Автор | Технологии без холода
24 апреля на рынке больших моделей в Китае произошло важное событие. Официально выпущена предварительная версия DeepSeek-V4 с одновременным открытием исходного кода, что сделало обработку сверхдлинного контекста в 1 миллион слов стандартной конфигурацией официального сервиса.
Если бы это произошло год назад, такие возможности обработки длинных текстов были бы эксклюзивной привилегией зарубежных крупных компаний, скрытой за корпоративным платным доступом. Теперь же они выложены на стол сообщества открытого исходного кода, став инфраструктурой, доступной разработчикам в любое время. Для разработчиков, которые долгие часы работают с длинными базами кода или сложными юридическими контрактами, это, несомненно, хорошая новость.
Однако за этим распространением технологий в официальном сообщении содержится очень сдержанное признание: «Из-за ограничений высокопроизводительных вычислительных мощностей пропускная способность службы DeepSeek-V4-Pro в настоящее время весьма ограничена».
Для тех, кто привык видеть, как компании на презентациях хвастаются своими вычислительными ресурсами, такая прямота кажется необычно холодной.
Во второй половине гонки больших моделей в отрасли хорошо известно, у кого сколько высокопроизводительных аппаратных ресурсов. Вместо поддержания видимости prosperity на уровне параметров, лучше прояснить текущую ситуацию в отрасли. Действия DeepSeek в данном случае фактически отказываются от одержимости pure benchmark-тестами и находят компромиссное решение,兼顾 (учитывающее) технологическое развитие и текущее состояние аппаратного обеспечения, между прорывом в ключевых алгоритмах, еще формирующейся в Китае экосистемой гетерогенных вычислений и реальной бизнес-средой предприятий.
Индустрия ИИ Китая сбрасывает раннюю одежду слепого сжигания денег и вступает в крайне реалистичную эру «бухгалтерской книги вычислительных мощностей».
Как выравнивается счет за вычисления Pro-версии?
