Author: Li Yuan
Have you ever asked an AI assistant about your health problems?
If you are a heavy user of AI like me, you probably have.
According to OpenAI's own data, health has become one of the most common use cases for ChatGPT, with over 230 million people worldwide asking health and wellness-related questions every week.
Because of this, as we move into 2026, the health field is showing strong signs of becoming a battleground in the AI sector.
On January 7th, OpenAI launched ChatGPT Health, allowing users to connect electronic medical records and various health apps to get more targeted medical responses; and on January 12th, Anthropic immediately launched Claude for Healthcare, emphasizing the new model's capabilities in medical scenarios.
Interestingly, this time, a Chinese company is not lagging behind, and even seems to be taking the lead.
On January 13th, Baichuan Intelligence announced the release of the Baichuan M3 model, which surpassed OpenAI's GPT-5.2 High on HealthBench, a medical and health evaluation test set released by OpenAI, achieving SOTA.
After facing much skepticism for announcing an All-in strategy on healthcare, Baichuan Intelligence seems to have finally proven itself. Geek Park specifically spoke with Wang Xiaochuan to discuss how Baichuan Intelligence views the capabilities of this M3 model and the endgame of AI in healthcare.
01 First to Surpass OpenAI on a Health Domain Test Set
One of the most eye-catching achievements of the newly released M3 model is that it surpassed OpenAI's GPT-5.2 High for the first time on HealthBench, a medical and health evaluation test set released by OpenAI, achieving SOTA.
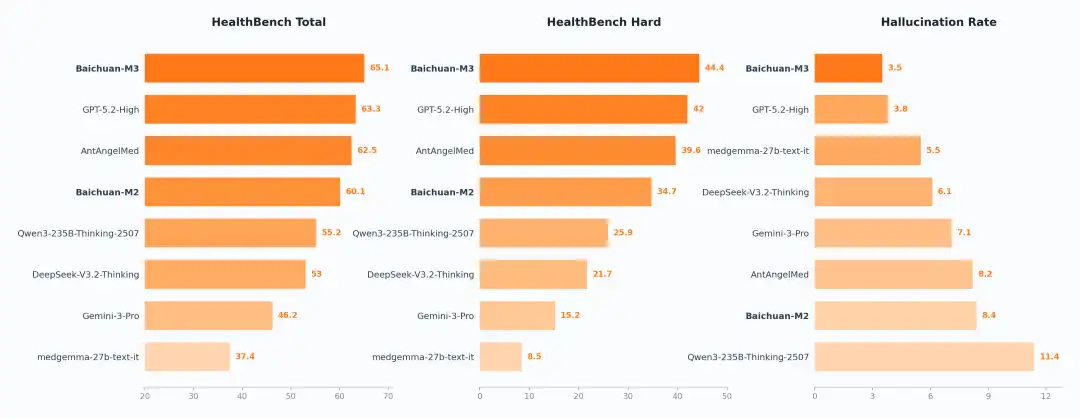
SOTA On Healthbench, Healthbench Hard and Hallucination Evaluation
Healthbench is a medical and health evaluation test set released by OpenAI in May 2025. It was built by 262 doctors from 60 countries and contains 5000 sets of highly realistic multi-turn medical dialogues. It is one of the most authoritative and clinically realistic medical evaluation sets globally.
Since its release, OpenAI's models have dominated the rankings.
This time, however, Baichuan Intelligence's new generation open-source medical large model, Baichuan-M3, achieved a comprehensive score of 65.1, ranking first globally. It even topped the charts on HealthBench Hard, which specifically tests complex decision-making abilities, setting a new high score.
Baichuan also simultaneously released a hallucination rate test result. The M3 model achieved a hallucination rate of 3.5%, among the lowest globally.
It is worth noting that this hallucination rate is measured in a pure model setting without relying on external retrieval tools.
Baichuan Intelligence stated that the key model improvement enabling these two points is the introduction of a reinforcement learning algorithm suitable for healthcare.
Baichuan首次在M3模型上使用了Fact Aware RL(事实感知强化学习)技术,达到了既让模型不说套话,也不让模型乱说话的效果。
This is actually very critical in the medical field.
When asking medical questions to an unoptimized model, the most common problems are two types: one is the model directly fabricating your symptoms and臆测ing a disease; the other is semantic ambiguity, ultimately suggesting you still need to see a doctor, which isn't very helpful for either doctors or patients.
This is precisely because many models use pure hallucination rate as the optimization target. At this point, the model might dilute the overall hallucination rate by piling up simple, correct facts. Baichuan introduced semantic clustering and importance weighting mechanisms—clustering eliminates interference from redundant expressions, and weighting ensures core medical assertions receive higher weight.
At the same time, if a high-weight hallucination penalty is simply introduced, it极易forces the model into a "say less, make fewer mistakes" conservative strategy. Therefore, the Fact Aware RL algorithm also includes a dynamic weight adjustment mechanism, adaptively balancing these two goals based on the model's current capability level—focusing on medical knowledge learning and expression (high Task Weight) during the capability building phase; and gradually tightening factual constraints (increasing Hallucination Weight) after capabilities mature.
