Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
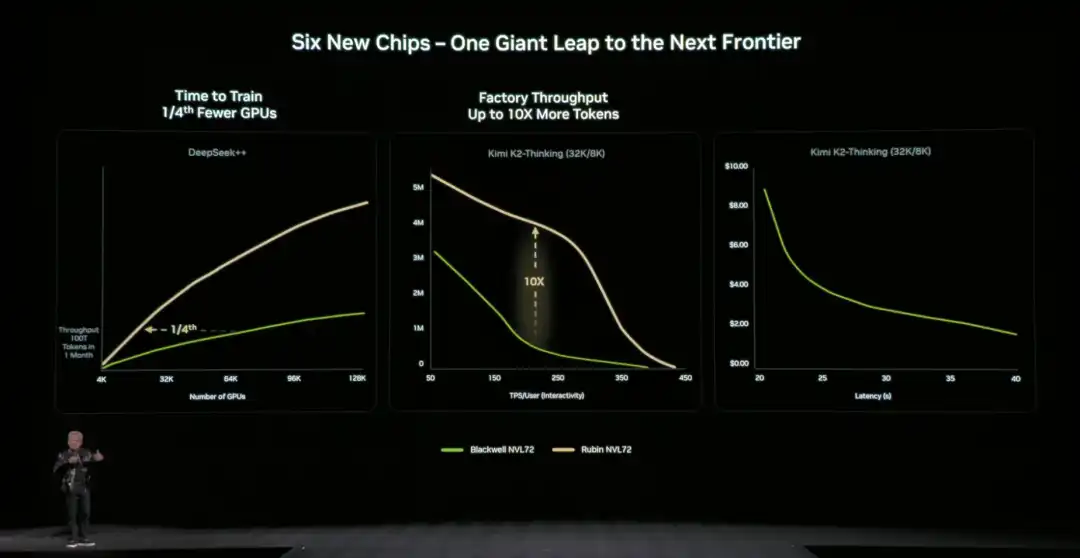
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
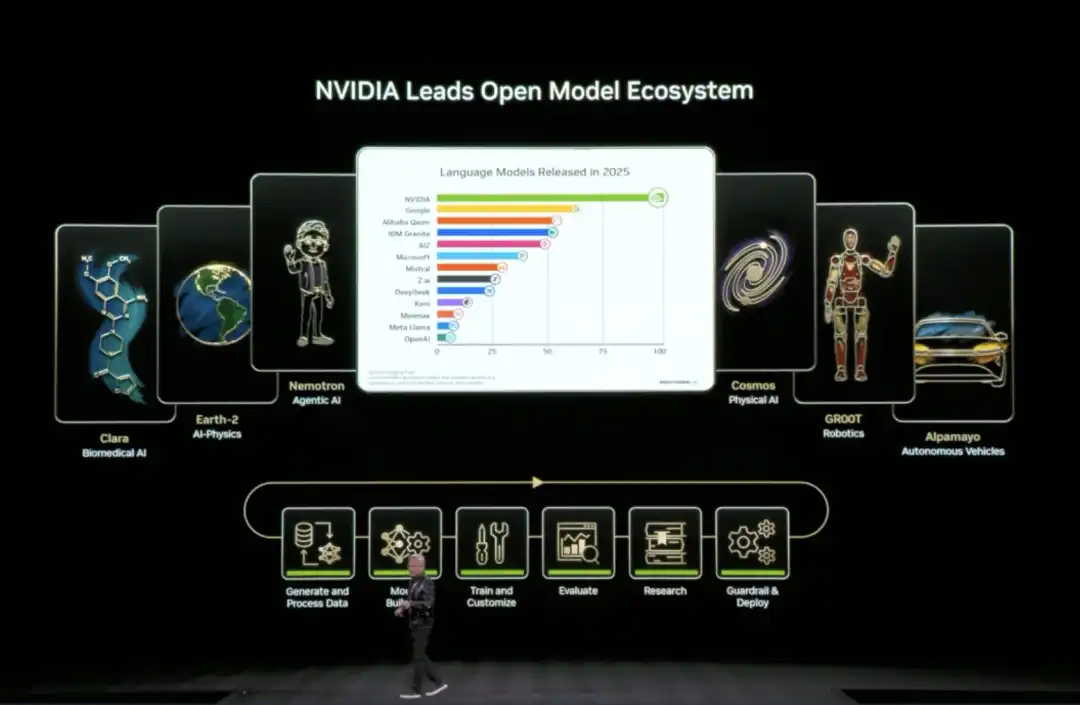
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
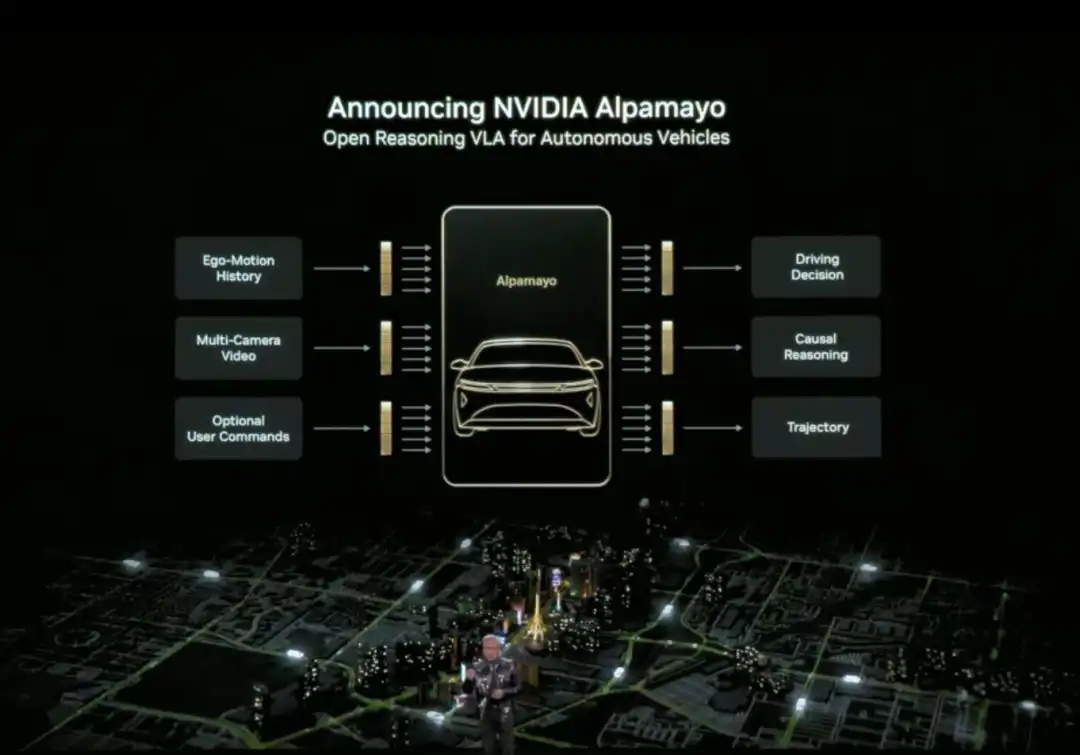
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
Crypto di tendenza
Domande pertinenti
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?![]()
AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?![]()
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?![]()
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?![]()
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?![]()
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
Letture associate





Trading
Articoli Popolari
Cosa è $S$
Comprendere SPERO: Una Panoramica Completa Introduzione a SPERO Mentre il panorama dell'innovazione continua a evolversi, l'emergere delle tecnologie web3 e dei progetti di criptovaluta gioca un ruolo fondamentale nel plasmare il futuro digitale. Un progetto che ha attirato l'attenzione in questo campo dinamico è SPERO, denotato come SPERO,$$s$. Questo articolo mira a raccogliere e presentare informazioni dettagliate su SPERO, per aiutare gli appassionati e gli investitori a comprendere le sue basi, obiettivi e innovazioni nei domini web3 e crypto. Che cos'è SPERO,$$s$? SPERO,$$s$ è un progetto unico all'interno dello spazio crypto che cerca di sfruttare i principi della decentralizzazione e della tecnologia blockchain per creare un ecosistema che promuove l'impegno, l'utilità e l'inclusione finanziaria. Il progetto è progettato per facilitare interazioni peer-to-peer in modi nuovi, fornendo agli utenti soluzioni e servizi finanziari innovativi. Al suo interno, SPERO,$$s$ mira a responsabilizzare gli individui fornendo strumenti e piattaforme che migliorano l'esperienza dell'utente nello spazio delle criptovalute. Questo include la possibilità di metodi di transazione più flessibili, la promozione di iniziative guidate dalla comunità e la creazione di percorsi per opportunità finanziarie attraverso applicazioni decentralizzate (dApps). La visione sottostante di SPERO,$$s$ ruota attorno all'inclusività, cercando di colmare le lacune all'interno della finanza tradizionale mentre sfrutta i vantaggi della tecnologia blockchain. Chi è il Creatore di SPERO,$$s$? L'identità del creatore di SPERO,$$s$ rimane piuttosto oscura, poiché ci sono risorse pubblicamente disponibili limitate che forniscono informazioni dettagliate sul suo fondatore o fondatori. Questa mancanza di trasparenza può derivare dall'impegno del progetto per la decentralizzazione—un ethos che molti progetti web3 condividono, dando priorità ai contributi collettivi rispetto al riconoscimento individuale. Centrando le discussioni attorno alla comunità e ai suoi obiettivi collettivi, SPERO,$$s$ incarna l'essenza dell'empowerment senza mettere in evidenza individui