Editor's Note: The future divergence of AI agents does not depend on leaps in model capabilities, but on a more fundamental design variable—where responsibility ultimately falls.
The author argues that "augmenting humans" and "replacing humans" are not two separate technical paths, but two outcomes of the same system under different design choices—when decisions still require human sign-off and responsibility can be traced to a specific individual, AI is an amplifier; when this link is removed (e.g., automatic approval, skipping permissions), the system naturally slides towards replacement.
The article further points out that the real value of AI agents is not "completing the work," but compressing the complex world into a "signable decision unit," allowing humans to understand and bear the consequences. However, in reality, "permission fatigue" leads users to gradually abandon review, moving from approving item-by-item to default consent, ultimately allowing the system to bypass humans. This is a cognitive mechanism, not an individual problem.
Therefore, the article proposes two key constraints: first, every important decision must correspond to a specific, refusable person; second, whoever benefits from the agent's autonomy must be responsible when problems arise.
Once responsibility returns to the builders, the system's default logic changes. Under this framework, the business narrative of AI is also rewritten. Rather than a market for a few giants "replacing half the jobs," it becomes a distributed tool market "amplifying human productivity," whose scale is anchored to the roughly $40 trillion global knowledge labor income, not enterprise software spending.
Ultimately, the article converges the question into an extremely simple but sharp choice: is AI meant to serve humans, or is it an end in itself—and this answer is being quietly decided by every product design detail.
The following is the original text:
TL;DR
· The "augmented future" and the "replacement future" use the same models and the same tools. What truly distinguishes them is a design choice about "who ultimately bears the consequences."
· The agent's real job is not to complete tasks for people, but to compress the complex world into a minimal and faithful "decidable unit" on which someone can sign their name and take responsibility. If this compression is done correctly, everything else falls into place.
· And this "someone" must be a specific individual who can be clearly identified. Vague, generalized responsibility quickly breaks down under high load. Therefore, every action with real consequences must be traceable to one specific person with real power to refuse.
· "Permission fatigue" will cause agent systems to spontaneously slide towards "replacing humans" along their own evolutionary path. Therefore, the "augmented future" is not the default; it must be consciously designed to counter this trend.
· If you build an agent and profit from its autonomy, then you should also bear responsibility when that autonomy causes problems. Once the cost truly falls on the builder, the entire system's default behavior will change accordingly.
· The market formed under this premise that "humans must still be responsible" is likely an order of magnitude larger than the current heavily invested narrative of "vertical agents replacing half the jobs," because it is anchored not to enterprise software budgets, but to the total wages of high-skilled labor.

Claude Code offers a parameter called --dangerously-skip-permissions. The naming is honest; the parameter does exactly what it says. An agent running with this parameter enabled is not more capable than one without it; what changes is that a link that originally required a human now bypasses them.
This parameter is itself a confession. It admits that, with exactly the same underlying capabilities, the same system can operate either in "human augmentation" mode or in "quietly replacing humans" mode. The so-called replacement mode doesn't require a different model; it just requires moving the "consent" step aside.
This is the argument compressed. In the most capable agent systems being released today, a significant portion of the gap between "augmentation" and "effective replacement" comes from removing approval, not from inventing a new category of capability. Whether the next decade looks more like "a world of augmented humans" or "a world where autonomous agents act on our behalf" depends less on model capabilities and more on whether the people building these systems see "human-in-the-loop" as the core of the system or as friction.
Does AI Augment Humans, or Bypass Them?
Beneath every technical question lies a non-technical one that few are willing to ask openly: Is AI for augmenting humans, or is AI itself the purpose?
These two answers imply truly different futures. The "augmentation" stance holds that value resides in the human themselves, and the agent's job is to make this person go further and make better decisions. The "AI as purpose" stance holds that intelligence in the world itself is the value, and humans are ultimately just an inefficient carrier medium. Most agent products are silently encoding one of these stances, and it's surprising how few founders are directly asked which one they belong to.
Capability design and consent mechanism design are still evolving. This article focuses on the "consent" side because it's a variable builders can actually control today, and because after generative capabilities become cheap, the attributes that retain economic value are those that cannot be stripped from the person: judgment, taste, relationships, responsibility, and the willingness to put one's name to a decision and bear its consequences. Among these, "liability" is the most concrete and the only one with centuries of enforcement infrastructure already in place.