When internet search is available, Baichuan also added an online verification module based on multi-turn search and introduced an efficient caching system for aligning massive medical knowledge.
02 Consultation Level Surpasses Human Doctors, Entering the Usable Stage
However, surpassing OpenAI on Healthbench is not the only highlight this time.
A more interesting point is that Baichuan creatively built its own SCAN-bench evaluation set. Compared to just topping OpenAI's leaderboard, the evaluation set built by Baichuan itself might better illustrate the direction Baichuan Intelligence wants to optimize for in healthcare.
The key point of this evaluation set built by Baichuan is to optimize "end-to-end consultation capability." This stems from an insight from Baichuan's own experiments: for every 2% increase in consultation accuracy, diagnosis accuracy increases by 1%.
That is, compared to OpenAI's HealthBench, which still mainly focuses on "whether the AI can answer questions," Baichuan's SCAN-bench hopes to evaluate: can the AI, in a Q&A process, obtain effective information and simultaneously provide correct diagnosis results and medical advice.
Usually, when we ask an AI assistant a question, if we just mention "you are an experienced doctor," we typically don't get very good model performance. Because a real doctor's consultation process is very standardized—Baichuan归纳izes it into four quadrants of the SCAN principle: Safety Stratification, Clarity Matters, Association & Inquiry, and Normative Protocol.
Centered around the SCAN principle, Baichuan,借鉴ing the OSCE method long used in medical education and collaborating with over 150 frontline doctors, built the SCAN-bench evaluation system. It breaks down the diagnosis process into three stages: medical history collection, auxiliary examination, and precise diagnosis, assessing them through dynamic, multi-turn methods, completely simulating the doctor's process from consultation to diagnosis, and also optimizing the model by achieving better results in these processes.
This time, Baichuan also announced the M3 model's evaluation results on SCAN-bench.
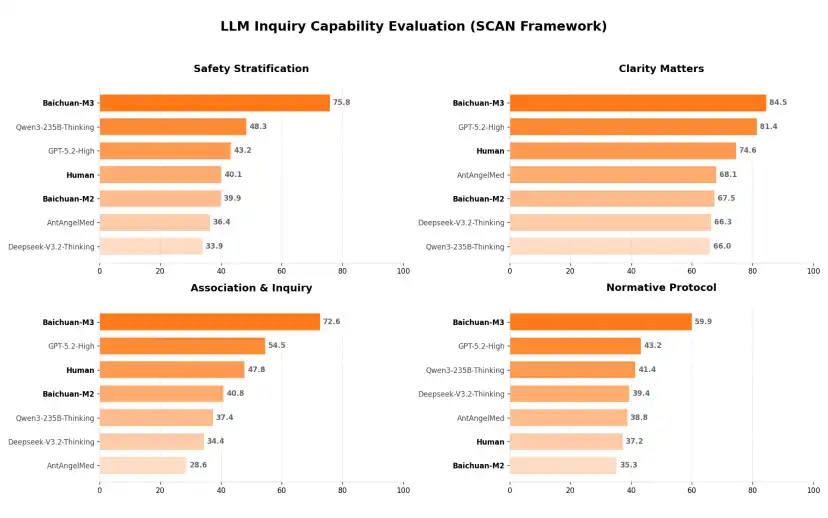
The results are very interesting. Baichuan not only compared with other models this time but also brought in real doctors for comparison. And in the four quadrants, the real doctors have actually fallen behind the level that the model can achieve.
Geek Park specifically asked the Baichuan team about this and received the answer: this evaluation involved real specialist doctors comparing with the model on specialist cases. The model won, firstly, because the model is more patient, but more importantly, the model has better mastery of interdisciplinary knowledge.
For example, in one case involving a 10-year-old child with recurrent fever—fever is a very comprehensive medical phenomenon. If only asking about cough and other lung conditions, it's easy to overlook serious problems in the joints and urinary system, misdiagnosing it as a common infection.
Human doctors are usually only good at conditions within their specialty, which is why complex symptoms often require specialist consultations, or even experts for difficult and complicated diseases often need to consult books and find information.
Ordinary models that haven't been specifically trained, just扮演ing doctors, often struggle to answer such questions well.
03 Next Step: Gradually Start Making C-end Products, Promoting More Serious Healthcare
For Baichuan Intelligence, surpassing human doctors is a very significant milestone: it means AI is starting to cross the usability threshold and can begin to be deployed in usage scenarios.
Starting January 13th, users can already experience the answers provided by the M3 model on the Baixiaoying website and app.
The current website design is very interesting. Although both use the M3 model for answers, they are differentiated into a doctor version and a user version. In the doctor version, the answers are more concise, cite more references, and are more "not speaking in layman's terms." In the ordinary patient version, the model almost never gives an answer all at once; it will ask more follow-up questions and provide a clearer diagnosis.

