Some cheered, calling this OpenAI's "most open" move. By equipping Codex with a plug socket for freely swappable models, they essentially filled the moat protecting their own models. What's their motive?
Overnight, OpenAI's coding agent Codex stopped recognizing only its own GPT models and opened up to all open-source models.
The developer community was the first to notice this signal.
A developer discovered a strange "open-source mode" (OSS mode) in Codex's command-line interface (CLI) and software development kit (SDK) configuration, officially referred to as "local providers."
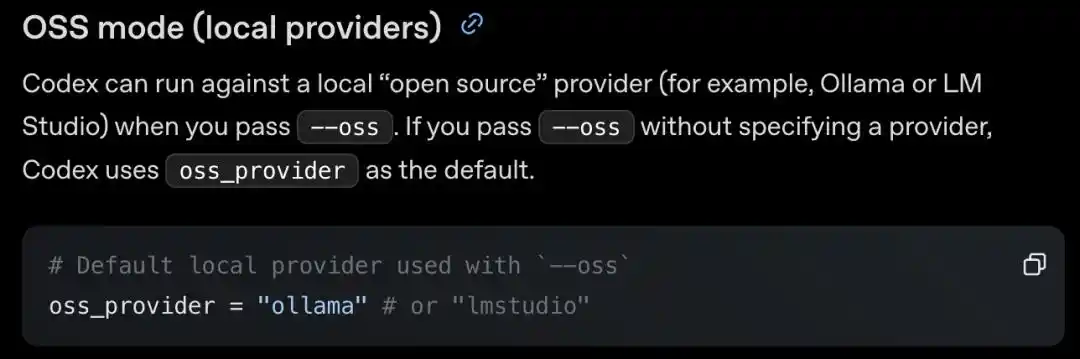
By adding a --oss flag in the command line, it can run open-source models locally; to connect to others, just change one field.
In the past, OpenAI was almost synonymous with "closed source," with Codex exclusively recognizing OpenAI's own GPT.
But now it's different. With just a single line of configuration, you can switch to local model services like Ollama and LM Studio.
This news quickly exploded within developer circles.
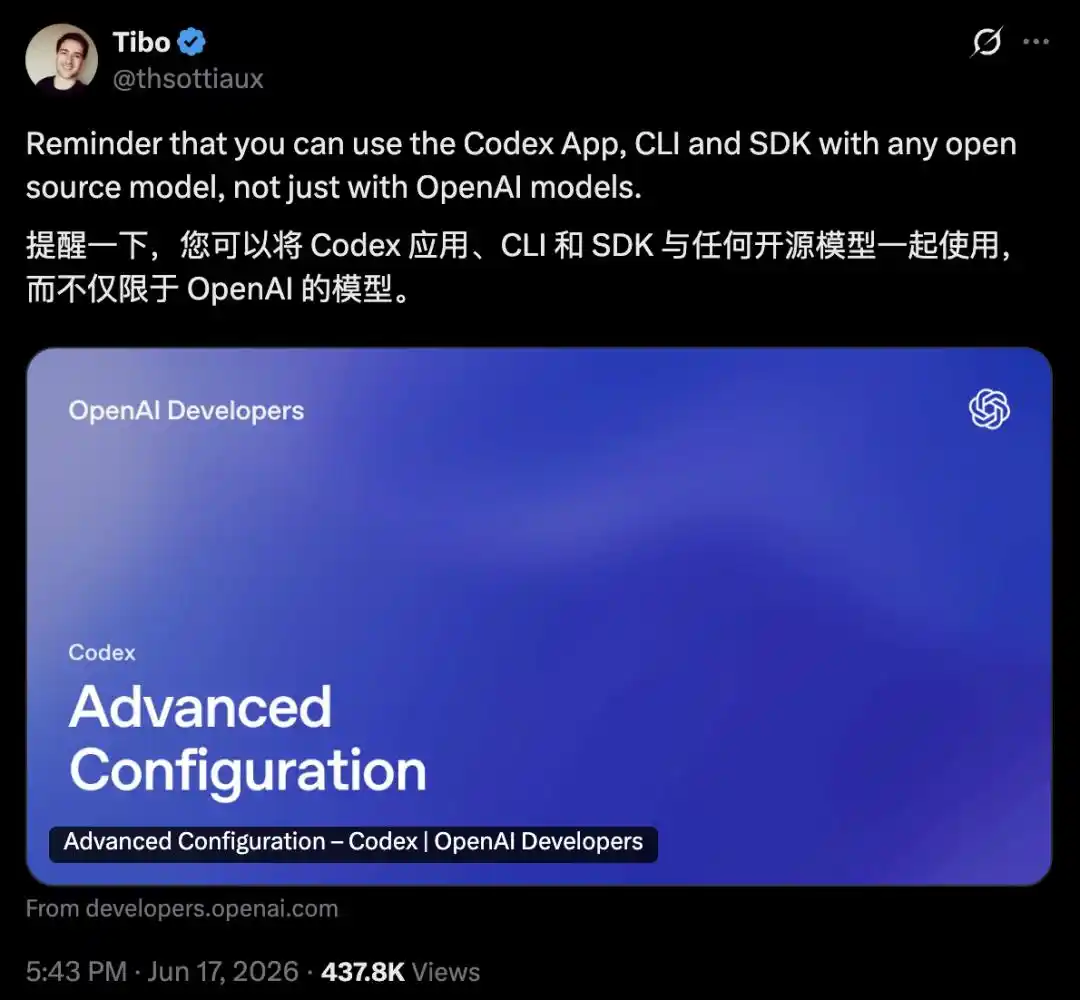
