If we throw AI into an engineering site with no standard answers, can it still survive?
For a long time, AI Agents have appeared omnipotent, but in reality, most are just 'flipping through memories' within known knowledge bases.
Yet the real engineering world is harsh: the stability of underwater robots, the lithium plating boundary of power batteries, the noise control of quantum circuits... These problems have no 'perfect score', only 'optimizations that inch closer to the limit'.
Recently, the Agent Benchmark released by Navers lab under Einsia AI—Frontier-Eng Bench—officially tore off the label of AI being an 'exam-crammer'.

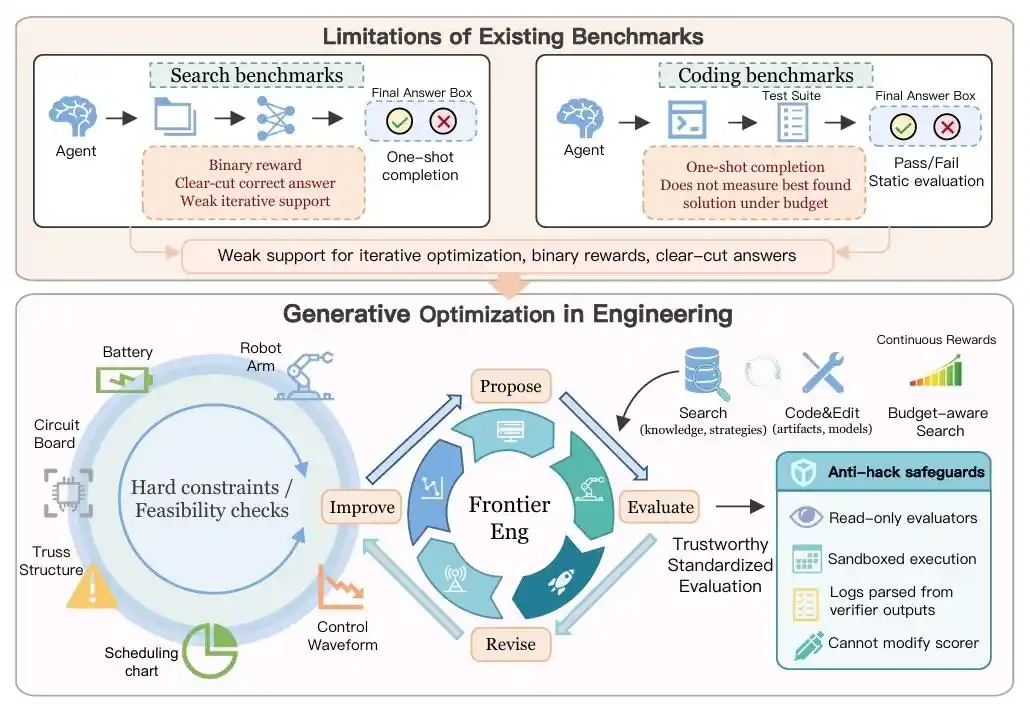
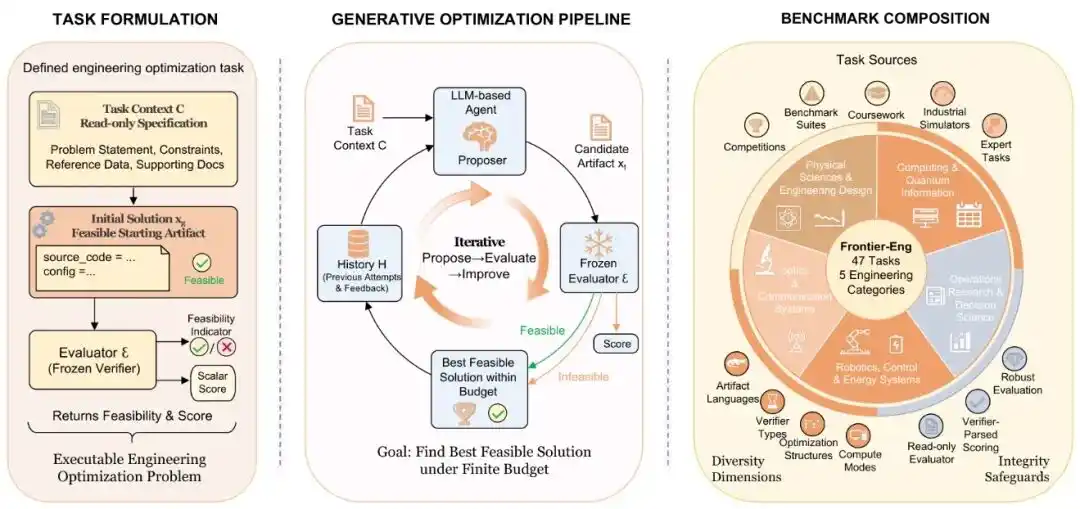
The research team didn't have AI grind through outdated coding problems. Instead, they gave it a complete 'engineering closed loop': propose a solution, connect to the simulator, digest errors, adjust parameters, and re-run.
