As is well known, training large models is extremely costly.
However, it's also widely understood that reducing training precision can significantly lower training costs. DeepSeek-V3's use of FP8 training brought the cost down to $5.6 million, already capturing the attention of the entire industry.
Following the success of FP8, the industry continues to explore the boundaries of lower precision: from FP8 down to FP4, how much more can training costs be reduced?
Theoretically, FP4 computational throughput could be twice that of FP8. Both NVIDIA's Blackwell and AMD's MI350 series have already natively supported FP4 operations at the hardware level, with the former claiming FP4 performance up to 4500 TOPS (sparse) on the B200. The hardware is ready, but the software and algorithm side has been stuck on one problem:
Training large models from scratch with FP4 is highly unstable.
Over the past two years, works like LLM-FP4 and NVFP4 pre-training have attempted this path, but few solutions have cleanly and efficiently executed full pipeline pre-training at 4-bit precision while maintaining convergence quality close to FP8.
More troublesome is that the cause of the collapse has been unclear. Analysis suggested the instability in FP4 training was likely due to insufficient randomness.
But recently, AMD, in collaboration with Pennsylvania State University, published a paper that overturns this traditional understanding, offering a new and clear diagnosis for native FP4 training.

- Paper Title: Pretraining large language models with MXFP4 on Native FP4 Hardware
- Paper Link: https://arxiv.org/abs/2605.09825
This paper successfully completed the full-pipeline pre-training of Llama 3.1-8B using the MXFP4 format on AMD Instinct MI355X GPUs, achieving 9-10% faster end-to-end training speed compared to the FP8 baseline, with only an 8-9% additional token cost. This is the first complete experiment to finish large model pre-training on native FP4 hardware (not software simulation).
More importantly, the paper reveals the core issue: The source of FP4 training instability is not insufficient randomness, but the cumulative amplification of structural microscaling errors along sensitive gradient paths.
What is MXFP4
Before dissecting the paper, it's necessary to understand the MXFP4 data format.
Traditional integer quantization typically uses a single scaling factor for an entire tensor. The core design of MXFP4 is called "Micro-scaling": splitting a tensor into small blocks (e.g., groups of 32 elements), assigning a shared exponent (E8M0 format) to each block, where each element within the block is represented by a 4-bit floating-point number. The reconstruction formula can be written as:
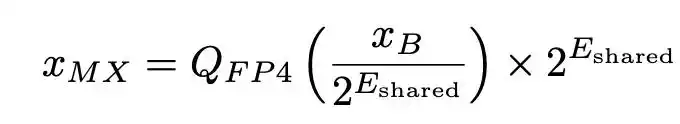
Where E_shared is the maximum exponent within the block, and Q_FP4 is the value rounded to the nearest representable 4-bit floating-point value.
The benefit of micro-scaling is that each small block has its own dynamic range and won't be "held hostage" by global outliers. This significantly improves the representational quality of 4-bit floating-point numbers compared to naive global quantization.
However, even with micro-scaling, FP4 training remains unstable.
Troubleshooting Experiments: The Root of Instability
The research team first designed a step-by-step controlled troubleshooting experiment.
A complete Transformer linear layer computation involves three general matrix multiplication operations:
Fprop (Forward Propagation): Computes Y = XW^T, producing activation values.
Dgrad (Activation Gradient): Computes ∇X = ∇Y · W, propagating gradients back to the input.
Wgrad (Weight Gradient): Computes ∇W = (∇Y)^T · X, producing the gradient used to update the weights.
Keeping all other factors constant, the research team gradually replaced these three operations from FP8 to MXFP4, observing the impact of each step on convergence. All experiments were executed using native FP4 tensor cores on AMD Instinct MI355X, without relying on software simulation.
The training task followed the MLPerf standard setup, pre-training Llama 3.1-8B on the C4 dataset, with a convergence target of achieving a validation perplexity of 3.3.