specifici. Pertanto, comprendere l'etica e la missione di SPERO rimane più importante che identificare un creatore singolo. Chi sono gli Investitori di SPERO,$$s$? SPERO,$$s$ è supportato da una varietà di investitori che vanno dai capitalisti di rischio agli investitori angelici dedicati a promuovere l'innovazione nel settore crypto. Il focus di questi investitori generalmente si allinea con la missione di SPERO—dando priorità a progetti che promettono avanzamenti tecnologici sociali, inclusività finanziaria e governance decentralizzata. Queste fondazioni di investitori sono tipicamente interessate a progetti che non solo offrono prodotti innovativi, ma contribuiscono anche positivamente alla comunità blockchain e ai suoi ecosistemi. Il supporto di questi investitori rafforza SPERO,$$s$ come un concorrente degno di nota nel dominio in rapida evoluzione dei progetti crypto. Come Funziona SPERO,$$s$? SPERO,$$s$ impiega un framework multifunzionale che lo distingue dai progetti di criptovaluta convenzionali. Ecco alcune delle caratteristiche chiave che sottolineano la sua unicità e innovazione: Governance Decentralizzata: SPERO,$$s$ integra modelli di governance decentralizzati, responsabilizzando gli utenti a partecipare attivamente ai processi decisionali riguardanti il futuro del progetto. Questo approccio favorisce un senso di proprietà e responsabilità tra i membri della comunità. Utilità del Token: SPERO,$$s$ utilizza il proprio token di criptovaluta, progettato per servire varie funzioni all'interno dell'ecosistema. Questi token abilitano transazioni, premi e la facilitazione dei servizi offerti sulla piattaforma, migliorando l'impegno e l'utilità complessivi. Architettura Stratificata: L'architettura tecnica di SPERO,$$s$ supporta la modularità e la scalabilità, consentendo un'integrazione fluida di funzionalità e applicazioni aggiuntive man mano che il progetto evolve. Questa adattabilità è fondamentale per mantenere la rilevanza nel panorama crypto in continua evoluzione. Coinvolgimento della Comunità: Il progetto enfatizza iniziative guidate dalla comunità, impiegando meccanismi che incentivano la collaborazione e il feedback. Nutrendo una comunità forte, SPERO,$$s$ può affrontare meglio le esigenze degli utenti e adattarsi alle tendenze di mercato. Focus sull'Inclusione: Offrendo basse commissioni di transazione e interfacce user-friendly, SPERO,$$s$ mira ad attrarre una base utenti diversificata, inclusi individui che potrebbero non aver precedentemente interagito nello spazio crypto. Questo impegno per l'inclusione si allinea con la sua missione generale di empowerment attraverso l'accessibilità. Cronologia di SPERO,$$s$ Comprendere la storia di un progetto fornisce preziose intuizioni sulla sua traiettoria di sviluppo e sui traguardi. Di seguito è riportata una cronologia suggerita che mappa eventi significativi nell'evoluzione di SPERO,$$s$: Fase di Concettualizzazione e Ideazione: Le idee