Faced with 47 hardcore tasks spanning multiple disciplines, AI must behave like a senior engineer, seeking the optimal solution within the 'impossible triangle' of power consumption, safety, and performance.
This is not just a test suite; it's more like a rehearsal for Agent 'evolution'.
When AI begins to learn self-correction from feedback, the Auto Research era, where 'humans set goals and AI iterates non-stop 24/7', might be closer than we imagine.
AI Starts Tackling 'Hard Work'
Past large language models were more like super straight-A students.
You pose a question, it 'flips through memory' from massive training data, then pieces together an answer that seems plausible.
In this mode, the large model is essentially playing 'word chain', not solving real-world problems.
But the emergence of Frontier-Eng Bench has AI doing the work of 'engineering optimization'.
The process has shifted to letting AI first propose a solution, then connect to a simulator to run experiments, subsequently obtain feedback and errors, modify parameters and code, and continue re-running until performance improves further.
In this closed-loop system, AI's identity undergoes a qualitative change.
Want to make the underwater robot more stable? AI must start automatically tuning the controller.
Want to increase the speed of the robotic arm a bit more? AI has to run simulations itself.
To some extent, AIs have shed their purely semantic understanding role and begun to act like professional engineers, continuously optimizing based on real-world environmental feedback.
△
The most interesting aspect of Frontier-Eng Bench is: it doesn't test whether AI 'answered correctly', but rather whether AI can continuously become stronger.
Because real engineering optimization is never about multiple-choice questions; there is no single standard answer.
