By | Xiang Xianzhi
In "The Three-Body Problem," Liu Cixin wrote an image that has been cited countless times—the dark forest. Every civilization is a hunter with a gun; whoever exposes themselves first dies first. The forest is not empty—it's that everyone knows turning on a light will attract bullets, so everyone keeps their lights off.
In the spring of 2026, top AI labs entered such a dark forest.
On April 16, Anthropic was the first to release Claude Opus 4.7. On the same day, they made an unusual move—publicly admitting that Opus 4.7's performance was not as good as an unreleased model called Mythos, citing safety concerns.
On April 23, OpenAI posted GPT-5.5 on its official website. On the same day, Anthropic published an incident review report titled "An update on recent Claude Code quality reports" on its official blog, admitting that Claude Code had indeed become dumber over the past month—one releasing a new card, the other admitting a mistake. But this "new king" was almost showing off: we admit Claude has temporarily become dumber—but don’t forget, we still have a Mythos card up our sleeve.
On April 24, the "mysterious Eastern force" DeepSeek V4 Preview was launched, with Liang Wenfeng's team officially announcing the model's deep integration with Huawei's Ascend 950PR for the first time; but everyone understood—the truly "full-blooded" V4 Pro Max would only be released after the mass production of Ascend 950 super nodes in the second half of the year.
Three companies, three moves. On the surface, they are各自的 product rhythms, but when pieced together, one thing becomes clear:
Each one holds at least one "gun"—a model stronger than the public version, a next-generation architecture not yet released to the public, or a super node of chips not yet widely deployed. But none dare to raise this gun first.
Because in this industry, the cost of "showing first" is far more than just leaking secrets. Showing first means handing your capability上限 to competitors as a reference;意味着率先承担安全审视、监管收紧、舆论压力的全部火力;意味着把自己变成下一轮所有竞对都要瞄准的那个移动靶子. There is no heroism in the forest—everyone who fires first becomes the next target.
So the most rational choice for hunters is to turn off the lights, hold their breath, and keep their weapons hidden behind their backs.
This is the optimal solution in game theory.
Anthropic's Fearlessness
On Claude's side, the past month has almost been the worst version release ever.
After早早 updating to Opus 4.7, Anthropic still dominated various charts, and they still had Mythos, which is only provided to enterprise customers—a seemingly unhurried attitude.
But the Opus 4.7 cycle was almost the worst user experience for Claude, with a flood of negative reviews.
In early March, Anthropic changed Claude Code's default reasoning depth from high to medium. The intention behind this decision was understandable: in high mode, the UI often appeared frozen, with responses so slow that paying users were frustrated. The problem was, they didn’t announce it at the time.
At the end of March, they launched an "efficiency optimization"—if a Claude Code session was idle for more than an hour, the system would clear old reasoning blocks. In design, this was to save computing power. In practice, after each round of conversation, Claude seemed to have amnesia, forgetting the context completely. The developer community was flooded with complaints during those weeks: "Claude no longer remembers what I asked it to do in the previous round."
Recently, a third thing happened—adding an instruction to compress verbosity in the system prompt. By Anthropic's own later admission, this instruction directly reduced Claude Code's coding quality by 3%.
These three things叠加在一起, led to an AMD senior director writing on GitHub: "Claude has regressed to the point it cannot be trusted to perform complex engineering." Axios' April 16 article, "Anthropic's AI downgrade stings power users," brought it into the mainstream spotlight.
Then Anthropic admitted that there were indeed some issues.
