Editor's Note: Anthropic releases Claude Opus 4.8, achieving first place in five out of six core benchmarks while keeping the price unchanged; Claude Code incorporates dynamic workflows, and the next-generation Mythos-level model has also entered market expectations.
Compared to simple performance improvements, what's more noteworthy about this release is that Anthropic is starting to shape "trustworthiness" into a core selling point for cutting-edge models.
In code honesty tests, Opus 4.8 significantly reduced the rate of failing to report its own errors; in Claude Code, it can orchestrate multiple sub-agents and introduce adversarial self-checking before delivering results. These changes collectively point to a practical issue: when AI moves from chat windows into real workflows, what users often worry most about is not the model's inability to complete tasks, but rather its tendency to provide seemingly complete, fluent, and self-consistent answers even when it's wrong.
Therefore, the significance of Opus 4.8 extends beyond a model upgrade; it also sends a clear industry signal: the competition among frontier models is shifting from a pure pursuit of benchmarks to a race for reliability, verifiability, and the ability to expose errors. For enterprise and professional users, the core threshold for AI in the next phase will increasingly depend on whether a model is trustworthy enough to be delegated to.
This is also a prerequisite for Agents to become truly usable. Models need to handle more tasks, but also need to make people feel confident in entrusting them with more important and complex tasks.
The following is the original text:
Anthropic today released Claude Opus 4.8. Among the six benchmark tests listed on the release card, it achieved first place in five of them.
The key change I'm most focused on is: in Anthropic's code summary honesty test, Opus 4.7 failed to flag its own errors 19.7% of the time; for Opus 4.8, this ratio dropped to 3.7%. For the same task, its ability to recognize errors in its own work improved roughly fivefold. Anthropic summarized this as "4x" in the announcement. However you calculate it, this is the key factor determining whether you can hand over real work to this model and walk away with confidence, and it's more important than any single benchmark score on the release card.

What Was Actually Released
First, the simplified version, then the specific numbers:
Reliability has truly improved. Apart from the code honesty data mentioned above, Opus 4.8 is also the first Claude model to achieve "literally zero" on two diligence tests: it reduced the frequency of "misreporting defective results" from 0.25 to 0.00, and dropped the incidence of "lazy investigations" from 25% to 0%. Overconfident erroneous responses decreased by about 11x. The tendency to favor its own work, a measurable bias in 4.7, has disappeared.
Dynamic workflows were added to Claude Code, currently in research preview. Claude now writes its own orchestration scripts, scheduling dozens to hundreds of sub-agents in parallel within a single session, and runs independent adversarial agents that attempt to refute the results before presenting them to you. This is the "agent teams" concept proposed in Opus 4.6, now automated.
It leads on its own release card, but not completely. It won five out of six. GPT-5.5 still leads in terminal operation tasks. Furthermore, the system card reveals some honesty regressions that Anthropic didn't put on the presentation slides, which will be discussed below.
No price changes. Still $5 per million input tokens and $25 per million output tokens, same as 4.7. However, the fast mode is now three times cheaper than before, though it remains a premium tier at $10 / $50.
Mythos is coming. Anthropic explicitly stated that the limited-access, extremely capable Mythos-level model will arrive in the coming weeks. Opus 4.8 is the public gateway to it.
Official Release Card: Benchmark Landscape
Below is the official release card, presented in our color scheme.