Конкретно рассмотрим V4-Pro с явно ограниченной пропускной способностью. Как флагман в системе, V4-Pro обладает общим объемом параметров до 1.6T, но при выводе активирует только 49B параметров. Этот предельно разреженный дизайн — не просто модель для витрины; под строгими испытаниями реального производства его технологический фундамент обладает极强的 обороноспособностью.
Способность справляться со сложным кодом и логическими рассуждениями является пробным камнем для проверки того, может ли большая модель真正 войти в ключевые производственные звенья. В среде оценки Agentic Coding (код интеллектуального агента) практические показатели V4-Pro稳稳 находятся в первом эшелоне текущих открытых моделей.
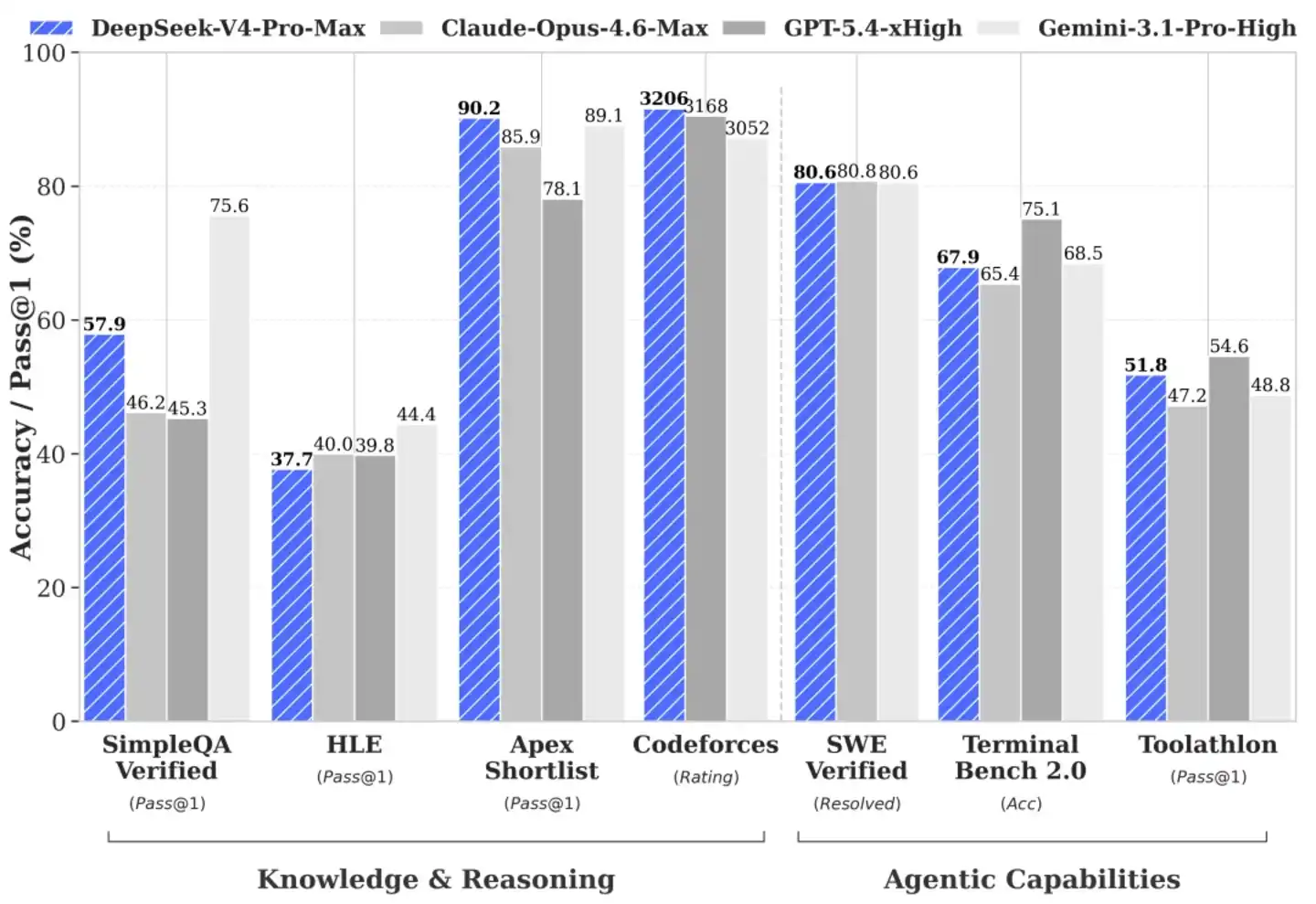
DeepSeek уже интегрировал его в свой внутренний конвейер кода, сделав его инструментом productivity, от которого сильно зависят инженеры первой линии. Отзывы разработчиков показывают, что опыт генерации и исправления кода превосходит Sonnet 4.5, а в сценариях, не требующих глубоких размышлений, приближается к Opus 4.6, хотя до режима размышлений Opus 4.6 все еще есть差距 (разрыв).
За этими практическими показателями стоит极致 (предельное)挖掘 (извлечение) алгоритмической глубины исследовательской группой. В оценке мировых знаний, проверяющей качество очистки данных предварительного обучения и плотность знаний, V4-Pro опережает большинство существующих открытых моделей, в настоящее время лишь немного уступая ведущей закрытой модели Gemini-Pro-3.1. Что касается математики, STEM (наука, технология, инженерия, математика) и соревновательных оценок кода, он получил право соревноваться наравне с ведущими мировыми закрытыми крупными компаниями.
Очевидно, что такая боеспособность достигнута не просто за счет накопления вычислительных карт. Китайские команды понимают, что реально соревноваться запасами высококлассных графических карт нереально. То, что V4-Pro может обрабатывать сверхбольшой контекст в 1M при ограниченной видеопамяти, поддерживается глубокой реструктуризацией механизма внимания, проведенной研发 (R&D) командой. Они реализовали全新的 (совершенно новую) схему сжатия внимания, проводя高强度 (высокоинтенсивное) сжатие на уровне token в сочетании с их фирменной технологией разреженного внимания DSA (DeepSeek Sparse Attention).