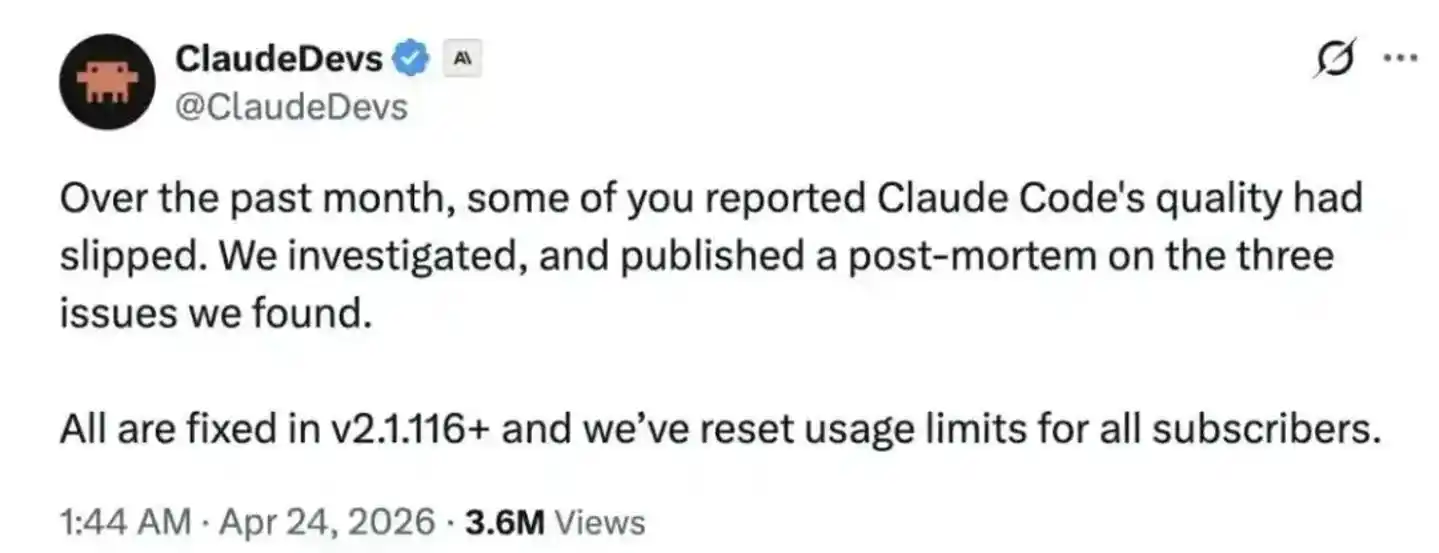
On April 7, they quietly rolled back the reasoning effort adjustment; on April 10, they fixed the cache bug; on April 20, they removed the system prompt compressing verbosity. But the real incident review report wasn’t released until April 23—coinciding with the day GPT-5.5 was publicly released.
This sense of slight contempt—"oh, there was a bug in our engineering strategy, it’s fixed now"—came just before and after OpenAI's heavyweight release. It’s hard to believe this was a coincidence.
What’s more intriguing is that when Opus 4.7 was released, Anthropic made an unusual move: publicly admitting that Opus 4.7's performance was不及 an unreleased model—Mythos. This was clearly a "strategic retreat"—Anthropic kept its strongest capabilities on the enterprise side and was in no hurry to release them to the public because the team wasn’t ready to release Mythos.
This explanation is believable. But from a business narrative perspective, the other half is equally true: Anthropic waited six weeks to publicly admit that Claude Code was regressing, and only brought up the issue on the day OpenAI was about to play a new card. If not for sufficient competitive pressure, if Opus 4.7 hadn’t proven "we still have a backup," this statement might never have come.
On Claude's side, squeezing toothpaste doesn’t mean deliberately crippling capabilities; it means: the pace of capability release and the timing of issue disclosure are both aligned with competitors' rhythms.
Releasing your most advanced capabilities will inevitably make you a target. Or, from Anthropic's perspective, the pressure from 4.6 on competitors hasn’t faded—so there’s no need to play the stronger card now.
OpenAI's Old Tricks
If Anthropic is "hiding a Mythos and not releasing it," then OpenAI's toothpaste-squeezing is more subtle—it leaves the power of capability release in the load curve of its own servers and a tiering mechanism called auto-router.
On April 23, the same day GPT-5.5 was released, Simon Willison (co-creator of the Django framework, well-known independent AI evaluator) wrote a cautious sentence in his blog: "It's not a dramatic departure from what we've had before."

He added a key piece of information: GPT-5.5 is the first completely retrained base model since GPT-4.5; that is, the past half-year's releases of 5.1, 5.2, 5.3, and 5.4 were all just incremental updates. In other words, OpenAI released the past four minor updates with restrained effort—because they didn’t know what competitors would release.