iniziali che formano la base di SPERO,$$s$ sono state concepite, allineandosi strettamente con i principi di decentralizzazione e focus sulla comunità all'interno dell'industria blockchain. Lancio del Whitepaper del Progetto: Dopo la fase concettuale, è stato rilasciato un whitepaper completo che dettaglia la visione, gli obiettivi e l'infrastruttura tecnologica di SPERO,$$s$ per suscitare interesse e feedback dalla comunità. Costruzione della Comunità e Prime Interazioni: Sono stati effettuati sforzi attivi di outreach per costruire una comunità di early adopters e potenziali investitori, facilitando discussioni attorno agli obiettivi del progetto e ottenendo supporto. Evento di Generazione del Token: SPERO,$$s$ ha condotto un evento di generazione del token (TGE) per distribuire i propri token nativi ai primi sostenitori e stabilire una liquidità iniziale all'interno dell'ecosistema. Lancio della Prima dApp: La prima applicazione decentralizzata (dApp) associata a SPERO,$$s$ è stata attivata, consentendo agli utenti di interagire con le funzionalità principali della piattaforma. Sviluppo Continuo e Partnership: Aggiornamenti e miglioramenti continui alle offerte del progetto, inclusi partnership strategiche con altri attori nello spazio blockchain, hanno plasmato SPERO,$$s$ in un concorrente competitivo e in evoluzione nel mercato crypto. Conclusione SPERO,$$s$ rappresenta una testimonianza del potenziale del web3 e delle criptovalute di rivoluzionare i sistemi finanziari e responsabilizzare gli individui. Con un impegno per la governance decentralizzata, il coinvolgimento della comunità e funzionalità progettate in modo innovativo, apre la strada verso un panorama finanziario più inclusivo. Come per qualsiasi investimento nello spazio crypto in rapida evoluzione, si incoraggiano potenziali investitori e utenti a ricercare approfonditamente e a impegnarsi in modo riflessivo con gli sviluppi in corso all'interno di SPERO,$$s$. Il progetto mostra lo spirito innovativo dell'industria crypto, invitando a ulteriori esplorazioni delle sue innumerevoli possibilità. Mentre il percorso di SPERO,$$s$ è ancora in fase di sviluppo, i suoi principi fondamentali potrebbero effettivamente influenzare il futuro di come interagiamo con la tecnologia, la finanza e tra di noi in ecosistemi digitali interconnessi.
181 Totale visualizzazioniPubblicato il 2024.12.17Aggiornato il 2024.12.17

Cosa è AGENT S
Agent S: Il Futuro dell'Interazione Autonoma in Web3 Introduzione Nel panorama in continua evoluzione di Web3 e criptovalute, le innovazioni stanno costantemente ridefinendo il modo in cui gli individui interagiscono con le piattaforme digitali. Uno di questi progetti pionieristici, Agent S, promette di rivoluzionare l'interazione uomo-computer attraverso il suo framework agentico aperto. Aprendo la strada a interazioni autonome, Agent S mira a semplificare compiti complessi, offrendo applicazioni trasformative