Les risques de l'IA qui écrit du code se cachent dans du code apparemment correct, pouvant entraîner des fuites de données ou des pertes d'actifs. Le projet open source Narwhal AI Code Risks recense des cas réels, des signaux précoces et des schémas de risques typiques, aidant les développeurs à identifier les dangers potentiels à l'avance et à éviter de répéter les mêmes erreurs.
2026, le code est généré à un rythme de plus en plus rapide, mais est déployé après de moins en moins d'examen.
De plus en plus souvent, les besoins de l'utilisateur sont placés dans une boîte de dialogue, l'IA lit le contexte, complète la fonction, met en place les dépendances, corrige la configuration, et génère même les tests.
Avant qu'on ne s'en rende compte, un morceau de code est déjà dans le dépôt, attendant d'être fusionné.
Les utilisateurs ont même développé de nouvelles habitudes : laisser d'abord l'IA écrire et faire tourner le code, puis regarder ce qui doit être modifié en cas de problème.
Mais dans le monde du logiciel, les choses les plus dangereuses sont souvent des codes qui paraissent banals : syntaxe correcte, interface légale, tests passés, commentaires parfaits.
Pourtant, ils peuvent tout de même introduire des noms de packages inexistants, ouvrir des autorisations trop larges, exposer des bases de données... ou même permettre à un Agent capable d'appeler directement les outils système, sous l'influence d'une injection d'invite, d'exfiltrer des données sensibles hors du système interne.
Ce qui est vraiment dangereux, ce n'est pas que le voyant d'erreur s'allume. C'est que tous les indicateurs de risque affichent "normal".
Les risques liés à l'IA qui écrit du code étaient jusqu'alors dispersés un peu partout : un cas dissimulé dans un blog de sécurité, une piste notée dans une Issue. Lorsqu'une autre équipe rencontrait un problème similaire, elle devait reconstituer la source du risque depuis le début et consacrer d'énormes efforts à des mesures empiriques à grande échelle sur le code.
Le Narwhal-Lab de l'Université de Pékin vient d'ouvrir en open source Narwhal AI Code Risks qui a déjà organisé ces fragments d'information, les classant en trois types : événements réels, signaux précoces et schémas de risques typiques, à la disposition des chercheurs.

Lien de l'article : https://github.com/Narwhal-Lab/Narwhal-aicode-risks
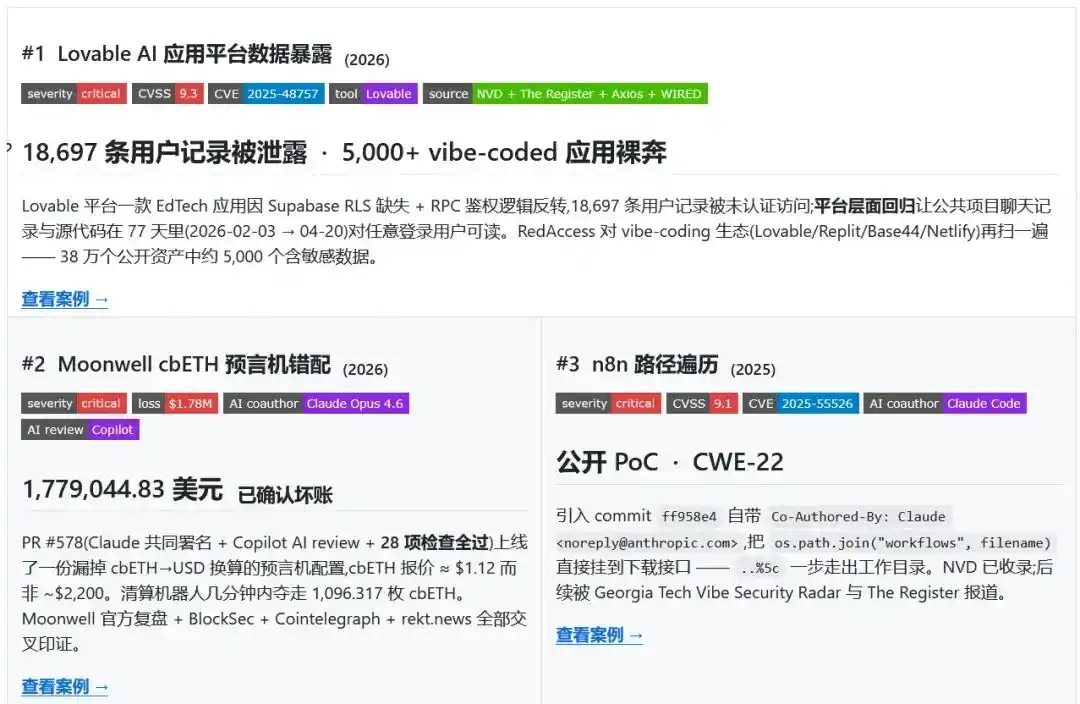
Quand les 28 vérifications sont toutes passées, le système dévie toujours
Le premier indice est une Pull Request déjà fusionnée, où la barre de signature affiche clairement Claude Opus 4.6 et Copilot, ainsi que quatre développeurs humains. Les 28 vérifications sont toutes passées : personne n'a détecté le problème.
