By Sun Yongjie
Entering 2026, the release window for DeepSeek V4 has been repeatedly postponed, unexpectedly igniting global discussions within the AI community about "de-CUDA-ization." According to reports from multiple media outlets, this open-source multimodal model, expected to have a parameter scale of trillions and support for million-token context, is being fully adapted for Huawei's Ascend chips, with core code rewritten through the CANN framework.
If this eventually becomes reality, it will mark the first time China's AI system has systematically explored the possibility of carrying core model capabilities on a non-CUDA platform in a real production environment. In other words, this is not just the release of a model but more like a "stress test" of the underlying technical route.
However, as DeepSeek founder Liang Wenfeng emphasized in internal communications, this is only "the first step of a long march." The future holds both risks and opportunities, and the balance—or even trade-off—between compatibility and self-reliance will determine whether China's AI can truly forge its own path of development.
DeepSeek V4 Delay: The Inevitable Cost of Transitioning the Foundational AI Computing Platform
As mentioned, the V4, originally planned for release during the Chinese New Year or in February–March of this year, has repeatedly missed its window. As of early April, relevant media confirmed a release "within weeks." The reason lies in the deep adaptation of the inference side to Huawei's Ascend chips. However, this path is far more complex than imagined. To understand this complexity, we must first return to the technical characteristics of DeepSeek V4 itself.
As is well known, entering 2026, large model parameter scales have crossed the "trillion" threshold and are moving toward tens of trillions. Against this backdrop, although V4 adopts a more aggressive MoE (Mixture of Experts) architecture, theoretically reducing single-inference computational load by "activating experts on demand," the trade-off is that it places more extreme demands on system capabilities, including memory bandwidth, inter-chip connectivity, and KV Cache management.
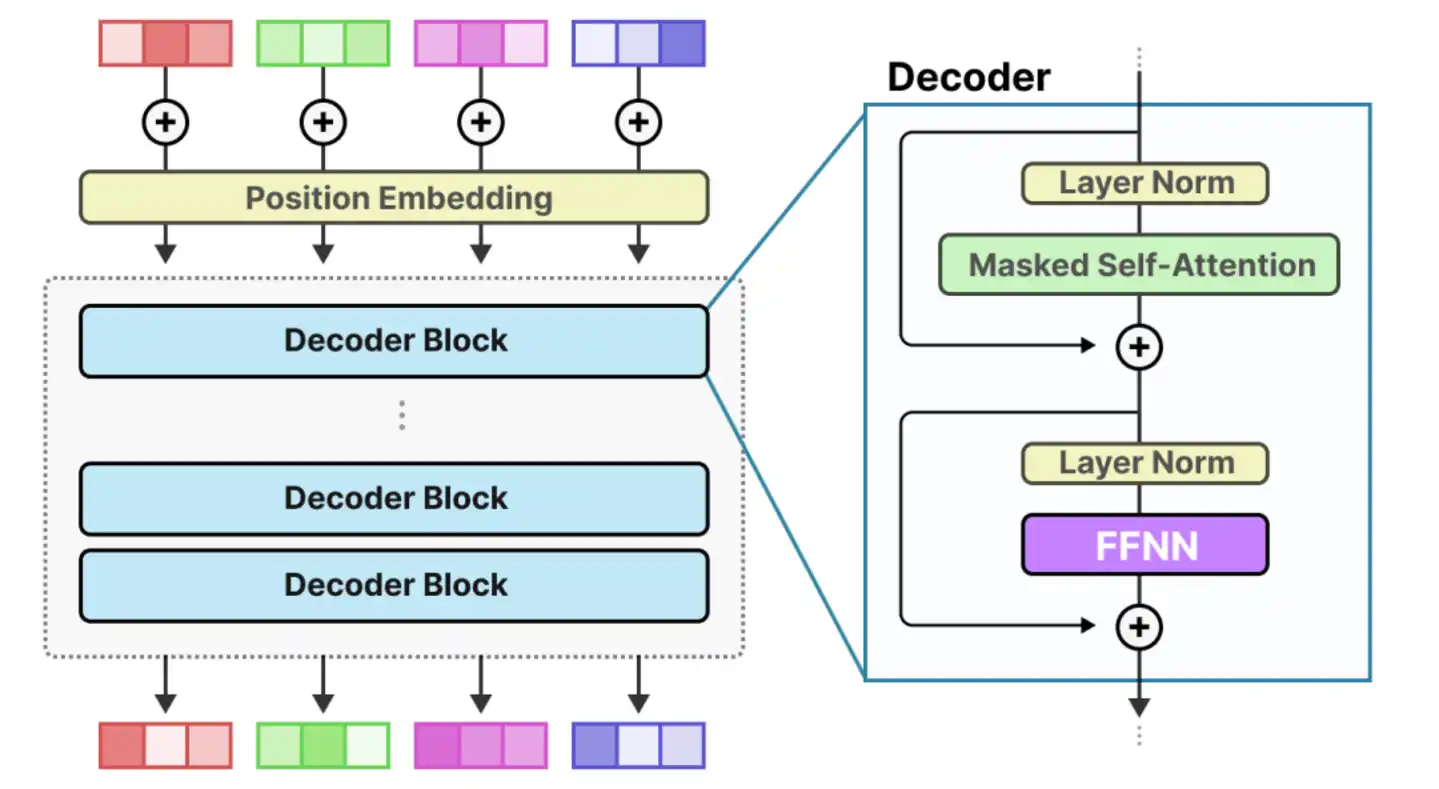
In other words, the computational pressure shifts from "pure computation" to "system scheduling and communication." Within the NVIDIA ecosystem, this set of problems has relatively mature solutions.