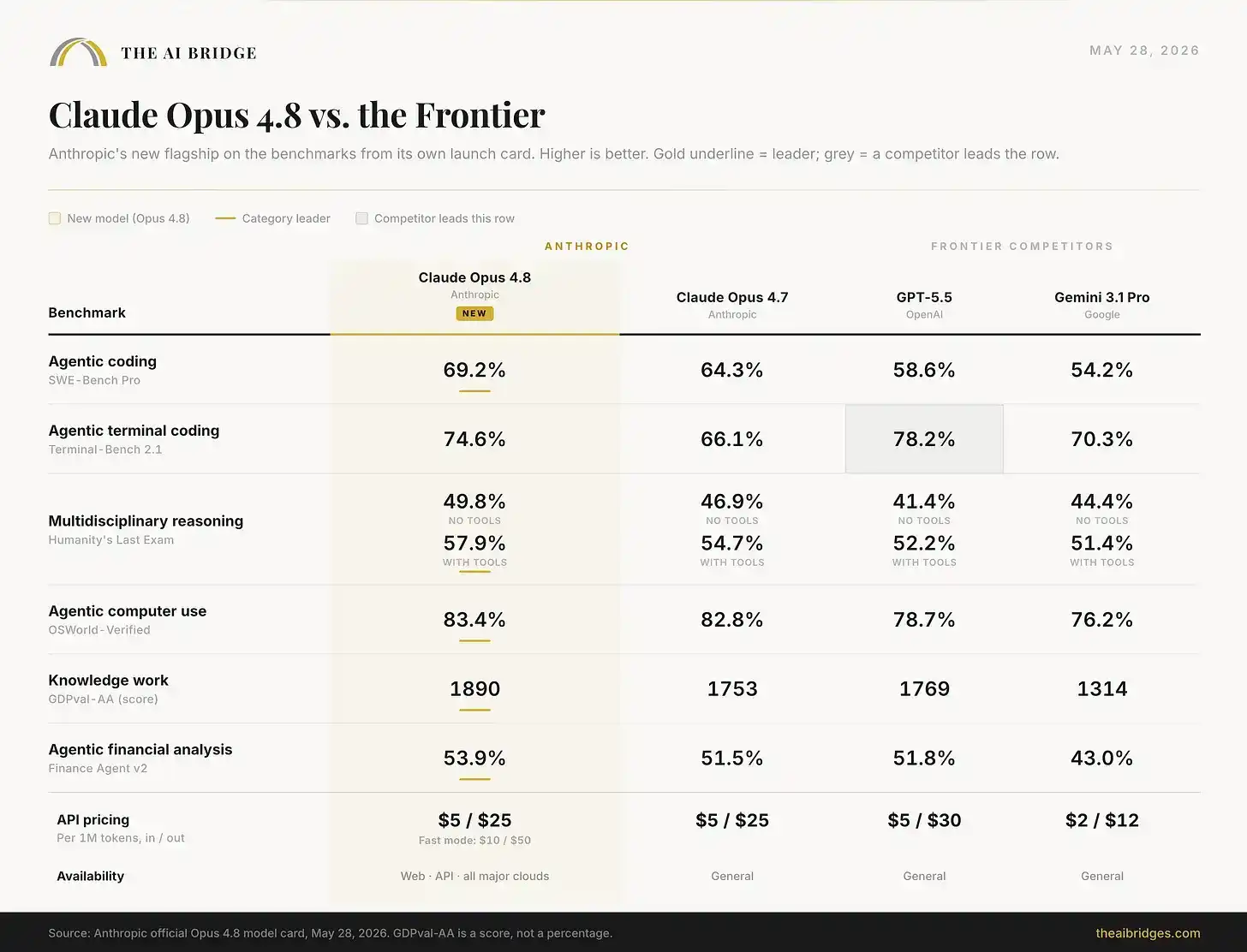
One category broke the sweep, and it's an important one. On Terminal-Bench 2.1, which tests a model's ability to complete long-horizon agent tasks via terminal, GPT-5.5 still leads with 78.2% versus Opus 4.8's 74.6%. Anthropic placed this loss on its own release card rather than hiding it. The "agent vs. craftsman" distinction we mentioned at GPT-5.5's launch hasn't been fully bridged: GPT-5.5 remains the stronger pure terminal operator, while Opus 4.8 is more like a stronger engineer in most tasks that real professional users care about, such as real-world coding, expert reasoning, computer use, and knowledge work.
Beyond the Release Card
The release card only shows six benchmarks. The 244-page system card reports on 40+ tests, and some of the most interesting results aren't on the slides. The following are noteworthy:
Mathematical ability improved by 27 percentage points. On the USAMO 2026, the United States of America Mathematical Olympiad held this March, Opus 4.8 scored 96.7%, while 4.7 scored 69.3%. Since this competition occurred after Opus 4.8's training cutoff, there's no data contamination issue. This is the largest intergenerational leap on the entire card.
Advantage widens in long-context scenarios. In a million-token graph reasoning test, Opus 4.8 scored 68.1, compared to 4.7's 40.3 and GPT-5.5's 45.4. The longer the context and the harder the task, the more its lead widens.
Multi-agent is where it truly excels. A single Opus 4.8 agent trails behind Gemini in web research tasks, scoring 84.3 vs. 85.9 respectively. However, if an orchestrator schedules a team of sub-agents, its score reaches 88.5%, becoming the highest reported result; a five-agent team can also achieve the single-agent best score in one-fifth of the time. This is the dynamic workflow feature manifesting in benchmarks.
Token efficiency sees a qualitative change. On the hardest coding tests, Opus 4.8 at its lowest effort setting achieves the performance that Opus 4.7 achieved at its highest effort setting. In other words, you get past peak performance at lower token cost.
