要点:
包装资产提升了代币在不同区块链之间的实用性和互操作性,帮助保持流动性并促进去中心化金融(DeFi)的活动。
WBTC是目前最大的包装资产之一,市值约为90亿美元。其供应量为15.4万,占比特币(BTC)当前供应量的0.8%,占以太坊智能合约中供应量的67%。
BitGo计划将WBTC托管权转移至与BiT Global的多司法管辖区合资企业,其中涉及了Justin Sun和Tron,已引发了一些担忧,促使DeFi进行风险缓解并引入新解决方案。
简介
随着加密生态系统的可服务市场的扩展,将各种价值和资产代币化的需求也在增长。如今,这类资产不仅包括纯数字资产如比特币(BTC),还包括代币化的基础资产,从加密货币(如BTC、ETH)到法定货币(如美元),以及现在的传统金融工具如政府证券。这催生了一系列领域,如包装资产、稳定币和代币化公共证券,增强了加密资产的互操作性和实用性。
在本期的Coin Metrics“网络状态”中,我们将包装和代币化资产在加密生态系统中的角色置于背景下,并聚焦于即将从BitGo重组托管的包装比特币(WBTC)。
代币化与包装资产的世界
代币化资产的世界已经大幅扩展,涵盖包装资产、稳定币和现实世界资产(RWAs)。虽然用途不同,但这些资产都可以归入代币化资产的大类中,因为它们都有代表不同基础资产价值的共同特点。
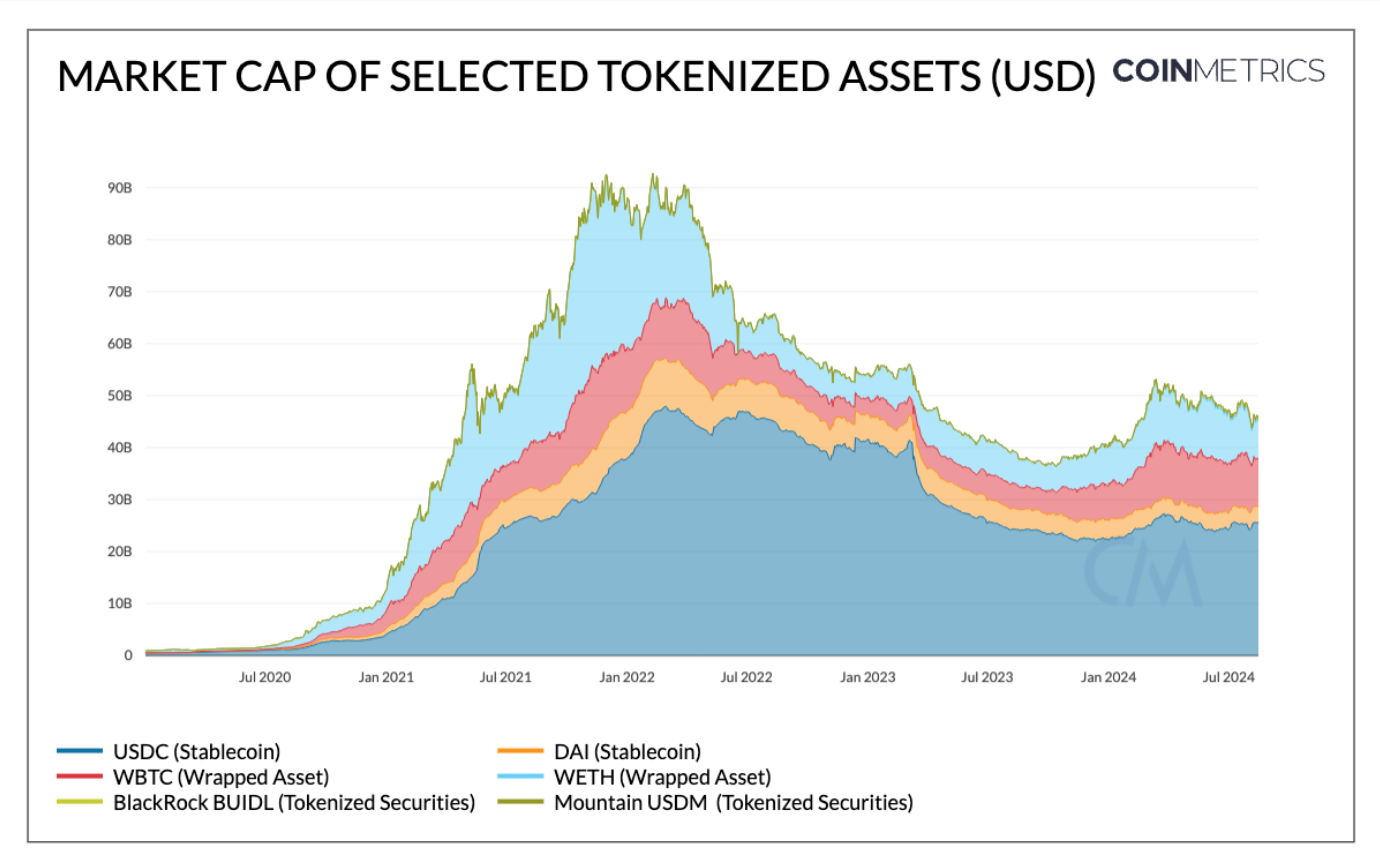
Source: Coin Metrics Network Data Pro
**Wrapped Assets: **
包装资产是代表其他加密货币价值的代币,允许在区块链网络之间进行互操作。例如,包装比特币(WBTC)是一种ERC-20代币,代表比特币,使持有者能够在以太坊生态系统中使用它。该类别还包括包装以太币(WETH)、包装的流动质押以太币(wstETH)等。WBTC和WETH是今天最大的包装资产,市值分别为91亿美元和76亿美元。
Source: Coin Metrics Network Data Pro
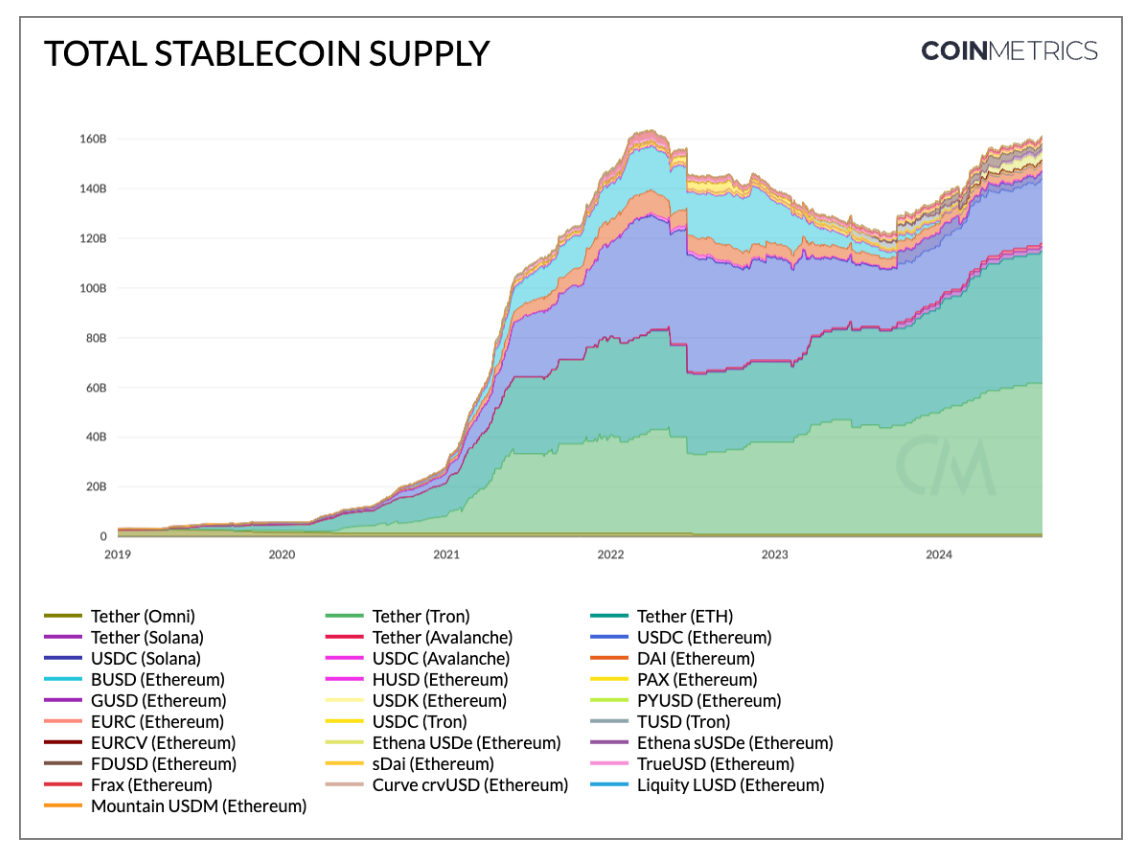