Этот оригинальный технологический маршрут в сочетании с впервые引入 (введенными) алгоритмами скользящего окна и сжатия KV Cache эффективно контролирует вычислительные затраты и占用 (занятие) памяти, вызванные обработкой длинных последовательностей. Чтобы разработчики действительно могли использовать его возможности в бизнесе,研发 (R&D) команда специально провела底层 (низкоуровневую) адаптацию для основных инструментов Agent, таких как Claude Code и OpenClaw.
В технической документации даже прямо указано, что разработчики при обработке сложных задач могут напрямую включить режим размышлений, установив параметр reasoning_effort в max. Такая системная инженерная оптимизация при ограниченных вычислительных ресурсах как раз доказывает отрасли, что даже при ограниченных высокопроизводительных мощностях локальные команды все еще могут расширять границы производительности модели за счет原生 (нативной) архитектурной разработки.
Кого задержал объем активации в 13B?
Те, кто盯 (уставился) на узкое место пропускной способности Pro-версии, часто упускают из виду коммерческую опорную точку, скрытую DeepSeek behind the scenes — Flash-версию. В отрасли есть голоса, считающие это merely продуктом компромисса из-за нехватки вычислительной мощности, но такое мнение явно недооценивает долгосрочные соображения управленческой команды. Это тщательно просчитанный по затратам прагматичный ход для захвата позиций в下沉жной (нисходящей) экосистеме.

Согласно公开 (открытой) информации о адаптации кода, общий объем параметров Flash-версии сохраняется на уровне 284B, но ее объем активированных параметров точно зафиксирован на 13B.
13B — в контексте, где коллеги пытаются pushed параметры к триллионным масштабам, не выглядит примечательным. Но это как раз и отражает экономическую логику архитектуры смешанных экспертов (MoE) в коммерческом внедрении: общие параметры определяют широту знаний модели, а активированные параметры напрямую определяют затраты на электроэнергию и пропускную способность памяти, которые сервер должен支出 (оплачивать) при каждом вызове интерфейса.
Удержание объема активации на уровне 13B напрямую отделяет большую модель от дорогостоящих顶级 (топовых) интеллектуальных вычислительных центров. Ее требования к видеопамяти одной карты и пиковой вычислительной мощности очень сдержаны. Практические тесты показывают, что Flash-версия при обработке massive, высокочастотных простых повседневных задач сохраняет стабильную скорость отклика и точность, базовая универсальная способность к рассуждению не показала явного спада. Для малых и средних разработчиков и long-tail предприятий, которым необходимо обрабатывать тысячи вызовов API daily, это действительно доступный и работающий инструмент productivity по доступной цене.
Более глубокая отраслевая логика заключается в том, что основные отечественные чипы для гетерогенных вычислений все еще находятся на стадии догоняющего развития по абсолютной производительности одной карты. Вычислительные системы, несущие полную активацию,极易 (очень легко) сталкиваются со стеной памяти, приводя к низкой эффективности работы; но面对 (столкнувшись) с Flash-версией с объемом активации всего 13B, эти чипы могут работать плавно при средней и низкой мощности.
Этот шаг DeepSeek оживляет大量 (большое количество) простаивающих ресурсов средних и низких вычислительных мощностей в стране, предоставляя отечественным чипам, остро нуждающимся в сценариях внедрения, высокосовместимый испытательный полигон. Эта логика строительства инфраструктуры с downward包容 (нисходящей包容чивостью) гораздо больше соответствует current商业 (текущей коммерческой) реальности, чем просто поднятие позиций в различных тестовых рейтингах.
Справляются ли отечественные чипы?
