The Constraint of Computing Power
Since the end of last year, domestic GPU companies such as Moore Threads, MetaX, Biren Technology, and Tianshu Zhixin have ignited a capital frenzy. However, beneath the wealth feast in the secondary market, an undeniable undercurrent is becoming increasingly clear, and the problems it triggers are becoming more urgent.
Over the past few years, domestic AI chips have primarily focused on the relatively safe and more peripheral "inference side." For instance, Doubao recently planned a massive purchase of 50,000 Tianshu Zhixin chips for inference computing tasks to meet the frequent calls from China's largest AI app terminal.
In the top tier of the computing power pyramid—AI training—domestic chips can currently only participate in peripheral "support" tasks.
AI training chips are primarily used for training artificial intelligence models, involving massive matrix operations and parameter adjustments. Therefore, they require powerful computing capabilities and high energy efficiency ratios, boasting higher performance but also a significantly higher price, such as NVIDIA's A100, H100, H200, and AMD's MI300 series.
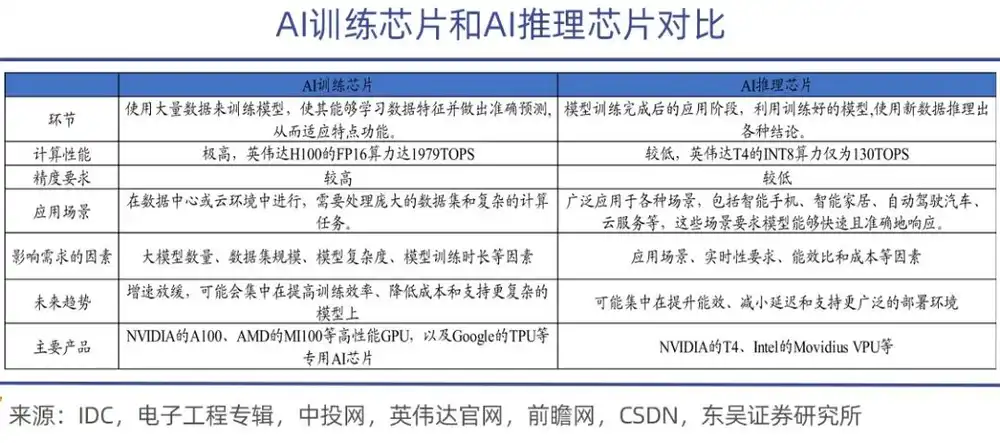
In contrast, the task of inference chips is much lighter. Used in the deployment stage after model training is completed, they are mainly responsible for executing model inference tasks, which require high real-time performance. Inference chips need to ensure rapid response and low power consumption while maintaining accuracy.
An apt analogy is that training is about making an AI model "learn knowledge," while inference is about making a large model "apply knowledge." During the learning phase, training chips must invoke massive amounts of data to "feed" dynamic updates involving billions, trillions, or even tens of trillions of parameters. They not only need robust computing power but also efficient bandwidth and communication capabilities, as well as ensuring stability in clusters with tens of thousands of cards.
The root of the Sino-US model gap lies precisely in these "invisible areas," especially the absence of high-end training chips.
Under the scaling law of large models, as model parameters increase, computing power demands grow linearly. The exponentially expanding computing power and hardware costs make training large models an "exclusive game" for a very few tech giants.
Among US tech giants, Meta alone plans to deploy over 1.2 million high-end GPUs by the end of 2026, with annual investments exceeding $145 billion; another estimate suggests Google's total AI computing power is equivalent to 5 million NVIDIA H100s, accounting for one-quarter of the global total for a single company.
The capital expenditures of Amazon, Microsoft, Alphabet, and Meta this year amount to a staggering $725 billion, a sharp 77% increase year-on-year. This scale is equivalent to 13% of the total annual private domestic investment in the United States. Morgan Stanley further predicts that by 2027, US tech companies' capital expenditures could reach a record $1.1 trillion.
