Recently, Anthropic published an article titled "When AI Builds Itself," which quickly sparked widespread discussion. The article revealed a striking set of internal data: as of May 2026, over 80% of the code in Anthropic's codebase had been written by Claude, with engineers merging eight times more code per day than in 2024. In an internal test, Claude improved the runtime of a piece of training code by approximately 52x over a baseline, whereas an experienced human researcher typically takes 4 to 8 hours to achieve a 4x speedup.
Anthropic points this trajectory towards a deeper destination: "Recursive Self-Improvement"—AI systems autonomously designing, building, and training their own successive versions, with humans no longer driving every step. Notably, the company also called for industry coordination to have the option to pause or even temporarily halt frontier AI development when the moment of recursive self-improvement arrives. And Anthropic is already doing this: restricting its latest Claude Fable 5 from being used for frontier AI research.
Now, Recursive Superintelligence has announced it has taken the first step toward automated AI research.
This new company co-founded by Tian Yuandong has been out of stealth mode for just one month, and has now released its first public technical achievement. They have built an open-ended automated knowledge discovery system and achieved state-of-the-art (SOTA) results on three benchmarks. Simply put, they have succeeded in making AI run experiments for you.

https://x.com/tydsh/status/2065062838255649082
The First Result: Let AI Run Experiments for You
Recursive's first public technical achievement is called "First Steps Toward Automated AI Research."

Tweet: https://x.com/Recursive_SI/status/2064980090702962699
Repo: https://github.com/recursive-org/first-steps-toward-automated-ai-research
Blog: https://www.recursive.com/articles/first-steps-toward-automated-ai-research
