Saving does not mean owning. Highlighting does not mean understanding.
Those deeply insightful articles that stirred your heart at 2 a.m., the dense web of bidirectional links you created in Obsidian, the meticulously formatted databases in Notion—they are all "cyber mummies" lying dormant in your note-taking apps.
The graphs look impressive, but they have long since decayed.
This is a systemic failure of the entire information-overload era.
Andrej Karpathy, a current Anthropic engineer, former OpenAI co-founder, and former Tesla AI director, couldn't stand it any longer. He dropped a bombshell.

Portal:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
He didn't announce a new model or release a new framework. He simply said: Treat your notes as immutable source code, and let the LLM be the compiler.
Two months later, this document has sparked a quiet yet profound migration across the Obsidian, Claude, and Cursor communities.
Some have already expanded their personal wikis to hundreds of pages and hundreds of thousands of words.
Automated plugins are emerging. Academic researchers, independent entrepreneurs, and lifelong learners are collectively shifting towards a new mode of knowledge production.
The Twilight of RAG: Information Hauling Cannot Save Your Thinking
Before LLM-WIKI, the mainstream solution was RAG (Retrieval-Augmented Generation).
Simply put, it gives a large language model a "filer." When you ask a question, it searches your notes for a few snippets and pieces together an answer.
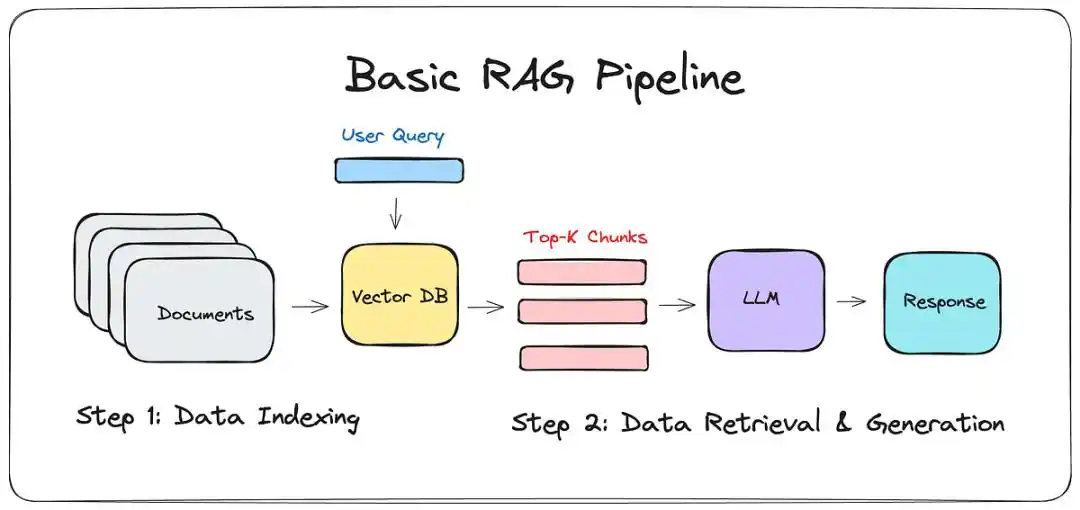
It sounds beautiful, but anyone who has used it knows the gap between "seller's show" and "buyer's reality."
It's merely a hauler: RAG only handles local context, incapable of global understanding.
It can tell you that note #5 mentions A, but it cannot tell you the underlying logic that all 500 notes collectively point towards.
It suffers from "split personality": If you believed A was correct six months ago but wrote a note refuting A yesterday, RAG often ends up contradicting itself, spouting a bunch of logically incoherent nonsense.
Graph Decay: Manually maintained knowledge links are like code without an automatic cleanup function. Over time, broken links are everywhere, and retrieval efficiency plummets exponentially.
Karpathy's insight is sharp: Search and retrieval are manifestations of human incapability. What we need is "consensus," "structure," "truth."
Treat Knowledge as Source Code, Let the LLM Be the Compiler
Karpathy's answer comes from an action programmers do every day but never think to apply to knowledge: compilation.
You write a piece of source code. You don't reread the entire code every time you run the program.
You compile it into a binary file. Compiling once is laborious, but every subsequent run is lightning-fast. The cost of compilation is amortized over thousands of future uses.
Why can't knowledge work the same way?
Karpathy says: Treat your raw notes as immutable source code. Treat the LLM as the compiler. Let it "compile" that pile of messy material once into a structured, interlinked Wiki.