For example, based on H100 or B200, high-bandwidth interconnects built via NVLink and NVSwitch can achieve TB/s-level bandwidth between GPUs within a single node, forming a near "fully connected" computational network where data flows between chips like on a highway, with latency and synchronization costs greatly compressed. However, when DeepSeek attempts to migrate this sophisticated system to the Huawei Ascend platform, it faces a completely different hardware topology.
It is undeniable that Ascend chips have made significant progress in recent years, but there remains a physical-layer gap with NVIDIA in terms of "full connectivity capability" in ultra-large-scale clusters. For instance, constrained by process technology and SerDes IP capabilities, Ascend relies more on optical modules for cross-node expansion. This "trading space for bandwidth" solution, while feasible, introduces longer physical links, thereby bringing complexities such as signal latency, synchronization overhead, and power and thermal management.
At the same time, the gap at the software level is equally non-negligible. The maturity of Huawei's CANN framework in areas such as operator coverage, automatic parallelism, kernel fusion, and distributed communication scheduling still lags behind the CUDA ecosystem overall. This means that DeepSeek's engineering team needs to perform targeted optimizations on a large number of underlying details, even manually rewriting key operators.
More棘手的是, this lag is often not linear but systemic. Specifically, the performance drop of one operator can affect the entire computational chain; a reduction in communication efficiency can cause significant fluctuations in overall throughput. The end result may be that the model can still run, but it is still a long way from being stable, efficient, and scalable.
From this perspective, the delay of DeepSeek V4 is not simply a product timing issue but an inevitable cost of the deep磨合 between China's top algorithm teams and the domestic chip system. Although the process is difficult, it is highly significant.
More importantly, this process sends a clear signal that AI competition is shifting from a "model capability contest" to a "systems engineering capability contest." In this phase, whoever can "run the model, run it stably, and run it cheaply" faster will truly approach an industrial-level advantage.
CUDA Monopoly Hard to Break, CANN's Reluctant Compromise
If the aforementioned adaptation difficulties of DeepSeek V4 on the inference side reveal the practical bottlenecks at the engineering level, then following this question further, a more fundamental question emerges: Why has migrating a model from one computing platform to another become so difficult?
Looking back at the Wintel alliance of the PC era, although Microsoft and Intel jointly held a monopoly, there was an interest game between the two companies, which预留ed space for the rise of Linux, AMD, and even Apple's system later. However, NVIDIA has established a "monolithic vertical monopoly" in the AI field, essentially the combined entity of Microsoft and Intel.
Specifically, at the hardware level, NVIDIA defined the physical structure of the SM (Streaming Multiprocessor) and the computational logic of the Tensor Core; at the software level, CUDA provides closed-source libraries like cuBLAS and cuDNN that are perfectly 1:1 matched with it. The叠加 of these two aspects has led to an extremely daunting reality: over 6 million developers worldwide optimize algorithms around cuBLAS, cuDNN, NVLink/NVSwitch; frameworks (PyTorch, TensorFlow) prioritize CUDA implementations; and even "anti-NVIDIA" heterogeneous clusters like AWS Trainium + Cerebras WSE still require NVIDIA NIXL software and AWS EFA for KV cache migration.
