By | Zimu AI
With every release of a frontier model, the AI community fixates on a few familiar scorecards.
MMLU-Pro, MMMU, MMMU-Pro... While these names might be unfamiliar to the average user, for model companies and researchers, they have essentially become "standard subjects." GPT, Claude, Gemini, Llama, Qwen, DeepSeek, and others continually submit their answers on these benchmarks.
"Put it to the test" - a model's performance often hinges on these scores for proof.
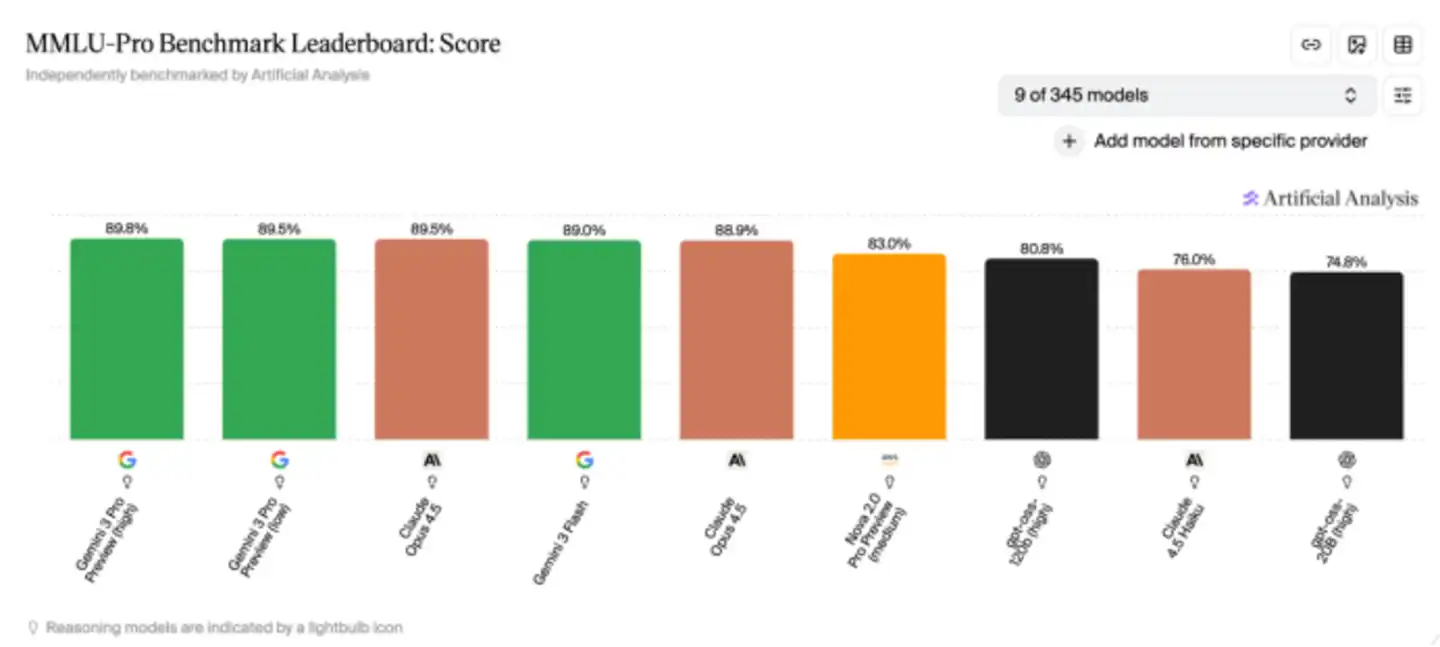
Many performance comparison charts in model launch presentations rely on them; some leaderboards on HuggingFace are also built upon these evaluation systems. It could even be said that when discussing model capabilities today, the AI industry is using a common language largely defined by these benchmarks.
Interestingly, while almost everyone focuses on the scores, few know who the question setters are. And behind MMLU-Pro, MMMU, and MMMU-Pro, one can find the same name—Wenhu Chen.
He is an Assistant Professor in the Computer Science Department at the University of Waterloo in Canada. On Google Scholar, his papers have been cited over 30,000 times.
He is also the founder of the "TIGER Lab" - the Text and Image GEnerative Research Lab. Because the name contains the Chinese character for "tiger" (虎, Hu), Chen Wenhu gave it a highly recognizable Chinese name—虎头帮 (Hutou Bang, Tiger Head Gang).
After the Old Exam Paper Fails
Chen Wenhu first caught wider attention because of MMLU-Pro.
MMLU was once one of the most commonly used benchmark evaluations for assessing the capabilities of large language models. It resembled a comprehensive test paper, covering multiple subjects, used to measure a model's performance in knowledge understanding and reasoning tasks.
