Author: Li Feifei
Translation: Jiayang
'World model' is probably the hottest and most confusing concept in the AI field since 2025. When Sora emerged, OpenAI called it a world simulator; Genie lets you walk around in generated scenes and is also called a world model; robotics companies say they're working on world models; NVIDIA says Omniverse is the infrastructure for world models; even game engines have been pulled into this narrative. Everyone is using the same term, but they're talking about completely different things.
Today, Li Feifei published a new article on her personal Substack to clarify this concept. She first returns to the most classic diagram in reinforcement learning textbooks (the POMDP closed loop: agent → action → state → observation → agent), then points out that what are now called 'world models' are actually three different projections of this closed loop. Those outputting pixels (observations) are renderers, those outputting states are simulators, and those outputting actions are planners. The classification criteria are very simple: it depends on which part of the loop you output.

(Source: MIT Technology Review)
She assesses that among the three, renderers are the most commercially mature but have a ceiling (looking good does not equal physical correctness); planners are the most exciting but furthest from real-world deployment (the chasm between lab demos and practical usability remains vast); and simulators are the severely underestimated critical hub. Because simulators operate at the level of geometry, physics, and dynamics, they can project upwards into pixels for human consumption and also derive action consequences downwards for robot use. Mastering simulation simultaneously provides the foundation for rendering and planning; the reverse is not true.
This article is, of course, also a product manifesto for World Labs. Their Marble already outputs both Gaussian splats and collision meshes, attempting to unify renderer and simulator into a single model. The ultimate vision described at the end of the article is a unified world foundation model that can freely switch between rendering, simulation, and planning based on downstream needs. Whether this vision can be realized is another matter, but as an analytical framework, the tripartite classification of renderer/simulator/planner may indeed help cut through some of the noise surrounding the current 'world model' concept.
The full translation follows.
"The world is all that is the case." — Ludwig Wittgenstein, Tractatus Logico-Philosophicus, 1921
The world is not made of words.
In an earlier article, we proposed that spatial intelligence is the next frontier for AI, and world models are the path toward it. Here, the World Labs team and I want to delve one level deeper: among the many things currently labeled as "world models," which functional modules truly constitute this capability, and what are their respective purposes?
Language models have endowed machines with powerful mastery over concepts, vocabulary, and reasoning. But the physical world, whether virtual or real, operates on a completely different substrate. Language models learn the statistical structure of text; world models learn the statistical structure of space and time: how light falls on a surface, what a garden looks like from an angle never captured by a camera, how objects respond to forces and follow physical laws.
This makes "world model" one of the most important and simultaneously most abused terms in today's AI field. Computer vision, robotics, reinforcement learning, and generative AI all claim to be building world models, but each refers to something drastically different. A video model that generates gorgeous but physically impossible flames, a language model that improvises playable games, a physics engine that faithfully simulates a combustion process—they are all called by the same name.
The ancient Greeks could never agree on what the world was made of—be it fire, water, or indivisible atoms—because "the world" has never been a single thing. It has always been a substitute term used by a thinker to reason about a certain totality. AI inherits the same problem, and it happens precisely at the moment when the field needs precision the most.
The Loop Behind the Taxonomy
To clear up this confusion, we can start with a diagram older than all the technologies mentioned above. All reinforcement learning textbooks, including the classic by Sutton and Barto, have used variations of the same diagram for decades to describe how an agent interacts with the world. Its formal name is the Partially Observable Markov Decision Process (POMDP), and the term "world model" was originally defined within this tradition.
An agent (which can be a human, a robot, or a software system) takes an action. These actions change the state of the world. But the agent can never directly see the state itself; what it receives are observations: photons hitting the retina, sensor readings, pixels in a video frame. New observations guide new actions, and the cycle repeats.
The word "state" needs to be unpacked because its meaning shifts across different domains. This is not the chemist's state, not the distinction between solid, liquid, and gas. This is the physicist's and roboticist's state: a complete description of everything happening in the world at a given moment, including every object, every position, every velocity, every property. The state is the underlying reality of the world, in principle complete, but forever unobservable directly by any agent within it. Observations are the agent's partial view of this reality. Actions are the agent's response accordingly.
