撰文:Jiawei @IOSG
三年前,我们写过一篇 Appchain 的文章,起因是 dYdX 宣布将其去中心化衍生品协议从 StarkEx L2 迁移到 Cosmos 链上,将其 v4 版本作为基于 Cosmos SDK 和 Tendermint 共识的独立区块链推出。
在 2022 年,Appchain 可能是相对边缘的技术选项。步入 2025 年,随着越来越多 Appchain,特别是 Unichain 和 HyperEVM 的推出,市场的竞争格局正在悄然变化,并且形成了围绕 Appchain 所展开的趋势。本文将从此出发,讨论我们的 Appchain Thesis。
Uniswap 和 Hyperliquid 的选择

Source: Unichain
关于 Unichain 的构想出现得很早,Nascent 创始人 Dan Elitzer 在 2022 年就发表了 The Inevitability of UNIchain,提出 Uniswap 的体量、品牌、流动性结构以及对性能和价值捕获的需求,指向其推出 Unichain 的必然性。从那时起就一直有关于 Unichain 的讨论。
Unichain 在今天 2 月正式推出,已经有超过 100 个应用程序和基础设施提供商在 Unichain 上构建。目前 TVL 约为 10 亿美金,排在众多 L2 的前五。未来还将推出 200ms 区块时间的 Flashblocks 和 Unichain 验证网络。
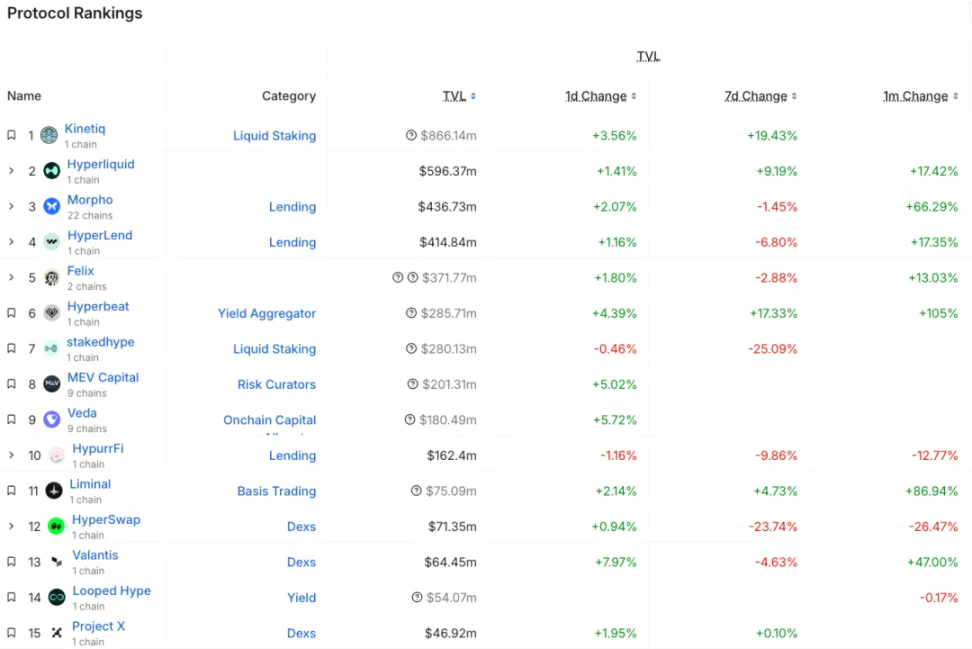
Source: DeFiLlama
而作为 perp 的 Hyperliquid 显然从 day 1 就有 Appchain 和深度定制化的需求。在核心产品之外,Hyperliquid 还推出了 HyperEVM,与 HyperCore 一样,由 HyperBFT 共识机制保护。
换句话说,在其本身强大的 perp 产品之外,Hyperliquid 还在探索构建生态的可能性。目前 HyperEVM 生态已经有超过 20 亿美金的 TVL,生态项目开始涌现。
从 Unichain 和 HyperEVM 的发展,我们可以直观地看到两点:
L1/L2 竞争格局开始分化。Unichain 和 HyperEVM 生态 TVL 加起来超过 30 亿美元。这些资产在过去本应沉淀在以太坊、Arbitrum 等通用型 L1/L2 上。顶级应用自立门户直接导致了这些平台的 TVL、交易量、交易费用和 MEV 等核心价值来源的流失。
过去,L1/L2 与 Uniswap、Hyperliquid 这类应用是共生关系,应用为平台带来活跃度和用户,平台为应用提供安全和基础设施。现在,Unichain 和 HyperEVM 自己成为了平台层,与其他 L1/L2 形成了直接的竞争关系。它们不仅争夺用户和流动性,也开始争夺开发者,邀请其他项目在自己的链上构建,这从很大程度上改变了竞争格局。
Unichain 和 HyperEVM 的扩张路径与现在的 L1/L2 截然不同。后者往往是先建基础设施,再用激励吸引开发者。而 Unichain 和 HyperEVM 的模型是「产品优先」——它们首先拥有一个经过市场验证、拥有庞大用户基础和品牌知名度的核心产品,随后围绕这个产品来构建生态和网络效应。
这种路径的效率和持续性更高。它们不需要通过高额的开发者激励「购买」生态,而是通过核心产品的网络效应和技术优势「吸引」生态。开发者之所以选择在 HyperEVM 上构建,是因为那里有高频交易用户和真实的需求场景,而不是因为虚无缥缈的激励承诺。显然这是一种更为有机和可持续的增长模式。
过去三年什么改变了?