In the early days, this paper was very useful. The scores could distinguish between models, and the industry could observe through it whether LLMs were genuinely improving.
But problems soon emerged.
As model capabilities continuously improved, MMLU gradually became "inadequate." The scores of frontier models got higher and higher, and the gaps between them grew smaller and smaller.
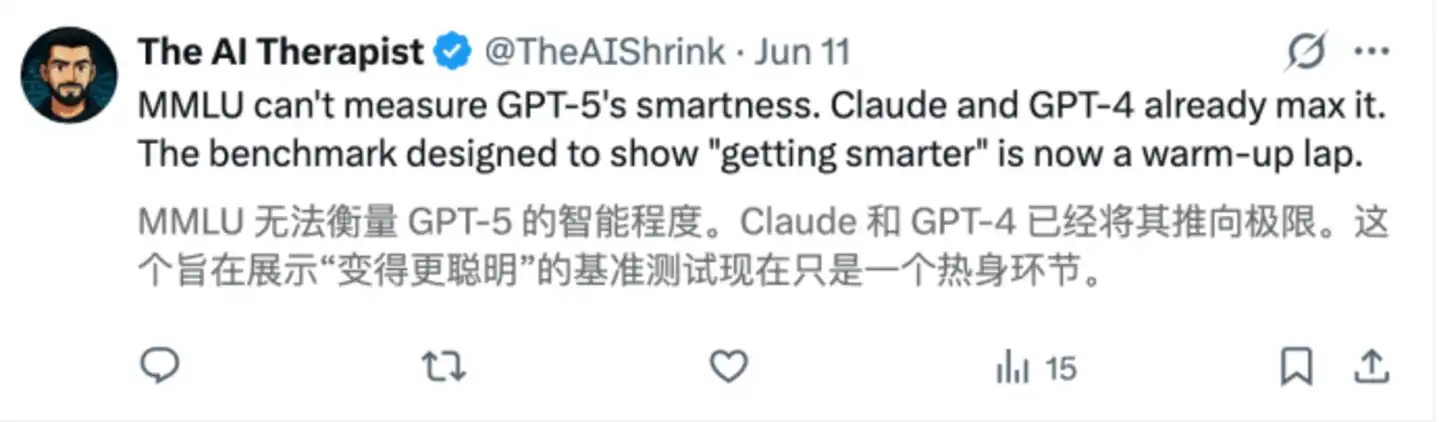
The issue became even more pronounced after OpenAI released o3. o3's accuracy on MMLU approached 100%, and other frontier models also subsequently submitted near-perfect scores.
This sounds like good news, but for evaluation purposes, it actually spells trouble.
If everyone scores close to full marks on an exam paper, it becomes difficult to continue judging who is stronger and where their strengths lie. It can still prove that models possess certain capabilities but is no longer suitable for measuring new progress.
The AI industry needed a harder, less "cheatable" exam paper.
In 2024, Chen Wenhu and his team introduced MMLU-Pro.
MMLU-Pro revamped this exam paper rather than simply expanding the question bank.
It contains 12,032 questions, covering 14 fields including mathematics, physics, chemistry, law, engineering, psychology, and health. Compared to the original MMLU, it expanded the multiple-choice options from 4 to 10, reducing the probability of models guessing correctly. It also incorporated more reasoning-oriented questions and filtered out relatively simple, ambiguous, or poorly discriminative questions from the original bank.
The effect was direct.
Paper results showed that model accuracy on MMLU-Pro decreased by 16% to 33% compared to the original MMLU. When testing the same model with 24 different prompt styles, score fluctuation also decreased from 4% to 5% on the original MMLU to about 2%.
In other words, this new paper is not only harder but also more stable.
It re-established gaps between models that all seemed excellent on the old exam paper. It also became easier to discern whether a model truly understands reasoning or is merely better at handling old-style questions.
Useful Benchmark Evaluations
The industry soon adopted MMLU-Pro.
MMLU-Pro subsequently entered the NeurIPS 2024 Datasets and Benchmarks Track and was integrated into EleutherAI's language model evaluation framework, lm-evaluation-harness. For the open-source model community, this meant it was no longer just a dataset in a paper but had entered the common evaluation toolchain.
Many model releases began reporting MMLU-Pro scores. Some leaderboards on HuggingFace also incorporated it into their evaluation systems.
If MMLU-Pro solved the problem of the "old exam paper failing" in language model evaluation, then MMMU propelled Chen Wenhu and TIGER Lab to the center of multimodal evaluation.
The problem with multimodal models is more complex.