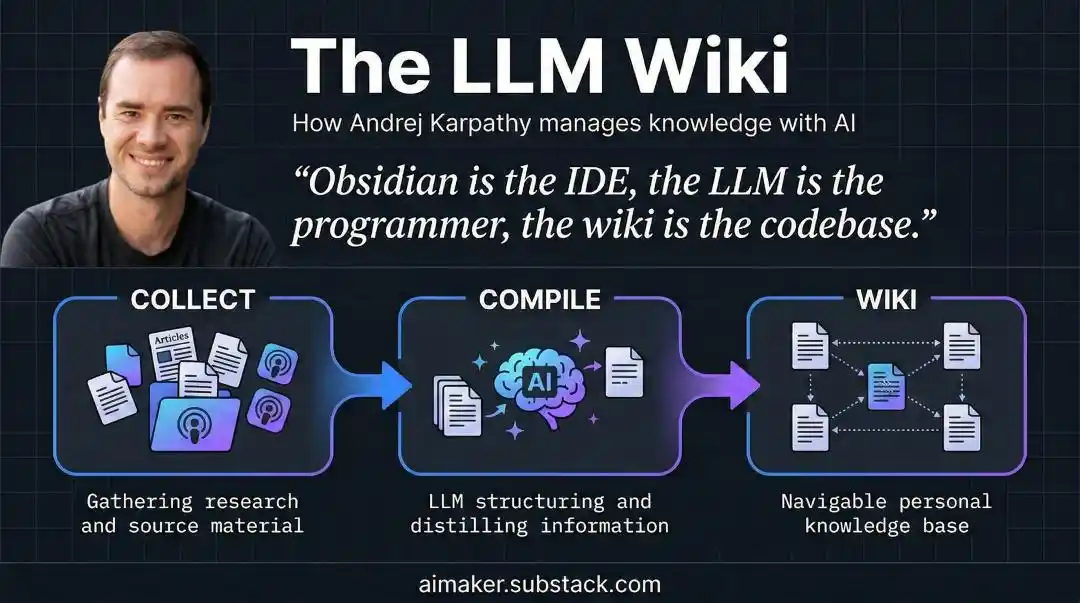
Every time you add new material, the AI performs a merge: it updates relevant entry pages, revises summaries, flags conflicts where new data clashes with old conclusions, and, in the process, reinforces or challenges existing judgments.
The key difference is here: Knowledge is compiled once and then kept fresh, not reconstructed from scratch for every query.
By the time you ask a question, cross-references are already there, contradictions have been flagged, and summaries already reflect everything you've read.
You don't recompile your source code every time you run a program. So why make the AI reread all your notes for every question?
A Fundamental Shift in the Production Relations of Cognition
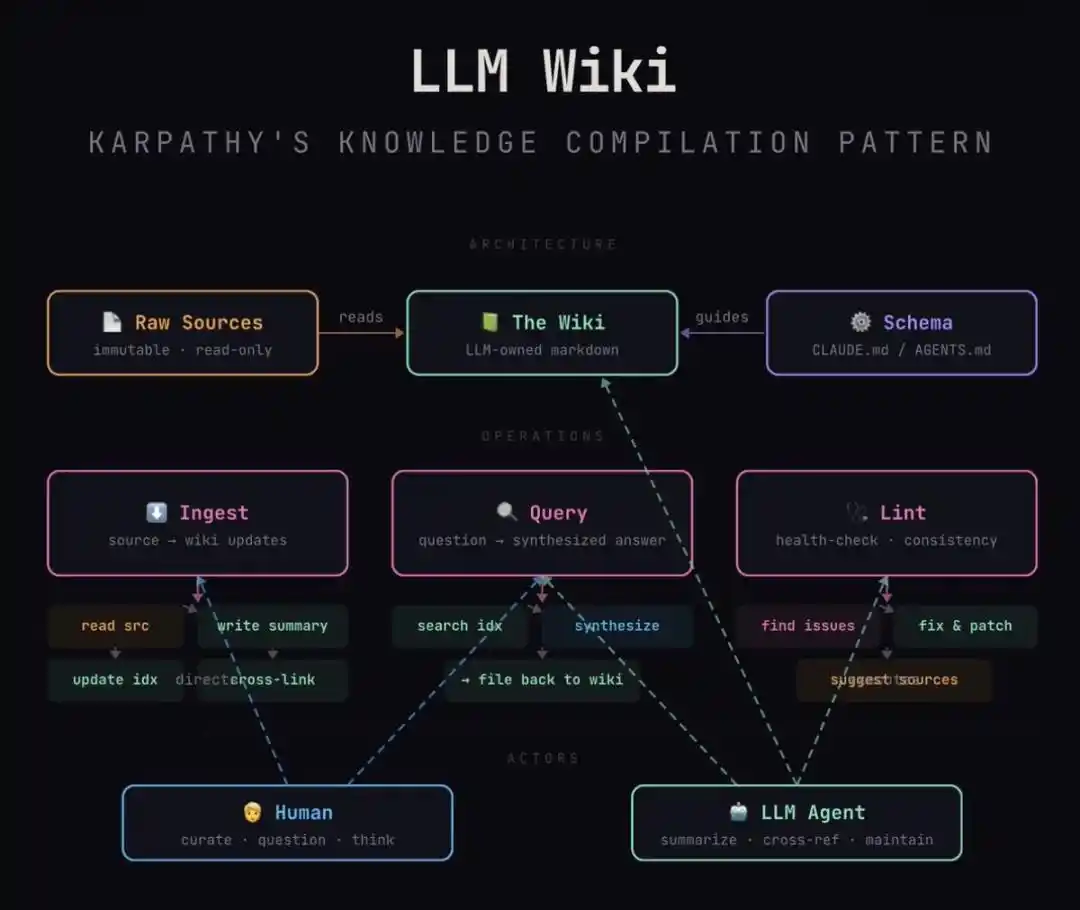
In his LLM-WIKI framework, notes are no longer dead text; they are "source code."