nell'intelligenza artificiale (AI). Questa esplorazione dettagliata approfondirà le complessità del progetto, le sue caratteristiche uniche e le implicazioni per il dominio delle criptovalute. Cos'è Agent S? Agent S si presenta come un innovativo framework agentico aperto, progettato specificamente per affrontare tre sfide fondamentali nell'automazione dei compiti informatici: Acquisizione di Conoscenze Specifiche del Dominio: Il framework apprende in modo intelligente da varie fonti di conoscenza esterne ed esperienze interne. Questo approccio duale gli consente di costruire un ricco repository di conoscenze specifiche del dominio, migliorando le sue prestazioni nell'esecuzione dei compiti. Pianificazione su Lungo Orizzonte di Compiti: Agent S impiega una pianificazione gerarchica potenziata dall'esperienza, un approccio strategico che facilita la suddivisione e l'esecuzione efficiente di compiti complessi. Questa caratteristica migliora significativamente la sua capacità di gestire più sottocompiti in modo efficiente ed efficace. Gestione di Interfacce Dinamiche e Non Uniformi: Il progetto introduce l'Interfaccia Agente-Computer (ACI), una soluzione innovativa che migliora l'interazione tra agenti e utenti. Utilizzando Modelli Linguistici Multimodali di Grandi Dimensioni (MLLM), Agent S può navigare e manipolare senza sforzo diverse interfacce grafiche utente. Attraverso queste caratteristiche pionieristiche, Agent S fornisce un framework robusto che affronta le complessità coinvolte nell'automazione dell'interazione umana con le macchine, preparando il terreno per innumerevoli applicazioni nell'AI e oltre. Chi è il Creatore di Agent S? Sebbene il concetto di Agent S sia fondamentalmente innovativo, informazioni specifiche sul suo creatore rimangono elusive. Il creatore è attualmente sconosciuto, il che evidenzia sia la fase embrionale del progetto sia la scelta strategica di mantenere i membri fondatori sotto anonimato. Indipendentemente dall'anonimato, l'attenzione rimane sulle capacità e sul potenziale del framework. Chi sono gli Investitori di Agent S? Poiché Agent S è relativamente nuovo nell'ecosistema crittografico, informazioni dettagliate riguardanti i suoi investitori e sostenitori finanziari non sono documentate esplicitamente. La mancanza di approfondimenti pubblicamente disponibili sulle fondazioni di investimento o sulle organizzazioni che supportano il progetto solleva interrogativi sulla sua struttura di finanziamento e sulla roadmap di sviluppo. Comprendere il supporto è cruciale per valutare la sostenibilità del progetto e il suo potenziale impatto sul mercato. Come Funziona Agent S? Al centro di Agent S si trova una tecnologia all'avanguardia che gli consente di funzionare efficacemente in contesti diversi. Il suo modello operativo è costruito attorno a diverse caratteristiche chiave: Interazione Uomo-Computer Simile a Quella Umana: Il framework offre una pianificazione AI avanzata, cercando