**稳定币:**稳定币将法定货币如美元或欧元代币化,或者在某些情况下,将加密货币和传统资产的组合进行代币化。例如,USDT和USDC与美元挂钩,每种稳定币由发行人储备中持有的现金等价物资产支持,以保持1:1的价值比例。我们已经看到了各种稳定币类别的出现,从法定支持到加密货币支持的等等,USDT和USDC的总市值约为1480亿美元。
Source: Coin Metrics Network Data Pro
**代币化RWAs:**
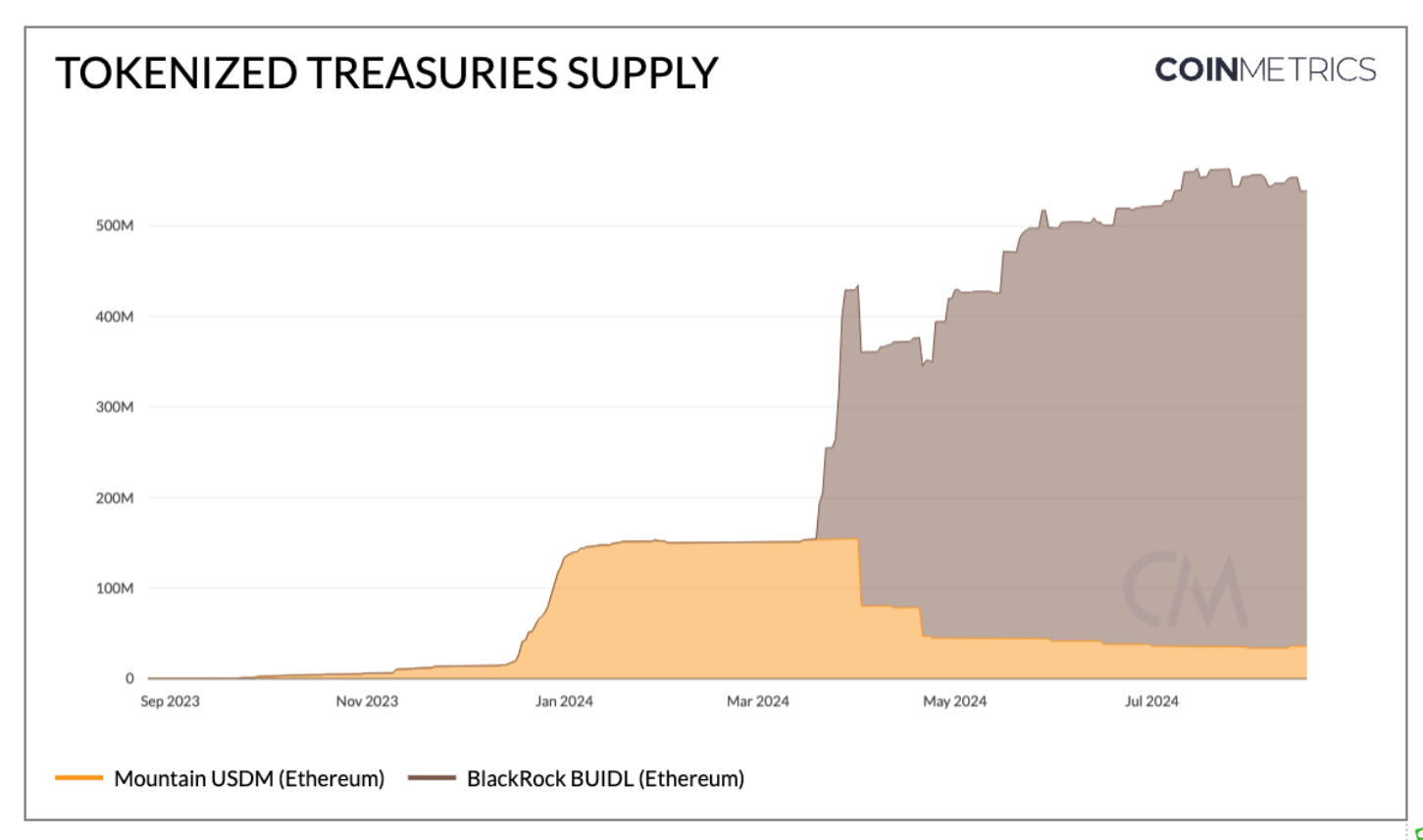
虽然相对较新,但代币化资产包括超越加密货币的一系列RWAs,如国债、私人信贷、大宗商品等。例如,BlackRock最近推出的USD Institutional Liquidity Fund(BUIDL)代币化了现金、回购协议和各种期限的美国国债,为合格投资者提供了传统投资机会的途径,并增强了传统市场的流动性。BUIDL是该类别中最大的,估计市值为5.17亿美元。
The Mechanics of Wrapped Bitcoin (WBTC)
包装资产通过在其原生区块链上锁定一种加密货币,并在另一区块链上发行等价的代币来创建。这个过程涉及各种模型,从使用托管人和商家的集中化方法,到利用直接智能合约交互或参与者网络的相对更无许可的解决方案,以减少潜在的故障点。