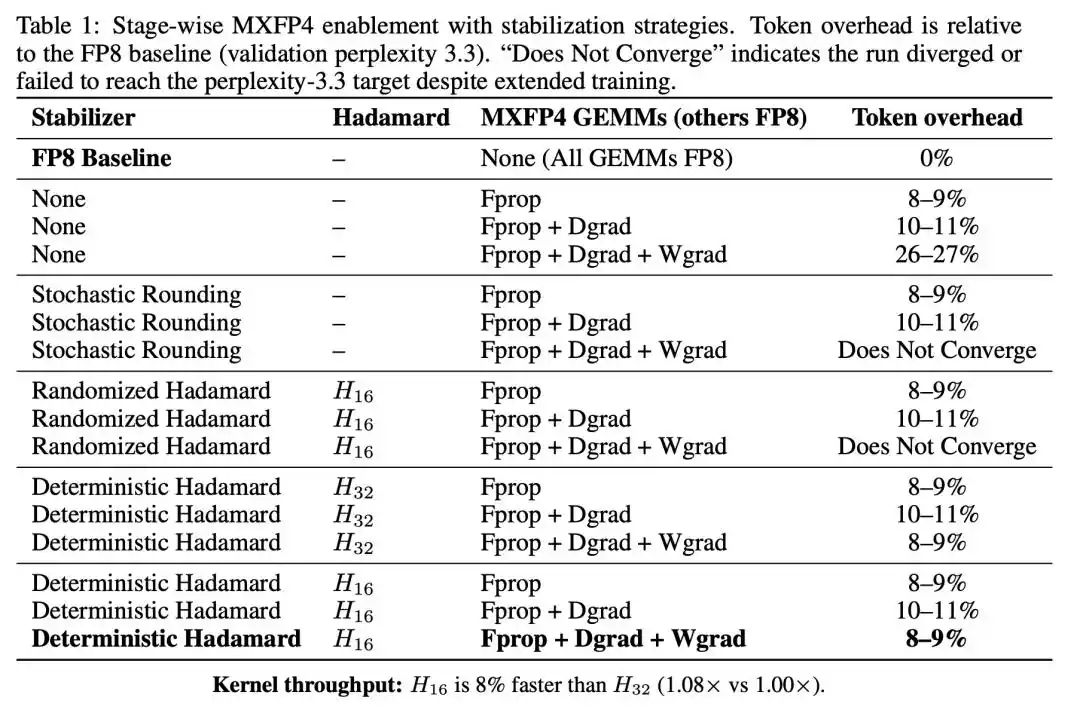
The first two steps only incurred a modest additional token cost. However, once Wgrad was also switched to MXFP4, the cost directly jumped to 26-27%.
Wgrad is the bottleneck for FP4 training. Forward propagation and activation gradient have considerable tolerance for FP4 quantization, but once the weight gradient is quantized to 4 bits, convergence quality degrades significantly.
The industry's prevailing intuition was that FP4 quantization error is essentially a noise problem, which could be "smoothed" by injecting randomness. Two common strategies are:
Stochastic Rounding: Introduces randomness during quantization to make the expected value of rounding error zero.
Randomized Hadamard Rotation: Uses a Hadamard transform with random sign flips to scatter the data distribution before quantization.
When Wgrad is quantized, both randomness strategies not only failed to stabilize training but directly caused non-convergence. Randomness didn't help; instead, it introduced more effective quantization error on the critical gradient path.
In contrast, deterministic Hadamard rotation dramatically reduced the full-pipeline token cost from 26-27% back to 8-9%, with the training trajectory closely tracking the FP8 baseline.
This is a highly diagnostic result. Both random and deterministic Hadamard rotations are orthogonal transformations that can scatter outlier energy distribution; theoretically, their effects on mitigating quantization error should be similar. Yet, their performance in the Wgrad scenario is completely opposite, revealing the nature of the problem:
FP4 training instability is driven by structural errors generated by MXFP4 micro-scaling on sensitive gradient paths. Randomness strategies failed because they introduced varying error patterns at each step, and these changing patterns accumulated along the gradient path, amplifying instability. Deterministic rotation was effective precisely because it applied the same transformation at every step, keeping the error pattern consistent and preventing error accumulation.