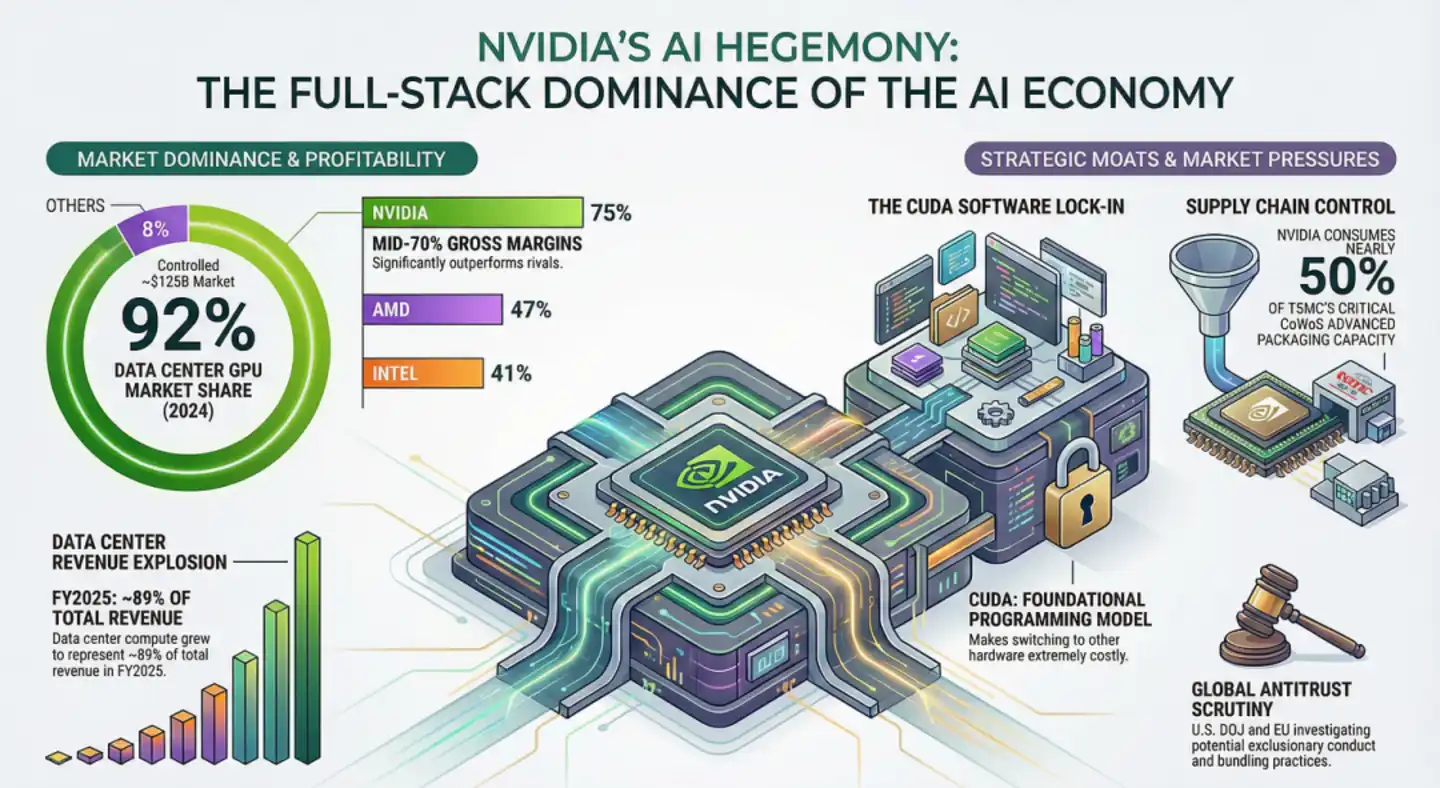
This shows that it is no longer a single-point technical detail but an ecosystem lock-in. Before model portability fails, developers' habit of "thinking in the language of NVIDIA hardware features" has become惯性. It is precisely this ecosystem惯性 that makes NVIDIA like a huge black hole, absorbing over 90% of global innovation红利.
Against this background, as its strongest competitor, Huawei's CANN initially attempted to follow a relatively independent path. However, with the advent of the large model era, this path gradually revealed problems, such as developers' reluctance to migrate, enterprises' fear of taking risks, and slow ecosystem growth. Coupled with the pressure of time (e.g., the rapid iteration of large models), the path of complete self-reliance began to become unrealistic.