WBTC是一个由REN、Kyber和BitGo于2019年发起的联合项目。WBTC使用去中心化自治组织(DAO)来管理托管人和商家的增减,由多签名合约密钥的持有者控制。BitGo作为WBTC的主要托管人,负责托管支持WBTC代币的比特币,而商家则作为中介,促进WBTC的铸造和销毁。
商家将比特币(BTC)锁定在BitGo中,启动WBTC的铸造过程。WBTC以ERC-20代币的形式在以太坊账户中表示,并具有1:1的支持。这使得比特币可以在以太坊上的产品和服务(如去中心化金融DeFi)中使用,而不会影响BTC的流动性。原始的BTC也可以通过将WBTC返回到托管方的以太坊账户进行赎回,随后WBTC将从流通中销毁。
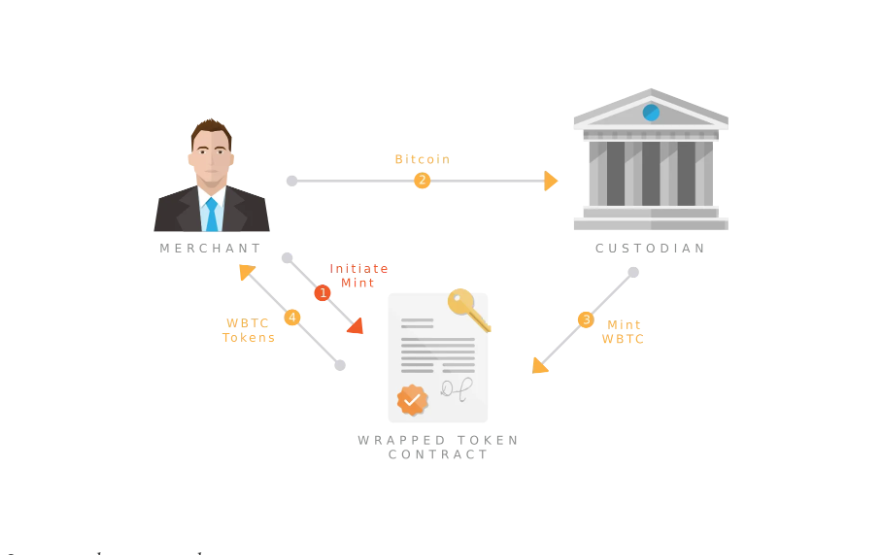
尽管目前存在多种比特币包装解决方案,各有优劣,但WBTC的托管模式已成为最广泛采用的方案。目前,有15.4万枚比特币(价值约90亿美元)被托管,且9.8万个以太坊地址持有正余额的WBTC。
WBTC的托管转移与BitGo的收入模式
