一份招聘广告,有时比一份年度财报更能揭示一家公司的战略意图。
2025年8月,京东科技的一则招聘信息正是如此。它没有出现在主流招聘网站的首页,而是在Web3的小圈子里悄然流传。引人注目的并非“稳定币链上活动策划”这个职位名称本身,而是其堪称“加密原生”的任职要求:“深度参与至少一个DeFi协议的经济模型设计”、“精通DEX、借贷、衍生品协议”。

这并非在寻找一位优化内部支付的金融科技专家,而是在“猎寻”一名真正的链上战略家。当一家年营收过万亿、以实体零售和供应链为根基的互联网巨头,开始公开物色能驰骋于去中心化世界的人才时,其释放的信号已再清晰不过:京东正准备将棋子,落在全球化、无需许可的Web3棋盘上。
香港“东风”已至,京东顺势入局
京东此举并非发生在真空里。招聘动作的时机,与香港一项关键的监管变革形成了精准的呼应。
就在招聘信息浮出水面的前几天——2025年8月1日,香港酝酿已久的《稳定币发行人发牌制度》正式生效。这意味着,香港金融管理局(HKMA)在经过多轮咨询和沙盒测试后,为全球的稳定币运营商铺开了一张合规的、规则明确的“迎宾毯”。因此,京东的这次“招兵买马”,与其说是一次向未知领域的探索,不如说是一次计算精准的落子,目标直指这块刚刚被官方认证的、极具战略价值的全球金融新大陆。
香港财经事务及库务局局长许正宇此前在公开场合多次强调:“在确保监管和风险可控的前提下,我们支持虚拟资产市场的稳慎发展,并视稳定币为连接传统金融与虚拟资产市场的关键桥梁。”
这股东风,对于像京东这样拥有庞大中国内地背景,又渴望链接全球市场的科技公司而言,来得恰逢其时。它提供了一个完美的“出海口”——一个在法律上明确、在地理上邻近、在文化上相通的战略支点。通过在香港设立合服规主体,京东便可以合法地发行锚定法币(如离岸人民币CNH或港币HKD)的稳定币,从而绕开中国内地对加密货币的严格管制,直接参与全球的链上经济活动。
京东的招聘紧随法规生效之后发布,这并非巧合,而是一场蓄谋已久的“顺势而为”。棋盘已经备好,京东显然不想只做看客。
PayFi:超越支付的“金融乐高”
如果说香港的合规环境是京东稳定币项目的“天时”,那么职位描述中一个不起眼的词——PayFi,则揭示了其真正的“地利”与核心野望。
PayFi,即Payment Finance(支付金融),是一个源于加密原生世界的概念。它远不止于“用加密货币支付”这么简单,其核心是通过智能合约,将支付行为本身与复杂的金融服务无缝结合,赋予每一笔资金流动的可编程性。
想象一下京东业务中的一个场景:一家为京东供货的中小企业,过去需要等待长达90天的账期才能收到回款,资金压力巨大。在PayFi模式下,会发生什么?
当京东确认收货后,系统可以生成一张代表这笔应收账款的链上凭证(NFT或同质化代币),并立即发送给供应商。供应商无需等待90天,而是可以立刻将这张“数字汇票”在DeFi借贷协议中作为抵押品,获得即时流动性;或者,它甚至可以被拆分、交易,作为支付给上游原材料供应商的款项。整个过程由代码自动执行,高效、透明且成本极低。
这正是Real World Assets(RWA,真实世界资产)代币化与PayFi结合的威力,也是2025年加密行业最激动人心的叙事之一。资产管理巨头富兰克林邓普顿的CEO Jenny Johnson就曾断言:“我们相信,将真实世界资产代币化,将重塑整个金融服务业。这是区块链技术最重大的应用之一。”
对于拥有海量商家、复杂供应链网络和亿万用户的京东而言,其内部蕴藏着价值万亿的“真实世界资产”——应收账款、仓单、物流订单、消费者信用。将这些资产通过稳定币和PayFi的模式在链上盘活,无异于打通了全身经络,其所能释放的能量将是指数级的。这不仅是对现有供应链金融业务的降本增效,更是创造了一个全新的、可编程的金融基础设施。
“两栖作战”:巨头们不同的Web3路径
京东对稳定币和DeFi的明确指向,也使其在中国科技巨头的Web3探索中,走出了一条截然不同的道路。如果我们横向对比,会发现一幅有趣的画面:
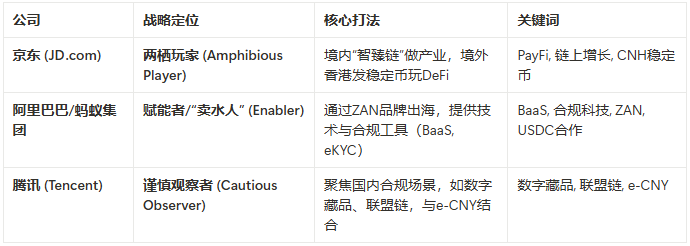
如上表所示,阿里巴巴旗下的蚂蚁集团,在Web3的布局更像是“卖水人”。其在香港推出的ZAN品牌,专注于为Web3开发者提供e-KYC(电子化身份验证)、AML(反洗钱)等合规技术组件和BaaS(区块链即服务)。其策略是“赋能”,帮助别人更好地“淘金”,而不是自己亲自下场。近期传出其专有链计划整合美元稳定币USDC的消息,也印证了其倾向于与成熟生态合作,而非另起炉灶的思路。
腾讯则更为谨慎,其动作大多围绕在联盟链和数字藏品等国内政策明确的领域,与公链世界保持着相当的距离。
在这样的背景下,京东的策略显得尤为独特和进取。它没有满足于只做技术服务商,而是选择了一条“两栖作战”的道路:
- 对内(Inland): 其自研的“智臻链”继续在许可环境下深耕产业区块链,服务于防伪溯源、数字存证等,拥抱监管,对接数字人民币(e-CNY),做强合规的“产业数字化”基本盘。
- 对外(Offshore): 则利用香港的窗口,亲自下场成为一名“玩家”,发行自己的稳定币,运营自己的链上生态,直接在DeFi的汪洋中捕鱼,探索“金融资产化”的星辰大海。
这种双线并行的策略,既保证了国内业务的稳定与合规,又为集团的未来打开了无限的想象空间。
从电商帝国到链上经济体
京东的这一步,标志着一个重要的转折点。它预示着顶级Web2巨头与Web3的融合,正在从理论探讨和边缘试水,走向核心业务的深度整合。
过去,人们总在讨论Web3将如何“颠覆”Web2。但京东的案例或许揭示了另一种可能:并非颠覆,而是“升维”。Web2巨头们并不会轻易被取代,它们会利用自身庞大的用户基础、丰富的应用场景和雄厚的资本,吸纳Web3的技术和理念,进化成一种新的、更强大的混合形态。
当然,前路并非坦途。从招聘一个职位到真正建立一个繁荣的链上生态,京东需要跨越技术集成、金融合规、市场教育和用户习惯等多重障碍。它将面对的不仅是传统金融机构的审视,还有来自加密原生世界的激烈竞争。
但无论如何,当京东这艘万亿级的商业航母开始调整航向,驶入DeFi的深水区时,整个行业都应该密切关注。因为这不仅仅关乎一家公司的未来,更可能是在为我们描绘一幅蓝图:一个电商帝国,如何通过稳定币这座桥梁,最终演化为一个高效、透明、全球化的链上经济体。那一天,交易的终点将不再是支付完成,而是另一段金融价值创造的开始。