Tibo, the lead of the OpenAI Codex team, personally reminded everyone on X:
Codex's App, CLI, and SDK can be used with any open-source model, not just OpenAI's own.
This reminder was quickly retweeted by Thomas Wolf, co-founder of Hugging Face, who added: "Just learned today that Codex can actually use open-source models now."

Some netizens exclaimed that this might be the most "open" move ever by OpenAI, a remarkable event.

The community moved even faster.
As soon as the official documentation was released, developers immediately tried integrating some open-source models and casually discussed more token-efficient hybrid solutions.
But some hit a wall quickly.
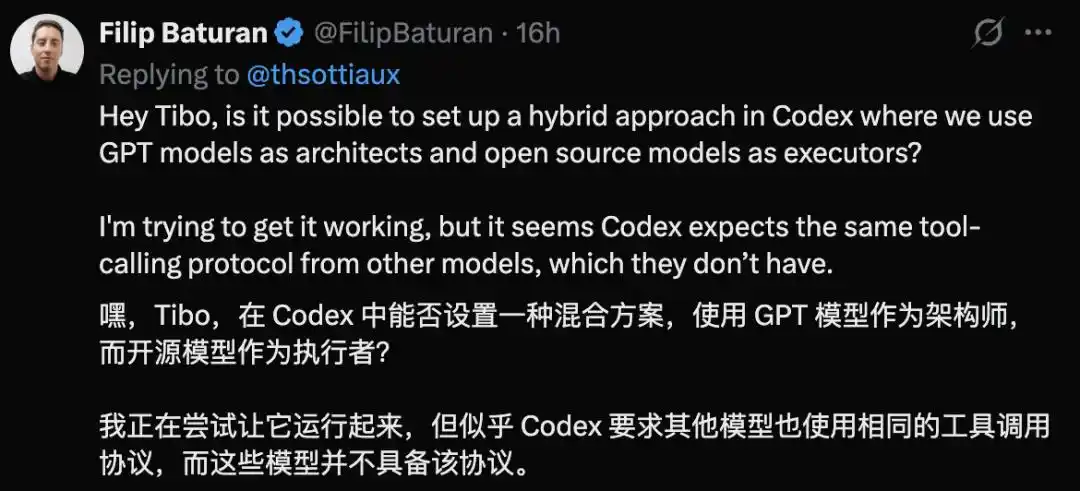
Developer Filip Baturan wanted to set up a hybrid solution in Codex: let GPT handle planning and let an open-source model act as the executor.
After testing, he found that Codex requires connected models to also use the same tool calling protocol, which open-source models might not have.
On one side, cheers for the "most open ever" move; on the other, protocol incompatibility preventing integration.
How far has OpenAI truly opened up this time?