Вызвавшей широкое обсуждение в отрасли此次 (этой) презентации является нанесенный ею ярлык全栈 (полного стека) отечественного внедрения. В течение долгого времени между алгоритмическими компаниями и производителями отечественных чипов существовал определенный разрыв: производители моделей опасались, что несовершенство аппаратной экосистемы замедлит研发 (R&D) прогресс, а производители чипов испытывали недостаток в передовых больших моделях для глубокой настройки. На этот раз тупик был substantially打破 (разрушен).
Huawei Computing быстро выступила с заявлением, подтвердив, что вся серия продуктов Ascend Super Node полностью поддерживает новую модель. С технической точки зрения, базовые чипы Ascend依靠 (полагаясь) на технологию融合 (слияния) kernel и многопоточного并行 (параллелизма), эффективно снижают вычислительные затраты системы, thereby стабилизируя производительность вывода в сценариях с длинным текстом. Cambricon также быстро завершила адаптацию Day 0 и открыла исходный код底层 (низкоуровневого) кода, Hygon DCU одновременно объявила о замыкании цикла.
Но нам нужно развеять表象 (видимость) prosperity экосистемы и审视 (внимательно изучить) реальное сопротивление, с которым сталкивается сшивка программного и аппаратного обеспечения в машинном зале. Взять, к примеру, чипы серии Ascend 950. Согласно отраслевой информации, этот чип обладает 112GB собственной HBM, пропускной способностью 1.4TB/秒 (в секунду) и энергопотреблением одной карты达 (достигающим) 600瓦 (ватт). При определенной точности вывода (например, FP4) его вычислительная мощность на одной карте уже демонстрирует extremely сильные данные, достигая 2.87 раза от показателей NVIDIA H20. Однако в более требовательных диапазонах общей точности обучения FP16 или FP32, производительный разрыв между отечественным hardware и NVIDIA все еще существует.
Кроме того, так называемая «адаптация Day 0» все еще需要跨越 (должна преодолеть) скрытые成本 (издержки), вызванные непрозрачностью цепочки поставок, для безотказной работы корпоративного бизнеса. Стандарты высокоскоростного соединения hardware Super Node крайне закрыты, поток ключевых компонентов resembles информационному черному ящику. Такой барьер на этапе закупок, несомненно, усложняет масштабное развертывание и обслуживание вычислительных систем.
В то же время, в настоящее время эта система сильно зависит от крупных оптовых заказов极少数 (очень немногих) крупных отечественных учреждений. Нехватка заказов с海外 (зарубежных) рынков означает, что эта битва за прорыв в вычислительной мощности может вестись только во внутреннем循环 (цикле). Такая единственная коммерческая闭环 (замкнутая система) делает urgent необходимость закалки эффективности работы всей системы软硬协同 (совместной работы программного и аппаратного обеспечения) в более разнообразной коммерческой среде.
Напряженный рост производства высокопроизводительных вычислительных мощностей напрямую привел к тому, что DeepSeek в своем сообщении坦白 (откровенно) признал: для значительного снижения цены на Pro-версию仍需等待 (все еще необходимо дождаться) массового выхода Super Node во второй половине года. Большие модели и отечественные чипы действительно завершили preliminary физическое сцепление, но при технологическом разрыве и ограничениях цепочки поставок, эта поза бега с травмами как раз и является самым реальным срезом выживания экосистемы отечественных вычислений.
Продолжит ли технология работать после ухода людей?
Возвращаясь к реальной商业 (коммерческой) конкуренции, появление DeepSeek-V4 является极其 (чрезвычайно) точной стратегической обороной. В течение последних полугода эта компания始终 находилась (всегда находилась) в состоянии высокого давления. Сегмент C-end превратился в красный океан, ведущие компании используют massive (огромные) средства для密集 (плотного) размещения. Данные QuestMobile показывают четкую конкурентную ситуацию: по состоянию на март 2026 года, месячная активность Doubao достигла 345 миллионов, Qianwen — 166 миллионов, а DeepSeek с 127 миллионами удерживает свою основную долю рынка.