di rendere le interazioni con i computer più intuitive. Mimando il comportamento umano nell'esecuzione dei compiti, promette di elevare le esperienze degli utenti. Memoria Narrativa: Utilizzata per sfruttare esperienze di alto livello, Agent S utilizza la memoria narrativa per tenere traccia delle storie dei compiti, migliorando così i suoi processi decisionali. Memoria Episodica: Questa caratteristica fornisce agli utenti una guida passo-passo, consentendo al framework di offrire supporto contestuale mentre i compiti si sviluppano. Supporto per OpenACI: Con la capacità di funzionare localmente, Agent S consente agli utenti di mantenere il controllo sulle proprie interazioni e flussi di lavoro, allineandosi con l'etica decentralizzata di Web3. Facile Integrazione con API Esterne: La sua versatilità e compatibilità con varie piattaforme AI garantiscono che Agent S possa adattarsi senza problemi agli ecosistemi tecnologici esistenti, rendendolo una scelta attraente per sviluppatori e organizzazioni. Queste funzionalità contribuiscono collettivamente alla posizione unica di Agent S all'interno dello spazio crittografico, poiché automatizza compiti complessi e multi-fase con un intervento umano minimo. Man mano che il progetto evolve, le sue potenziali applicazioni in Web3 potrebbero ridefinire il modo in cui si svolgono le interazioni digitali. Cronologia di Agent S Lo sviluppo e le tappe di Agent S possono essere riassunti in una cronologia che evidenzia i suoi eventi significativi: 27 Settembre 2024: Il concetto di Agent S è stato lanciato in un documento di ricerca completo intitolato “Un Framework Agentico Aperto che Usa i Computer Come un Umano”, mostrando le basi per il progetto. 10 Ottobre 2024: Il documento di ricerca è stato reso pubblicamente disponibile su arXiv, offrendo un'esplorazione approfondita del framework e della sua valutazione delle prestazioni basata sul benchmark OSWorld. 12 Ottobre 2024: È stata rilasciata una presentazione video, fornendo un'idea visiva delle capacità e delle caratteristiche di Agent S, coinvolgendo ulteriormente potenziali utenti e investitori. Questi indicatori nella cronologia non solo illustrano i progressi di Agent S, ma indicano anche il suo impegno per la trasparenza e il coinvolgimento della comunità. Punti Chiave su Agent S Man mano che il framework Agent S continua a evolversi, diversi attributi chiave si distinguono, sottolineando la sua natura innovativa e il potenziale: Framework Innovativo: Progettato per fornire un uso intuitivo dei computer simile all'interazione umana, Agent S porta un approccio nuovo all'automazione dei compiti. Interazione Autonoma: La capacità di interagire autonomamente con i computer attraverso GUI segna un passo avanti verso soluzioni informatiche più intelligenti ed efficienti. Automazione di Compiti Complessi: Con la sua metodologia robusta, può automatizzare compiti complessi e multi-fase, rendendo i processi più