How Are Open-Source Models Integrated into Codex?
OpenAI's opening of Codex this time is essentially not about opening the model itself but about opening the "model integration layer."
In other words, it hasn't opened the GPT model but has added a "pluggable model interface layer" to Codex.
This capability is accomplished through a configuration called "model_providers."
Developers can register multiple "model providers" in the configuration file, each containing four types of information:
Access address (base_url), communication protocol (wire_api), authentication method (env_key), and model mapping (model).
When Codex starts, it selects the corresponding model provider based on the configuration, routing requests to different model services, including OpenAI's own models, local Ollama models, or third-party APIs like DeepSeek.
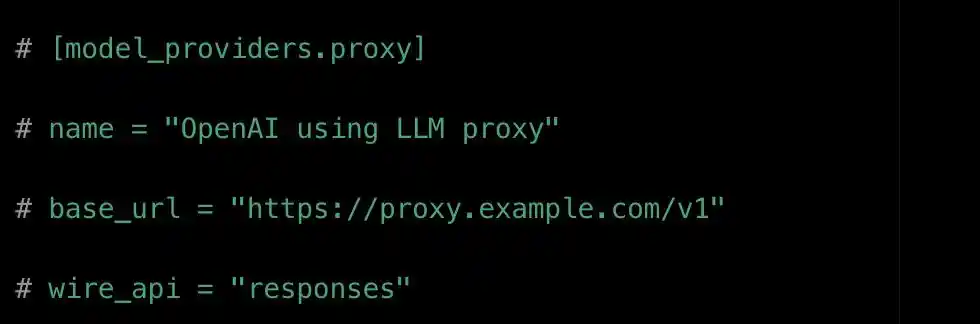
Example of Codex's model_providers configuration. base_url is the model address, and the protocol field wire_api only recognizes one value: 'responses'.
Mistral, company self-built proxies, third-party gateways—all can be integrated into Codex this way.
A netizen summarized the highlights of this capability as: "Not locked to one vendor, switchable on demand, with privacy and costs under your own control."
More conveniently, you can save all these settings as "configuration profiles." When debugging, just click its name in the command line to switch.
Compared to manual configuration above, there's an even more direct switch: --oss. Adding this parameter makes Codex directly connect to local open-source model services.
By default, there are two: Ollama and LM Studio. The former is the most popular tool for running large models locally, and the latter is a desktop alternative with a graphical interface.
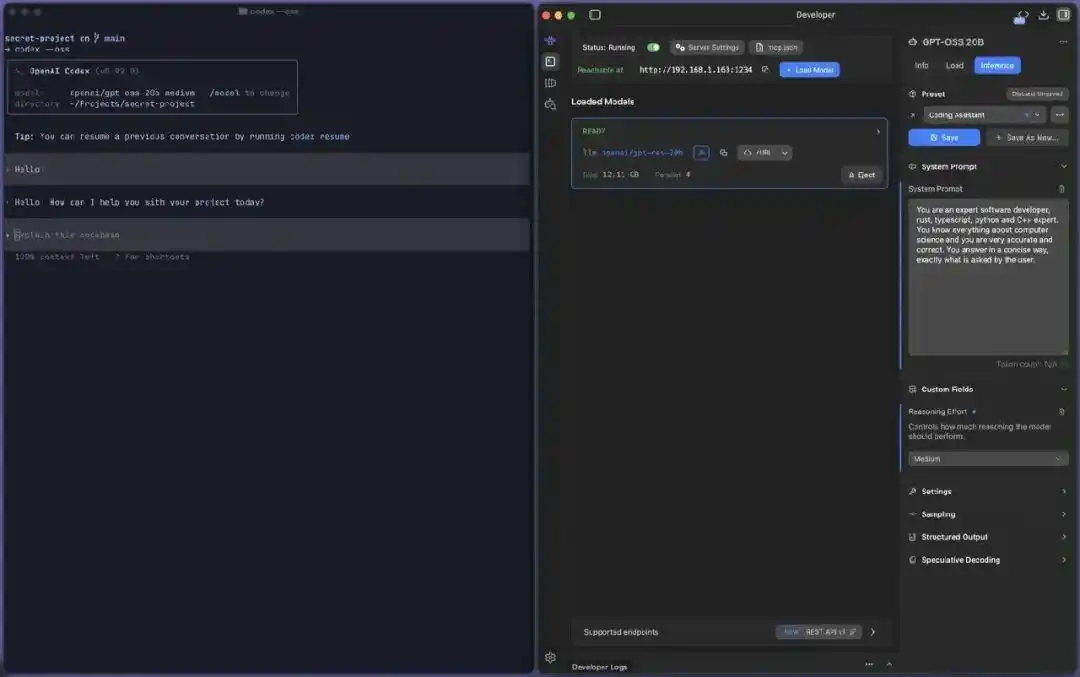
Practical screenshot of Codex --oss connecting to local models: On the left, Codex CLI (v0.92.0) uses --oss to call a local model. On the right, LM Studio loads openai/gpt-oss-20b (12.11GB) on the local machine's port 1234 to provide services. The entire process is offline and local.