Liability, The Dividing Line Between Augmentation and Replacement
The structural rule that distinguishes an "augmented future" from a "replacement future" can be roughly stated as: Any action performed by an agent that has real-world consequences must be traceable through a documented chain to a specific person—a person who saw the relevant context and genuinely had the opportunity to say "no" to it.
Generalized responsibility quickly fails this test. "The company is responsible" operationally covers nothing specific. "The user clicked agree" did not agree to anything specific. "A human reviewed the process" allows that person to review something completely different from what was finally published. What's really needed is a specific person, a named person, who saw this decision placed before them, had the option to refuse, and chose not to.
This sounds like bureaucracy until you notice the properties that "liability" has which alternatives lack. Capability improvements cannot optimize it away; a smarter model doesn't affect who ultimately gets sued, fined, or jailed. It forces the design interface to expose a "refusal point." It scales naturally with risk. And it is the strongest cross-domain constraint and already has ready-made enforcement infrastructure: courts, insurance agencies, professional boards, regulators. Licensing, fiduciary duty, and industry regulation also work, but they constrain narrower domains and all presume the question of "liability attribution" is already solved.
In contrast, AI-level alternatives cannot pass the same test. "Alignment" is unenforceable; we can't even agree on what it means. "Explainability" can be formally satisfied while being empty in substance. "Human-in-the-loop" has been hollowed out to "a human is somewhere." "Liability" has bite because the enforcement infrastructure underpinning it was built centuries before the tech existed.
Permission Fatigue, Pushing Systems Towards "Replacement"
This gradient pushes systems towards "replacement," and the push is strong. Every permission check consumes attention. Agents are usually right. For any single decision, the expected value of "agreeing without reading" is often positive. So, a rational user learns to click agree faster, then agree in bulk, then turn on auto-approve for a category of actions, then expand to more categories, then flip that dangerous switch for a session, and finally forget the switch exists.
I flipped the switch in my second week using Claude Code and was no longer aware of it by the third. Every developer I know who uses Cursor or Devin long-term has a similar story. The pattern holds for cookie banners, EULAs, TLS warnings, and phone permission requests. Recurring low-risk consent decisions eventually converge to "unconditional consent." This is a cognitive property, not a moral failing.
The "augmented future" won't happen automatically. The default path for an agent system not carefully designed is towards replacement, because users themselves, in their pursuit of convenience, will actively choose the replacement path. The other future must be designed against this gradient.
The Value of an Agent is Not Execution, But Enabling a "Signature"
What is truly valuable about an agent is not doing the work itself, but compressing the work into a form that can be signed off on.
A frontier model can easily write a 4000-line code commit, draft a 30-page contract, generate a clinical note, or execute a trade. But the bottleneck for these outputs to actually have impact isn't "generating them," but whether a human has the capacity to bear the consequences after they land. A code commit no one truly understands becomes a burden once merged; a contract no one read is a ticking time bomb once signed; a clinical note not actually endorsed by a practicing doctor isn't even a valid record in most regulated healthcare systems.
In the "augmentation" framework, the agent does everything except the "signing": reading ten thousand pages of context, writing four thousand lines of code, calculating thirty plausible options, then compressing it all down to a minimal, faithful representation that someone can base a "yes" or "no" decision on, and put their name at the bottom of the document.
Think of the agent as a press secretary. The president does the signing; the secretary's job is to do everything leading up to the signature.
This is actually a harder engineering problem than "having the system do the work autonomously." The capability to generate content is advancing rapidly, but the capability to "faithfully compress a decision" is far behind. The teams that will win in an "augmentation market" are those that can provide the shortest, most faithful decision summary for high-liability risk scenarios.
The truly unsolved problem in that sentence is the word "faithful." A summary a human can read is only valuable if the compression process did not distort the information. Whether this can be verified programmatically is the truly difficult technical problem in the "augmented future," and most aren't even seriously facing it yet.
Some basic approaches are emerging:
Confirming human understanding aligns with original content via paraphrase tests
Forcing the presentation of minority or dissenting opinions in summaries
Conducting counterfactual tests ("What would this agent do if you refused?"