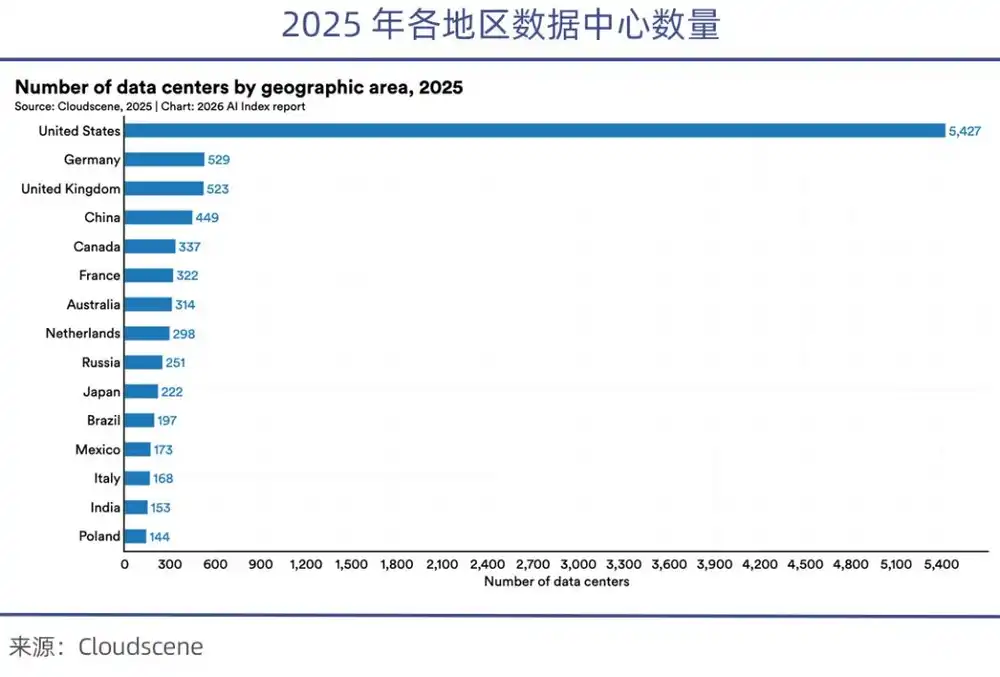
The US currently controls over 70% of the world's high-end GPUs. After the chip export bans, the high-end chips available domestically in China are only 1/8th of those in the US. The Stanford AI Index Report 2026 points out that the number of data centers in the US (5,427) is over 10 times that of China.
According to calculations by the China Academy of Information and Communications Technology (CAICT), as of early 2025, the US computing power scale was 2400 EFLOPS, while China's was 1053 EFLOPS, making the US's scale more than double that of China.
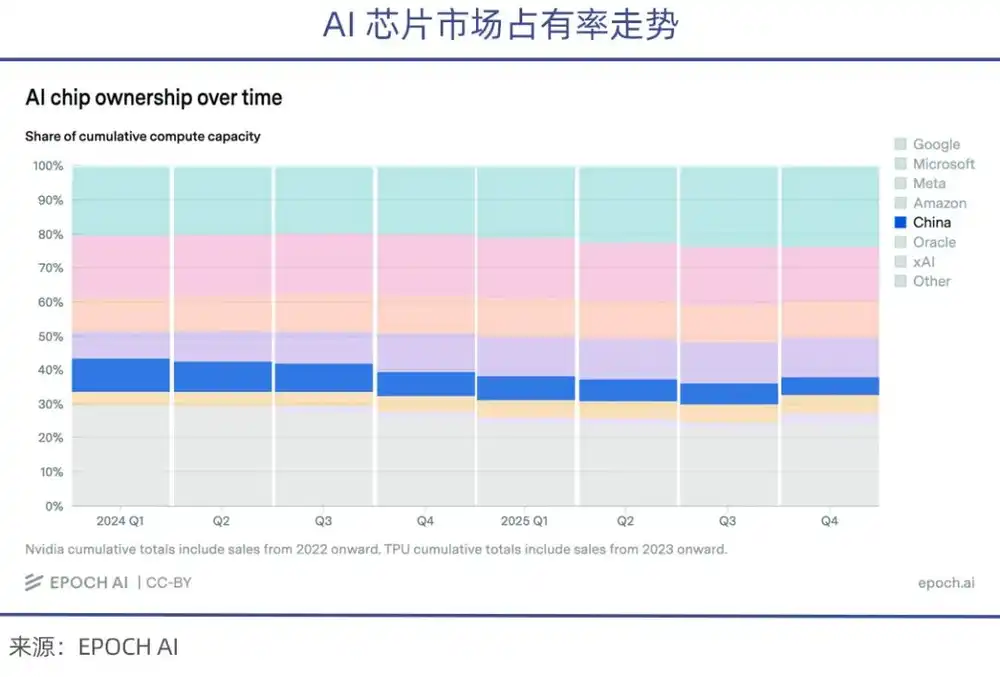
The computing power scale held by each of the aforementioned four tech giants individually has already surpassed the sum of all Chinese AI companies.