End-to-End Efficiency: Training Step Throughput +20%, Comprehensive Speedup 9-10%
After applying deterministic Hadamard rotation to the full-pipeline MXFP4, the efficiency data is as follows:

Training step throughput increased by 20%. After accounting for the additional 8-9% token cost, the end-to-end comprehensive speedup remains 9-10%.
Considering this directly halves precision from 8 bits to 4 bits, this convergence quality and speedup magnitude are quite significant.
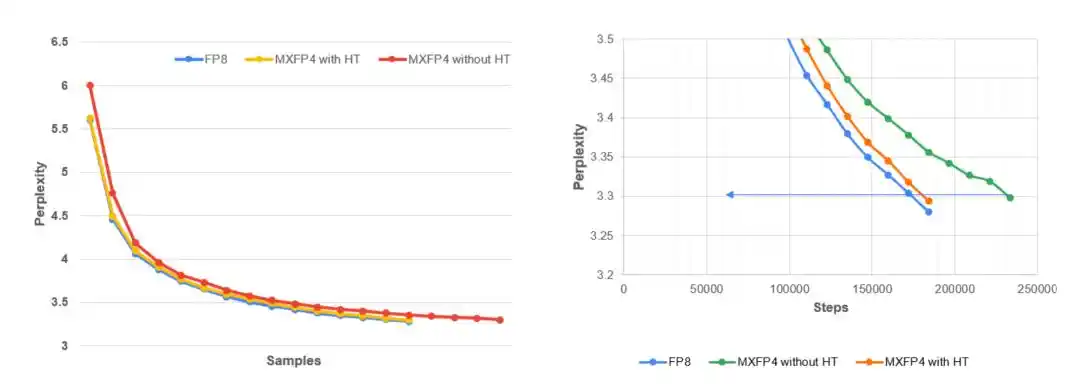
Left: Curve showing the validation perplexity of Llama 3.1–8B versus training token count during MLPerf pre-training on the C4 dataset. Results show MXFP4 + deterministic Hadamard performs very close to FP8, while unstabilized full-pipeline MXFP4 converges slower and is less stable. Right: Zoomed-in view of the later training stage. The MLPerf target perplexity is 3.3. Compared to the unstabilized MXFP4 run, deterministic Hadamard (H16) maintains much tighter alignment with the FP8 baseline.
Notably, the authors explicitly emphasize an important limitation in the paper: The effectiveness of this FP4 training scheme (MLPerf C4 dataset + Llama 3.1-8B) has been verified, but it cannot be assumed to seamlessly transfer to all models, all datasets, and all training methods. FP4 training behavior might be highly setting-dependent, and specific stabilization strategies need re-validation per scenario.
Conclusion
Placing this paper within the broader industry context reveals at least three layers of significance.
First layer: It answers a fundamental "why". Previous FP4 training work mostly focused on "how to make it not crash." This paper provides the first clear causal diagnosis: collapse stems from structural microscaling errors on the Wgrad path, not insufficient randomness. This diagnosis itself holds methodological value, telling subsequent researchers that when encountering instability in low-precision training, they should prioritize investigating structural error sources rather than blindly adding randomness.
Second layer: It pushes FP4 from "inference-only" towards "usable for training". Previously, the industry consensus was that FP4 was only suitable for inference quantization, with FP8 being the minimum for training. NVIDIA's emphasis on FP4 inference rather than training on Blackwell also reflects this judgment. This paper successfully ran full-pipeline pre-training on native FP4 hardware, meaning that the FP4 compute power prepared for inference on MI355X and Blackwell could theoretically also be used for training. If FP4 training proves viable on larger models and more scenarios, it effectively doubles the usable training compute of existing hardware.
Third layer: It utilizes the OCP open standard. MXFP4 is part of the OCP Microscaling format standard, jointly supported by seven companies: AMD, NVIDIA, Intel, Meta, Microsoft, Arm, and Qualcomm. Basing on an open standard means this method has portability across different vendors' hardware and won't be locked into a single ecosystem.
From FP16 to FP8, DeepSeek-V3 has already proven that halving precision can dramatically reduce training costs. From FP8 to FP4, this paper takes the critical first step. With each slash in precision, the entire economics of large model training are shifting.
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), edited by Leng Mao.