Take fast-charging batteries as an example: the goal sounds simple—charge as fast as possible, but reality isn't so easy.
Under strict constraints like temperature mustn't spike, voltage can't overspeed, battery life can't drop too fast, and lithium plating must be avoided, AI must precisely hit the balance point of performance.
This means AI cannot pass through by any clever 'test-cramming' tricks; it must demonstrate endurance for continuous evolution through long-term feedback.
Can AI perform long-term optimization in real environments?
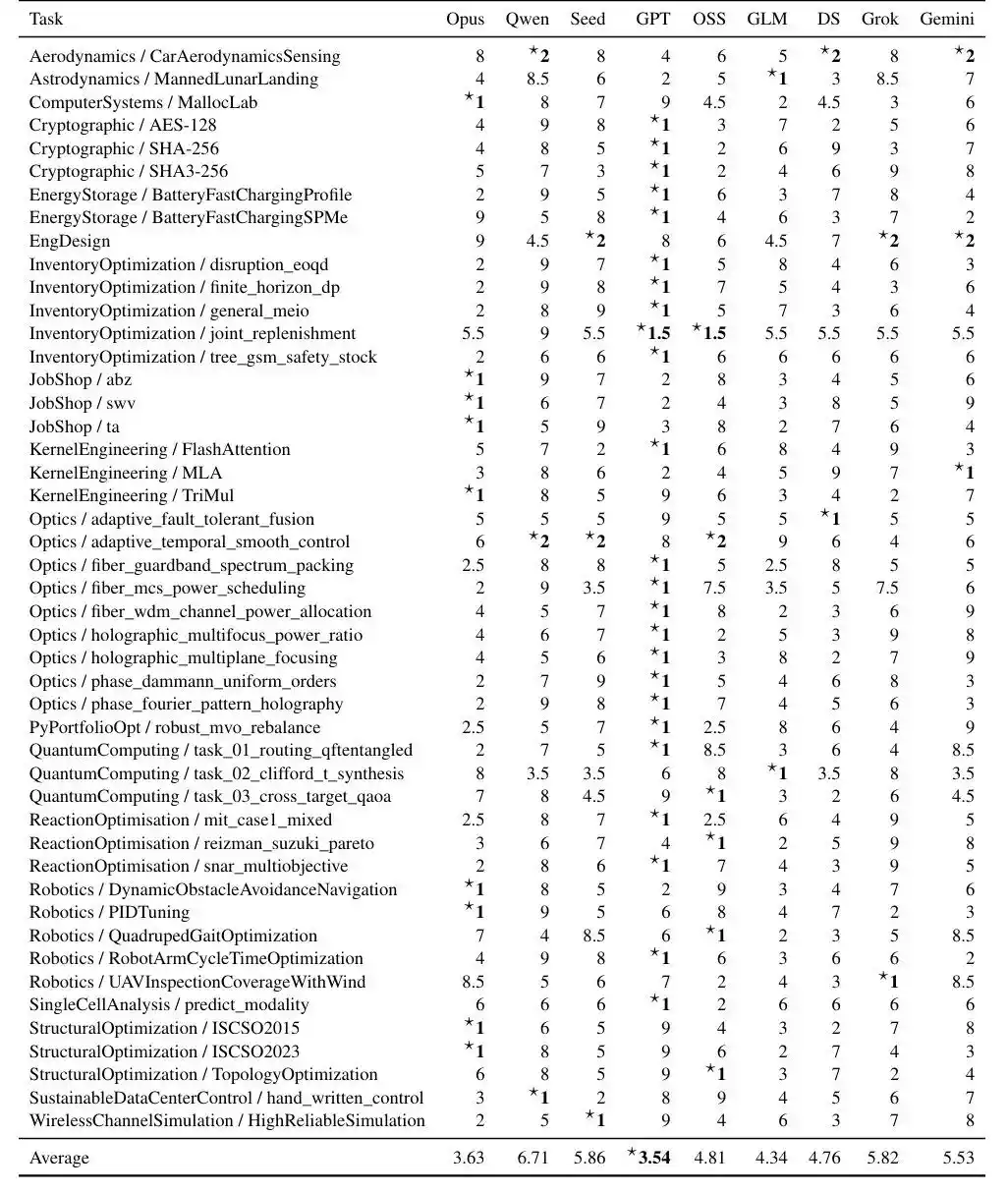
Looking at the results, GPT5.4 showed the most stable overall performance, but AIs still have a long way to go before 'solving' the Benchmark.
△
Auto Research Enters the 'Iterative Optimization' Era
The research team raised a very interesting point in their paper:
Truly advanced intelligence essentially relies on long-term feedback loops.
Just as AlphaGo could defeat Lee Sedol, it lay in the vast number of simulations and immediate feedback behind each decision, not the rote memorization of established game records.
True scientific research is the same: top labs don't rely on a single burst of inspiration, but continuously propose hypotheses, run experiments, examine results, modify plans, and try again.
Engineering optimization follows the same principle: anyone can create the first version; what's truly difficult is that final 1% performance leap.
The significance of Frontier-Eng Bench lies here: For the first time, it systematically begins testing AI's 'iterative optimization capability', and has summarized two nearly brutal laws of AI evolution.
△
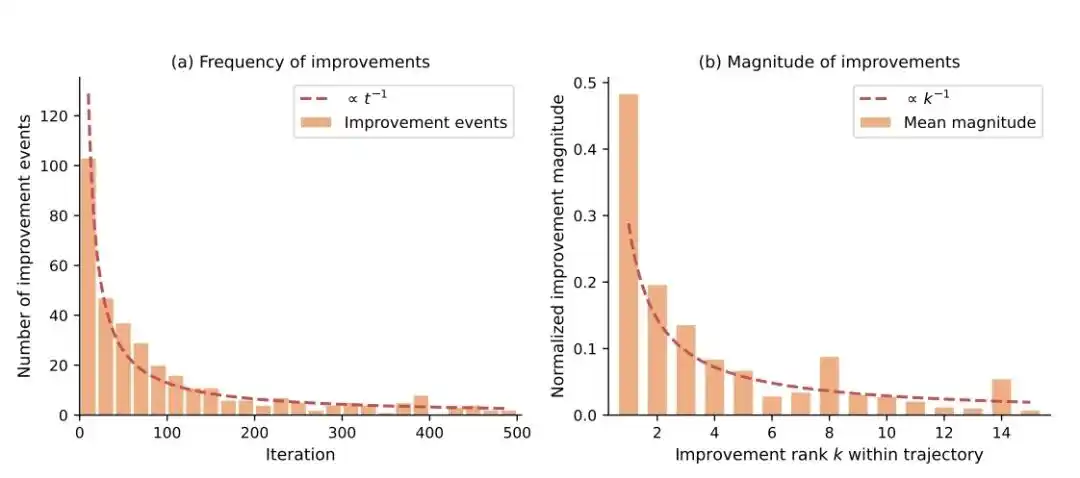
The first law is: The further you go, the harder the improvement.