This overwhelming computing power advantage allows US companies to complete over a dozen rounds of large model iteration experiments within a year.
Elon Musk is even more extravagant. His xAI boasts the Colossus 2, claimed to be the world's "first GW-class AI cluster." Therefore, he confidently announced that he is simultaneously training 7 models—two with 1 trillion, two with 1.5 trillion, one with 6 trillion, and one with 10 trillion parameters. This kind of "brute force aesthetics" is only possible with an extreme abundance of computing power.

Meanwhile, due to US restrictions on chip exports, the share of high-end AI chips acquired by Chinese companies in recent shipments has been continuously declining (according to epoch.AI statistics).
It is no exaggeration to say that the huge gap in the computing power foundation will keep Chinese AI in a catching-up phase for a long time and will make the process for domestic large models to catch up with their US counterparts even more difficult.
The Gap Between Generations
"The pace of Chinese innovation is unstoppable," "Anyone who thinks China cannot make (chips) is truly mistaken. The gap between China and the US is only at the nanosecond level."
NVIDIA founder Jensen Huang has praised the progress of China's semiconductor industry on multiple public occasions.

Elon Musk also frequently expresses similar views on X—"China will definitely solve the chip bottleneck issue; in the field of artificial intelligence computing power, it will far surpass all other countries globally," "China will win the AI race on Earth."
Such lavish praise from globally renowned tech leaders about China's AI development can easily be taken at face value. These remarks are clearly suspect of being flattery aimed at setting unrealistic expectations. Some US media continuously propagate the narrative that the gap between Chinese and US models is minimal, attempting to obscure facts and cover up certain objective truths.
In this regard, all domestic AI-related fields should maintain a clear and calm perspective.
If it is said that China's advanced large models are not very different from their US counterparts when solving standardized problems, the gap becomes more apparent in complex industrial and enterprise environments.
Compared to cutting-edge models from US companies like Anthropic, China still belongs to the catching-up camp. US CAISI assessments suggest that China's strongest model, DeepSeek V4 Pro, lags behind the US cutting-edge by about 8 months.
Kai-Fu Lee recently stated in an interview with The Wall Street Journal that, using top US models like Anthropic's Claude Fable 5 as benchmarks, the US currently leads China by about 15 months.

Large models follow the scaling law: the larger the model parameters, the more training data, and the greater the computing power invested, the better the model's performance. Currently, the most cutting-edge US large models have entered the era of tens of trillions of parameters, and the iteration speed is still accelerating.
Anthropic's most powerful model, Mythos, has reached 10 trillion parameters, costing $10 billion to train; xAI's Colossus 2 is simultaneously training 7 models, including 6-trillion and 10-trillion parameter models; OpenAI's iteration cycle for a 4-trillion parameter model is just one month.
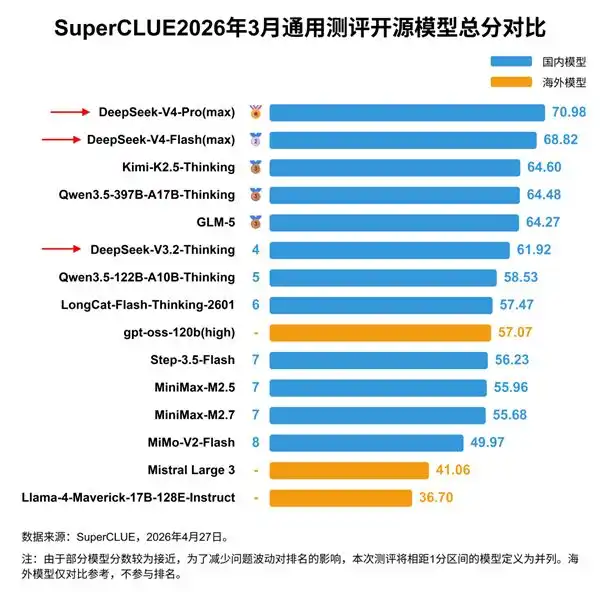
China's strongest model, DeepSeek V4 Pro, has a total parameter count of 1.6 trillion, about 6 times less than the US cutting-edge tens-of-trillions-level models.
Anthropic's Claude series has already been widely recognized as the strongest AI programming large model in recent years. Mythos has once again refreshed public perception, with its performance being even more powerful than the previous flagship, Oups 4.6.