Based on this, CANN gradually introduced abstraction layer designs similar to CUDA. For example, in CANN Next, it attempted to对标 cuBLAS and cuDNN interfaces, achieving high比例 compatibility, reducing model migration costs from "weeks or even months" to "hours." At the architectural level, the recently released 950PR heterogeneous architecture (prefill/decode decoupling) also deliberately imitates NVIDIA's decoupled service approach, rather than Google TPU's彻底 heterogeneous route.
We must admit that this "compatibility first" strategy is successful in the short term. It lowers the threshold, allowing Ascend to quickly gain an application foundation in the domestic market, and enables companies like DeepSeek, Tencent, and ByteDance to尝试 domestic computing power with a relatively low barrier to entry. For example, CANN Next achieves over 95% CUDA compatibility through the SIMT programming model, already helping many enterprises大幅 shorten migration time to the hour level, accelerating practical deployment.
But the随之而来的 challenge is that once it involves cutting-edge innovation, the compatibility layer becomes a "ceiling."
For instance, when developers深入 use the Ascend platform, they find that although common paths have been smoothed, once they involve some niche, innovative underlying operators, CANN's support drops, and performance jitters剧烈. The difficulties DeepSeek V4 encountered during adaptation, such as when trying to introduce hybrid architectures like SSM (State Space Model) or Mamba (non-Transformer structures), and finding that CANN's underlying optimization is still mainly倾斜 towards matrix multiplication (GEMM), are largely because they hit the "boundary" of CANN's compatibility layer when attempting algorithm optimizations that go beyond the conventional.
The deeper issue is that once compatibility is chosen, it means默认 CUDA remains the隐形 standard. You can replace the hardware, but in terms of software semantics and development paradigms, you are still following the rules defined by the other party. This is both a shortcut and a limitation.
Compatibility Hides Risks and Challenges, Future Opportunities Still Require True Self-Reliance
As前述, under the reality that the CUDA ecosystem has become a de facto standard, Huawei's choice of a "compatibility-like" path is almost inevitable. However, it also pushes the entire Chinese AI industry to a critical choice node: continue to be compatible with CUDA, or gradually move towards a truly independent ecosystem?
In the short term, the answer is almost unquestionably that compatibility is necessary; it is a choice of efficiency and reality. But in the long term, this path hides risks that cannot be ignored.
As is well known, when a system (like CANN) is designed to be compatible with another system (like CUDA), it inevitably inherits the other's limitations.
The fact is, most global open-source algorithms are currently developed around the NVIDIA architecture. If we一味 pursue 1:1 compatibility to leverage these existing assets, we will fall into the "imitator trap" in hardware design. This manifests as follows: if NVIDIA's hardware architecture faces a paradigm shift at some future point, for example, shifting from Transformer to some new architecture that doesn't require large-scale matrix multiplication but relies more on asynchronous logic, then the domestic computing stack, which has been in a "shadow state," might face an instant technological断层. This dead end of "Bug-for-Bug compatibility"无疑 keeps our underlying innovation perpetually shrouded in the shadow of others.
And the deeper risk lies in the "time gap." According to statistics from Bernstein and Epoch AI, although Huawei's domestic share has surged,国产 chips account for only 5% of the global AI computing power total, which remains relatively limited. It is precisely this absolute scale gap that causes serious "R&D efficiency friction."