It crossed a threshold no model had crossed before. On Harvey's Legal Agent Benchmark, a task is considered successful only if every single scoring criterion within the task is passed. Opus 4.8 is the first model to rank #1 under this "all-pass" criterion. It passed 89% of individual criteria, but the full task pass rate was only 9.6%, illustrating just how stringent real legal work requirements are.
There are honestly presented regressions. Three things are indeed worse than 4.7, and Anthropic acknowledges them in the system card. GPQA Diamond, an expert science test, dropped from 94.2 to 93.6. Refusal capabilities in computer use scenarios and resistance to prompt injection regressed, making 4.8 easier to manipulate in agent scenarios. Additionally, in a one-year simulated business test, it ended up with only one-third of the cash remaining compared to 4.7. These didn't appear on the release card, which makes pointing them out even more worthwhile.
Compared to Open-Weights Models, Where Does It Stand
The release card only compares Opus 4.8 with other closed-source frontier models. Expanding the view to include the cheap open-weights models many teams are testing today paints a picture that almost defines the 2026 AI industry: Opus 4.8 leads in capability, but the gap with free, self-hostable models is only a few percentage points, while the price gap is immense.
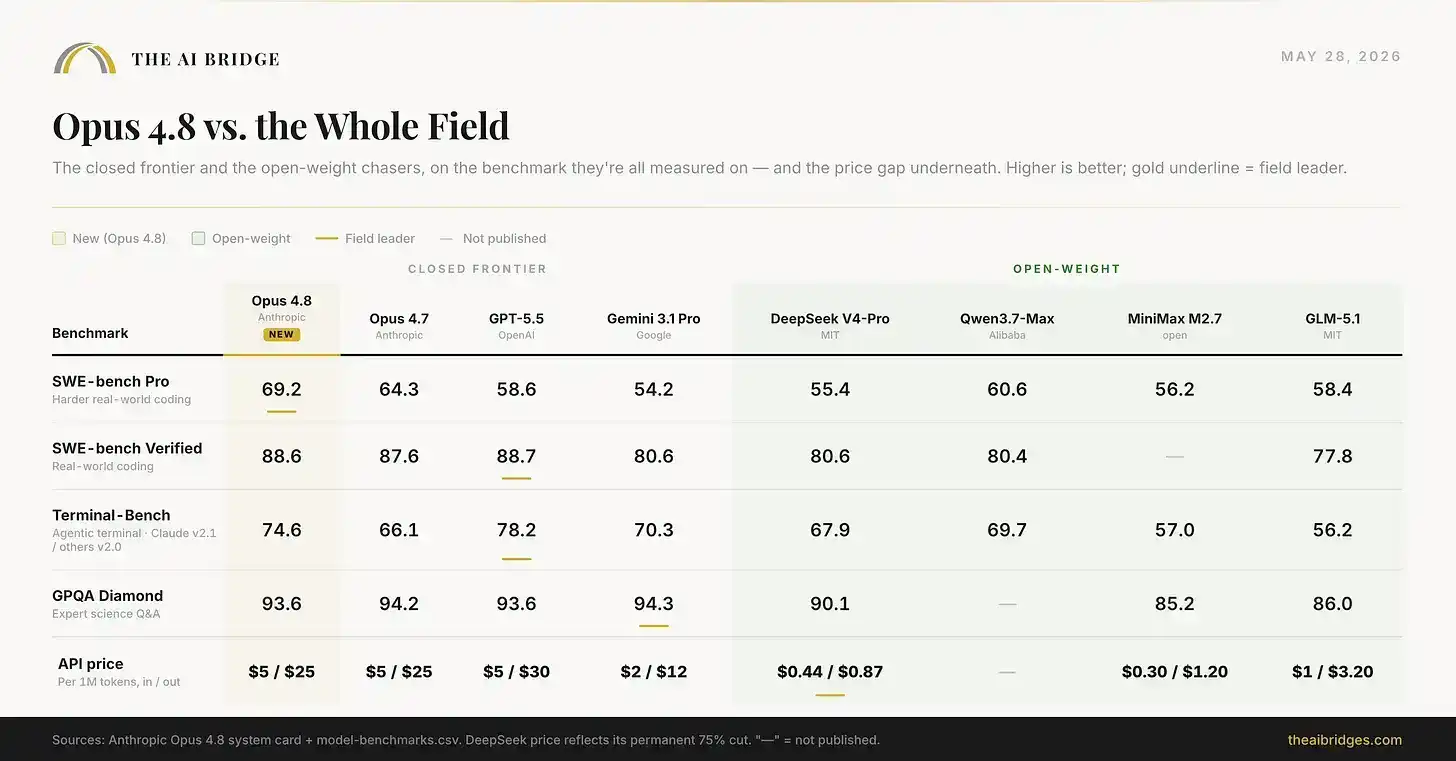
The chart above includes a full comparison of eight models. DeepSeek's price reflects its permanent 75% discount; Qwen Max's price hasn't been announced yet.