The large model is no longer a translator looking up a dictionary; it is the "compiler."
This architecture brilliantly achieves a three-layer decoupling:
1. Raw Layer (Raw Material): This is your mine of inspiration. Random insights you jot down, clipped articles, meeting minutes. It is "immutable," preserving the rawness and messiness of human input.
2. Schema Layer (Knowledge Constitution): This is the "rules of engagement" you write for the AI. For example, you dictate: every person entry must contain "motivation, limitations, key achievements"; every technology stack must explain "pros and cons."
3. Wiki Layer (Compiled Product): This is the zone maintained autonomously by the AI. Following your Schema, it compiles that messy pile of Raw material into structured, cross-linked, logically coherent encyclopedia pages.
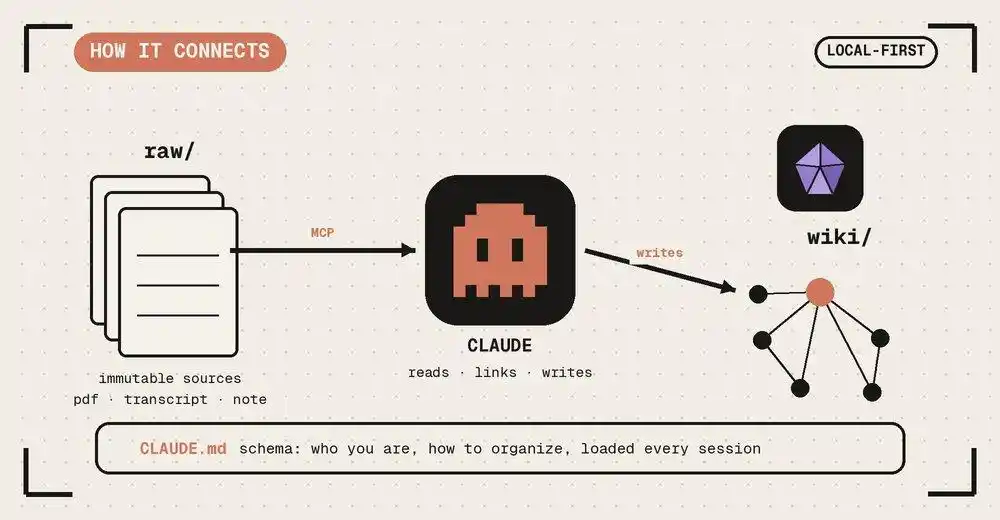
The daily workflow is three actions:
1. Ingest: Toss in a new piece of material. The AI reads it, discusses key points with you, writes a summary, and sweeps through the entire library to update related pages—one source can potentially affect a dozen pages.
2. Query: Ask the compiled Wiki directly. Answers come with citations. The best part: Excellent answers can be archived directly as new pages. Every exploration you make compounds interest.
3. Lint: Periodically have the AI perform a self-check, like code review—find contradictions, find outdated assertions, find isolated pages with no links, find gaps that need filling. Clean early, don't let the library grow rotten.
You are no longer a porter of knowledge; you are the architect of this intellectual empire.
You are only responsible for input and final review. The AI handles all the "grunt work": organizing, aligning, cross-linking, detecting contradictions.
This is a fundamental shift in the production relations of cognition.
This is not another chatbot. ChatGPT understands the internet. LLM-Wiki understands you—or more precisely, what you've taught it.
Every answer comes with [wiki-links] back to your knowledge graph. Every response is the starting point of an exploration path, not the end.
An Invention 80 Years Late
At this point, you might think this is just a clever workflow.
It's more than that.
At the end of his gist, Karpathy casually drops a name: Vannevar Bush, and his 1945 essay "As We May Think."

In 1945, just after WWII, this giant of American science envisioned a machine called "Memex":
A mechanical desk that could store all your books, records, and correspondence, and create "associative trails" between related items—connections between documents as valuable as the documents themselves.