"Releasing with restrained effort" has a more understandable name: squeezing toothpaste.
But a more memorable scene occurred hours after GPT-5.5 went live. Codex users filed Issue #19241 on GitHub, complaining that Fast mode was initially very fast but became visibly slower as more users were let in, while billing was still at the Fast tier. The wording was familiar: "Please investigate whether GPT-5.5 Fast mode is downgraded under high load."
This was almost an exact replay of the scene on August 7, 2025, the day GPT-5 was first released—back then, Reddit r/ChatGPT pushed "GPT-5 is horrible" to 4600+ upvotes, and Sam Altman personally admitted in an AMA the next day that "the autoswitcher broke... GPT-5 seemed way dumber"—admitting that the router had downgraded users behind the scenes.
The same script was上演 again eight months later.
More ironically, the day before GPT-5.5's official release, OpenAI's Codex mistakenly pushed the internal staging environment to production, captured by several Pro users, fixed within minutes, but the content had already spread. What appeared in the selector at that time, besides GPT-5.5 itself, was a series called Glacier (tooltip reading "Intelligence that moves continents"), a life sciences model called Heisenberg, an unknown-purpose model called Arcanine, and multiple versions with codenames like oai-2.1.
That is, at the same time OpenAI released GPT-5.5 as the "next generation," internally there were at least 5 to 6 parallel product lines running, none of which had reached the public yet.
OpenAI itself admitted it. In its official 2026 roadmap, they used a term long discussed in academic circles—capability overhang—admitting that there is a huge gap between the true capabilities of current large models and the effects users can actually achieve.
Sound familiar? It’s almost the same wording Anthropic used for Mythos. Even if the Codex leak on April 22 was truly a mistake, OpenAI actively putting the term "capability overhang" into its roadmap sends a clear message—we have much more in hand, you deal with it.
You can only squeeze if you have far more than what you sell to users. The 24 hours of GPT-5.5 turned this premise into a live broadcast once again.
DeepSeek's Patient Wait
On DeepSeek's side, the way of "squeezing" has completely changed—it is not hiding capabilities but waiting for a more suitable delivery time.
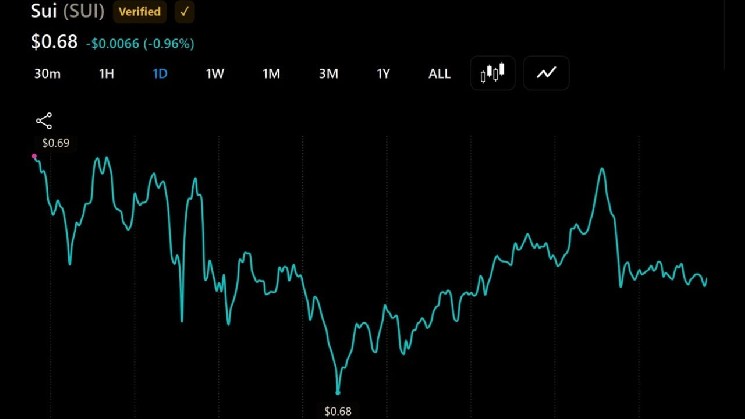
1.6T MoE, 1M context, Pro/Flash dual specifications, priced at 3.48 per 1M tokens—dozens of times cheaper than GPT-5.5, an order of magnitude difference from Opus 4.7. Overseas independent evaluators concluded with two sentences: performance is close to but slightly lower than GPT-5.4 / Gemini 3.1-Pro, price "shatters the economics of frontier labs."
But in DeepSeek's own coordinate system, V4 Preview is already significantly more expensive than V3's "bizarrely cheap" price. Everyone knows—this is not the full-blooded version.
The complete story of DeepSeek V4 does not end with its release, nor does it start with it.
It starts with the unreleased release of R2 in 2025. R2 was originally scheduled for release in May 2025 but was eventually postponed to autumn/winter. DeepSeek's entire infrastructure in China migrated to Huawei's CANN ecosystem. For any lab, this is not an engineering feat that can be completed in a quarter—compiler, operators, communication libraries, inference framework, MoE routing, all had to be rewritten.