This means that through local model services and network permission configuration, you can have Codex perform code generation and inference on your machine, achieving a degree of offline operation and local processing.
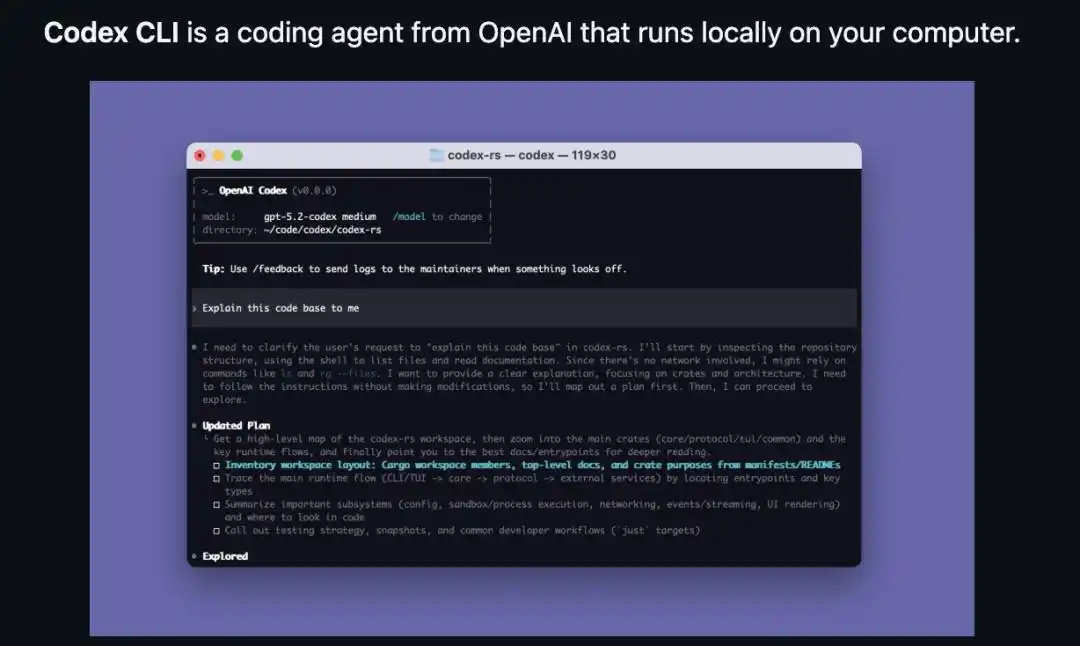
Codex CLI interface: The startup information shows the current model (gpt-5.2-codex) in the 'model' line, followed by "/model to change." A single command can switch models, with the entire agent running locally on the machine.
However, just because a socket is installed doesn't mean any appliance plugged in will work.
Integrated models typically need to be compatible with the Chat Completions interface format. As for whether more complex capabilities like function calling can fully work, OpenAI hasn't guaranteed it—you'll have to test them one by one.
It's precisely because protocols often don't align perfectly that the community has to write their own routing tools for translation in the middle. These are solutions currently explored by the community, not yet endorsed by OpenAI.
When GPT and Open-Source Models Mix
Working Together in Codex
While OpenAI just opened a crack, the community is already having a blast.
