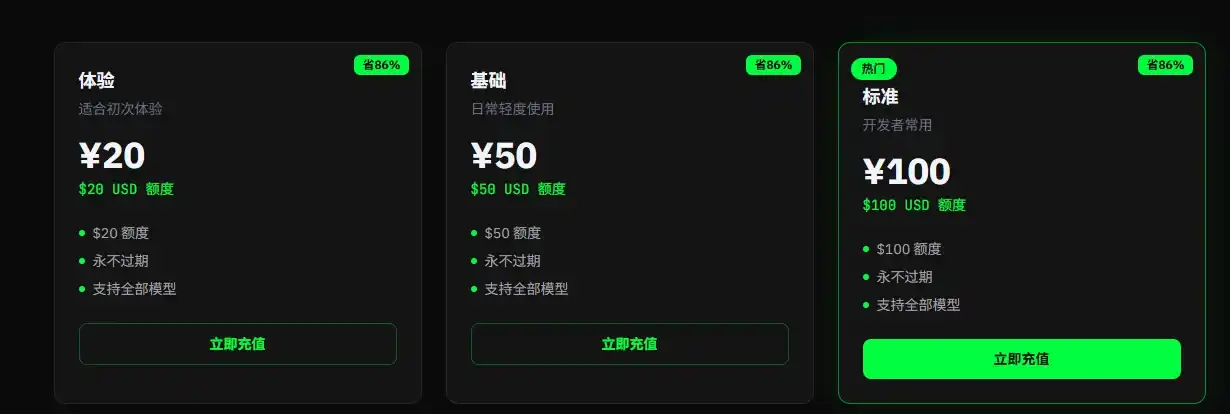
The main selling point of relay stations is offering access to APIs at prices far below official rates, for example, purchasing $1 worth of tokens for 1 RMB, with discounted prices being only about 15% of the official rate. For users with substantial demand, this is tangible cost savings.
Second is access barriers. As access restrictions from US models on users in mainland China become increasingly strict, even ignoring price advantages, using official APIs or plans at full price poses a high verification barrier for many users. Additionally, in usage scenarios, if users want to use Claude, GPT, Gemini, and domestic models simultaneously, they must switch between multiple platforms. Relay stations compress this complexity into a single entry point, acting like an "aggregated socket" in the AI model world—users no longer care which line is behind it, only if it delivers stable power.
Third is the push from development tools. In the past, models were mainly used for Q&A and writing; now, tools like Claude Code, Codex, and Cursor are integrating models into local development workflows. Model calls are no longer just a single chat but could be a code review, a project refactor, or an automatic fix. Furthermore, with the emergence of the "crawfish farming" trend, the demand for tokens has also grown. The heavier the demand, the more likely users are to seek cheaper, higher-capacity, more unified access methods.
Therefore, the booming business of relay stations is driven by real demand, not just another hype cycle.
2. Do You Really Need a Relay Station?
However, not everyone needs to use a relay station.
If you only occasionally ask questions, translate text, summarize public information, or write general copy, you often don't need a relay station. Models and tools like ChatGPT, Gemini, Antigravity, etc., have free tiers. If dealing with verification and accounts is an issue, many large model aggregators are available, some also offering free tiers sufficient for daily use.
For light users, rather than handing data over to an unknown relay station for "cheapness," it's better to first exhaust the free tiers of official and legitimate tools. Free tiers may change, and specific limits should be checked on each platform's official page, but the principle remains: low-frequency demand doesn't require rushing to use a relay.