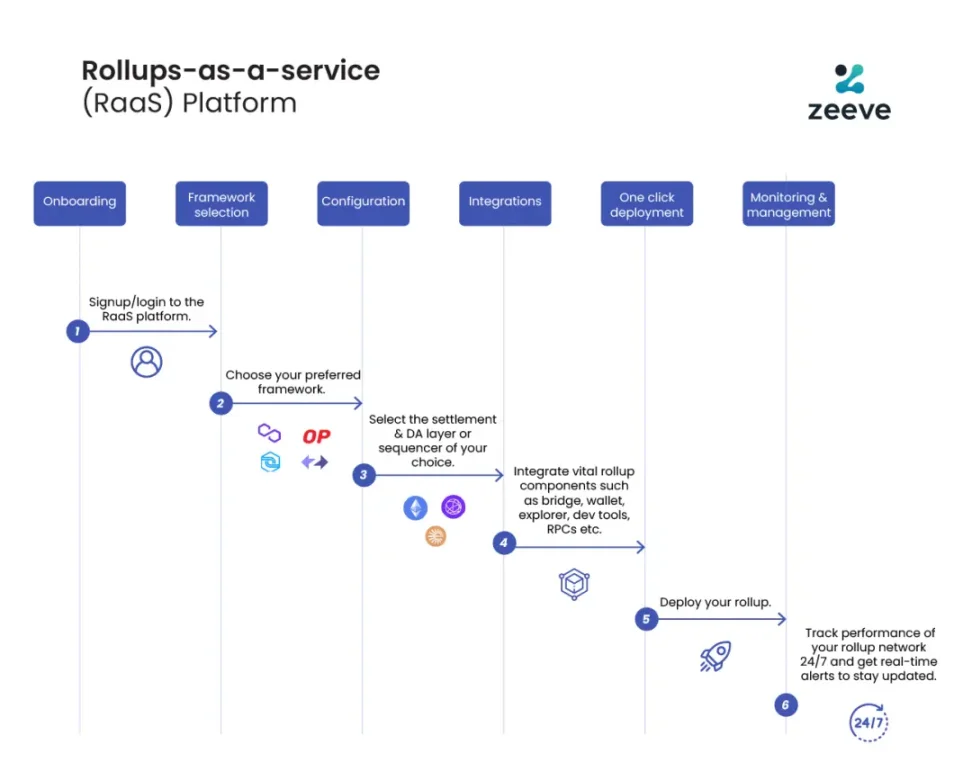
Source: zeeve
首先是技术栈的成熟和第三方服务提供商的完善。三年前,构建 Appchain 需要团队掌握区块链的全栈技术,而随着 OP Stack、Arbitrum Orbit、AltLayer 等 RaaS 服务的发展与成熟,从执行、数据可用性到结算和互操作,开发者可以像选用云服务一样,将各个模块化按需组合,极大降低了构建 Appchain 的工程复杂度和前期资本投入。运营模式从自建基础设施转变为购买服务,为应用层创新提供了灵活性和可行性。
其次是品牌和用户心智。我们都知道注意力是稀缺资源。用户往往忠于应用的品牌,而非底层技术设施:用户使用 Uniswap 是因为其产品体验,而不是因为它运行在以太坊上。而随着多链钱包的广泛采用以及 UX 的进一步改善,用户在使用不同链的时候近乎是无感知的——他们的接触点往往首先是钱包和应用。而当应用构建自己的链,用户的资产、身份和使用习惯都沉淀在应用生态内,形成强大的网络效应。
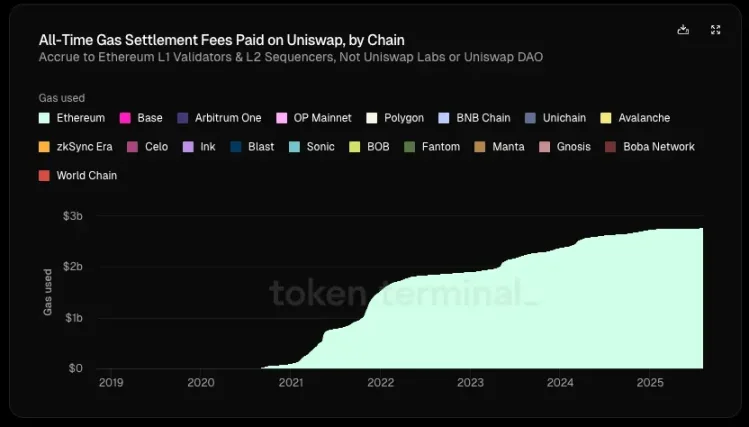
Source: Token Terminal
最重要的是应用对经济主权的追求在慢慢凸显。在传统的 L1/L2 架构中,我们可以看到价值流动呈现明显的「自顶向下」趋势:
-
应用层创造价值(Uniswap 的交易、Aave 的借贷)
-
用户为使用应用支付费用(application fees+ gas fee),这些费用的一部分给协议,一部分给 LP 或其他参与者
-
其中的 gas 费用 100% 流向 L1 验证者或 L2 排序器
-
MEV 被搜索者、构建者和验证者按不同比例瓜分
-
最终 L1 的代币通过质押捕获除 app fee 外的其他价值
在这个链条中,创造最多价值的应用层反而捕获最少。
根据 Token Terminal 统计,在 Uniswap 64 亿美元的总价值创造中(包括 LP 收益、gas 费等等),协议 / 开发者、股权投资者和代币持有者所获得的分配还不到 1%。而自推出起,Uniswap 为以太坊创造了 27 亿美金的 gas 收入,这大概是以太坊收取的结算费用的 20%。
而如果应用有自己的链,会怎么样呢?