8月9日,BitGo宣布计划通过与BiT Global的合资企业重组WBTC的管理,过渡期为60天。新结构旨在实现托管和冷存储的多司法管辖区多元化,从当前的美国模式扩展到包括香港和新加坡。值得注意的是,该合资企业将与Justin Sun和Tron生态系统密切集成,通过将多签名合约的3个私钥中的2个交给BiT Global,影响WBTC的管理。
BitGo传统上通过对WBTC铸造和销毁操作收取费用来赚取收入。此费用通常为0.4%至0.5%,根据交易规模和市场条件而变化。这些操作可以在WBTC的订单簿和区块浏览器上透明审计。例如,在一笔交易中,作为托管人的BitGo收到了52.17193124 BTC。然而,商家请求的对应铸造交易显示仅铸造了52.08845615 BTC,暗示BitGo收取了约0.16%的费用作为收入。
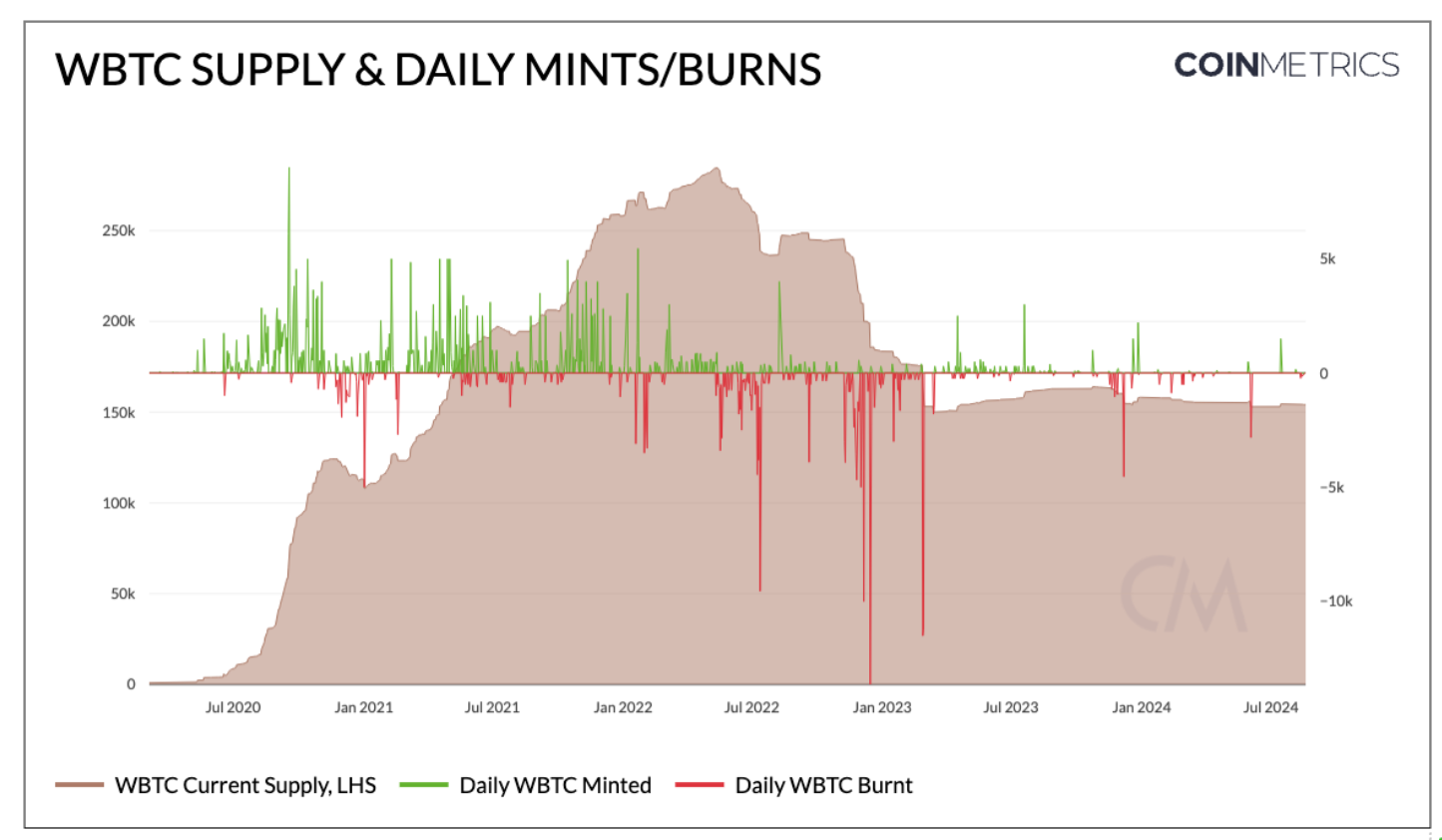
Source: Coin Metrics Network Data Pro
虽然这一重组可能会扩大BitGo在亚洲市场的影响力,但也可能影响其收入模式。与BiT Global共享WBTC的托管责任可能会导致未来费用分配和收集方式的变化。