Baichuan Intelligence mentioned that the model's backend thinking is很有意思. "We often see the model mention in its chain of thought, 'This patient didn't answer my question, but I must ask this question.' We've even seen extreme cases where it says, 'I've already asked the patient 20 rounds, which has exceeded the set maximum number of rounds, but I still have to ask this question.' This is because during training, the model doesn't get rewarded for being slick with its words; it only gets rewarded if it truly obtains enough key information and makes the correct diagnosis. This is a clear difference between how we train our models and how others do."
Many AI companies have recently started介入 the medical field. This is also where Baichuan Intelligence sees its biggest difference—it wants to do more serious healthcare.
"This means that when Baichuan chooses a scenario, it's not about which scenario is easiest to do. On the contrary, Baichuan insists on continuously pushing technological capabilities and challenging more difficult problems," Wang Xiaochuan said.
A typical example is that Baichuan will prioritize solving scenarios in oncology, while psychological healing is lower on Baichuan's priority list.
In popular opinion, it's generally believed that AI providing psychological healing is simpler and an easier scenario to implement. Baichuan's judgment logic is different. They believe the oncology field has stricter scientific basis. Here, AI is more likely to produce serious medical effects,从而达到 or even surpass the level of human doctors. In contrast, the field of psychology lacks this kind of deterministic scientific anchor point.
Another example is that some companies choose to create avatars for doctors. Wang Xiaochuan believes this direction is not what Baichuan wants to do. A doctor's avatar itself cannot fully reuse the doctor's level of ability, let alone surpass it. Such AI can only end up being a幌子 and a customer acquisition tool, not truly promoting serious healthcare.
This insistence on seriousness deeply affects many of Baichuan's business choices.
This is directly related to Wang Xiaochuan's thinking on the fundamental issues of the next stage of medical AI. He believes that the most important task at the current stage is to gradually provide more medical supply based on enhancing AI capabilities.
China has been trying to implement a hierarchical diagnosis and treatment system and a general practitioner system for many years. The original intention was希望老百姓 to first seek medical care at the grassroots level, solving the problems of difficult appointments, long queues, and severe congestion in large hospitals.
The reason this system has been difficult to推行 is essentially due to insufficient supply of medical resources. Grassroots medical institutions lack high-level doctors. People are willing to queue at tertiary hospitals even for a cold because they distrust the diagnostic level at the grassroots level.
This is the key point where medical AI can play a role. Large models can achieve规模化 distribution of top-tier medical knowledge. They fill the supply gap at the grassroots level, allowing every community, every family to possess diagnostic capabilities like experts from tertiary hospitals.
In the long run, this can have a broader impact, potentially shifting the decision-making power in healthcare from doctors to users. In traditional medical scenarios, patients are the beneficiaries but often lack decision-making power. Decision-making power is concentrated in the hands of doctors. This power asymmetry often leads to communication costs and suffering during treatment.
Baichuan hopes that through AI, patients can more easily access the supply of high-quality medical resources. "Many people think medicine is too complex, and patients will never understand it. But we think about the jury system in the US judicial system. Law is also a very professional matter. The ordinary people on the jury don't understand, so it requires the judge, lawyers, and prosecutors to lead, engage in full debate, make things clear to a level where ordinary people can judge guilt or innocence, allowing ordinary people to make normal judgments based on logic," Wang Xiaochuan said.
This is also one of the reasons why Baichuan Intelligence is unwilling to only work on simple scenarios but hopes to continuously advance towards high-difficulty serious diagnosis and treatment.
When asked whether solving high-difficulty problems is the most commercially rewarding, Wang Xiaochuan gave a profound answer.
He believes that solving minor problems like colds and fevers很难 builds sufficient trust in the users' minds. Healthcare is an industry highly dependent on trust. Only when AI can solve high-difficulty problems like serious illnesses can it truly establish a foundation of trust.
From a commercial logic perspective, patients facing serious health problems are also more willing to pay for high-quality AI services. This trust is not only a prerequisite for commercial回报 but also the core for the scalable application of AI in healthcare.
On a more fundamental level, healthcare for Baichuan Intelligence and Wang Xiaochuan personally still represents a path approaching Artificial General Intelligence (AGI).
Wang Xiaochuan believes that AI has already found practical solutions in fields like literature, science, engineering, and art, but healthcare is an extremely unique field. Human exploration of medicine has not been exhausted, and AI is also in a exploratory stage in this field.
Baichuan's roadmap is very clear. First, use AI to improve diagnostic efficiency and solve the current shortage of medical supply. On this basis, Baichuan is committed to建立 deep trust with patients. When patients are willing to use AI tools for long-term medical consultations, AI can accumulate real and high-quality medical data during long-term companionship.
The ultimate goal of this data is to build a mathematical model of life. This is a path that human doctors have not yet fully traversed, and it is highly likely that AI will achieve it first in the future. If modeling the essence of life can be completed, it will become a key step in pushing general artificial intelligence towards higher-level progress.






