
事后看来一切都很明显!
又是我,再次吐槽韩元稳定币。
但今天我终于搞明白了,为什么我们的“掌控者”如此热衷于推广稳定币。
我想我已经发现他们这一切背后的真正动机了!
我们先来看看《金融时报》的报道:
曾任经济与财政部第二副部长的安道杰 (Ahn Do-geol)最近与企划财政部、韩国银行、金融服务委员会、韩国资本市场研究所和其他相关机构组成了一个工作组,起草一份关于韩元计价稳定币的法案。
(…)
安道杰的办公室计划在法案中不仅涵盖稳定币发行方的基本资格和许可要求,还将纳入有关抵押资产要求、货币政策管理措施、外汇交易监管以及用户保护机制的条款。
韩国资本市场研究院的高级研究员黄世云(Hwang Se-woon),作为安安道杰韩元稳定币特别工作组的一员,强调只有符合严格资格标准的实体才应被允许发行稳定币,并且发行方的资格应通过许可制度授予。
TLDR:发行韩元稳定币很可能需要政府的许可
那么,谁最有可能获得政府的批准呢?可能是与政府关系密切的人?或者是那些已经暗示正在为此做准备的成熟企业?
目前还没有人真正知道这项仓促政策的最终赢家会是谁,但市场似乎已经在某些名字上押注得非常积极了。
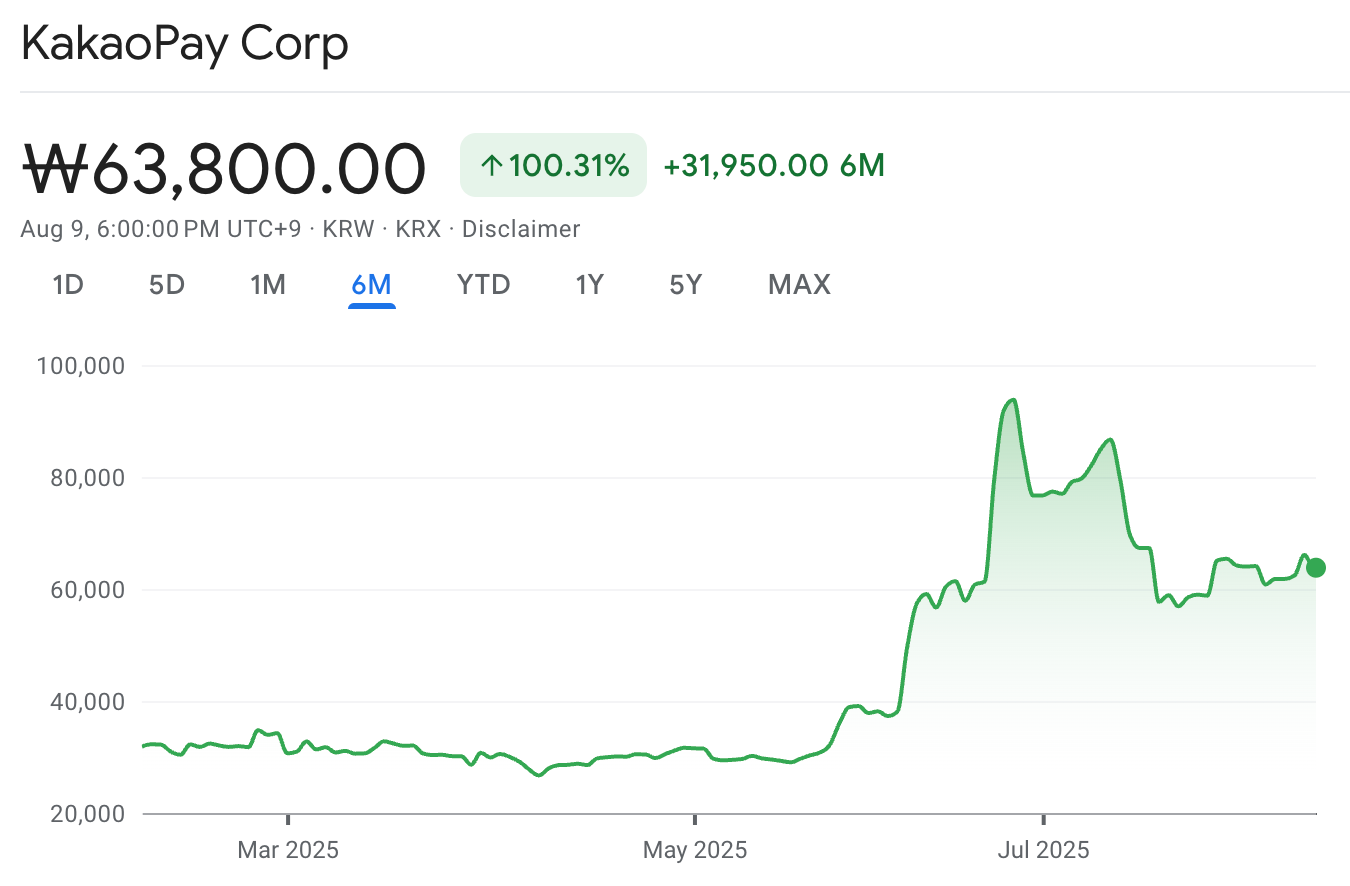
KakaoPay 是韩元稳定币潜在受益者中的显而易见的候选者之一,毕竟它是韩国最大的支付应用之一。
随着 KakaoPay走在前列,Kakao集团正计划部署自己的银行KakaoBank ,进一步推动其稳定币的梦想。
看来韩国的加密玩家们又要“吃饱了”,而那只“看不见的手”似乎在默默地发挥作用。
但这只手真的看不见吗?还是说对某些人来说,它其实是“看得见”的?
