The field of text-to-image generation has long been a fiercely competitive red ocean, seemingly with no room left to innovate.
What do you need to train a powerful text-to-image model today?
Following the current mainstream approach, you would need: a pre-trained VAE encoder-decoder, concatenated text encoders, meticulously designed conditional injection mechanisms, massive datasets, RL or DPO alignment phases...
Overall, there seems to be a consensus: text-to-image generation must be this complex.
He Kaiming's team, however, takes a contrarian approach, offering a new perspective in the field of text-to-image models. They have released MiniT2I — a minimalist, pixel-space text-to-image model that deliberately pursues simplicity.
No VAE encoder-decoder, no AdaLN conditional injection, no auxiliary loss functions, no private data, no RL/DPO alignment, just pure flow matching trained directly on pixels. The 258M-parameter B/16 version achieves 0.87 on GenEval and 84.2 on DPG-Bench, surpassing pixel-space models several times its size.

The core proposition of MiniT2I is: If text conditioning is treated as 'context tokens with semantic information' and injected into the model, text-to-image generation and class-conditional ImageNet generation are not fundamentally that different — the architecture can be similar, computational requirements comparable, and even the scale of data can be aligned.

- Paper Title: A Minimalist Baseline for Text-to-Image Generation
- Technical Blog: https://peppaking8.github.io/#/post/minit2i
- Open Source Repo: https://github.com/PeppaKing8/minit2i-jax
Technical Approach: Subtraction at Every Step
Direct Pixel-Space Output, No VAE
MiniT2I's first design choice is radical: discard the VAE, perform denoising directly on RGB pixels.
Latent Diffusion Models are the current mainstream paradigm, first compressing images into a low-dimensional latent space using an autoencoder before diffusion. This makes high-resolution generation feasible, but at the cost of introducing reconstruction error, an extra training phase, and misalignment between the encoder and denoiser objectives.
MiniT2I's choice of pixel space is pragmatic: For 512×512 resolution, using 16×16 patches to divide the image into 1024 tokens keeps the sequence length well within the Transformer's comfort zone. Removing the VAE reduces single-step forward computation from ~1379 GFLOPs to ~570 GFLOPs (B/16 setting), and eliminates the ceiling on reconstruction accuracy — the output quality is only limited by the denoiser's capability.
Experiments confirm this: Under the same parameter budget, pixel models achieve FID on par with latent space models (18.7 vs 19.0), but with a 5x lower per-step cost.

MM-JiT Architecture: Returning to a Simple Transformer
SD3's MM-DiT uses AdaLN (Adaptive Layer Normalization) within each block to inject timestep and pooled text embeddings into the network — each sub-block needs to compute scale, shift, and gate parameters generated by an extra MLP from the conditioning vectors. This is an elaborate modulation mechanism, but MiniT2I finds it non-essential.