veloci e meno soggetti a errori. Miglioramento Continuo: I meccanismi di apprendimento consentono ad Agent S di migliorare dalle esperienze passate, migliorando continuamente le sue prestazioni e la sua efficacia. Versatilità: La sua adattabilità attraverso diversi ambienti operativi come OSWorld e WindowsAgentArena garantisce che possa servire un'ampia gamma di applicazioni. Man mano che Agent S si posiziona nel panorama di Web3 e delle criptovalute, il suo potenziale per migliorare le capacità di interazione e automatizzare i processi segna un significativo avanzamento nelle tecnologie AI. Attraverso il suo framework innovativo, Agent S esemplifica il futuro delle interazioni digitali, promettendo un'esperienza più fluida ed efficiente per gli utenti in vari settori. Conclusione Agent S rappresenta un audace passo avanti nell'unione tra AI e Web3, con la capacità di ridefinire il modo in cui interagiamo con la tecnologia. Sebbene sia ancora nelle sue fasi iniziali, le possibilità per la sua applicazione sono vaste e coinvolgenti. Attraverso il suo framework completo che affronta sfide critiche, Agent S mira a portare le interazioni autonome al centro dell'esperienza digitale. Man mano che ci addentriamo nei regni delle criptovalute e della decentralizzazione, progetti come Agent S giocheranno senza dubbio un ruolo cruciale nel plasmare il futuro della tecnologia e della collaborazione uomo-computer.
641 Totale visualizzazioniPubblicato il 2025.01.14Aggiornato il 2025.01.14
Come comprare S
Benvenuto in HTX.com! Abbiamo reso l'acquisto di Sonic (S) semplice e conveniente. Segui la nostra guida passo passo per intraprendere il tuo viaggio nel mondo delle criptovalute.Step 1: Crea il tuo Account HTXUsa la tua email o numero di telefono per registrarti il tuo account gratuito su HTX. Vivi un'esperienza facile e sblocca tutte le funzionalità,Crea il mio accountStep 2: Vai in Acquista crypto e seleziona il tuo metodo di pagamentoCarta di credito/debito: utilizza la tua Visa o Mastercard per acquistare immediatamente SonicS.Bilancio: Usa i fondi dal bilancio del tuo account HTX per fare trading senza problemi.Terze parti: abbiamo aggiunto metodi di pagamento molto utilizzati come Google Pay e Apple Pay per maggiore comodità.P2P: Fai trading direttamente con altri utenti HTX.Over-the-Counter (OTC): Offriamo servizi su misura e tassi di cambio competitivi per i trader.Step 3: Conserva Sonic (S)Dopo aver acquistato Sonic (S), conserva nel tuo account HTX. In alternativa, puoi inviare tramite trasferimento blockchain o scambiare per altre criptovalute.Step 4: Scambia Sonic (S)Scambia facilmente Sonic (S) nel mercato spot di HTX. Accedi al tuo account, seleziona la tua coppia di trading, esegui le tue operazioni e monitora in tempo reale. Offriamo un'esperienza user-friendly sia per chi ha appena iniziato che per i trader più esperti.
1.3k Totale visualizzazioniPubblicato il 2025.01.15Aggiornato il 2026.06.02