This closed loop (agent → action → state → observation → agent) is precisely the structure that gives the term "world model" its technical meaning. The phrase itself is even older, traceable to Kenneth Craik's 1943 proposal that the mind reasons by running "small-scale models" of reality, and by the late 1980s and early 1990s, the concept was introduced into neural networks. This loop also explains what people mean when they use the term today. The various things now called world models are actually different projections of the same closed loop, each outputting a different component of the loop.
Three Functions of World Models
The first type of world model is the Renderer. A renderer outputs observations, specifically pixels for the human eye, and the most important quality metric is visual fidelity. A video model that transforms text prompts into cinematic aerial shots is a renderer; interactive systems like Google's Genie 3 or World Labs' own RTFM are also renderers, generating visuals in real-time based on user input. Such models lack an explicit understanding of 3D structure. They generate what a viewer would see, not what things are like in themselves. The building in an aerial shot might look flawless from above, but try navigating the city below, and they will collapse.
The second type is the Simulator. A simulator outputs states: a geometrically, physically, or kinematically faithful representation of the world upon which both humans and computer programs can compute and interact. The renderer's contract is purely visual, while the simulator's contract is structural, demanding geometry that holds up under scrutiny, physics that obey Newton's laws, and dynamics that behave as expected by physical principles. Simulators serve two classes of users. Professionals like architects, designers, filmmakers, and game developers require accuracy beyond visual plausibility. Computer programs like reinforcement learning agents, robot controllers, and autonomous vehicles treat the simulator as a training ground to interact with the world at scale, testing scenarios that are either dangerous, expensive, or simply impossible to execute in reality.
The third type is the Planner. A planner outputs actions. Given an observation and a goal, the planner answers the question: what should the agent do next? In many ways, the planner is the inverse of the renderer. The renderer takes actions as input and produces observations; the planner takes observations as input and produces actions, thereby closing the perception-action loop. Vision-Language-Action models (VLA), model-based systems, and the new wave of World Action Models are all different attempts at planners: enabling systems to decide what a robot should do in an unstructured world.