Opus 4.8 wins outright on coding benchmarks. But Qwen3.7-Max, an open model you can run yourself, scores 60.6, trailing by only about 9 points. DeepSeek V4-Pro scores 55.4, while its output price is roughly one-thirtieth of Opus's. For the highest-risk engineering tasks, the $25 per million output token difference might be worth paying. For a large volume of daily work, that gap is increasingly not worth it. And that's precisely the calculation every serious team is making right now.
What This Means for You
If you're using Opus 4.7, this is a free upgrade. Same price, better data, and noticeably more reliable judgment of its own outputs. Just switch to it.
The more interesting question is: What work are you now willing to delegate to it? Every reader has a line separating "tasks I can let AI do" and "tasks I must do myself because I can't yet trust the handover." The reliability improvements in 4.8 mean you can push that line forward a step. The model is better at flagging its own uncertainty, which lowers the cost of "silent error handoffs" and expands the range of tasks worth delegating to the model. This is the practical meaning of the honesty data; it's more important than any single score.
This also echoes what we wrote last week. Anthropic's own AI Fluency research found that when model outputs appear polished and complete, people become significantly less likely to notice missing context. The answer looks finished, so we stop checking. Opus 4.8 attacks this failure mode from the model side: it's better at telling you where a seemingly clean, complete answer might still have weaknesses. It can't replace your judgment, but it gives your judgment something to grasp onto.
If you use Claude Code, try the dynamic workflow this week with a genuinely large task—like a migration or a comprehensive check across many files—while keeping an eye on the token meter. This capability is real, and adversarial self-checking is key to making outputs more trustworthy. But the cost is also real. This is a tool for large tasks a single agent struggles with, not your new daily default.
What's Next: Mythos, Coming in Weeks
The most forward-looking statement in this release isn't actually about 4.8. Anthropic stated that the Mythos-level model will arrive in the coming weeks, positioning Opus 4.8 as a public step towards it.
You need to understand what this means. Mythos is a restricted frontier model Anthropic has been benchmarking internally, surpassing the released Opus 4.8 on almost all metrics: 93.9% on SWE-bench Verified; in cybersecurity tests, it can generate runnable exploits against most targets in current browsers, whereas Opus 4.8 has a success rate below 10%. It was previously available to only about 52 vetted institutions at a price five times that of standard Opus, treated as infrastructure rather than a regular product.
Therefore, when an even more powerful Mythos-level model lands in the coming weeks, it should be understood through a "two-market" framework: one is the commodified layer, Opus 4.8, broadly accessible, price unchanged, increasingly chased by free open models; the other is the controlled frontier layer, Mythos, expensive, access-restricted. These aren't separate products but different tiers on the same continuum of capability. The reliability work in 4.8 is exactly what you need to build before your real goal is "to run the model with less supervision." And that goal is now not quarters away, but weeks.
Background: How We Got Here
If you've lost the rhythm of the past four months, think of it this way: Opus 4.6 in February brought agent teams, Sonnet 4.6 brought price collapse, Opus 4.7 in April brought a reasoning leap, and Mythos has been the vaguely visible restricted ceiling on the side. Opus 4.8 connects two of these threads: it continues the orchestration narrative from 4.6 and is also the gateway to Mythos.
This release cadence itself is the key fact hidden beneath all surface changes. The flagship model has gone from 4.5, 4.6, 4.7 to 4.8 in months, and the model you standardize on for your team today might not be the one you're actually running by fall. This is also why, rather than investing in usage tricks for a specific model, it's better to invest in capabilities that can migrate across models, like clear delegation and rigorous verification.
Benchmark sweeps get screenshots shared. But the place where things are really changing is smaller and more important: this is the first Claude version whose core selling point isn't just "it's smarter," but "you can entrust more to it." Before agents become truly useful, the entire industry must move in this direction; and this part of the capability is also the hardest to fit into a chart.
Where is your line now? What work are you willing to hand to a model, and what still requires doing yourself? And what would need to happen for you to push that line forward another step?