The reason is simple: Codex is good, but using OpenAI's models with token-based billing is too expensive.
Thus, many developers have turned their attention to open-source models.
DeepSeek is one of the most familiar open-source models for many Chinese developers. A natural question is: Can Codex directly use DeepSeek?
The answer from CC Switch is: Yes, but not directly; it needs an extra layer of "gateway."
CC Switch community tutorial: "Running DeepSeek with Local Routing in Codex"
Their community tutorial "Running DeepSeek with Local Routing in Codex" points out that the reason is the new version of Codex is mainly based on OpenAI's Responses API, while DeepSeek and most open-source model interfaces are still based on Chat Completions.
The two interface sets are not entirely consistent in request structure, streaming output methods, and function calling mechanisms.
So directly entering DeepSeek's address into Codex doesn't work smoothly. Common situations include mismatched request parameters or unparseable return results, leading to call failures or abnormal outputs, not just simple "connection failure."
The community's solution is to add a local "routing layer" or "protocol converter" in the middle.
The basic process is as follows:
1. Codex sends requests according to the Responses API;
2. The routing layer converts it to Chat Completions format;
3. Forwards it to open-source models like DeepSeek;
4. Converts the returned results back to the Responses format recognizable by Codex.
Similar capabilities aren't offered only by CC Switch.
LiteLLM, claude-code-router, and various proxy services built by developers essentially solve the same problem: enabling interaction between different models through a unified interface standard.
OpenAI opened a crack this time, but true implementation still requires the community to "add bricks and tiles."
Behind all this is a hybrid routing approach.
For example, let GPT handle planning: decomposing tasks, designing architecture, figuring out what needs to be done. Let open-source models handle execution: turning solutions into runnable code, batch editing files.
Through such mixing, for the same task, costs might be slashed by more than half.
Besides being more cost-effective, pairing Codex with local open-source models means not a single line of code leaves your own computer.
For individual developers who don't want to upload private projects to the cloud or keep paying API fees, this temptation is no small matter.
The Model War is Over
The Interface War Has Begun
For the past few years, everyone thought the moat was the model. Whoever had the largest model parameters, highest benchmark scores, and smartest answers would win.
But this time, OpenAI made Codex into a pluggable interface layer, and the value it provides is shifting towards an ecosystem gateway.
OpenAI's plan is likely to pivot from being a model-selling vendor to becoming a platform and framework player: you can swap models as you like, but the tools must be mine.
Whoever occupies the entry point developers open every day holds the distribution and sits at the core of the ecosystem.
This isn't the first time OpenAI has made moves in the open-source ecosystem.
Although it hadn't released open-weight large language models for a long time since GPT-2 in 2019, under the rapid development of the open-source ecosystem (models like Llama, DeepSeek), it re-launched the gpt-oss series of open-weight models in August 2025.

These models were quickly integrated and supported by community toolchains (like Ollama, LM Studio), precisely what Codex --oss now connects to by default.
At the configuration layer, OpenAI indeed opened the model integration capability, allowing third-party models to connect through the model provider abstraction layer. However, not any model can be used directly; it must comply with their interface protocol or be converted through an adaptation layer.
At the protocol layer, it retains a key constraint: using the Responses API as the main interaction standard while allowing support for other model interfaces like Chat Completions through compatibility layers.
In other words, regardless of which model is integrated, it must align with the request and response structure defined by OpenAI. Its ultimate goal is to keep the interface standard in its own hands.
From this perspective, this previously easily overlooked interface protocol is becoming a new competitive focus.
Perhaps, this time OpenAI wants to use an inconspicuous configuration switch to start an entry-point war for AI programming, making its next phase of competition with Anthropic not about models.
For developers who open Codex every day, this is real convenience: able to run open-source models, save on tokens, and work locally offline.
But the more smoothly you use it, the deeper you delve, the harder it becomes to leave this gateway.
References:
https://x.com/thsottiaux/status/2067181377028538431
https://developers.openai.com/codex/config-advanced#oss-mode-local-providers
https://www.ccswitch.io/en/tutorials/codex-deepseek-routing-guide
This article is from the WeChat public account "New Zhiyuan," author: ASI Apocalypse, editor: Yuanyu