OpenBSD is reputed in the industry for having the most secure system. Yet, Mythos found a vulnerability that had gone undetected for 27 years. It also discovered vulnerabilities in FFmpeg and the Linux kernel that had been unnoticed for years or even over a decade, and it did so completely autonomously, without human assistance.
It is important to note that a model's "pre-training" determines the upper limit of its capabilities. It is impossible to fine-tune a trillion-parameter level model through "post-training" to reach the capability level of a 10-trillion parameter model. And the decisive factor in pre-training is high-end computing power chips, which determine the parameter scale and training iteration speed.
Liu Qingfeng, Chairman of iFlytek, frankly admitted that currently, all top large model companies, especially US giants, are building ultra-large-scale computing power platforms. Domestic computing power indeed faces a painful period, leading to limitations encountered when training on ultra-long contexts.
Thus, the computing power gap is the root cause of the difference between Chinese and US models.
The Rise of Domestic Chips
One company monopolizes 90% of the global high-end AI training chip market—this has helped NVIDIA maintain its throne as the world's largest company by market capitalization. Its total market value once exceeded Germany's 2025 GDP, the world's third-largest economy.
Data from TrendForce shows that in Q1 2026, NVIDIA alone accounted for 68% of the global GPU server market, AMD held 5%-6%, while domestic GPU manufacturers collectively accounted for less than 4%.
Leveraging first-mover advantage, formidable technical barriers, high-speed interconnects, software ecosystem, and ties to TSMC's advanced processes, NVIDIA dominates the world. In high-end training scenarios, NVIDIA's GB300 outperforms AMD's MI325, as well as Cambricon's Siyuan 690 and Moore Threads' MTT40. Especially in trillion-parameter large model training, it outperforms competitors by over 30%.
Under the export bans, Jensen Huang has previously stated that NVIDIA's market share (new) in China has essentially dropped to zero, leaving only the existing stock market. Supported by domestic substitution policies, companies including Huawei's Ascend 910, Hygon's DCU ShenSuan 2, Cambricon's Siyuan 370/590, as well as Moore Threads, MetaX, and others have emerged.
Among them, the Ascend 910 is Huawei's strongest computing power chip. The Ascend 910B's computing power reaches 640 TOPS (INT8), comparable to NVIDIA's A100 chip.
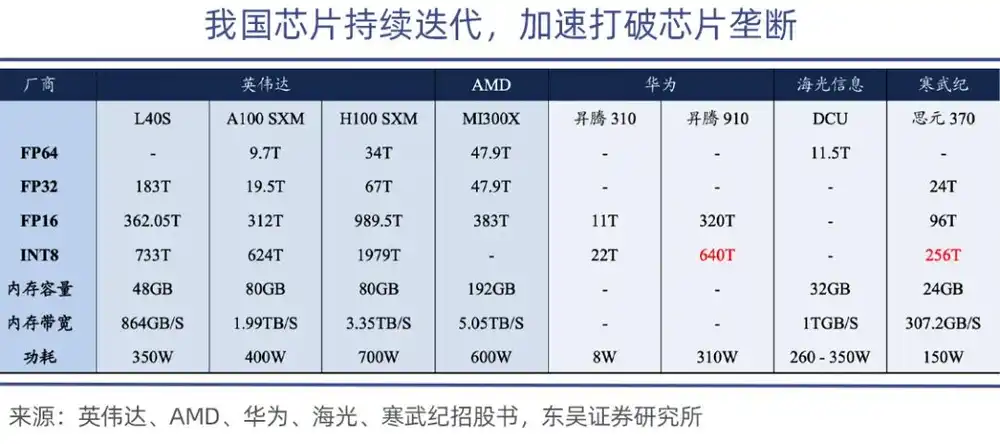
At the absolute performance level, although domestic GPUs still have a gap, they can start from inference and edge scenarios. Currently, domestic GPUs basically meet the general inference needs of domestic government and enterprise sectors. The gap with NVIDIA's mid-range products has narrowed to 15%-20%, making substitution feasible.