This paper found that the frequency and magnitude of Agent improvements follow a power-law decay:
- Improvement frequency ∝ 1 / iteration count
- Improvement magnitude ∝ 1 / improvement count
Simply put: the fastest gains come in the first few rounds, and it gets progressively harder and smaller later on.
This closely resembles the real R&D process: the first version of AI can quickly eliminate many 'low-hanging fruits', but the closer it gets to the bottleneck, the more effort is required to squeeze out even a bit more performance.
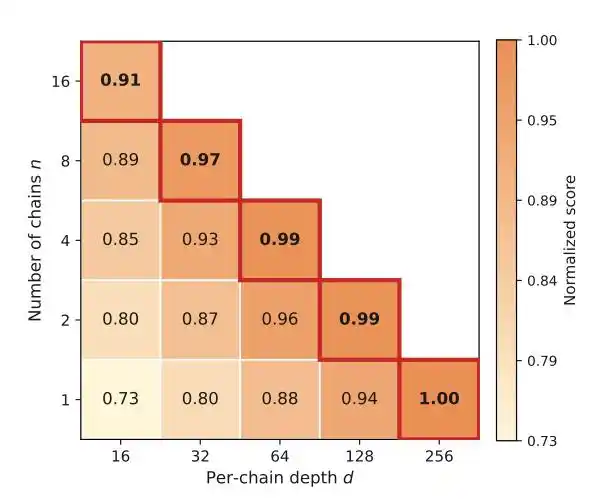
Would it be more cost-effective to explore multiple paths in parallel for trial and error? The answer lies in the second law.
△
The second law: Breadth is useful, but depth is even more indispensable.
Running multiple parallel paths can avoid getting stuck, but with a fixed budget, each additional chain opened shallows the depth of exploration.
Many engineering breakthroughs require continuous accumulation and constant correction before structural leaps emerge; they can't be achieved simply by 'trying a few more times'.
This actually points towards the development direction of next-generation Agents: not models that 'output an answer once', but systems that can continuously iterate and self-evolve within long-term feedback loops.
AI Engineers Might Really Be Coming
The true far-reaching significance of this research lies in its preliminary outline of an AI system beginning to approach the real engineering cycle.
△
Imagine when AI connects to industrial software, simulation environments, CAD systems, chip design tools, scientific computing platforms...
A dramatic transformation in the modality of productivity is on the verge of emerging.
In future labs, a division of labor like this might appear:
Human researchers are responsible for proposing directions and goals.
For example, 'reduce this component's energy consumption by 30%', 'compress this model's forward pass GPU usage even lower', 'increase the stability of robot control a bit more', 'push the fidelity of this quantum circuit closer to the limit', etc.
And AI is responsible for 'grinding the path'. They focus on these goals, continuously optimizing.
For example, automatically running simulations and experiments, automatically reading feedback from verifiers and simulators, then continuing to modify and optimize, iterating non-stop 24/7.
This evolutionary logic frees AI from the identity of an 'assistive tool', allowing it to begin solving complex system problems like a real engineering team—and tirelessly at that.
And the issues revealed by the Frontier-Eng Benchmark are actually very direct:
When AI begins to learn 'long-term optimization', how far is it from true engineering intelligence?
Paper Title: Frontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
Project Homepage: https://lab.einsia.ai/frontier-eng/
Arxiv: https://arxiv.org/abs/2604.12290
GitHub repo: https://github.com/EinsiaLab/Frontier-Engineering
This article is from the WeChat public account "Quantum Bit", author: Yun Zhong