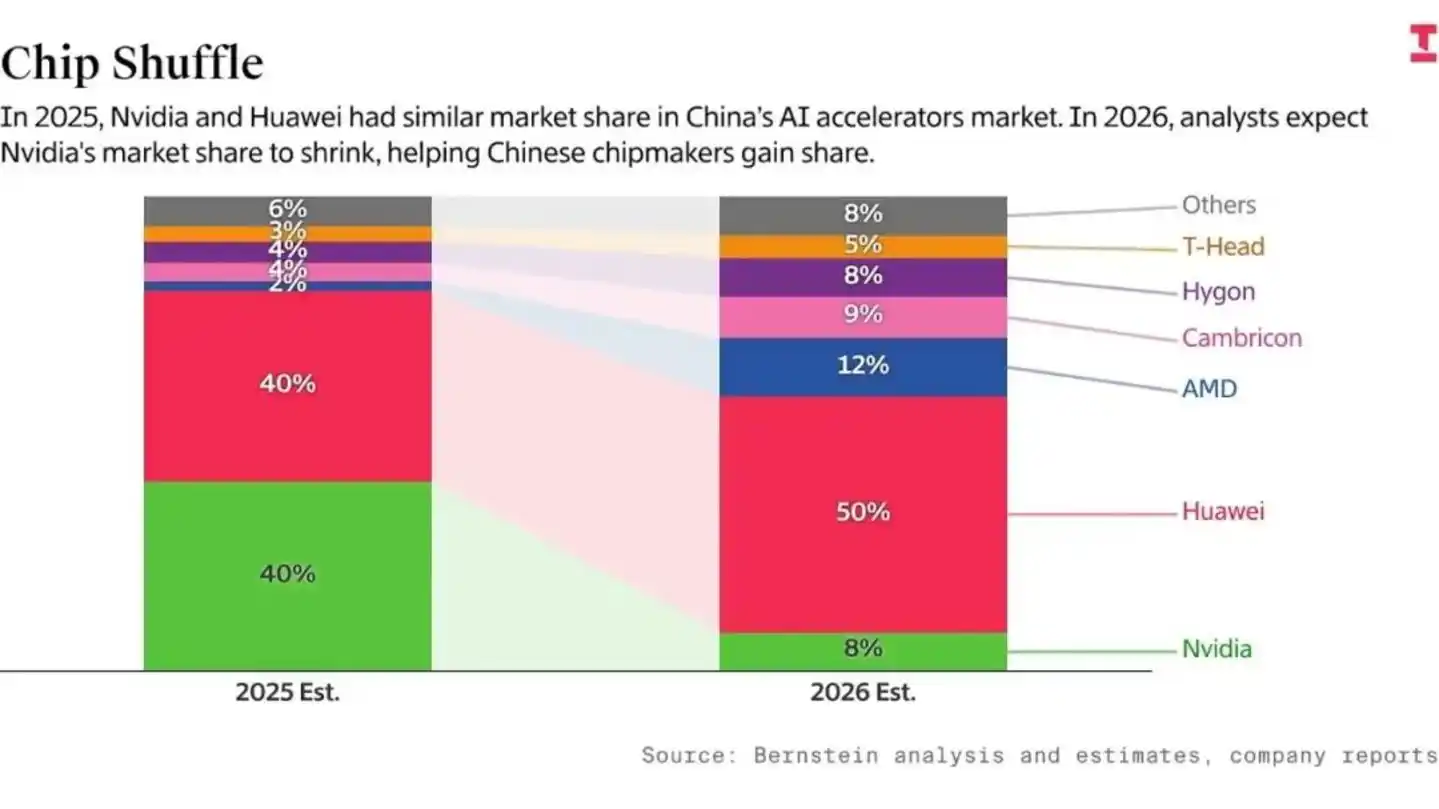
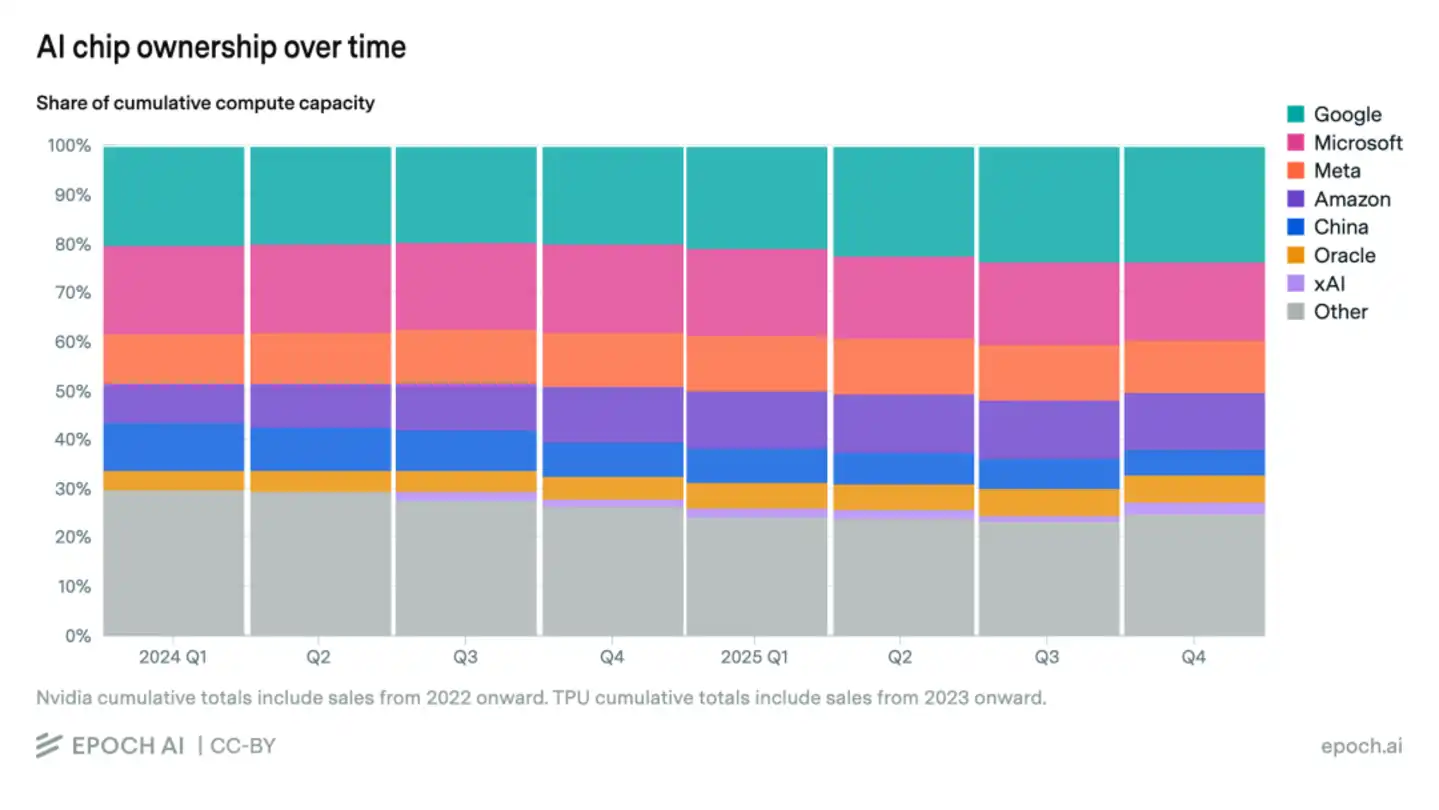
Specifically, US AI giants can leverage Blackwell's powerful communication bandwidth to run through 10T parameter Scaling Laws in 18 months, while China's top talent has to消耗 over 50% of its R&D capacity on issues like "how to solve signal attenuation in older chips" and "adapting to immature compilers."
It needs to be clarified that this kind of time misalignment is放大ed infinitely in the rapidly changing AI era. While our talent is still busy "filling pits," opponents may have already completed exponential compound growth in model capabilities, leading to a one-year lead in the opponent's model演变为 a gap of more than a year for us, compounded by exponential growth in model capability, data flywheel, and safety alignment.
Of course, challenges often contain opportunities. If DeepSeek V4 is successfully released, it will prove the feasibility of a "domestic full-stack," accelerate the maturation of the CANN ecosystem, attract more developers to follow suit, and coupled with the global sentiment of "the world has long suffered under NVIDIA," industry support for CANN may exceed expectations. If后续 Huawei Ascend and other chips achieve 80%–90% of H100's inference performance,叠加ed with the compatibility红利 of CANN Next, a critical mass for China's AI supply chain is expected to form within 1–2 years.
But it is necessary to清醒认识 that compatibility can only solve the problem of "survival"; true self-reliance determines "how far we can go." The next 3-5 years will be a critical window. If we can gradually establish independent programming models, operator systems, and system architectures while maintaining compatibility, China's AI ecosystem still has the opportunity to achieve a leap from following to defining the rules. Otherwise, Chinese AI may陷入 the轨道 of rough replication."
In conclusion: The delayed release of DeepSeek V4, seemingly an accidental "slip," actually reveals a deeper reality: AI competition has long ceased to be just about models; it is a comprehensive contest of underlying ecosystems and system capabilities. Compatibility with CUDA is固然 the shortest path to reality, but stopping there may also lock in the future ceiling.
Therefore, the real challenge lies not in whether we can replace one set of technologies, but in whether we can break free from dependence on existing paradigms and build our own rule system. The next 3-5 years will determine whether China's AI becomes an important pole in the global ecosystem or remains in a position of "high-level following" for the long term. Of course, while pursuing self-reliance, we must also be vigilant about the potential impact a closed ecosystem might have on its attractiveness to global developers, to ensure the ecosystem's openness and long-term international competitiveness.