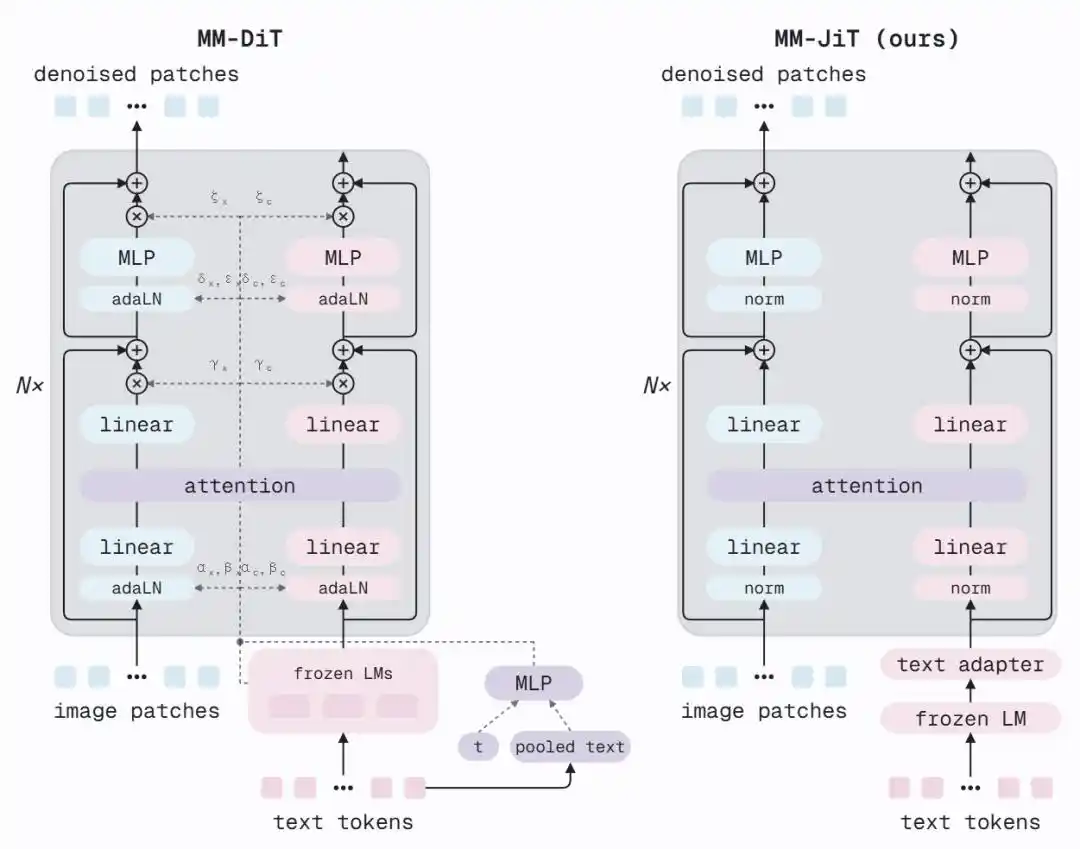
The proposed MM-JiT architecture does two things:
1. Add Two Text Adapter Layers: Insert two lightweight Transformer blocks before joint attention, allowing the frozen T5 features to first 'adapt' to the denoiser's needs.
2. Remove the AdaLN Branch: No longer inject timestep and global text information through an additional path. The model can still perceive noise levels — because the noise-corrupted image itself carries timestep information.
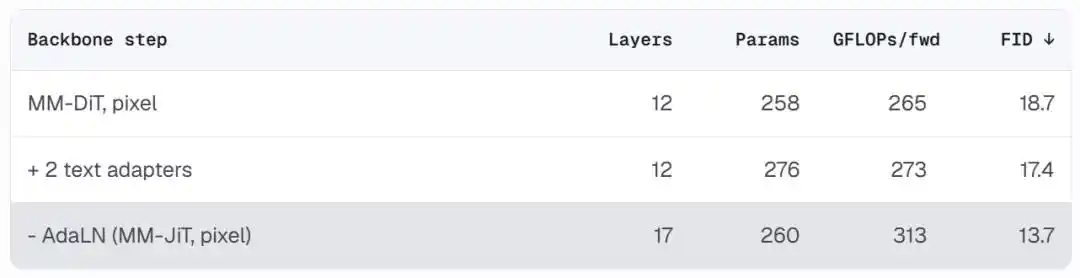
The result is a clean architecture nearly identical to a standard pre-normalization Transformer. Removing AdaLN reduces parameters, allowing for more layers within the same compute budget (12 layers → 17 layers). FID drops from 18.7 to 13.7, and the architecture itself is easier to understand and modify.
Training Data: Fully Public, Two-Phase
MiniT2I's training data also pursues minimalism:
- Pre-training: LLaVA-recaptioned CC12M (publicly available VLM re-captioned dataset), 250K steps
- Fine-tuning: ~120K high-quality image-text pairs (BLIP3o-60K + LAION DALL・E 3 Discord set + ShareGPT-4o-Image), 40K steps
This 'pre-train then fine-tune' two-stage pattern directly mirrors LLM training paradigms: pre-training buys coverage, fine-tuning teaches the model what a good answer is. Ablations show both are indispensable — pre-training alone yields acceptable image quality but poor prompt following; fine-tuning alone makes the model's world too narrow, causing generative diversity to collapse.