To summarize in one sentence, the core of this work is: building a system capable of autonomously advancing the AI research cycle and setting new records on three benchmark tests.
Before dissecting the results, it's necessary to understand the design logic of this system.
The traditional AI research process is a highly human-dependent closed loop of "propose idea—write code—run experiment—analyze results—propose new idea." Its efficiency bottleneck lies not in computing power, but in people. The number of researchers worldwide who can design frontier training pipelines is exceedingly small, and each round of experimental iteration requires their intensive involvement.
Recursive's system attempts to automate this closed loop.
Its working method is: for a clearly defined optimization objective, the system automatically proposes experimental ideas, implements code, runs validation, learns from it, and then decides how to search next. Multiple research lines can be advanced in parallel, effective discoveries can be reused across tasks, and mechanisms for detecting reward hacking are embedded within the entire loop to prevent the system from "taking shortcuts" to inflate evaluation metrics without genuinely improving anything.
This is not a specialized tool fine-tuned for a single problem, but rather a general-purpose research automation framework spanning different domains. Recursive demonstrates this using three significantly different test scenarios.
Three Battlefields, Three New Records
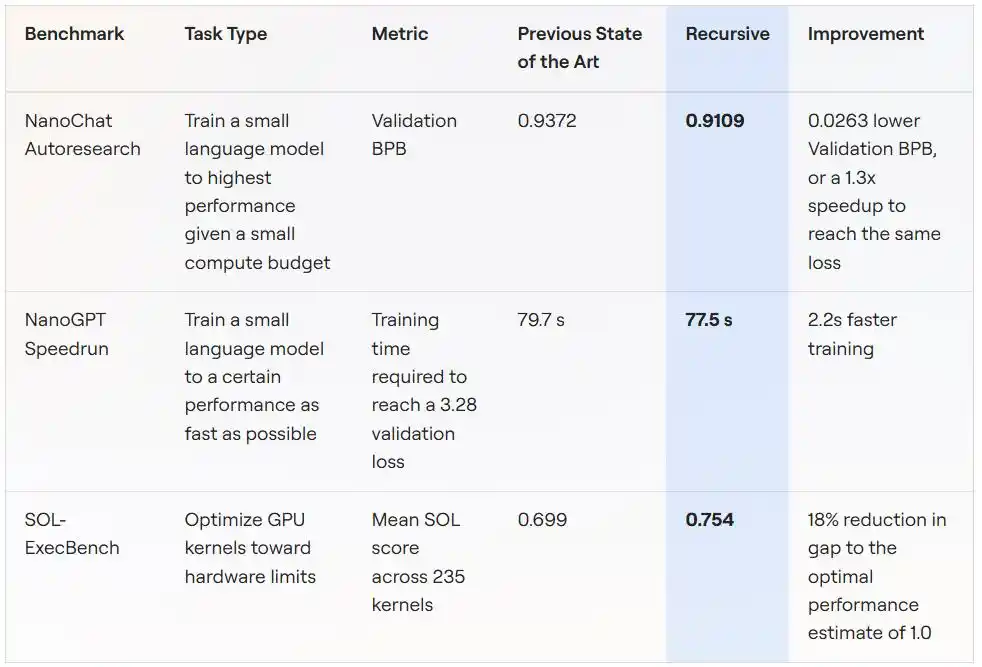
Scenario One: Small Model Training Under Fixed Compute Budget (NanoChat Autoresearch)
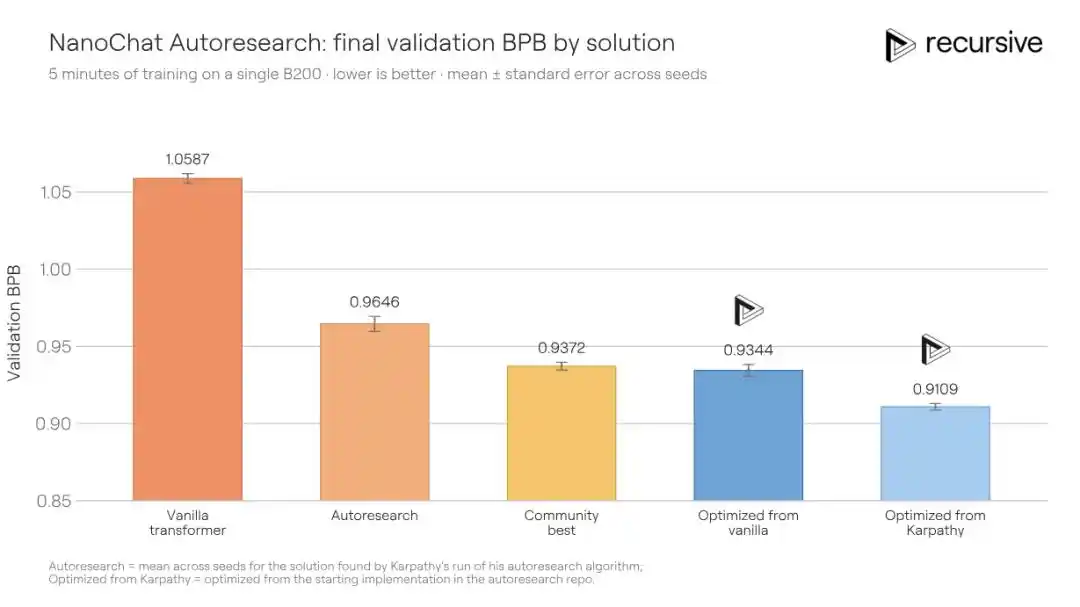
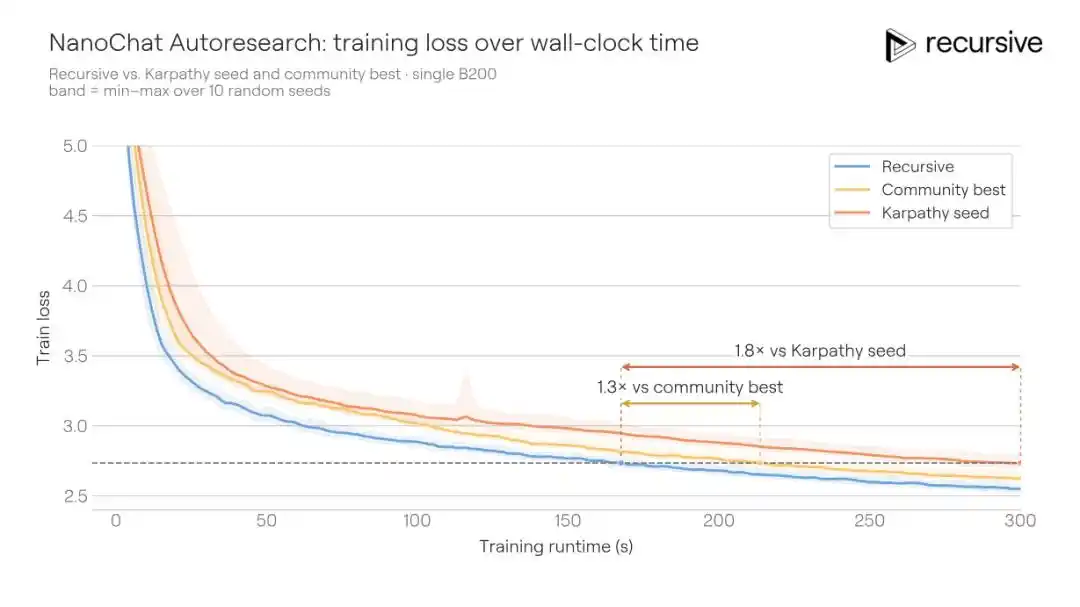
The rules for this benchmark come from the autoresearch project initiated by Andrej Karpathy (author of GPT-2, former OpenAI co-founder): on a single GPU, given a fixed training budget of five minutes, train a small language model to achieve the lowest possible validation loss (measured in BPB, lower is better).