Reproducibility checks (Can another agent generate the same summary from the same context?)
These are far from solved. And the teams that solve them first will build a moat that won't be easily eroded by model capability improvements.
Establishing a Liability Tier for AI Actions
If "liability" plays a structural role, then every action performed by an agent should come with a "liability tier" that determines the minimum signing mechanism required for that action.
Currently, such a standard system has not been widely established—but it probably should be.
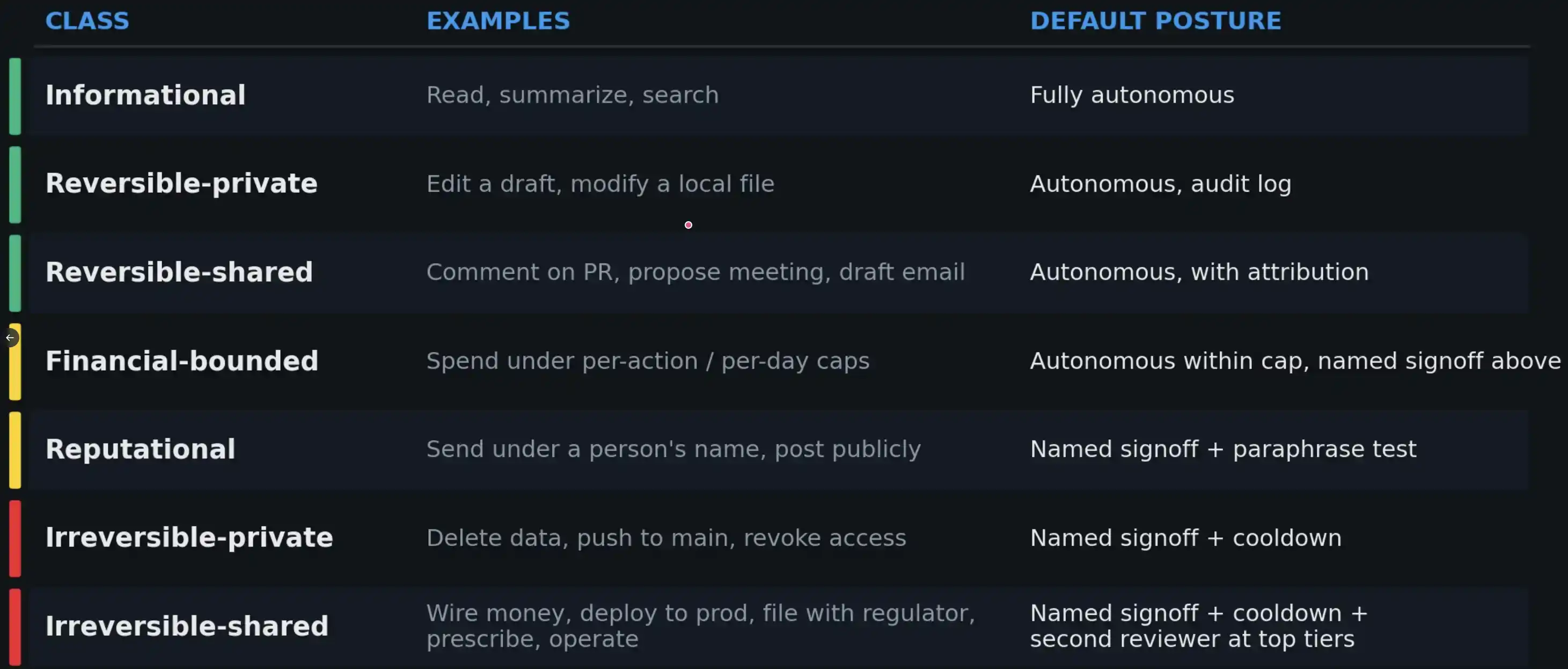
A "approval posture" that matches the consequences is the only realistic path to managing permission fatigue. At higher risk tiers, more constrained positive engagement mechanisms need to be added (e.g., paraphrase tests, cooldown periods, second reviewer), because in these scenarios, the real failure mode is not the agent suggesting wrong, but the human approving without thinking.
Do You Care?