它们可以将 gas 费收归己有,用自己的代币作为 gas token;并且把 MEV 内部化,通过控制排序器来最小化恶意 MEV,将良性 MEV 返还给用户;或是定制费用模型,实现更复杂的费用结构等等。
这样看来,寻求价值的内化成为应用的理想选择。当应用的议价权足够大,自然会要求更多的经济利益。因此优质应用对底层链是弱依附关系,而底层链对优质应用是强依附关系。
小结
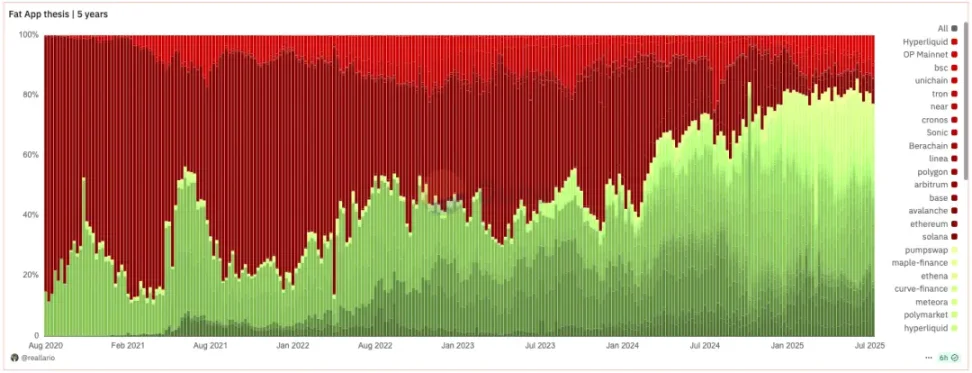
Source: Dune@reallario
上图粗略对比了 2020 年至今协议(红色)和应用(绿色)的收入。我们显然可以看到应用捕获的价值在逐渐上升,并在今年达到约 80% 的水平。这可能在某种程度上推翻了 Joel Monegro 著名的关于「胖协议瘦应用」的理论。
我们正在见证「胖协议」理论向「胖应用」理论的范式转移。回顾过去加密领域对项目的定价逻辑,主要是以「技术攻关」和底层基础设施的推动为核心的。未来则会逐步转向以品牌、流量与价值捕获能力为锚点的定价方法。如果应用可以轻松地基于模块化服务构建自己的链,L1 传统的「收租」模式就会受到挑战。就像 SaaS 的兴起降低了传统软件巨头的议价能力,模块化基础设施的成熟也在削弱 L1 的垄断地位。
未来头部应用的市值无疑会超过多数 L1,L1 的估值逻辑将从以往的「捕获生态总价值」转变为一个稳定、安全的去中心化「基础设施服务提供商」,其估值逻辑将更接近于产生稳定现金流的公共产品,而非能够捕获大部分生态价值的「垄断性」巨头。其估值泡沫会在一定程度上被挤压。L1 也需要重新思考自身定位。
关于 Appchain,我们的观点是:由于具备品牌、用户心智与高度定制化的链上能力,Appchain 可以更好地沉淀长期用户价值。在「胖应用」时代下,这些应用不仅可以捕获自己创造的直接价值,还能围绕应用自身构建区块链,进一步将其外化并捕获基础设施的价值——它们既是产品,又是平台;既服务终端用户,又服务其他开发者。除了经济主权外,顶级的应用还将寻求其他主权:协议升级的决定权、交易排序和审查抵抗和用户数据的所有权等等。
当然,本文主要在已经推出 Appchain 的 Uniswap 和 Hyperliquid 等顶级应用的语境下探讨。Appchain 的发展仍在早期阶段(Uniswap 的 TVL 在以太坊上占比仍然有 71.4%)。而对类似 Aave 等涉及到包装资产和抵押品、高度依赖一条链上的可组合性的协议,也不太适合 Appchain。相对来说,对外部需求只有预言机的 perp 就更适合 Appchain。并且,Appchain 对于中腰部的应用来说并非是最佳选择,需要具体情况具体分析。这里就不再展开叙述。