Ensuite, le robot de liquidation a mis quelques minutes pour saisir des garanties d'une valeur de 1 778 044,83 dollars.
Dans le fichier de configuration, le prix du cbETH était défini sur le taux de conversion avec l'ETH, soit environ 1,12 dollar, au lieu du prix réel proche de 2 200 dollars.
Une erreur sémantique de prix a ainsi traversé les processus de développement, de vérification et de fusion, pour finalement se transformer en perte réelle dans le système financier. C'est ce qui rend l'incident de configuration de l'oracle cbETH de Moonwell si frappant.
Le problème vient du fait qu'il n'y avait pas d'erreur de syntaxe dans le code, et les développeurs humains n'ont pas immédiatement bloqué le processus anormal. Au contraire, tout semblait complet, fluide, c'était une livraison d'ingénierie normale.
Mais c'est précisément cette normalité aux courants souterrains qui en fait un exemple typique d'incident de sécurité.
Le risque de l'AI Coding réside dans le fait qu'il ne se manifeste pas toujours par des erreurs.
Souvent, il revêt l'apparence de la bonne réponse et entre silencieusement dans le flux d'ingénierie. Le code fonctionne, les vérifications passent, la PR est fusionnée, mais la sémantique métier s'est déjà écartée du monde réel.
Dans un projet à faible risque, cet écart sémantique pourrait n'être qu'une retouche ; mais dans des scénarios sensibles comme la finance ou les systèmes de données d'entreprise, il entraînera directement des fuites de données, des expositions de permissions et des pertes d'actifs.
Lorsque l'IA participe à l'écriture du code, à la modification de la configuration, à la relecture, voire co-signe dans une PR, avons-nous une assurance suffisante pour savoir comment chaque déviation se produit ?
Le signal de feu vert n'éclaire pas tous les recoins
Au début, l'IA vous aidant à écrire du code se limitait souvent à des complétions locales. Si la syntaxe était erronée, le compilateur signalait l'erreur, les tests unitaires échouaient, le processus d'intégration continue (CI) le rejetait.
Aujourd'hui, l'AI Coding va beaucoup plus loin, alors que la régulation tarde à suivre.
Il peut lire des fichiers, modifier des configurations, installer des dépendances, générer des scripts d'infrastructure, et permettre à un Agent de planifier de manière autonome entre plusieurs tâches.
L'IA n'est plus juste assise à côté à passer les outils, elle commence à s'insérer dans des chaînes plus longues de l'ingénierie logicielle.
Les frontières autrefois claires de l'ingénierie logicielle sont reconnectées par l'Agent d'IA en un chemin plus long, plus difficile à retracer.