Language models answer questions, primarily processing text. Multimodal models must simultaneously handle information in various forms: images, charts, diagrams, maps, tables, musical scores, chemical structures, etc. It's not just about understanding the question stem; it must truly comprehend the content within the images and integrate visual information, textual information, and subject knowledge for reasoning.
The MMMU benchmark contains 11,500 multimodal questions sourced from university exams, quizzes, and textbooks. It covers six major domains: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Technology & Engineering, further subdivided into 30 subjects and 183 subfields.
These questions don't simply ask the model "what's in the picture"; they require the model to combine image information with subject knowledge, much like a student solving a professional problem.
When MMMU was released, the research team tested 14 open-source multimodal models, as well as representative closed-source models like GPT-4V and Gemini Ultra. Even the strongest closed-source models at the time, GPT-4V and Gemini Ultra, only achieved accuracy rates of 56% and 59% respectively.
These numbers indicate that while multimodal models appear to be advancing rapidly, they still have substantial room for improvement on problems requiring genuine professional understanding and reasoning.
Later, Chen Wenhu's team launched MMMU-Pro, further closing avenues for models to bypass visual information. It filtered out questions that text-only models could also answer, expanded answer choices, and introduced a vision-only setting, embedding the question within the image, requiring the model to perform both visual reading and text comprehension simultaneously.
Simply put, it prevents the model from "guessing the answer by only reading the text."
This kind of work might sound somewhat tedious, but it's crucial. Because multimodal models will enter scenarios like healthcare, education, scientific research, design, and engineering in the future, merely describing images is insufficient. They must be capable of judgment, reasoning, explanation, and identifying truly useful information within complex visual data.
The Person Behind the "Exam Papers"
Chen Wenhu's later work on MMLU-Pro and MMMU stemmed from his long-standing research focus.

His research interests have always been related to complex information understanding, knowledge question answering, and reasoning.
He earned his bachelor's degree from Huazhong University of Science and Technology, then pursued a master's at RWTH Aachen University in Germany, and obtained his Ph.D. in Computer Science from the University of California, Santa Barbara. During his Ph.D., he was already conducting research in areas like complex QA, table reasoning, and knowledge evidence localization.
These tasks share a common characteristic: the answer is often not found within a single piece of text.
It might be hidden within a table, require combining a passage of text and an image, or necessitate the model to first retrieve information, then integrate, calculate, and reason. The model cannot merely recite existing knowledge.
Projects Chen Wenhu has been involved in, such as HybridQA, TabFact, Program of Thoughts, and MAmmoTH, are all related to this line of work.
This also explains his sensitivity to loopholes in model evaluation.
A good benchmark evaluation is not simply about making questions increasingly difficult; it's about anticipating where models are most likely to "guess correctly" or "appear competent."
A model might memorize the question bank, guess answers based on options, or use text to circumvent visual information... A good evaluation must patch these vulnerabilities.
After completing his Ph.D., Chen Wenhu joined Google Research and later worked on Google DeepMind's Gemini multimodal model and evaluation from 2021 to 2025. This experience was also significant. Long-term exposure to frontier model development gave him a clearer understanding of how model capabilities grow and made it easier to spot potential biases and blind spots in evaluation.
In the fall of 2022, Chen Wenhu joined the School of Computer Science at the University of Waterloo as an Assistant Professor. That same year, he was selected as a Canada CIFAR AI Chair. Subsequently, he founded the "TIGER Lab (aka Hutou Bang)" and continued research around foundation models, multimodal capabilities, and benchmark evaluations.

Hutou Bang doesn't just work on benchmark evaluations; it also conducts model and systems research.
In the video domain, UniVideo attempts to place video understanding, generation, and editing within a single framework, enabling the model not only to generate footage but also to understand content, respond to instructions, and complete edits. Vamba targets long video understanding, addressing memory, computation, and training efficiency issues posed by hour-long videos. MoCha, developed in collaboration with Meta's Generative AI team, focuses on talking virtual character generation, producing high-quality human videos from audio and textual descriptions.
A question setter who never solves problems themselves cannot create good questions. Working on models themselves conversely makes them more suitable for evaluation.
Because truly good evaluation often stems from an understanding of model capability boundaries. Only by knowing how models are built and the problems they encounter in real-world tasks is it easier to design questions that can measure differences and expose issues.
Currently, Chen Wenhu has joined Meta's Superalignment Lab, where his work continues to focus on multimodal pre-training data and evaluation, serving Meta's foundational models.
The AI industry is not short of visible figures. Spotlights typically shine on entrepreneurs, star researchers, and leaders of major model companies. New product launches, funding news, open-source models, and team changes often attract the most external attention, making these names more likely to enter the public eye.
But the involvement of Chinese talent in today's AI field extends far beyond these most prominent positions.