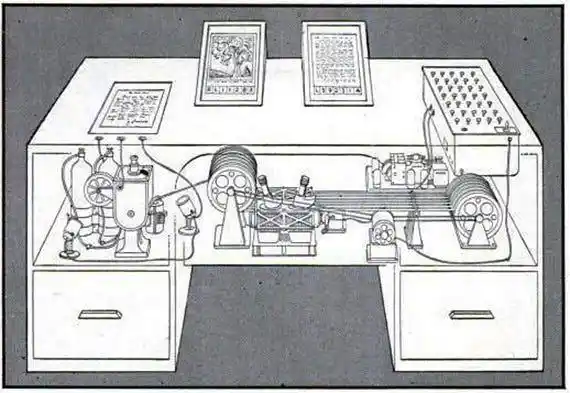
Sound familiar? This is almost a word-for-word description of LLM-Wiki.
Bush's vision was, in fact, closer to this than the later World Wide Web: a private, personally curated knowledge network where connections *are* the value.

So why wasn't Memex built in 80 years?
Because Bush was stuck on a problem he couldn't solve—who maintains it?
Every associative trail had to be created manually. Every cross-reference had to be linked by someone.
Bush imagined dedicated "operators" laying down these little paths through knowledge for you.
But reality is, no one could sustain this tedious chore at scale. Humans abandon maintenance because the cost of maintenance always grows faster than the value it brings.
Karpathy's sentence is the crux of the entire paradigm: The hardest part of maintaining a knowledge base was never reading; it was bookkeeping.
Updating cross-references, keeping summaries fresh, tagging conflicts between new data and old conclusions, keeping dozens of pages consistent. This drudgery was enough to deter anyone.
But a large language model won't forget to update a cross-reference. It can modify fifteen files in one go.
It doesn't get tired. It doesn't get annoyed. It doesn't collapse from late-night fatigue. The maintenance cost is driven to near zero.
Thus, the machine that had stumped humanity for eighty years suddenly started running.
What's Liberated is Human Attention
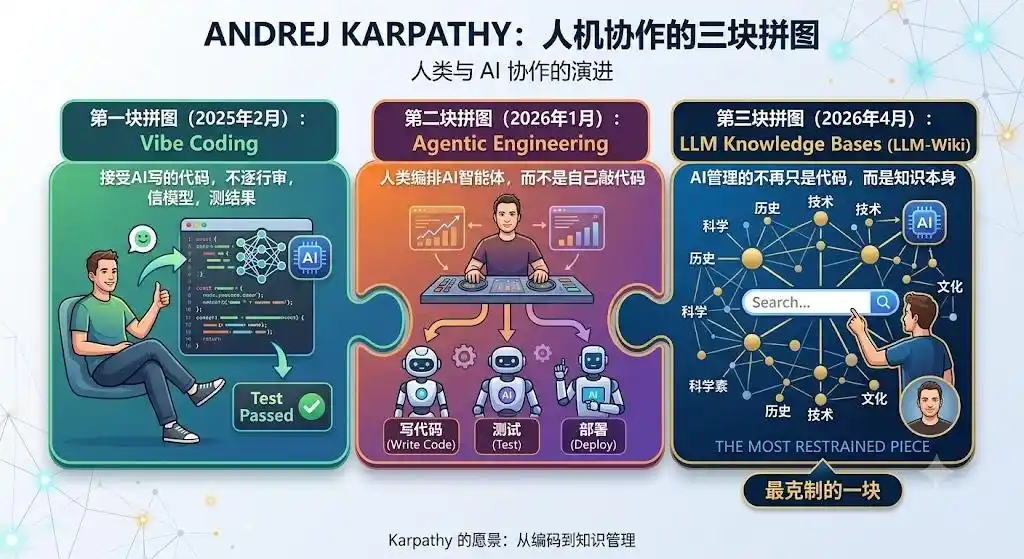
Looking back, LLM-Wiki is Karpathy's third piece in the puzzle of "human-computer collaboration," and also the most restrained.
The first piece, Vibe Coding (Feb 2025): Accepting AI-written code, not reviewing line-by-line, trusting the model, testing the outcome.
The second piece, Agentic Engineering (Jan 2026): Humans orchestrating AI agents, not writing code themselves.
The third piece, LLM Knowledge Bases (April 2026): What the AI manages is no longer just code, but knowledge itself.
In this new paradigm, what is stripped away from humans are the chores no one likes to do: saving, organizing, linking, bookkeeping.
What remains for humans are only two things: deciding *what* to read, and figuring out what all of it *really means*. These are precisely the two things machines still cannot do and should never do for you.
This is a story of a tool evolving to its extreme, ultimately coming full circle to return human attention back to humans themselves.
That plain, almost unassuming markdown file didn't announce a model or top a leaderboard.
It just quietly reminded us: Your brain was never meant for bookkeeping.
This article is from the WeChat public account "新智元" (New Zhiyuan), author: ASI启示录







