Wang Chuan: When the neighbor Lao Wang earned thirty times from investing in memory storage stocks, how can you still avoid anxiety (6) - The trap of homogeneous products
The article, "Wang Chuan: How to Remain Unanxious After Neighbor Lao Wang's Thirty-Fold Gain on Storage Stocks (Part 6) - The Trap of Commoditized Goods," analyzes the cyclical and perilous nature of the data storage industry through historical and current case studies.
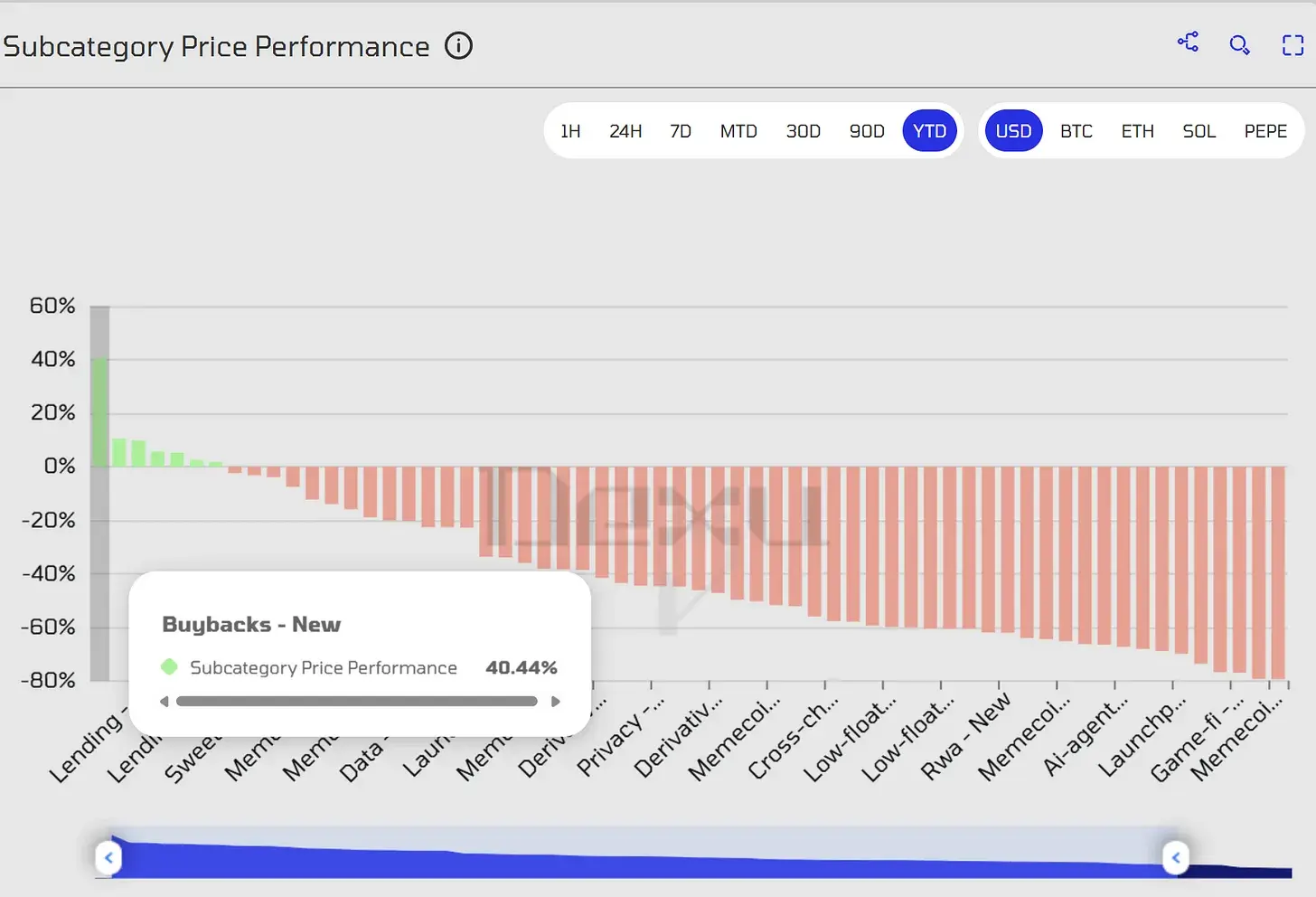
It begins with the example of Iomega, whose Zip drives led to a stock surge of over 160x in the mid-1990s before collapsing over 97% from its peak due to competition from cheaper CD-R technology. This pattern is characteristic of storage, where products like DRAM are highly commoditized, leading to extreme price volatility. The sector has seen prices crash over 80% multiple times, with companies often facing bankruptcy.
