原文标题:The Exact Setup I』m Using to Make $ 1 M+ from HyperEVM
原文作者:@PixOnChain,Bubblemaps 成员
原文编译:律动小 Deep
编者按:本文分享了作者在 HyperEVM 生态中通过资本高效、Delta 中性的策略赚取百万美元以上的详细配置。作者研究了 65 个原生协议,推荐通过 HyperUnit 跨链、质押 $HYPE、提供流动性及对冲等操作,覆盖多个协议以积累积分,同时赚取 19% 以上年化收益。额外玩法包括购买 .hl 域名、NFT 及稳定币操作,重点关注 @hyperunit 和 @prjx_hl,认为早期参与可获高额空投回报。
以下为原文内容(为便于阅读理解,原内容有所整编):
大多数人对 HyperEVM 还毫无察觉。我花了 20 多个小时研究了全部 65 个原生协议。如果你操作得当,我坚信你能拿到六到七位数的空投。
以下是完整攻略:
步骤 1 :在链上获取资金(高效利用资本)
你需要在 HyperEVM 上有流动资金。但并非所有跨链桥都一样。
我使用的跨链桥如下(全部无代币):
@hyperunit
@HyperSwapX bridge
@HyBridgeHL
我主要通过 HyperUnit 跨链转移资产。
它会先桥接到 Hypercore(Hyperliquid 的交易层)。
从那里,只需两步就能到 HyperEVM(详见下文)。
步骤 2 :收益策略(Delta 中性,低风险)
我不喜欢无常损失。我追求收益。以下是我的具体配置:
1. 通过 HyperUnit 跨链
2. 兑换成 $USDC,然后现货买入 $HYPE
3. 将 20% 的 $HYPE 质押到 HypurrCollective x Nansen 验证者
4. 剩余部分转到 HyperEVM(Portfolio > Balances > Transfer to EVM)(Portfolio > Balances > Transfer to EVM)
5. 在 @0x HyperBeat 上将 $HYPE 质押为 $stHYPE
6. 将 $stHYPE 提供给 @HypurrFi 并借入 $HYPE
7. 在 @HyperSwapX 上将 $HYPE 兑换为 $stHYPE
8. 将 $stHYPE 提供给 @hyperlendx
9. 通过 1 倍做空对冲 $HYPE 敞口(目前通过资金费用可赚 35% 年化收益率)。
这种配置形成了一个 Delta 中性的仓位,既能赚取被动收益,又能同时在多个协议上积累积分。以下是基于当前利率的策略收益示例计算:
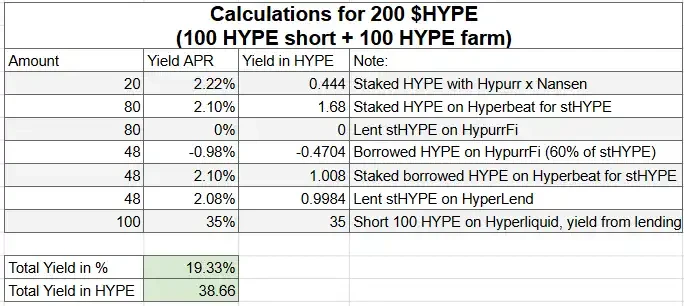
步骤 3 :获取更多积分的玩法
从 @hlnames 购买了几个 .hl 域名
在 @drip__trade 上获得了一个 @HypioHL NFT
在 @HypurrFi 和 @hyperlendx 上提供了 UBTC + UETH(在资金费用为正时对冲,约 11% 年化收益率+)
我还在生态系统中使用了稳定币:
在 HLP(Hyperliquid → Vaults → Protocol Vaults)中使用 USDC
在 @HypurrFi 和 @felixprotocol 上借出 USDT 0
在 @HyperSwapX 上提供 USDT 0/feUSD 流动性对(范围极窄,APY 优秀)
在 @felixprotocol 上提供 feUSD
这种配置几乎覆盖了 HyperEVM 的每个垂直领域。
步骤 4 :该配置的收益
Unit 积分
Hyperliquid 积分
Nansen 积分
Hyperbeat 积分
Drip 积分
Hypio 积分
Felix 积分
HypurrFi 积分
HyperSwap 积分
HyperLend 积分
HyperEVM 积分
HL Names 积分
同时,我的资本还能获得 19% 以上的年化收益率。
其中一些积分系统已确认,其他则是推测性的。我在全面下注。
步骤 5 :隐藏玩法
目前,HyperEVM 上的大多数协议只有 5 千到 1 万用户。这和 Jito 空投前的用户规模相当。
如果你看到这篇文章,你很可能属于前 1% 的早期参与者。
但有几个玩法能带来更高的不对称回报。我重点关注以下两个:
@hyperunit
@prjx_hl
先说 Unit。
这可能是整个 HyperEVM 生态中最被低估的协议。它已经上线,无代币,默默无闻。
但如果他们能实现目标——将现实世界的股票上链——然后推出代币?这可能轻松成为十亿美元级别的空投。
我对空投公式的猜测是:
空投 =(持有 Unit 资产 × 持有时间)+(跨链交易量 × 系数)
所以我早早跨链,跨链规模大,
然后让资产静静地留在现货 HL、流动性池或借贷市场中。
再说 Project X。目前它还是个黑箱,但……
这个团队在 InfoFi 浪潮还未命名时就已推动其发展,还给参与者空投了大量 $$$。
是的,他们在预发布时已经有些热度,但我仍然认为现在还早。
这正是我想参与的原因。
这就是我的配置。
Delta 中性,资本高效。在赚取收益的同时,积累无人关注的积分。大多数人在等待下一个大空投。我已经为它做好了准备。
如果我错了?我依然有回报。
如果我对了?你会在链上看到结果。
P.S. 我与这些协议没有任何关联,也未收到任何报酬。请 DYOR。