All the above questions ultimately point to a fundamental question at the founder level: Do you care whether humans remain a part of this future? Many design decisions in current agent products are essentially a "silent vote" on this question, just that the voters are often unwilling to admit they are making a choice.
If you care, then the design constraints are not vague: You need to build liability tiering systems; design "refusal" as a first-class feature; the metric should be the quality of the summary the agent gives the human, not the degree of autonomy it achieves in completing tasks无人干预; you need to bind every action with real consequences to a specific person in a tamper-evident log.
This technical work itself is realistic and feasible. The real difficulty is the willingness to do it—because the "augmentation" build path is less dazzling in demos and less aggressive in per-seat economics than the alternative path.
The Anthropic Paradox: Most Emphasized on Safety, Yet Easiest to Bypass Humans
Anthropic is a very typical case study in how "endogenous drift" happens in this field. Not because it is particularly negligent, but precisely because its articulation on safety is the clearest, making the gap between "framework" and "product surface" most visible. Its "Responsible Scaling Policy" and "Constitutional AI" work primarily constrain model behavior during training; but the default autonomy settings for agents built on these models belong to another policy system, and that convenient "dangerous switch" is just one keystroke away from being enabled from the default state.
This pattern exists in most mainstream coding agents, but Anthropic's case is the easiest to observe clearly. This is the so-called "Anthropic Paradox": the lab that most clearly writes down safety frameworks also provides the shortest path from "augmentation" to "replacement," and we can see the latter precisely because the former is so clear.
To be fair, they launched "auto mode" in March as an intermediate path between manual approval and the dangerous switch. In this mode, each action is reviewed by a Sonnet 4.6 classifier before execution. They directly identified the problem in their official note—calling it "approval fatigue"—and provided a data point: users accept 93% of prompts in manual mode. This is essentially a quantification of "permission fatigue." This assessment is consistent with the analysis in this article.
But on the solution path, I would offer a different perspective. "Auto mode" replaces human approval with model approval, meaning the gradient "sliding towards replacement" isn't terminated, just moved up one level. The classifier can indeed block dangerous behavior, but for the behaviors it allows, no specific person is actually taking responsibility. Anthropic itself acknowledges that "auto mode" does not eliminate risk and advises users to run it in a sandbox—in other words, the question of "liability attribution" remains unanswered.
An obvious objection is: if the ultimate responsibility falls on an individual, isn't that just manual mode? And manual mode is precisely what gets broken by fatigue. The reason "placing responsibility on the builder" escapes this gradient is that it changes who bears the cost of "over-approval." Under the current structure, the user pays the cost for each careful review, and the builder bears none, so the default settings lean towards reducing user friction and externalizing risk. Once the cost of "unreviewed actions" is transferred to the builder, the entire calculus reverses: the builder has a direct economic incentive to design liability tiers, paraphrase tests, and approval mechanisms that make the signing cost lower for low-risk decisions and higher for high-risk ones. The gradient doesn't disappear, but its direction changes. No major lab, including the one closest to realizing the problem, has truly practiced this yet.
If You Build the Agent, You Should Bear the Responsibility
If the explicit purpose of an agent is to replace a human in performing actions previously done by a person, then the company that builds and operates this agent should bear the same responsibility as the human would have. This principle is not radical; it already applies to all industries that "produce actions in the real world": Toyota is responsible for brakes, Boeing for flight control systems, Pfizer for drugs, bridge engineers for bridges, doctors for prescriptions. This liability model exists in almost all legal systems.
However, AI currently enjoys a kind of "implicit exemption." Model providers claim they are merely tool suppliers; application layer companies claim they are just thin wrappers around models; users waive all liability upfront through arbitration clauses. When agent systems fail catastrophically (e.g., the Air Canada chatbot case, the Replit production database deletion incident, or something akin to the 2012 Knight Capital trading glitch that lost $440 million in 45 minutes), the loss ultimately falls on the party least able to bear it—the user. This allocation of responsibility will not survive the first truly "monetary, documented" major incident.
The solution is simple to state: Whoever builds the agent and profits from its autonomy should bear the consequences when it goes wrong. Once liability truly falls on the builder, permission prompts are no longer seen as "friction" but as "insurance." That dangerous switch would be renamed, and the default settings would change accordingly.