WBTC在DeFi中的应用:托管变动中的实用性与风险管理
包装资产是去中心化金融(DeFi)生态系统中的重要构件。它们提升了加密货币在不同区块链网络及其应用中的流动性、互操作性和可用性。因此,与BTC相比,WBTC的平均转账金额几乎大7倍,典型的WBTC转账为76,000美元,而BTC为11,000美元。虽然WBTC代表了比特币当前供应量的约0.8%(1970万),但其中的大部分,大约67%的供应量存在于基于以太坊的智能合约中,证明了其在DeFi中的应用。
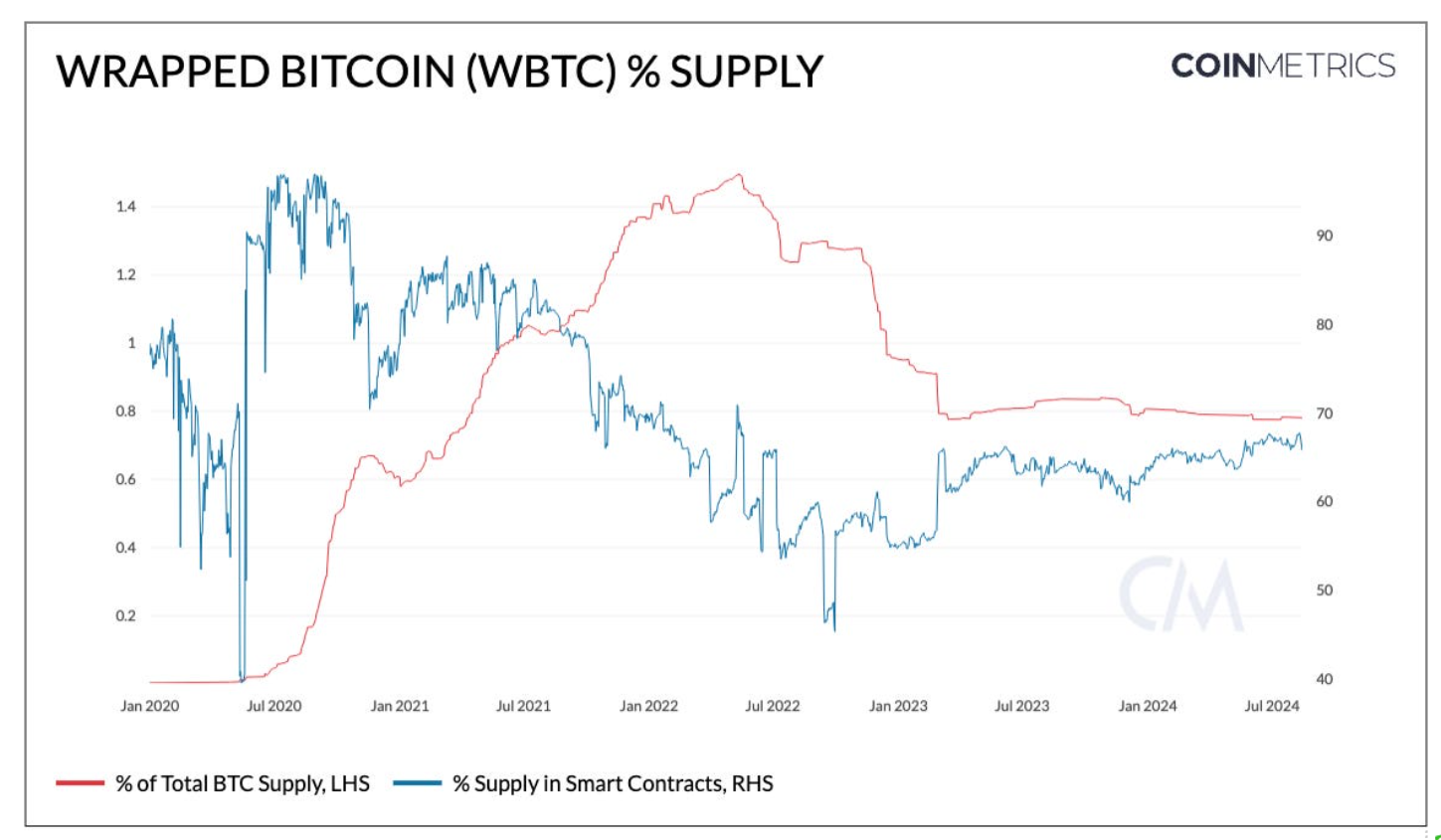
Source: Coin Metrics Network Data Pro
WBTC与其他包装和衍生资产一起,被广泛用作DeFi借贷平台上的抵押品,用于借入其他资产或赚取流动性利息,同时也可以在去中心化交易所(DEX)中进行交易。它形成了像Maker、SparkLend和Aave v3等协议的重要收入来源,因为它们对WBTC的债务收取利息。在以太坊上,总计约50,000个包装比特币(当前价值约30亿美元)被用于借贷协议中。