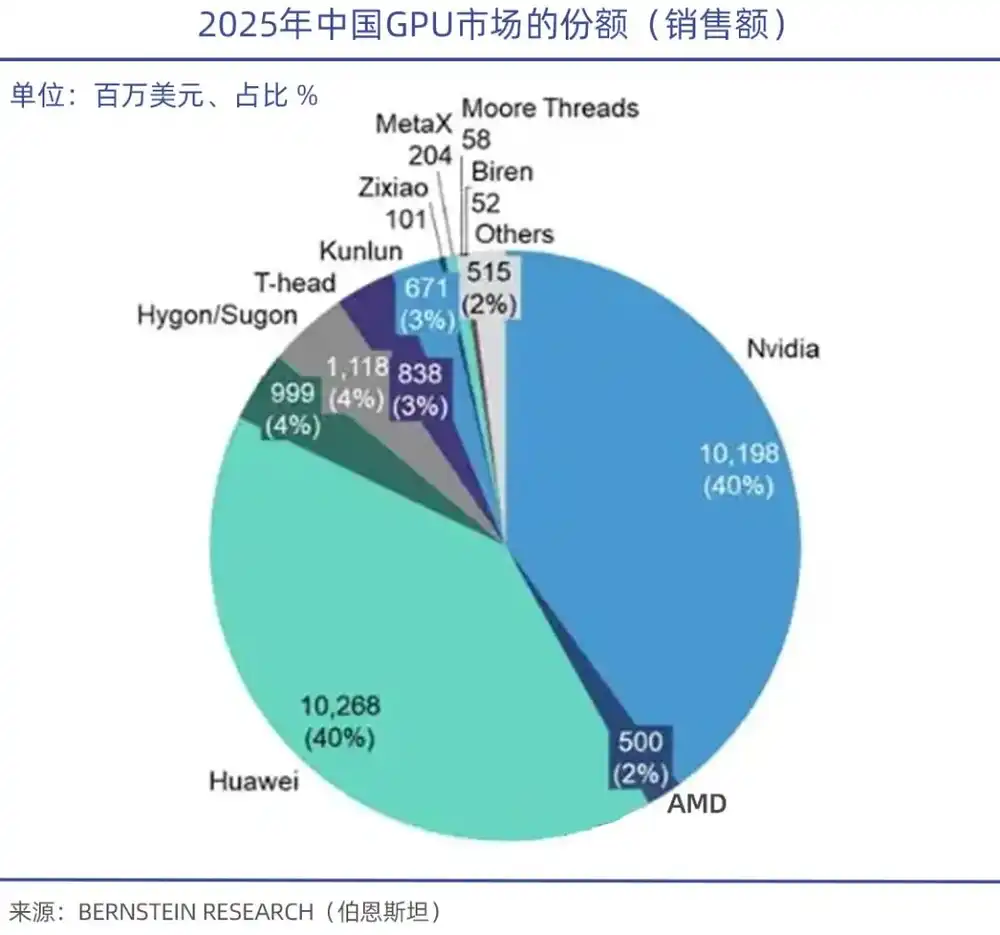
It is particularly important to note that while computing power performance is crucial, the underlying technical software ecosystem is the Achilles' heel of domestic GPUs. Just as CUDA is the foundation of NVIDIA's GPU empire, Chinese Academy of Engineering academician Zheng Weimin pointed out that the core issue with domestic AI chips is the insufficiently developed ecosystem. If the ecosystem were good, even with 60% of the performance, there would be users.
It can be said that the software ecosystem is the hardest barrier in the GPU赛道, and in this regard, NVIDIA's capabilities are equally difficult to replace.
The CUDA ecosystem, cultivated over more than a decade, now boasts over 4 million developers, hundreds of thousands of open-source models, and a full range of third-party toolchains, covering AI training, inference, graphics rendering, and scientific computing. Its ecosystem barrier is formidable and unparalleled.
IDC data shows that currently over 95% of global AI models are developed based on the CUDA ecosystem. While domestic GPUs rely on policy support, they need long-term collaboration with the industry chain and require sufficient patience from media, public opinion, and the capital market.