Willingness to take responsibility for one's own system is what distinguishes a real industry from an "extractive industry."
Regulation as a "Steering Mechanism"
The market itself will not naturally move towards an "augmented future." What actually steers are often regulators and insurance underwriters, and viewed overall, this is not necessarily a bad thing.
Europe will likely be the earliest regulatory channel. The EU has a clear precedent for setting rules (like GDPR, the AI Act, DMA), and its rules often become de facto global defaults because the cost of maintaining a separate product for non-EU markets is usually higher than just complying with European standards. A baseline requiring "all actions with real consequences must be confirmed by a named human with the power to refuse" is closer to a car crash test standard than an impediment to technological progress.
A more direct push will come from the insurance industry. Underwriters pricing Errors & Omissions (E&O), Directors & Officers (D&O), and cyber insurance must answer the question: When an agent acts with user authorization and causes loss, where does liability fall? The easiest path to a insurable structure is having a named human in the chain. Therefore, systems without this structure will naturally see their insurance premiums reflect higher risk. The window for builders who want to define the rules themselves, rather than having regulators or insurers do it, is not wide.
The Market Logic Obscured by the Mainstream Narrative
The current mainstream narrative holds that: Vertical agents will absorb roughly half the jobs in the industries they touch, and value will concentrate into a handful of vertically integrated agent companies—one "Anthropic" for law, one for medicine, one for accounting. Almost all multi-billion dollar AI financings in the past year and a half are predicated on this assumption in some way. This is the "replacement logic" dressed in business attire, but its judgment about market structure is wrong, and this error directly affects how capital is allocated.
The "augmentation" framework implies a different market shape. If every action with real consequences must ultimately land on a named person, then the unit being sold is not "autonomous agents" but "amplified human capability." The doctor who can handle three times the caseload with higher accuracy is the buyer; likewise, the lawyer covering ten times the transaction flow, the engineer delivering at five times the speed, and the accountants, underwriters, analysts, architects, surgeons, teachers, loan officers, journalists, and pharmacists behind them are all buyers.
This market is larger because it relies on distribution at scale, not centralization. The rational valuation anchor should not be enterprise software budgets, but the total wages of the labor being "amplified." Global enterprise IT spending is around $4 trillion annually (Gartner data); the total compensation for global skilled, credentialed, and knowledge workers is roughly an order of magnitude higher, around $40 trillion (estimated based on ILO data, excluding low-skill segments). AI companies won't capture the entire wage pool, but they can capture a portion of the productivity gains. Even capturing a single-digit percentage share would support a market the size of today's entire enterprise software market, and this is the floor, not the ceiling. The ultimate size of the market depends on a key design decision: where responsibility ultimately falls.
The eventual winners will look more like tools than replacements, priced based on "the amplified person," not "the replaced job"; they will embed into existing professional workflows, not replace them; there will be thousands of them, not a handful. The final shape of this market is closer to SaaS than cloud infrastructure. We are still in the very early stages of the deployment curve; common adoption curves, on a timeline that will extend another decade, are just the leftmost few pixels. And the shape of these "pixels" is being determined by design choices in a small set of products right now.
The Choice: Keep Humans Responsible, or Make Them Disappear?
Keeping humans responsible forces system architecture to revolve around "augmenting humans"; once people are removed from the liability chain, the system defaults to sliding towards "replacement," even if everyone present, if asked explicitly, might not choose this outcome.
The real question is not whether some actions should be fully automated—the framework above already acknowledges this, e.g., pure information retrieval operations can be automated. The key is how this boundary moves as risk escalates, and who decides it. In the most advanced agent systems today, the path from "augmentation" to "effective replacement" is exceptionally short, often just a parameter switch or a default setting away. The real work is ensuring this switch is always treated as a "dangerous option," not gradually made the default driven by convenience.
If builders do this work proactively, we transition relatively smoothly into an "augmented future"; if they don't, regulators and insurance underwriters will do it for them, and the outcome will also lead there.
Whether you care is a design choice. And this choice determines what you are building. Every founder launching an agent product today must publicly answer a question they seem reluctant to face: Are you building augmentation, or replacement?