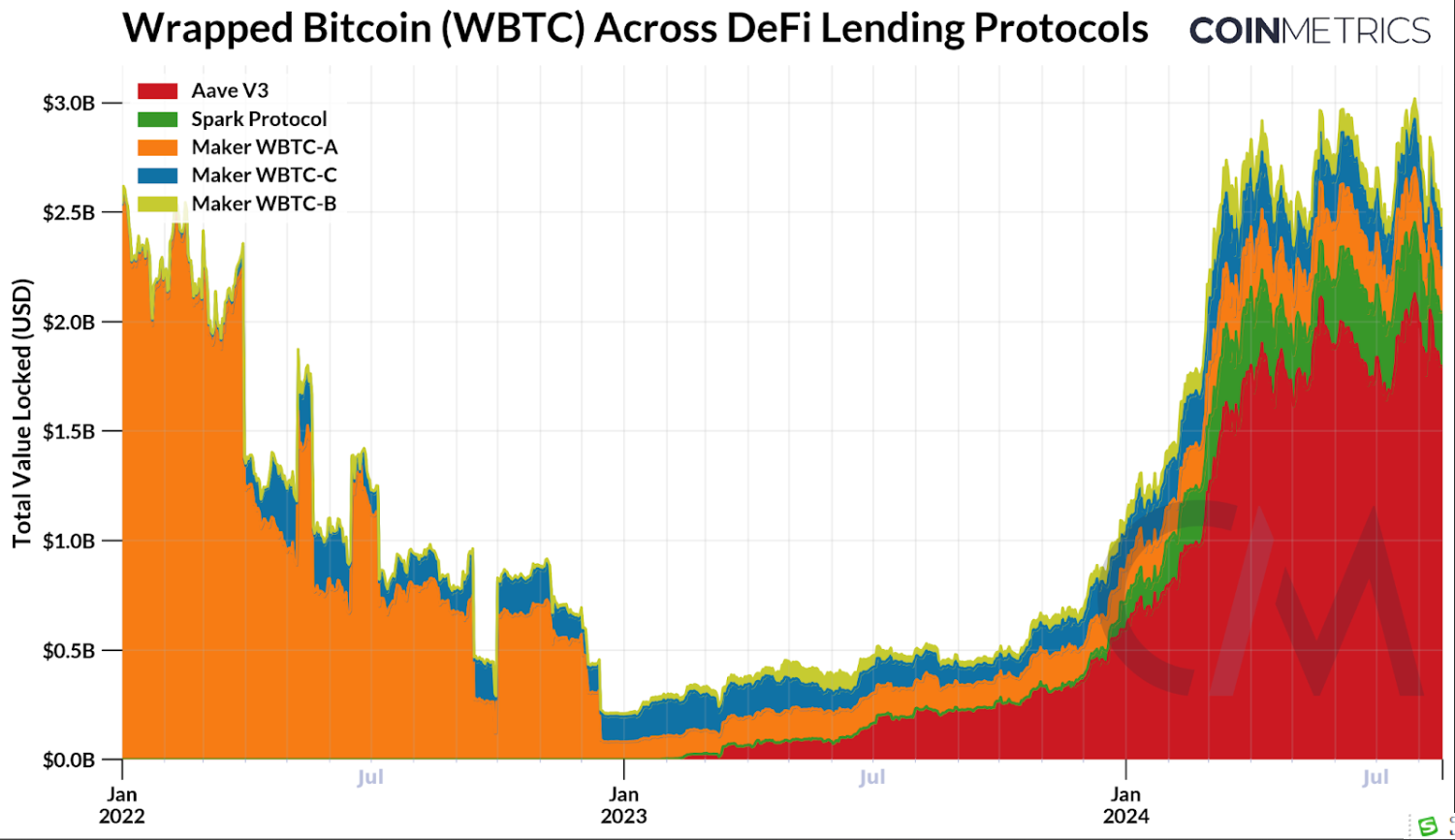
Source: Coin Metrics ATLAS
鉴于WBTC的托管转移,主流DeFi借贷平台的治理机构(DAO)提出了各种风险管理策略,以缓解其生态系统中的风险。Aave DAO决定目前不对其市场做出重大变化。在Aave V3的总市场规模为140亿美元的情况下,约34,000个比特币(约19亿美元)被保存在Aave上,DAO决定不移除WBTC本身,风险管理机构Chaos Labs指出它为协议带来了约600万美元的年化收入。
然而,MakerDAO则采取了更果断的立场。他们执行了一项提案,逐步淘汰WBTC在Maker和SparkLend平台上的使用,旨在降低Dai稳定币的风险。受WBTC新运营结构相关风险的推动,此举导致WBTC金库的债务上限和稳定费发生了变化。因此,用户无法再使用WBTC作为抵押贷款,有效地限制了其在这些协议中的使用。
结论