This scenario is naturally suited for automated research: short experimental cycles, low metric variance, relatively easy detection of cheating behavior. Precisely because of this, a community project called "autoresearch@home" has been running on this benchmark for a long time—dozens of human researchers collaborating with hundreds of AI agents continuously pushing the metric down.
Recursive's system started from the same initial code and ultimately improved the validation BPB from the community's best of 0.9372 to 0.9109, an improvement of 0.0263 BPB. Put another way: to achieve the same training quality, Recursive's solution requires 1.3 times less training time than the competitor's.
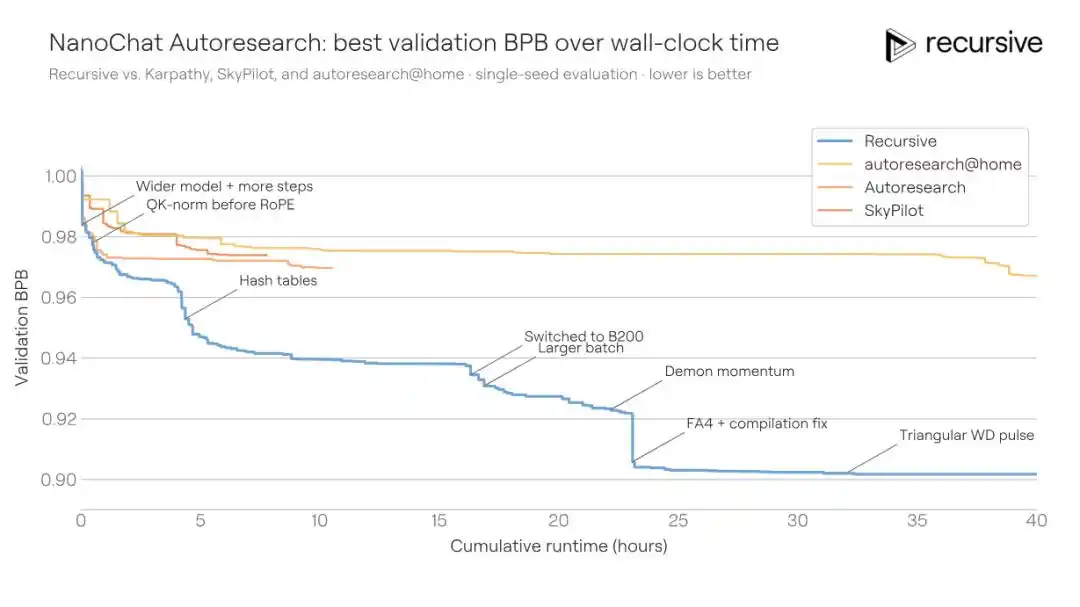
The improvements discovered by the system were not a single silver bullet. It combined architecture adjustments, auxiliary losses, attention mechanism modifications, optimizer behavior, weight decay scheduling, compiler settings, and more. One of the key discoveries was a richer short-context memory mechanism: within the attention's value path, embedding both bigram (adjacent word pairs) and trigram (triplet) information via hash tables, with weighted mixing via learnable gating. Different Transformer layers use different hash functions, reducing the probability of cross-layer collision.
This trick is conceptually related to works like DeepSeek Engram, but the system deployed it in a specific variant not yet seen in published literature for the fixed-budget scenario.
Scenario Two: Training Speed Limit Race (NanoGPT Speedrun)
If the previous scenario was about "going one step further" on an active community's results, this scenario is much harder.