And this time with V4, it is the first time DeepSeek officially wrote Ascend into the training hardware list. V4 is the first version of mixed training—Ascend's first entry.
But the next-generation chip Ascend 950DT, optimized for large-scale training, is scheduled for mass production in Q4 2026 according to Huawei's roadmap. That is, V4 training was able to run by拼凑上一代的 950PR; to make the full-blooded version like V4 Pro Max, a 1.6T MoE model, both fully trainable and deployable at scale, we must wait for the next generation to arrive.
The real engineering challenge is not "whether V4 can be trained"—it has been trained—but "how to make V4 run fully, stably, and cheaply on Ascend."
Ascend 950PR was mass-produced in Q1 2026, with FP4 computing power of 1.56 PFLOPS, on-chip memory of 112GB, paper specifications对标 and exceeding NVIDIA H20. But from a single chip running, to a whole super node stably serving millions of tokens/second inference requests, are two different things. The full-blooded version of V4 Pro Max is locked to this "super node"—the large-scale cluster version of the Ascend 950 series, which will be available in the second half of 2026.
This constitutes a strategy completely different from the previous two. Anthropic and OpenAI's logic for squeezing toothpaste is: I have something stronger, I won’t give it to you yet; DeepSeek's logic for squeezing toothpaste is: my full-blooded version must wait for a moment when the price can drop another notch.
This difference is important.
DeepSeek's real killer feature has never been "the most cutting-edge performance," but "with adequate performance, cutting the token price to a level others dare not." V4 Preview has been adapted to run on NVIDIA cards and Ascend 950PR, but to achieve full-blooded inference at production scale, we must wait for the super nodes to arrive. Once that moment comes, two things will happen simultaneously: first, V4 Pro Max's capabilities can be released to the maximum; second, inference costs and API pricing will drop another level—for a company that relies on price to break through the market, the latter is more致命 than the former.
What people truly expected, the "DeepSeek moment" that happened in early 2025, did not happen again in this release. And the release of V4 Preview is actually a trailer; the real highlight is the "DeepSeek + Huawei Ascend" moment in the second half of the year.
From this perspective, what Liang Wenfeng's team is doing now is not被迫 "hiding," but a commercially restrained "choice"—choosing to hand the premiere of the strongest version to a scenario where it has the most say: the first day after the large-scale deployment of domestic super nodes. Before that, use V4 Preview to consolidate the narrative of cost-effectiveness for another round.

What DeepSeek carries has never been the "longboard narrative" of making domestic large models rank first on some chart, but the "systemic narrative" of simultaneously making chips, training, inference, and pricing work together—the latter is far more important than the former.
Just a few days ago, Jensen Huang said on Dwarkesh Patel's podcast that if DeepSeek premieres on Huawei chips, "that's a horrible outcome for our nation."
NVIDIA still controls the top computing power for now. But according to the "AI five-layer cake" that Jensen Huang himself proposed—energy, chips, infrastructure, models, applications—the domestic large model industry already has workable domestic options at every layer, and the gap is narrowing at a visible speed. With the final piece of the chip puzzle in place, DeepSeek's open-source large model story becomes a bigger story than American large models: this is an important step towards global intelligence parity without excessive cost consumption.
Allowing the world to bypass certain advanced computing powers controlled by hegemony and enter an efficient intelligent society.
Epilogue
Anthropic's "hiding"—is active. They have Mythos, didn’t release it, citing safety.
OpenAI's "hiding"—is structural. They have Pro tiers, don’t always give them to you, citing infrastructure and price tiers.
DeepSeek's "hiding"—is necessary. It concerns a whole set of narrative templates for societal intelligence leap.
But from another perspective, this is exactly like the dark forest depicted by Liu Cixin: in this dark forest of intelligence, no top hunter will fire the first shot.
Exposure means having no reservations,意味着没有底牌, and becoming a live target for another hunter.
No one knows who will fire the most致命 shot first. But one thing is certain: every model you use today is not its true form.