Results: Small Model, Big Performance
In comparisons among pixel-space text-to-image models, MiniT2I offers exceptional value:
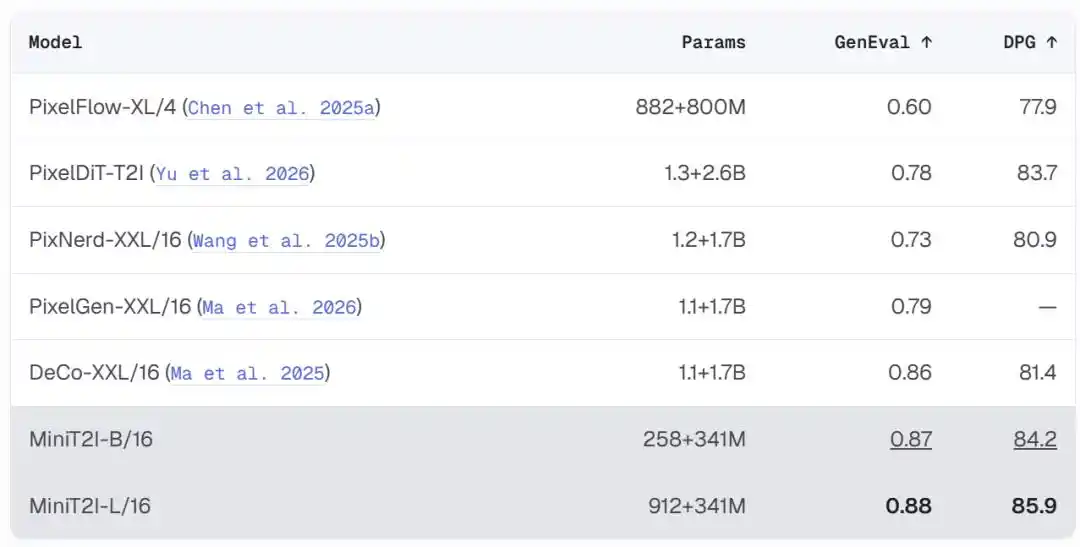
MiniT2I-B/16, with only ~600M total parameters (including text encoder), surpasses models 3-4 times its size on GenEval and DPG-Bench. Moreover, training cost is extremely low: the B/32 ablation model required only about 3 days on 8 H100s, with total training FLOPs comparable to a standard 200-epoch ImageNet experiment.
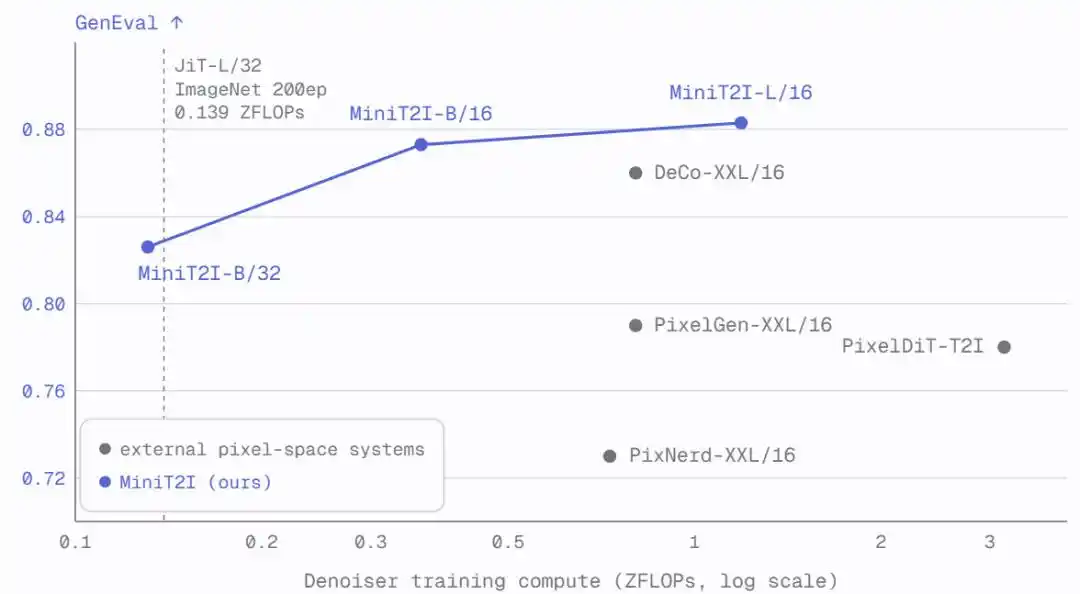
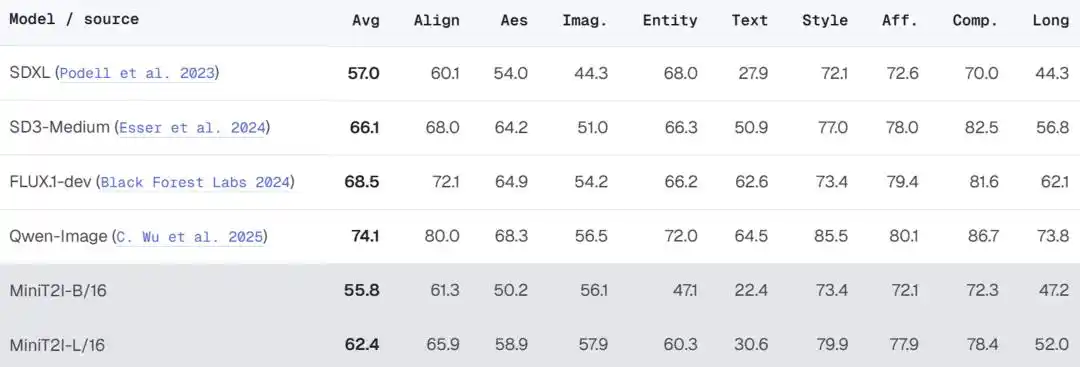
Scaling to L/16 (912M parameters) yields noticeable improvements in style diversity, spatial relationships, and text rendering, achieving quality on imaginative scenes comparable to or even better than SD3-Medium (~2B parameters).
In the more comprehensive PRISM-Bench evaluation, MiniT2I-L/16 performs well in style, composition, and imagination dimensions (79.9, 78.4, 57.9), approaching SD3-Medium levels. However, gaps remain in text rendering (30.6 vs SD3's 50.9) and named entities (60.3 vs 66.3) — the team acknowledges these are inherent limitations of the public data recipe, requiring targeted data to bridge.
Limitations and Outlook
MiniT2I is a proof of concept for a technical path, not a final product. The team honestly points out several unresolved issues:
- Patch artifacts in pixel space: Measurable discontinuities exist at patch boundaries (gradients 17-22% higher at boundaries than elsewhere), a problem latent-space models do not have.
- Side effects of CFG in pixel space: High guidance scales (~6) push local tokens away from the data manifold, directly exposing visual artifacts without a decoder's 'smoothing' effect.
- Resolution ceiling: Works well at 512×512 currently; pushing to 4K+ requires longer sequences or more efficient attention mechanisms.
- Data bottleneck: Text rendering and named entities remain weaker than industrial systems, requiring specialized data augmentation.
MiniT2I demonstrates that state-of-the-art text-to-image generation is no longer a game only for top industrial labs.
When a 258M-parameter model, trained on purely public data with academic-level compute for just 3 days, can defeat opponents orders of magnitude larger, perhaps text-to-image is undergoing a paradigm shift from 'brute force' to 'distillation'.
"T2I is no longer an insurmountable wall. Welcome to use and improve it, to build a simpler baseline."
This article is from the WeChat public account "机器之心" (Almost Human)