NanoGPT Speedrun is another benchmark initiated by Karpathy and continuously optimized by the community for over two years: the shortest time required to train a GPT model to a validation loss of 3.28 on 8 H100 GPUs. Since mid-2024, the community has compressed the time from about 45 minutes to 79.7 seconds through 83 documented contributions. Each new solution must squeeze out more time from an already extremely optimized codebase, making the difficulty self-evident.
Recursive's system started from the existing optimal solution and further compressed the training time to 77.5 seconds, saving 2.2 seconds. This improvement is comparable to, or even better than, what recent human contributors have achieved.
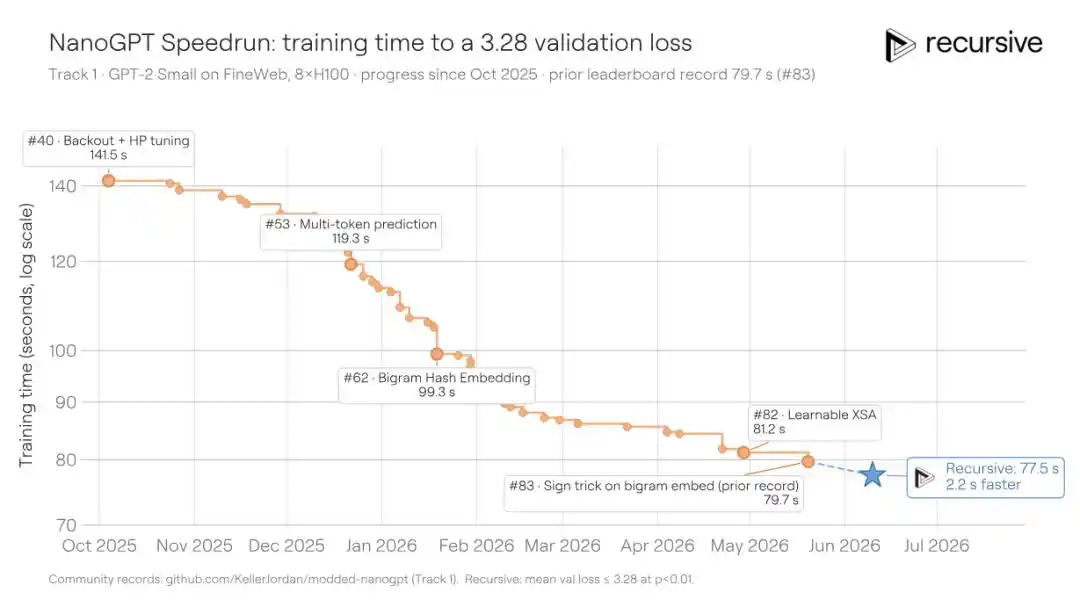
The core tricks found by the system this time include:
FP8 Precision Attention Computation. The community solution used FP8 (8-bit floating point) computation only in the model's final layer (language model head). The system extended FP8 into the matrix operations of the attention layers, using FP8 for forward propagation to achieve twice the Tensor Core throughput, while retaining BF16 for backward propagation to maintain stability.
Annealing Exploration Noise in the Optimizer. The system injected zero-mean Gaussian noise into the update steps of the NorMuon optimizer, with the noise amplitude linearly annealing to zero as training progressed. This is somewhat like giving the optimizer a behavior pattern of "explore boldly first, then converge robustly," helping the final solution settle in a flatter loss basin.
More Streamlined Fused MLP Kernel. The system rewrote a Triton GPU kernel so that forward propagation only stores activation values after ReLU squaring, and during backward propagation, the unsquared intermediate results are recomputed internally within the kernel, saving one full round-trip read/write of the activation tensor in high-bandwidth GPU memory—a direct hardware-level speedup.
Three improvements, belonging to three different specialized areas: precision strategy, optimizer design, and GPU kernel programming. The fact that the system found room for improvement on a result optimized by the community for two years speaks for itself.
Scenario Three: GPU Kernel Optimization (SOL-ExecBench)
The first two scenarios operated at the model training level. The third scenario delves deeper: optimizing GPU compute kernels.
SOL-ExecBench is a benchmark introduced by NVIDIA, containing 235 kernel writing tasks covering various real-world workloads like matrix multiplication, reduction, normalization layers, attention components, quantization routines, fused blocks, etc. The scoring metric is the SOL score: 0.5 corresponds to a baseline PyTorch implementation, and 1.0 corresponds to the hardware's theoretical limit. The previous best public score was 0.699.