Des enregistrements dispersés ont besoin d'un journal de bord public
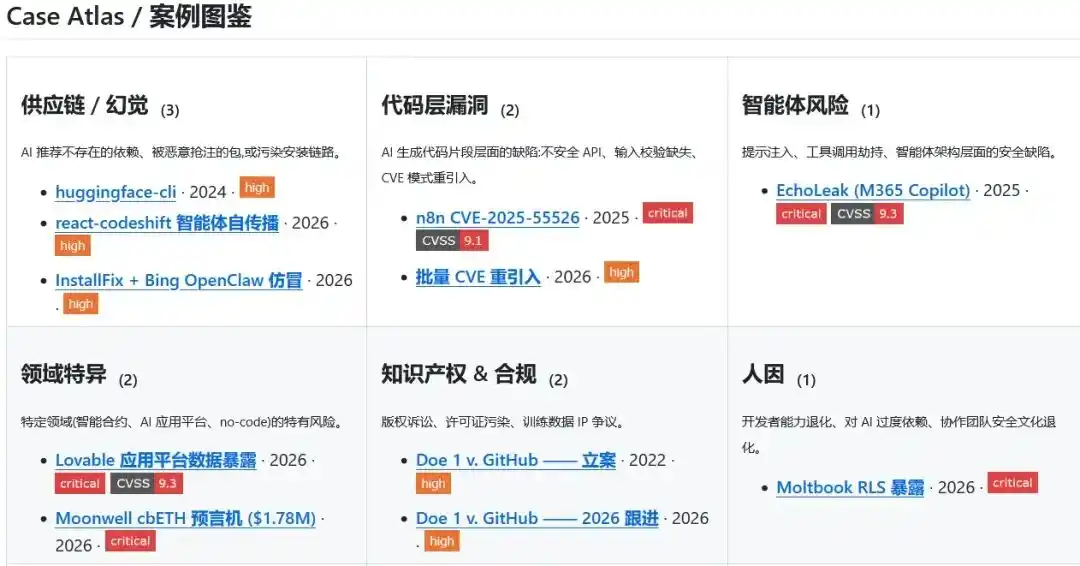
Les incidents de sécurité ont rarement des conclusions complètes dès le départ. Certains ont des preuves solides et peuvent entrer dans le répertoire comme cas réels ; d'autres restent au stade de captures d'écran communautaires, de discussions entre chercheurs ou de divulgations préliminaires, et méritent seulement d'être surveillés ; d'autres encore ne sont liés à aucun événement réel unique, mais présentent déjà un schéma clair, adapté à une simulation préalable.
Narwhal AI Code Risks divise les matériaux en trois couches : `cases/`, `inferred/` et `scenarios/`.
cases/ enregistre les événements réels ayant des sources publiques et une chaîne de preuves étayée ; inferred/ conserve les signaux précoces qui ne sont pas encore totalement avérés, mais méritent un suivi continu ; scenarios/ organise les scénarios typiques qui ne sont pas liés à un événement unique, mais dont le schéma de risque est suffisamment clair.
Sans un tel enregistrement public, les risques de l'AI Coding pourraient facilement devenir une mémoire à court terme sur Internet.
Aujourd'hui, on se souvient d'un nom de package, demain on discute d'une exposition de données, dans quelques mois on est submergé par une nouvelle vague d'outils. Lorsqu'un problème similaire réapparaît, les équipes foncent toujours comme des mouches sans tête dans une zone de navigation aux risques inconnus.
Ce que fait Narwhal AI Code Risks, c'est figer ces fragments de risque épars, pour que les personnes suivantes puissent se référer à la même page.
Suivre les sept catégories d'index, voir d'où vient le risque
Les problèmes apportés par l'IA qui écrit du code ne sont pas seulement dans le code. Ils sont dans les dépendances, dans les permissions, dans les appels d'outils de l'Agent, et surtout dans la façon dont les humains font confiance à la sortie de l'IA.
Narwhal AI Code Risks classe actuellement les risques en 7 catégories : chaîne d'approvisionnement, vulnérabilités au niveau du code, configuration cloud et infrastructure, risques liés aux Agents, risques sectoriels, risques de propriété intellectuelle et de conformité, et facteurs humains.