Внешняя конкуренция за трафик fierce, внутренний технологический штаб также сталкивается с испытанием текучести. Конкуренция за переманивание в отрасли白热化 (накалилась до предела), ключевые сотрудники нескольких бизнес-направлений接连 (один за другим) уходят. Согласно公开 (открытым) резюме и отраслевой информации, основной автор языковой модели первого поколения подтвердил присоединение к Tencent, ключевой участник V3 перешел в Xiaomi, ключевой исследователь R1 поступил на работу в ByteDance, ключевые силы в multimodal направлении также подтвердили свое новое направление. По отраслевым слухам, ключевой автор направления OCR Вэй Хаоран также уволился.
Изменения в составе ключевых研发 (R&D) сотрудников неизбежно вызовут пристальное审视 (внимание) к их研发 (R&D) потенциалу: пострадает ли инновационная способность底层 (низкоуровневой) архитектуры этой компании,立足 (стоящей) на технологиях?
В этот момент выпуск предварительной версии V4 стал самым прямым ответом. Он подтвердил рынку, что компания создала системный研发 (R&D) конвейер, способный противостоять рискам. Даже перед лицом调整 (корректировок) кадровой структуры, логика其技术演进 (ее технологического развития) все еще может работать точно. Эта организационная resilience, построенная на основе инженерной системы, быстро получила положительную обратную связь на资本市场 (рынке капитала).
Недавно стало известно, что DeepSeek ищет финансирование с оценкой не ниже 100 миллиардов долларов, планируя привлечь средства для пополнения резервов. Согласно отраслевым СМИ, со ссылкой на источники, близкие к сделке, ходят слухи, что ожидается взнос от ведущего интернет-гиганта, который может поднять оценку в этом раунде. Если эта сделка最终 состоится (в конечном итоге состоится), она перепишет рекорды оценки на внутреннем треке больших моделей, превзойдя предыдущие показатели Moon's Dark Side. В关键期 (ключевой период) переговоров по финансированию, представить百万 (миллионный) контекст и实质性 (существенные) результаты全栈 (полной) отечественной адаптации — это理性 (рациональный) ход руководства для стабилизации общей стратегической ситуации и回应 (ответа) на внешние сомнения.
В заключение
В коммерческом контексте технологий с частой сменой концепций команды, желающие专注于 (сконцентрироваться на) создании底层 (низкоуровневой) инфраструктуры,始终稀缺 (всегда稀缺ны). Выпуск DeepSeek-V4 устанавливает прагматичный и холодный тон для竞争 (соревнования) во второй половине гонки больших моделей.
Столкнувшись с узким местом вычислительной мощности, они не выбрали приукрашивание, а бросили реальную ситуацию спроса и предложения на отечественное high-end hardware рынку; Столкнувшись с потребностями в downward (нисходящем) внедрении, они использовали Flash-версию с объемом активации 13B, чтобы предоставить пространство для выживания отечественным вычислительным чипам, находящимся на стадии догоняющего развития; Столкнувшись с внешней блокировкой трафика и конкуренцией за таланты, они конкретными возможностями обработки длинных текстов дали ответ на отраслевом уровне.
Цитируемые官方 (официально) в день выпуска слова Сюнь-цзы极具深意 (чрезвычайно глубоки): «Не соблазняться славой, не бояться клеветы, следовать пути и правильно выпрямлять себя».
Модель можно открыть, но вычислительная мощность не будет бесплатной. То, что представил DeepSeek на этот раз, — это не более сильная модель, а решение о том, как перераспределяются возможности после того, как вычислительная мощность стала ограничением. В реальности, где вычислительная мощность все еще неидеальна, это, возможно, и есть направление evolution,更接近 (более близкое) к сути отрасли.