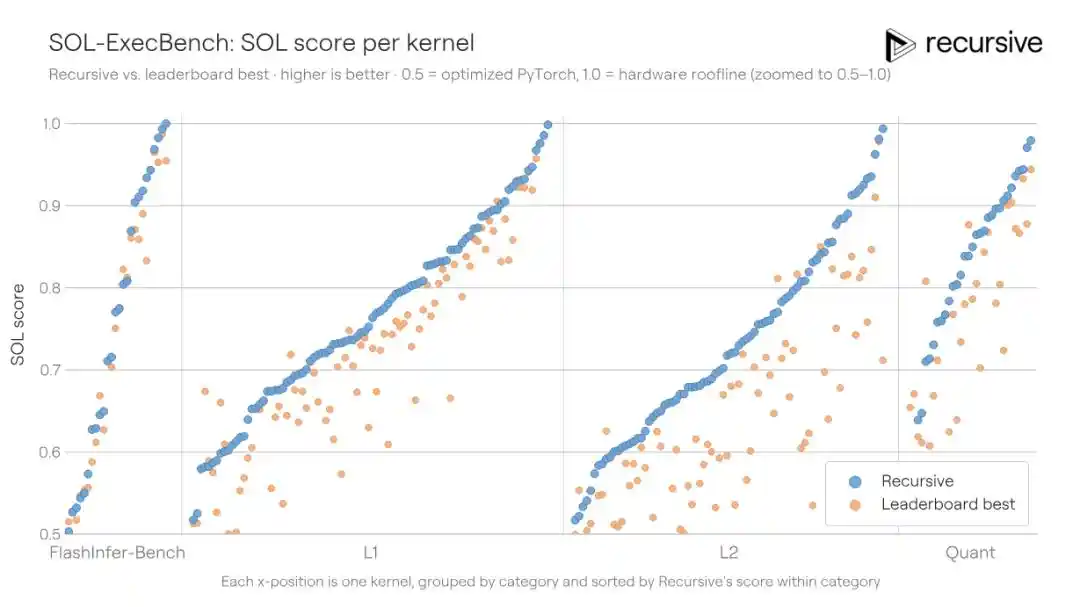
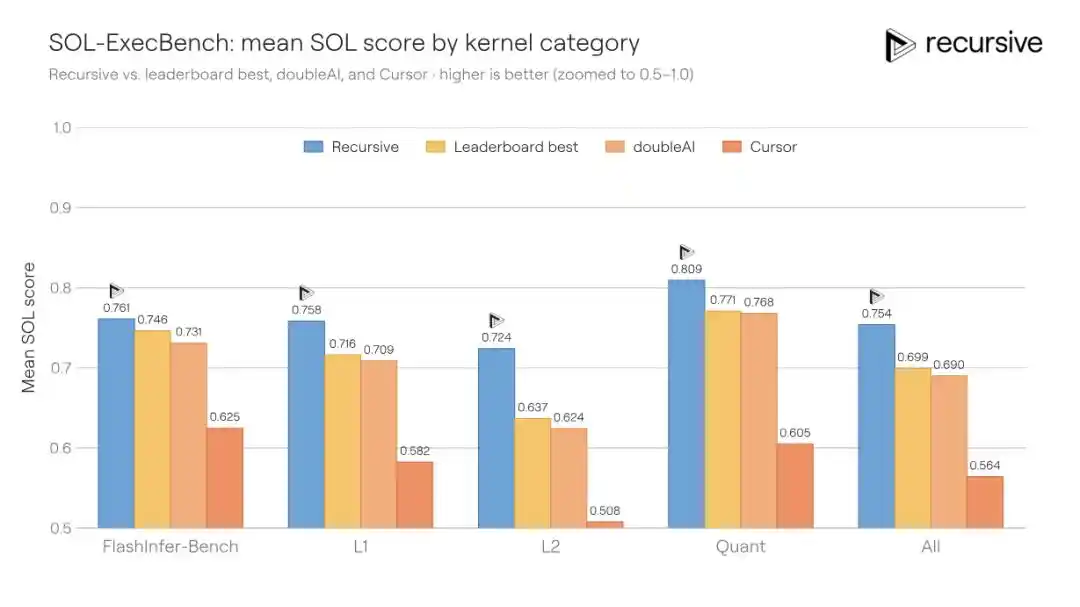
Recursive's system ran on all 235 kernels, allowing discovered optimization patterns (e.g., memory access strategies, tiling methods, reduction techniques) to be reused across tasks. The final score improved to 0.754, reducing the gap to the hardware limit by 18%.