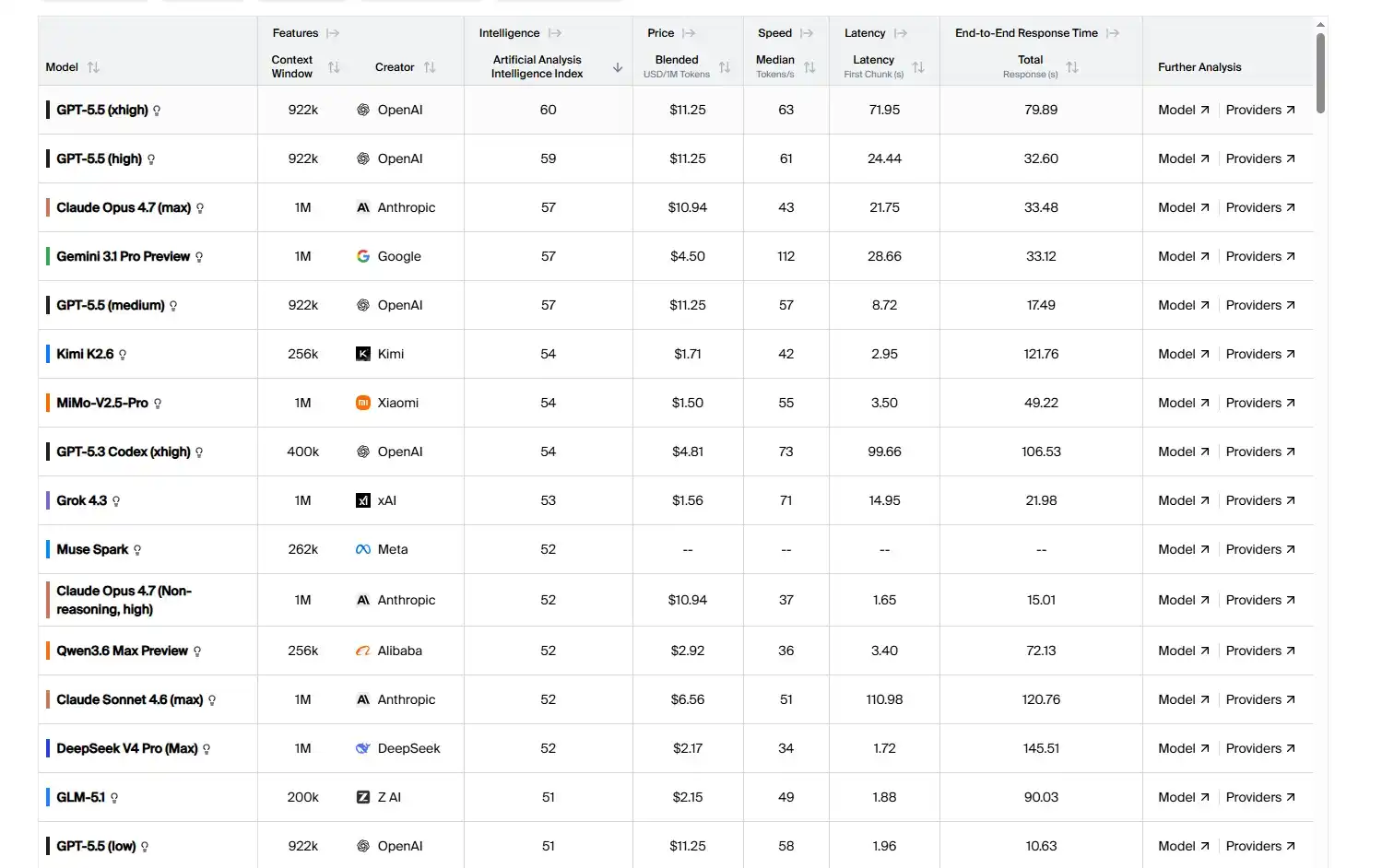
For heavy programming users, it's also not always necessary to delegate all tasks to expensive models or relay stations. A safer approach is to use models in layers: use stronger large models for requirement breakdown, technical direction, architecture design, and code review; then use cheaper domestic models for more concrete function development, daily operations, etc. Moreover, with domestic models continuously catching up, many are already comparable in capability to top US models for daily development tasks, often at prices cheaper than many relay stations. Take Kimi K2.6 as an example, its output price per million tokens is $4, only 13% of ChatGPT 5.5, a price lower than many relay stations.
Of course, this method isn't perfect, but it better matches cost structures. Complex tasks most need directional judgment and framework ability; concrete implementation can be broken down into multiple low-risk, low-cost subtasks. For individual developers and small teams, breaking tasks down first, then deciding which stages require high-end models, is usually more rational than directly purchasing large relay station quotas.
Only when users already have continuous, high-frequency, multi-model calling needs—such as long-term use of AI programming tools, processing large volumes of public information, conducting model comparisons, building internal automation workflows—and official quotas are clearly insufficient, do relay stations become a potential option. Even then, they should be a "tool after screening," not the default entry point.
3. How to Choose and Use Relay Stations?
If evaluation confirms the need for a relay station, the next question is no longer "to use or not," but "how to use it without incident." The following is a complete operational process from evaluation to daily use.
Step 1: Verify First, Then Top Up
After getting a relay station address, don't rush to top up. First, do three things:
Verify model authenticity. Call the relay station and the official API with the same prompt, compare output quality, response format, and token usage. Some relay stations might impersonate higher-version models with lower ones, or inject extra system prompts in outputs. A simple test is to ask the model to report its version info, then cross-check with official behavior. While not foolproof, this can filter out obviously problematic platforms.