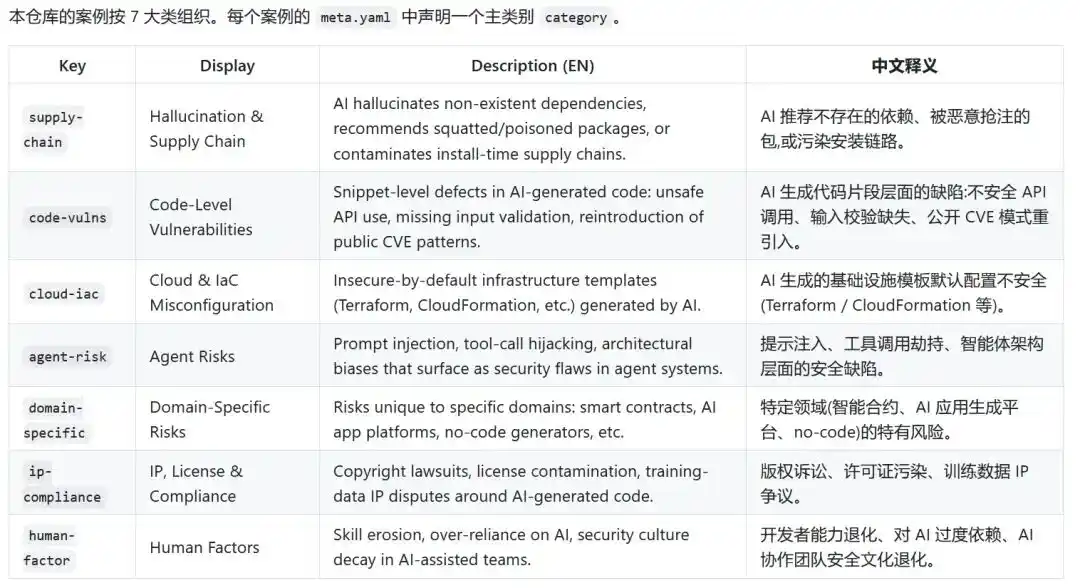
Dans les risques de la chaîne d'approvisionnement, l'IA peut recommander des dépendances inexistantes. Dans les vulnérabilités au niveau du code, l'IA peut réintroduire des traversées de répertoires, des absences de validation d'entrée, des problèmes d'authentification dans le code métier. Dans la configuration cloud et infrastructure, l'IA peut, pour faire tourner le code rapidement, accorder des autorisations trop larges, des buckets de stockage publics ou des ports exposés. Les risques liés aux Agents sont plus complexes, il ne s'agit plus seulement de générer du texte, mais de commencer à exécuter des actions. Les productions de l'IA sont en train de semer des dangers dans des systèmes réels.
Le moteur de l'IA démarre, et le journal de bord commence tout juste à s'écrire
Alors que l'IA pénètre progressivement dans le monde réel, la prévention des risques associés ne devrait pas se limiter à des analyses post-mortem ou des discussions éparses.
L'aspect vraiment important de Narwhal AI Code Risks est de transformer les cas de risque en connaissances réutilisables.
Les développeurs peuvent l'utiliser pour identifier des problèmes similaires ; les chercheurs en sécurité peuvent s'en servir comme base d'échantillons ; les éditeurs d'outils peuvent en extraire des règles de détection et des benchmarks d'évaluation ; la communauté open source peut également continuer à ajouter de nouveaux cas, de nouvelles preuves et de nouveaux types de risques.
Le moteur de l'IA rugit, et chaque déviation devrait laisser ses coordonnées. Le risque ne disparaît jamais parce qu'on l'ignore, mais l'expérience peut être enregistrée et transmise. La valeur réelle ne réside pas dans la découverte d'une vulnérabilité, mais dans le fait que ceux qui suivent n'aient pas à retomber dans le même piège.
Ce que Narwhal AI Code Risks est en train de faire, c'est laisser un journal de bord open source pour le monde logiciel de l'année charnière de l'IA appliquée.
Références :
https://github.com/Narwhal-Lab/Narwhal-aicode-risks
Cet article provient du compte WeChat public "新智元", auteur : LRST