This scenario is particularly significant because kernel engineering is an extremely specialized field—engineers who can write efficient Triton/CUDA kernels are rare globally. The Recursive team candidly admits in their blog, "We ourselves are not experts in kernel engineering. These ideas came from the system itself, not from our specialized background."
Recursive: Using AI to Research and Recursively Improve AI
The company releasing this achievement, Recursive Superintelligence, was founded between late 2025 and early 2026 and only came out of stealth last month. In addition to Tian Yuandong, former Research Scientist Director at Meta FAIR, the founding team includes:
Richard Socher, Recursive CEO, former Chief Scientist at Salesforce.
Alexey Dosovitskiy, former Google DeepMind Research Scientist and first author of Vision Transformer, with over 160,000 Google Scholar citations.
Tim Rocktäschel, former DeepMind Principal Scientist and UCL AI Professor.
Peter Norvig, former Google Director of Research, co-author with Stuart Russell of the famous AI textbook "Artificial Intelligence: A Modern Approach."
Caiming Xiong, former VP of AI at Salesforce.
Tim Shi, former OpenAI researcher, co-founder and CTO of enterprise AI company Cresta.
Josh Tobin, Recursive CTO, former Research Lead at OpenAI and Uber ATG.
Jeff Clune, former VP of Research at Google DeepMind, Professor of Computer Science at the University of British Columbia, Canada.
Remarkably, this startup, without even having a public product yet, has already secured $650 million in funding with a valuation of $4.65 billion, led by GV (Google Ventures) and Greycroft, with follow-on investment from NVIDIA and AMD Ventures.
The company's core proposition directly corresponds to its name: building AI systems that can recursively enhance their own research capabilities, allowing AI to participate in and accelerate the R&D process of AI itself, ultimately forming a self-reinforcing closed loop.
For more details, refer to the report "After Leaving Meta, Tian Yuandong Just Announced His Startup."
Of course, Recursive is not alone in this arena. Yann LeCun's AMI Labs raised $1 billion in March this year, and David Silver's Ineffable Intelligence secured a $1.1 billion seed round in April, both pointing in a similar direction: enabling AI systems to autonomously generate knowledge and reduce human intervention in the research process. However, in terms of the pace of public achievements, Recursive's "First Steps" is likely one of the most concrete and reproducible technical demonstrations among similar companies to date.
The Dawn of the Recursive Paradigm
Placed within the broader industry context, Recursive's released achievement represents the preliminary realization of a new type of AI R&D paradigm: making the AI system itself the primary agent of research.
The core logic of this "recursive AI" is not complicated: AI enhances AI research capabilities, and the improved AI can then more effectively enhance itself, in a virtuous cycle. It does not rely on a single breakthrough, but on a system that continuously generates breakthroughs.
This approach has significant implications for the economics of AI research itself. The training pipelines for frontier models still heavily depend on a small number of researchers with specific skills, numbering no more than a few thousand globally. If automated research systems can take over even a portion of this work, both the speed and cost curve of AI progress will change.
This assessment also echoes other recent voices from the industry. For instance, Anthropic's "When AI Builds Itself" mentioned at the beginning of this article has a serious tone—it calls for industry coordination to have options to pause or temporarily halt frontier AI development when the moment of recursive self-improvement arrives, to allow time for societal structures and alignment research to catch up. For more details, see "AI Self-Evolution Too Fast, Anthropic Calls for Global Halt on R&D."

https://www.anthropic.com/institute/recursive-self-improvement
These two events happening simultaneously are thought-provoking. On one side, Anthropic is documenting and warning about the direction of this trajectory; on the other side, teams like Recursive are making step-by-step progress to turn this trajectory into reality.
Of course, Recursive itself acknowledges this is still the "first step": the current system works best in scenarios with clear metrics, rapid feedback, and detectable cheating. There is still considerable distance from autonomously advancing open scientific questions. Preventing reward hacking will be a core challenge on the path to scaling.
But a closed loop has begun to turn. The question now is simply how fast it will spin.
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Machine Heart in Recursive Evolution, editor: Panda