These three categories cover most of the work currently being implemented, and the distinction is useful in practice. But these categories are not fundamentally separate. They share the same underlying knowledge about how the world works: geometry, physics, dynamics. A model that can render a cup from any angle should, in principle, also be able to simulate what happens if the cup is pushed and plan a hand to pick it up. Increasingly, the most interesting research is deliberately blurring the boundaries between these three.
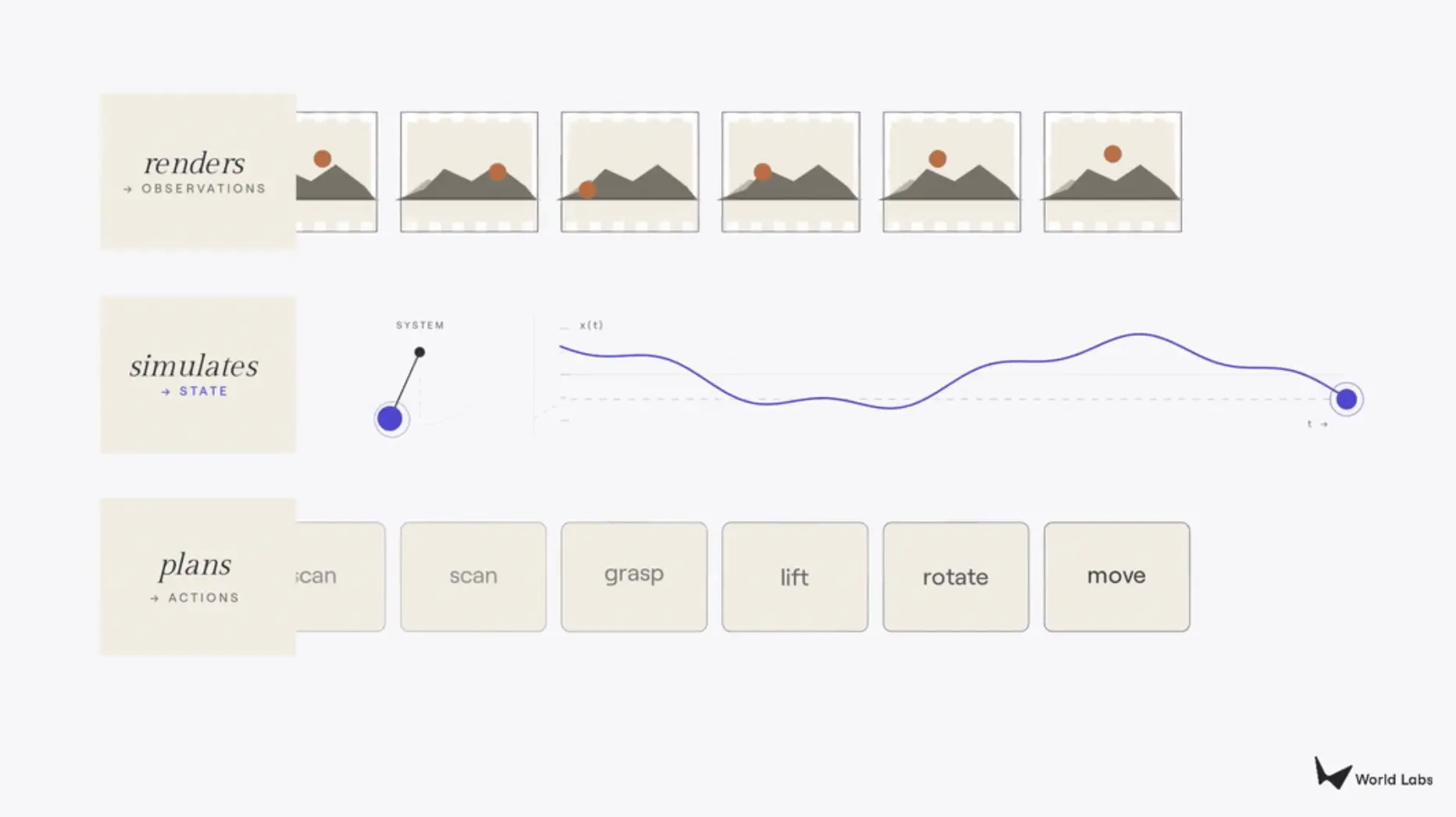
Illustration | Three Types of World Models (Source: Substack)
Why Simulation Is the Key Hub
Among the three categories, simulators receive the least public attention yet are the most important of the three. This article seeks to correct that asymmetry.
Renderers are currently the most commercially mature. Numerous image or text-to-video products are rapidly expanding in consumer and enterprise markets. Google's Nano Banana model has brought renderer-level image generation capabilities to potentially hundreds of millions of users. The technology is real, and the market is real. However, renderers optimize for visual plausibility rather than physical accuracy, and this ceiling is important. Their outputs are beautiful, but you cannot use them to design a building or train a robot.
Planners are the most exciting and least mature, closely tied to the rapidly evolving field of robot learning. The past two years have produced many robot demos that look impressive in videos, but we need to be honest about what these demos actually show. Almost all demos are confined to highly constrained lab environments with limited objects and short task durations. None have been validated against the complexity, diversity, and duration required for real-world deployment. The gap from a stunning demo video to a robot that works reliably in a kitchen, warehouse, or operating room remains vast.
Nevertheless, the scale of commercial bets is substantial. A wave of well-funded new entrants is racing to launch general-purpose planning systems, while large infrastructure players are layering planning capabilities atop broader simulation stacks.
Simulation is the bridge connecting the two. If language is an abstraction of the world and pixels are a projection of the world, then geometry, physics, and dynamics are the world itself. A simulator must operate at this level: it is the structural skeleton from which visual appearances (for renderers) and action consequences (for planners) can both be derived.
A model that masters simulation can project its understanding into pixels for human consumption and into action predictions for embodied agents. A model that masters only rendering or only planning can do neither. The commercial space here is immense. NVIDIA's Omniverse alone, according to the company's estimate, targets a market opportunity exceeding a trillion dollars, covering factories, warehouses, supply chains, and digital twins. Robot training, autonomous vehicle testing, architectural visualization, engineering design, drug discovery—all rely on some form of simulation.
