Let's build a simple, hypothetical trading strategy. The premise is straightforward and rooted in a widely discussed narrative: when coins leave exchanges, it tends to be bullish. The reasoning is intuitive: coins moving off exchanges typically signal that holders are withdrawing to self-custody, reducing the available supply for selling. Conversely, coins flowing onto exchanges may indicate that holders are preparing to sell.
A single day of outflows, however, is just noise. To identify a genuine trend, we would apply a moving average crossover on the exchange balance. When the short-term average falls below the long-term average, it confirms that coins have been leaving exchanges consistently, as a sustained pattern, rather than isolated events.
Using Glassnode's exchange balance for Binance, we define the following:
- Enter the market when the 5-day moving average of Binance's BTC balance falls below its 14-day moving average, signaling a sustained outflow trend.
- Exit the market when the 5-day average rises back above the 14-day average, signaling that the outflow trend has reversed and coins are returning to the exchange.
We then benchmark this strategy against simply holding BTC over the same period, starting January 1, 2024 through March 9, 2026, with an initial capital of $1,000 and 0.1% trading fees applied to each trade.
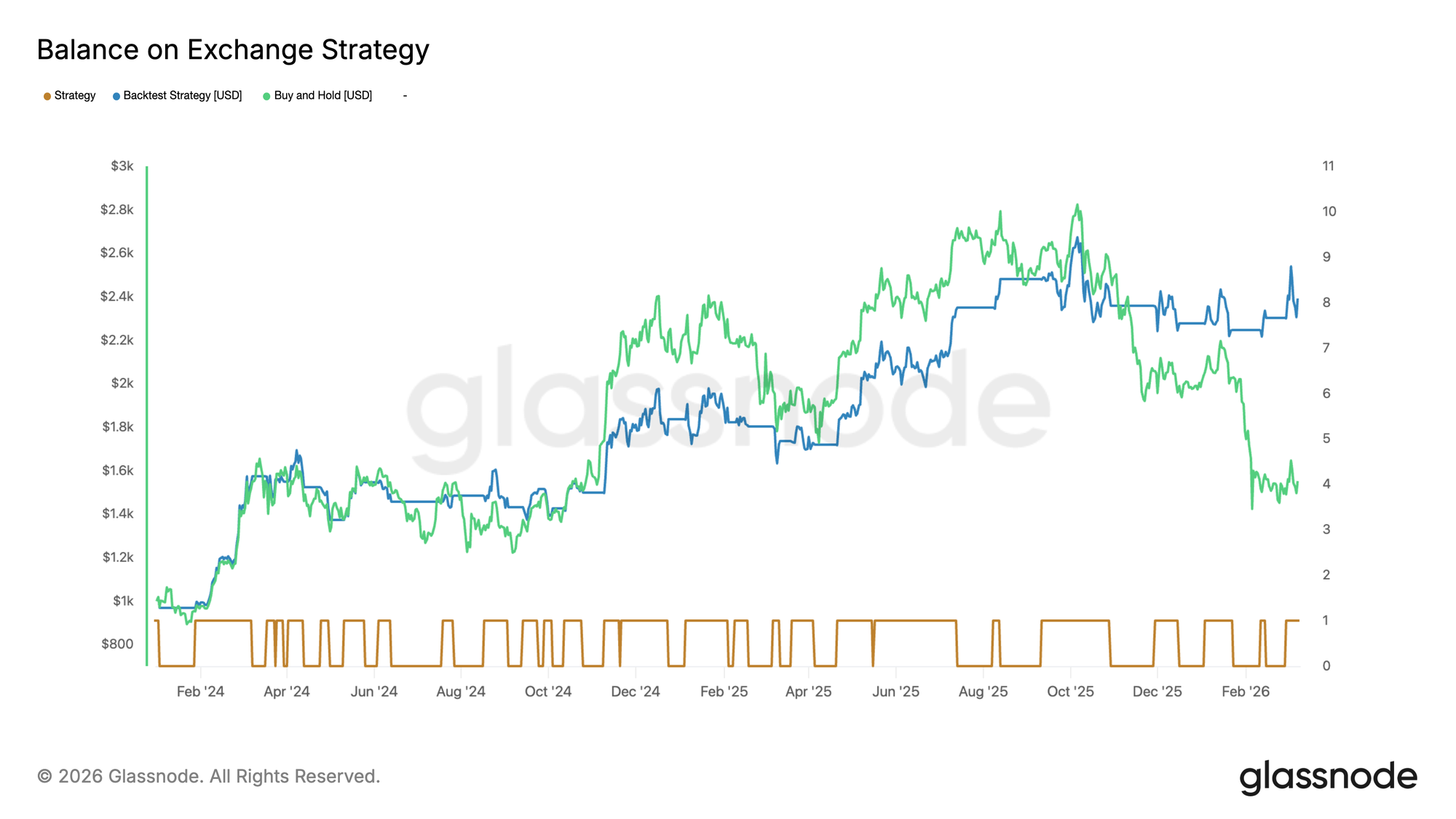
Here's how to read this chart:
🟫 The brown line at the bottom is the binary trading signal, toggling between in the market (1) and out of the market (0).
🟦 The blue line tracks the strategy's portfolio value over time.
🟩 The green line is the buy-and-hold portfolio benchmark.
We can observe that the exchange balance strategy performed reasonably well, although at times the buy-and-hold strategy outperformed it. In the final days of the research period, however, the exchange balance strategy caught up. While some investors may find the combination of reduced volatility and an ultimately comparable performance to buy-and-hold appealing, the final numbers are misleading – and here’s why.