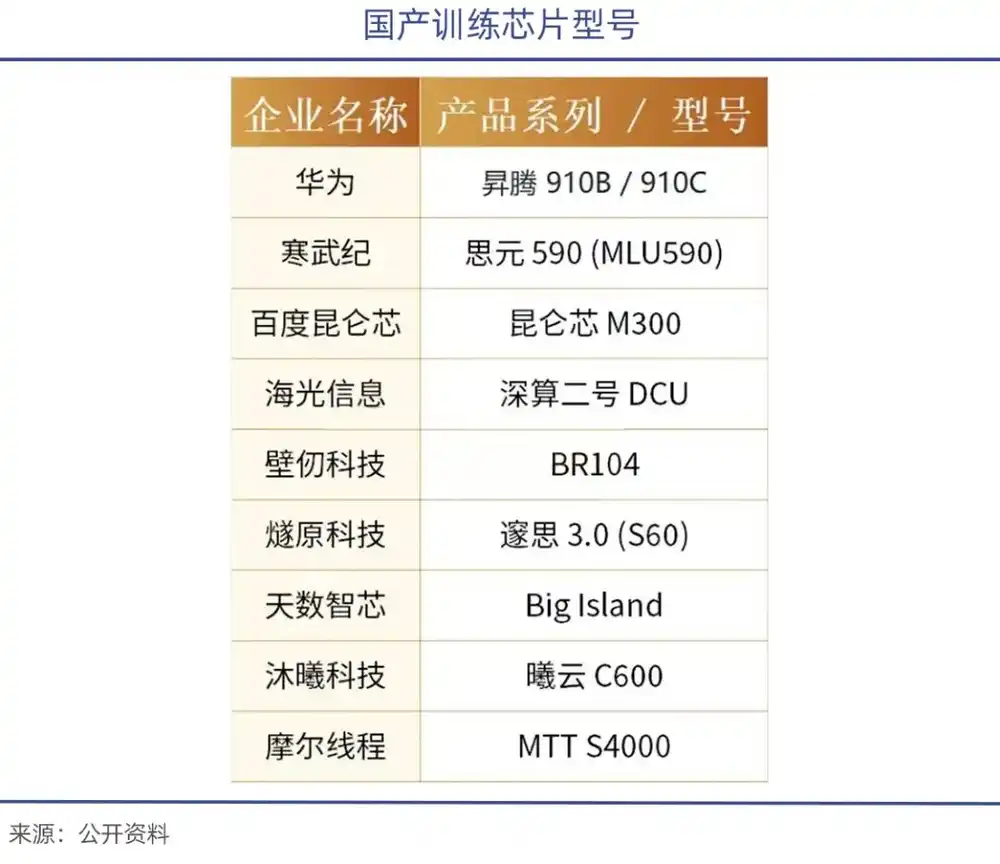
In January this year, Zhipu AI, in collaboration with Huawei, open-sourced the new-generation image generation model GLM-Image. This model was developed based on Huawei's Ascend Atlas 800T A2 equipment and the MindSpore AI framework, achieving a full-process closed loop from data processing to model training. It is the first SOTA multimodal model trained entirely on domestic chips.
Moore Threads also collaborated with the Beijing Academy of Artificial Intelligence (BAAI). Based on the MTT S5000 intelligent computing cluster and the FlagOS-Robo framework, they completed the full-process training of BAAI's self-developed embodied brain model, RoboBrain 2.5. This achievement marks the first verification of the usability of domestic computing power clusters in training embodied intelligence large models.
It can be seen that domestic GPUs have made breakthroughs in compatibility and ecosystem building, and are moving from "single-point breakthroughs" on the inference side to "gradual adaptation" on the training side. This already represents significant progress.
Summary
Overall, against the backdrop of obstacles to importing advanced foreign chips, it is advisable to "combine Chinese and Western approaches" and walk on two legs. Simultaneously, focus should be on supporting domestic computing power chips to meet urgent market demands.
The authenticity of the demand is undeniable. The "bubble theory" still exists, but its voice is not growing louder. The global market's enthusiasm for AI construction has already surpassed the early development journey of any previous industry.
Since the beginning of this year, the global capital market has once again ignited a super AI cycle. Stock prices of Samsung, SK Hynix, Broadcom, and TSMC have repeatedly hit new highs. In the domestic market, hard-tech companies represented by Cambricon have seen strong gains, and the optical module giant Zhongji Innolight's market capitalization once surpassed that of Kweichow Moutai.
Looking back at the history of South Korea's semiconductor industry, South Korea supported its memory chip industry with a national effort, endured the darkest moments, and ultimately defeated Japan to become the absolute world leader in the memory industry.
Whether it's memory chips, mobile phone chips, or even current AI chips, China is still in a catching-up stage. This is by no means an overnight achievement. However, with a huge market, continuously emerging AI talent, and massive capital strength, domestic GPUs have begun to demonstrate certain adaptability and can solve the real needs of many AI enterprises.
In this AI rivalry concerning national destinies, China and the United States are both rivals and possess technologies, markets, and resources that the other needs.
This article is from the WeChat public account: 巨潮WAVE , Editor: Yang Xuran, Author: Xie Zefeng, Original Title: "The Computing Power Dilemma in the Sino-US AI Rivalry | 巨潮"