WBTC的托管重组为实现地理多元化而设立,然而这一变化在整个加密生态系统中引发了担忧。鉴于WBTC在链上生态系统中的重要作用,此转变将托管和运营风险推到了前台,激发了人们对无许可替代方案(如Threshold BTC (tBTC))和新兴参与者(如Coinbase的cbBTC)的兴趣。随着这一变化的影响逐渐显现,DeFi协议和其他利益相关者可能会实施风险缓解措施——特别是在更多种类的代币化资产进入互联链上生态系统之际。
网络数据洞察
摘要亮点
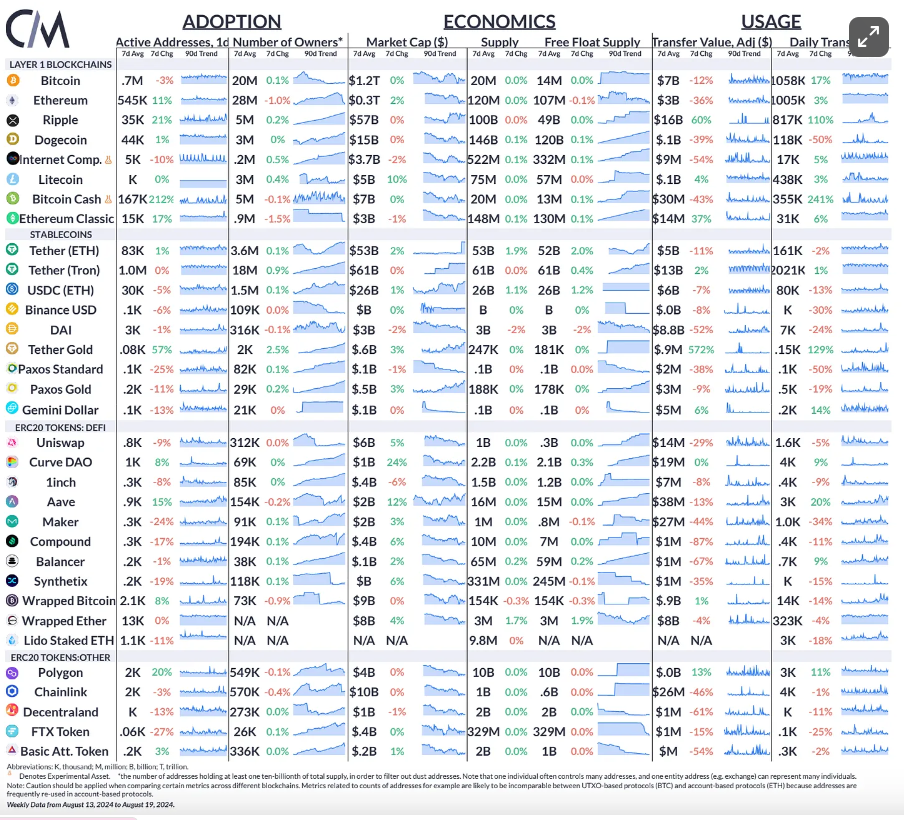
Source: Coin Metrics Network Data Pro
比特币的每日活跃地址减少了3%,而以太坊的活动增加了11%上周。Ripple的转账价值(调整后)增长了60%,转账次数增长了110%,使XRP的价格行动强劲。
Coin Metrics更新
本周Coin Metrics团队的更新:
关注Coin Metrics的“市场状态”通讯,该通讯将每周的加密市场动向置于背景下,提供简洁的评论、丰富的视觉效果和及时的数据。
查看我们对Network Data Pro和ATLAS的稳定币覆盖范围的持续扩展。