Test latency and stability. Make 20-50 consecutive calls, observe for frequent timeouts, random errors, or fluctuations in response quality. The relay station path has an extra layer compared to direct connection; if basic stability isn't up to par, issues will only multiply later.
Check documentation quality. A seriously operated relay station usually provides complete API documentation, OpenAI-compatible access instructions, clear model lists, and pricing tables. If a platform's documentation is patchy, or its model list vague, be more cautious.
Step 2: Isolate Configuration, Don't Mix
After confirming basic platform usability, next comes technical isolation. Many users skip this step, but it determines the scope of loss if problems arise.
Use independent API Keys. Don't directly enter the Key you applied for on the official platform into the relay station, nor share the same Key across multiple relay stations. Generate a separate Key for each relay station. If one platform has issues, you can immediately invalidate it without affecting other services.
Manage keys via environment variables. In local development environments, store API Keys in .env files or system environment variables; don't hardcode them into the code. For example, in Cursor, when filling in the API Base URL and Key in settings, ensure these configurations won't be committed to the Git repository. If using command-line tools like Claude Code or Codex, check your shell configuration files to ensure Keys don't appear in version control history.
Set usage limits. Most legitimate relay stations support setting monthly token quotas or spending caps. The first thing after topping up is to set these limits. This isn't just cost control; it's also a safety net. If your Key is accidentally leaked, usage limits can contain the damage.
Step 3: Establish Data Classification Habits
After technical configuration, the most crucial part of daily use is making quick data classification judgments for each call. You don't need to write a security report each time, but develop a reflex-like checking habit.
Before sending, ask yourself one question: If this content appears on a public forum tomorrow, can I accept it?
If the answer is "yes"—like summarizing public materials, general translation, technical discussions on open-source projects, analyzing public documents—then you can directly use the relay station.
If the answer is "not really, but the loss is controllable"—like internal meeting minutes, business document drafts, customer communication templates, code snippets—then anonymize before sending. Specific practices: replace names with role codes ("Client A", "Colleague B"), replace specific amounts with proportions or ranges, replace internal IDs with placeholders, delete database connection strings, internal API endpoints, and descriptions of unpublished business logic. This process doesn't take long, usually a minute or two, but it reduces risk from "might cause trouble" to "basically manageable."
If the answer is "absolutely not"—like private keys, mnemonics, production environment keys, database passwords, unpublished financial data, customer privacy information, complete private codebases—then don't hand it to any relay station, no matter how secure it claims to be.
Step 4: Treat AI Programming Tools Separately
This point deserves special emphasis because AI programming tools have a much larger data exposure surface than ordinary chat.
When you connect a relay station in tools like Cursor, Claude Code, Cline, the model receives not just your actively entered prompt, but may also include: currently open file content, project directory structure, terminal output history, dependency config files (like package.json, requirements.txt), Git commit history, and file paths and environment variable names in error messages.
This means a seemingly ordinary "help me fix this bug" might send far more data to the relay station than you expect.
Operational advice: When using relay stations in AI programming tools, prioritize independent, non-core business-related coding tasks. If you must handle code involving private repositories or production environments, two relatively safe practices exist: one is to only paste anonymized code snippets, not let the tool directly read the entire project; the other is to switch development of sensitive projects back to official APIs or local models, using relay stations only for non-sensitive projects. Neither is perfect, but both are better than handing the entire development context indiscriminately to a third-party proxy.
Step 5: Continuous Monitoring, Be Ready to Exit
Using a relay station is not a one-time decision but an ongoing evaluation process.
Regularly check billing records. Confirm token consumption matches your actual usage. If usage doesn't increase noticeably during a period but charges accelerate, the platform might have adjusted billing rules, or your Key might have abnormal calls.
Monitor platform announcements and community feedback. The operational status of relay stations can change at any time—upstream channel adjustments, quota policy changes, service sudden shutdowns are all possible. If you rely on a relay station as your main access method, at least have a backup plan. It's recommended to register for 2-3 platforms simultaneously, maintain minimum top-ups, and avoid concentrating all calls on a single channel.
Ensure migration readiness. When configuring the relay station, use standard interfaces in OpenAI-compatible format, so switching platforms usually only requires changing the Base URL and API Key, without modifying code logic. If your project is deeply tied to a relay station's private interface or special features, migration costs will rise significantly—another risk to consider in advance.
Ultimately, relay stations are tools, not beliefs. Their value lies in solving real access needs with controllable costs, but this "controllability" needs to be defined and maintained by you. Through verification, isolation, classification, specialized handling, and continuous monitoring, keep the initiative in your own hands.