The Problem: Data Mutation and Look-Ahead Bias
Metrics are not static. Many are retroactively revised as new information becomes available. This is particularly true for metrics that depend on address clustering or entity labeling, such as on-chain exchange balances. However, it is also the case for metrics such as trading volume or price, as individual exchanges can occasionally submit their data with slight delays.
This means that a value you see today for, say, January 15, 2024, may not be the same value that was published on January 15, 2024. The data has been revised with hindsight. When you backtest a strategy on this revised data, you are implicitly using information that was not available at the time the trading decisions would have been made. This introduces a look-ahead bias.
The Honest Backtest: Using Point-in-Time Data
Let's therefore repeat the exact same backtest – same signal logic, same parameters, same dates, same fees – but this time using the Point-in-Time (PiT) variant of the Exchange Balance metric, available in Glassnode Studio.
PiT metrics are strictly append-only and immutable. Each historical data point reflects only the information that was known at the time it was first computed. No retroactive revisions, no look-ahead bias.
While we are using the same metric, the strategy now produces significantly different results, as illustrated by the purple line in the new chart below. The overall performance is notably worse.
Although both strategies behave similarly for much of 2024, we observe that the PiT-based version fails to capture the strong upticks in November 2024 and March 2025 as effectively. As a result, the cumulative performance diverges meaningfully and ends up considerably lower.
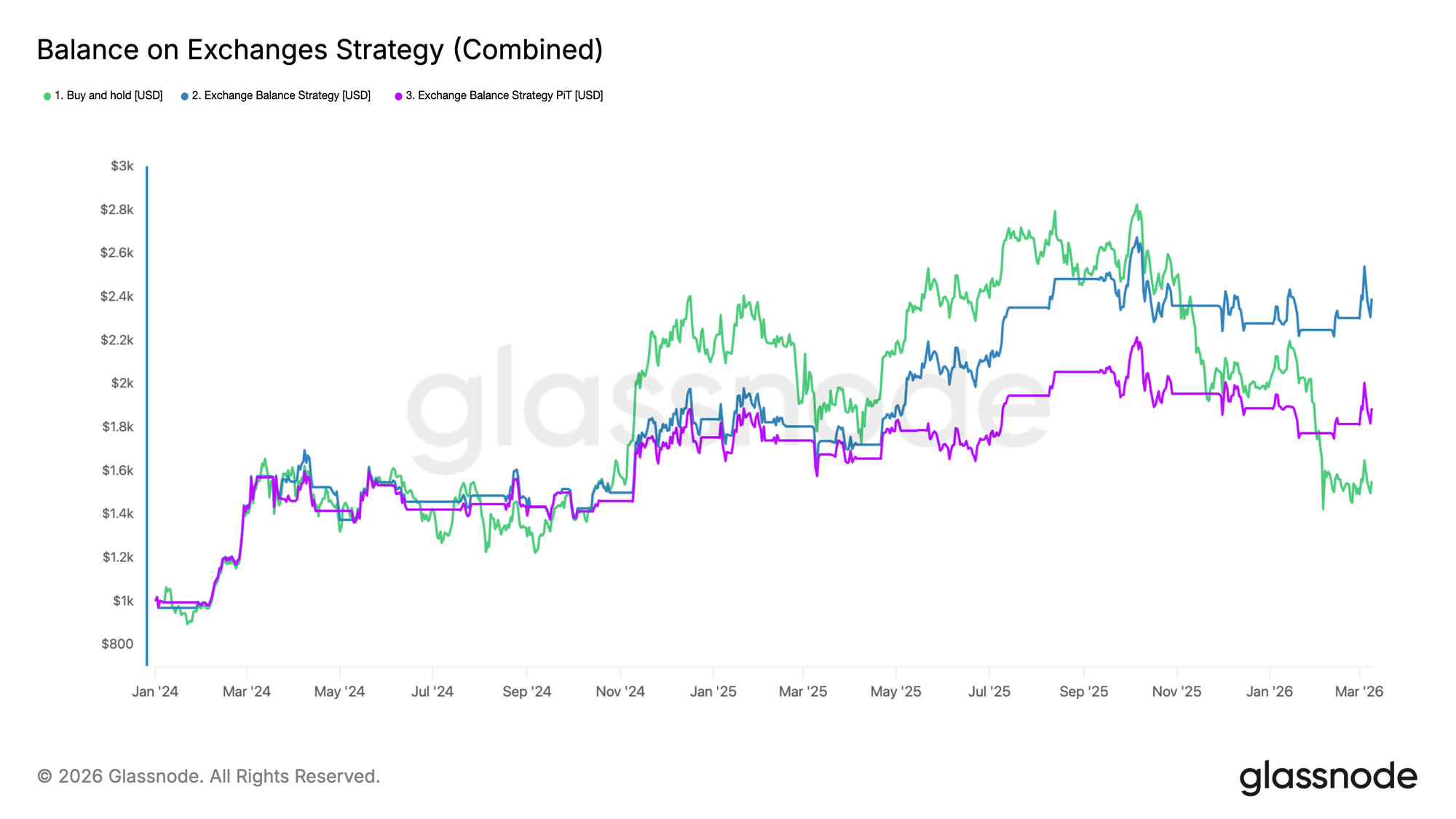
Key Takeaway
In this example, the purple strategy, which only has access to information as it was available at the time, performs noticeably worse. ► Backtests will lie if fed with wrong or revised data. Only immutable, Point-in-Time metrics ensure you’re replaying history as it actually happened.