感谢4K摄像头,让那只“看不见的手”变得清晰可见
揭露那些宣称自己不持有证券却可能涉及内幕交易的民选官员。
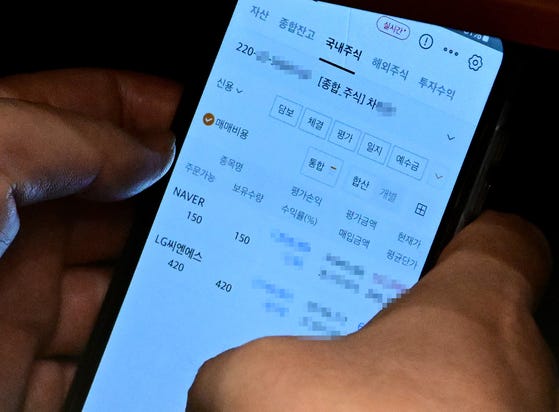
图:韩国民主党议员李春锡(Lee Chun-seok)在国会以他人名义进行股票交易。
韩国民主党议员李春锡(Lee Chun-seok)在国会全体会议期间被拍到通过手机上的证券交易应用操作股票交易,例如交易Naver股票。问题在于,照片中的账户名称并非“李春锡”,而是他的助手车某(Mr. Cha)。
(…)
虽然在过去10个月内拍摄了两张类似的照片,但截至去年12月31日,李议员的资产披露声明中表明,他本人及其家属均未持有任何股票(证券)。根据《金融交易实名制法》,所有金融交易必须以真实姓名进行。任何人若以他人名义进行交易以达到非法目的,例如隐匿资产,可能面临最高五年监禁或最高5000万韩元的罚款。
这经典的“我才不在乎背后有能125倍变焦的摄像头呢,让我看看这些股票涨得怎么样,同时投个赞成票”真的让我无语了。
虽然目前尚无定论他是否真的涉及内幕交易,但仅仅是他用助手账户进行交易这一事实,就已经散发着犯罪的气息。
说到犯罪,很多事情都打着“教育内容”的旗号在进行。

在上述视频的 17:06 时间点,讲述者声称韩流(K-Pop)和韩国文化(K-Culture)可能是韩元稳定币的一个良好应用场景,并重复了那些试图推动相关立法的政治人物的论点。
然而,这段视频真正令人震惊的并不是视频内容本身,而是当你查看评论区时,发现观众对频道主表达的全是失望之情:
- “你怎么了?是在试图竞选吗?”
- “看来我之前一直高估了孝锡(Hyoseok)……”
- “这是怎么回事?政府是不是威胁你发这个视频了?哈哈……嗯。”
然而,看到评论区对这种“洗脑”企图表达不满的声音,反而让我感到一丝恐惧,因为我突然意识到,这些提出质疑的人可能只是这个国家中的绝对少数。
大多数人甚至完全不关心稳定币是什么,也不在意它如何运作。只有具备一定金融知识的人才有能力去关注并解决这些问题。
现任政府的支持率高达65%。当然,这和那张免费的100美元消费券绝对没有关系!
只要继续撒钱,或许他们最终真的能达到自己的目标。
我们都会成功。