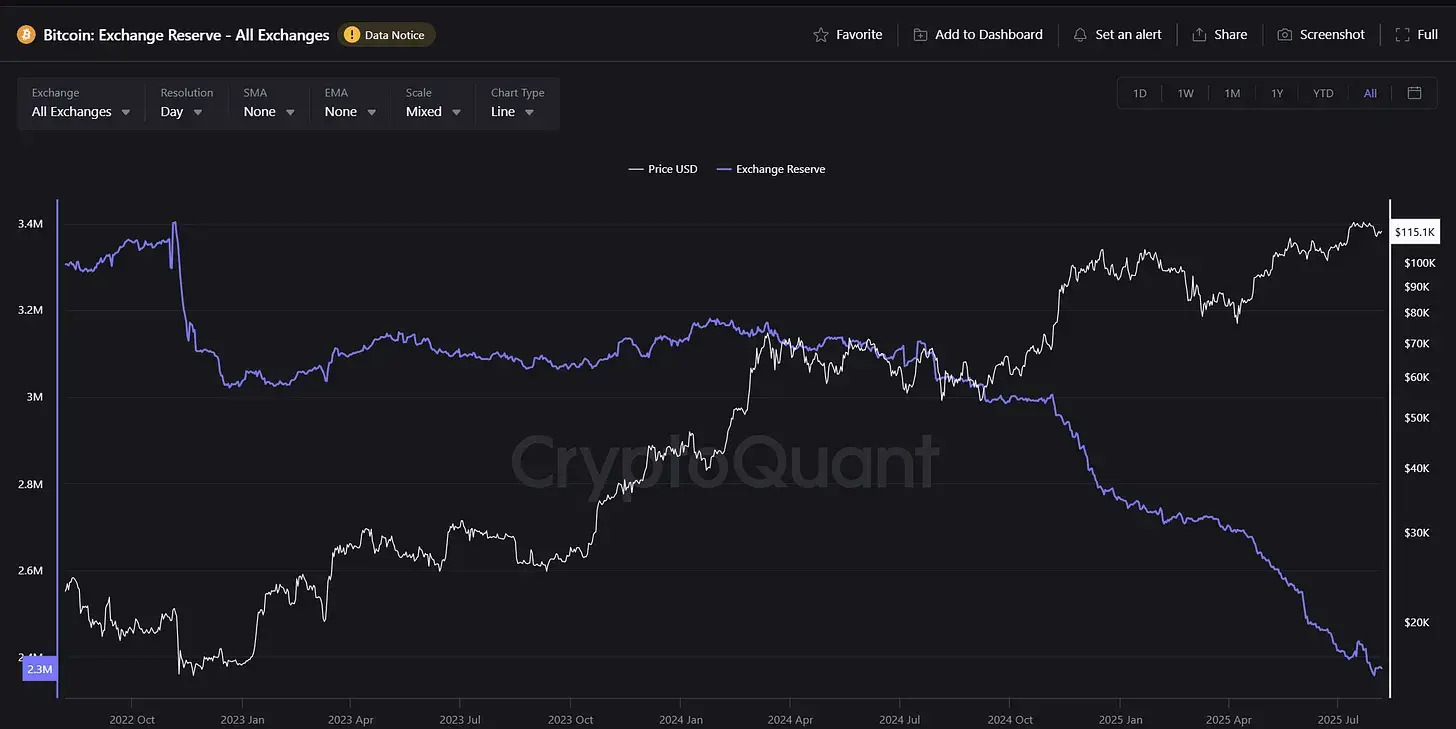
The core dynamic is "elastic demand facing heavy-asset, long-cycle, rigid supply." High prices attract new capacity, but the long lead time means supply eventually overshoots, causing sharp price corrections. The current AI-driven boom, exemplified by surging demand for High-Bandwidth Memory (HBM), has led to skyrocketing prices and profit margins for companies like SanDisk and Micron, despite relatively flat production volumes.
However, the author warns this high-margin environment is self-defeating. The high profits are already triggering massive new capacity investments (hundreds of billions starting 2026), with supply expected to ramp up by late 2027. When supply catches up, total revenue and profits may fall even as more units are sold. Long-term supply agreements offer little protection, as buyers can find ways to renegotiate if market prices drop, similar to fragile political treaties.
Key risks include economic downturns, cuts in AI spending, faster-than-expected capacity expansion (especially from Chinese firms), and innovations in chip/algorithm design that reduce memory needs. A critical trap is that at the cycle's peak, storage stocks often appear cheap with low P/E ratios, luring value investors just before an impending downturn where profits evaporate.
The conclusion cautions that for commoditized goods like storage, high margins inevitably destroy themselves, and the current asymmetry favors downside risk over further upside. The neighbor's dream of easy wealth from storage stocks is portrayed as a precarious illusion.
链捕手4 dk önce