The most difficult open questions in the field are also concentrated here. 3D data with explicit geometry, material properties, and physical annotations is orders of magnitude scarcer than internet videos used for renderer training. The sim-to-real gap (the difference between how objects behave in simulation versus the real world) persists. Generative simulators introduce new risks on top of this: AI-generated geometry might look correct but actually contain self-intersections or incorrect scales, leading to absurd results in physics simulation. The computational cost of large-scale multi-physics simulation (rigid bodies, deformable objects, fluids, cloth all interacting simultaneously) remains orders of magnitude higher than simulation in a single domain.
At World Labs, Marble is our first step in this direction. It takes multimodal input (text, image, video, or spatial sketches) and generates explorable 3D environments, simultaneously outputting Gaussian splats for visual exploration and collision meshes for physics engines. But Marble is only the first chapter of a long arc. As the boundaries between rendering, simulation, and planning begin to dissolve, the entire field is writing this story.
The Boundaries Are Blurring, and What Comes Next
The most important trend in the field right now is that the three categories are beginning to merge. The underlying consensus is that the knowledge required to render a world, simulate it, and act within it is largely the same. Continuing with the previous example, a model that truly understands how a cup sits on a table (its geometry, material properties, response to forces, etc.) should be able to render that cup from any angle, simulate what happens if the cup is pushed, and plan a hand to pick it up. The three categories are three projections of the same underlying understanding.
For instance, a small but growing body of work from various robotics labs has recently shown the possibility, at least conceptually, that a pre-trained video renderer can serve as the backbone for joint world prediction and action prediction, allowing a single model to simultaneously imagine "what will happen" and "what to do," thus bridging renderers and planners. World Labs' Marble can already output both Gaussian splats and collision meshes from a single model, dissolving the boundary between renderer and simulator. At every level, the move is from passive output to interactive systems: renderers become responsive to action conditioning, simulators generate worlds that are more controllable and editable, and planners begin deliberative reasoning rather than merely reacting.
The logical endpoint is a unified world model: a foundation model capable of rendering photorealistic views, generating physically accurate structures, planning action sequences, and switching between different output modalities based on the needs of downstream users. We will still face a series of formidable challenges. The data landscape is extremely uneven, with renderers sitting on vast amounts of internet video, while simulators and planners face severe shortages of 3D assets and robot demonstration data. Optimization for visual beauty may come at the expense of precision needed for robotics or high-fidelity simulation. Reconciling these tensions within a single architecture is the central open problem in world model research today, and what World Labs is committed to solving as Marble continues to evolve.
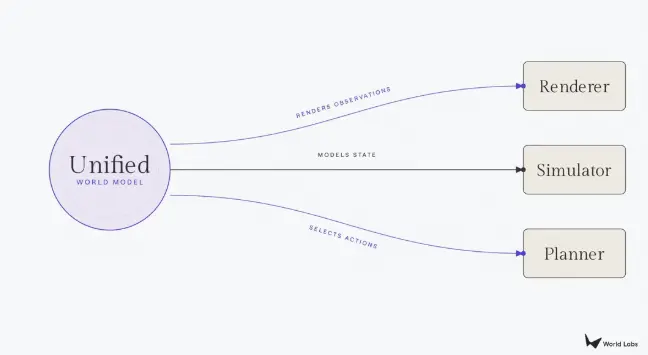
(Source: Substack)
But the overall direction is clear. From the late 1980s to today, the field's bet has always been the same: that if the world model is rich enough, everything an agent needs to see the world, build it, and act within it is contained therein. This bet is now driving a generation of research. And what truly gives it weight is the already-occurring convergence: the three threads of rendering, simulation, and planning, each already supporting industries worth billions, started as independent research directions and are now beginning to merge. When the boundaries disappear, the confluence of the three will redefine something larger: the relationship between machine intelligence and the physical world it inhabits, which is the long-term trajectory of spatial intelligence.
Language has given machines a way to talk about the world. World models are the path by which machines finally come to understand, imagine, reason, and interact with it.
Reference: 1.https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models







