ИИ все больше похож на человека, и теперь люди вынуждены доказывать, что они не ИИ.
Только в этом месяце в литературных кругах произошло два случая.
Первый — произведение, получившее Содружественную премию за короткий рассказ, было определено сторонним инструментом для обнаружения ИИ как «100% сгенерированное ИИ». Организаторы использовали Claude для повторной проверки, но не получили аналогичного результата.
Второй случай — новый роман лауреата Нобелевской премии по литературе был заподозрен в написании с помощью ИИ еще до публикации.
ИИ становится все мощнее, и тексты, изображения и видео все труднее различить невооруженным глазом. Но при этом инструменты для определения у людей не стали столь же надежными.
Так возникает новый порядок.
Победители литературных премий должны объяснять свои работы, нобелевские лауреаты — объяснять свой творческий процесс, художники — делать скриншоты, вести прямые трансляции, показывать слои, а обычные блогеры могут столкнуться с комментариями «слишком пахнет ИИ».
Раньше машины стремились пройти тест Тьюринга, доказывая, что они похожи на людей.
Теперь все больше людей участвуют в обратном тесте Тьюринга: доказывают, что они не машины.
01
Даже нобелевскому лауреату не избежать «определения ИИ»
В мае этого года произведение, получившее Содружественную премию за короткий рассказ, вызвало крупный спор о «определении ИИ».
Вызвал споры короткий рассказ писателя из Тринидада и Тобаго Джамира Назира (Jamir Nazir).
Это произведение получило региональную премию Карибского бассейна Содружественной премии за короткий рассказ 2026 года и было опубликовано в литературном журнале Granta. Вскоре читатели и коллеги по цеху начали сомневаться в языке рассказа: в нем заметны следы ИИ — смешанные метафоры, упорядоченные предложения, риторика, будто сгенерированная массово.

Затем инструмент для обнаружения ИИ Pangram выдал, казалось бы, совершенно определенное суждение: 100% сгенерировано ИИ.
Цифра 100% выглядела как железное доказательство, но она не сразу стала вердиктом.
Фонд Содружества заявил, что все финалисты подтвердили, что не использовали помощь ИИ; Granta также не могла, основываясь лишь на результате одного теста, признать автора нарушившим правила.

Таким образом, дело перешло в крайне абсурдную стадию. Журнал Granta попытался использовать Claude для повторной проверки этого рассказа, попросив другой ИИ определить, написан ли он ИИ.
В результате Claude не дал однозначного ответа, то есть произведение, которое Pangram решительно определил как «100% сгенерированное ИИ», Claude не смог уверенно определить.
Лауреат Нобелевской премии по литературе Ольга Токарчук (Olga Tokarczuk) также недавно столкнулась со спорами.
Причиной послужило ее интервью, в котором она рассказала, что использует ИИ для помощи в разработке идей, систематизации материалов, предварительного исследования и проверки фактов.

Это заявление быстро вызвало обсуждение в обществе. Что еще хуже, у Токарчук скоро выходит новая книга, и все начали активно обсуждать, не написана ли ее новая книга ИИ.
Впоследствии Токарчук была вынуждена публично заявить, что ее новая книга на польском языке, которая выйдет осенью 2026 года, не написана ИИ или кем-либо другим. Она подчеркнула, что на протяжении десятилетий она всегда писала одна.
В конце концов, сейчас ИИ действительно становится все сильнее, и определение ИИ становится все труднее.
В конце прошлого года The New Yorker опубликовал экспериментальную статью. Исследователи использовали произведения нескольких писателей для дообучения моделей, заставляя ИИ изучать и имитировать их личный стиль.
В ходе эксперимента студенты, изучающие творческое письмо, читали человеческие тексты и тексты ИИ, не зная об их происхождении, и определяли, какой отрывок им больше нравится. Результат показал, что почти в двух третях случаев они предпочитали версии, сгенерированные ИИ.
Это более проблематично, чем «ИИ может писать рассказы».
Автор The New Yorker Ваухини Вара (Vauhini Vara) также написала в статье, что друзья и профессиональные читатели принимали предложения, сгенерированные ИИ, за ее собственный стиль, а ее реально написанный оригинальный текст критиковали как «похожий на ИИ».
02
Художник, который «доказывает свою невиновность» с помощью записи всего процесса, хочет плакать
«Эффект зловещей долины» касается не только сущности, которая выглядит похожей на человека, но не совсем. Когда тексты, изображения и видео, созданные ИИ, все больше приближаются к человеческим, и даже самый человечный «стиль» становится покоренным, у людей неизбежно возникает экзистенциальный кризис.
Это одна из основных причин нынешней популярности «определения ИИ на глаз».
Другими словами, «определение ИИ» можно понять, за ним стоит своего рода страх — это человек? Это ИИ? А кто я? Кто мы?
Но то, что это можно понять, не означает, что это правильно. «Определение ИИ» создает проблемы для создателей в различных областях, заставляя их помимо творчества нести дополнительные затраты на «доказательство своей невиновности».
Что касается влияния ИИ, художественные круги с ним не понаслышке знакомы. Мы уже обсуждали влияние ИИ на художественные круги и сопротивление многих художников ИИ несколько лет назад.
Однако в настоящее время проблема, с которой сталкиваются художники, уже не только в том, чтобы не позволить ИИ использовать свои работы, но и в том, что их собственные работы, созданные вручную, подвергаются «определению ИИ».
Поиск в социальных сетях по запросу «UP-художник доказывает» покажет много примеров.
Некоторых художников после «определения ИИ» записывают на видео, показывая все слои, чтобы доказать, что работа создана их собственными руками.
Но часто этого недостаточно.
Один художник-иллюстратор рассказал нам, что сейчас многие иллюстраторы записывают весь процесс рисования на видео, чтобы в случае «определения ИИ» было легче доказать свою невиновность. Это также самый надежный на сегодняшний день метод.
Если записи нет или есть запись «доказательства», но все еще подозревают в «обводке по шаблону», то есть следующий шаг — пари.
Да, в художественном мире из-за ИИ уже развились пари между стороной «определяющей ИИ» и стороной «определяемой как ИИ». В одном из случаев, который мы видели, автор поста выдвинул ряд причин, таких как «разрыв волос», «проблемы со структурой плеч и шеи» и т.д., определив, что работы определенного художника, вероятно, были обведены поверх изображения ИИ или скопированы с изображения ИИ.
Стороны заключили пари на 2000 юаней, в итоге художник «успешно доказал свою невиновность», и автор поста заплатил художнику 2000 юаней.
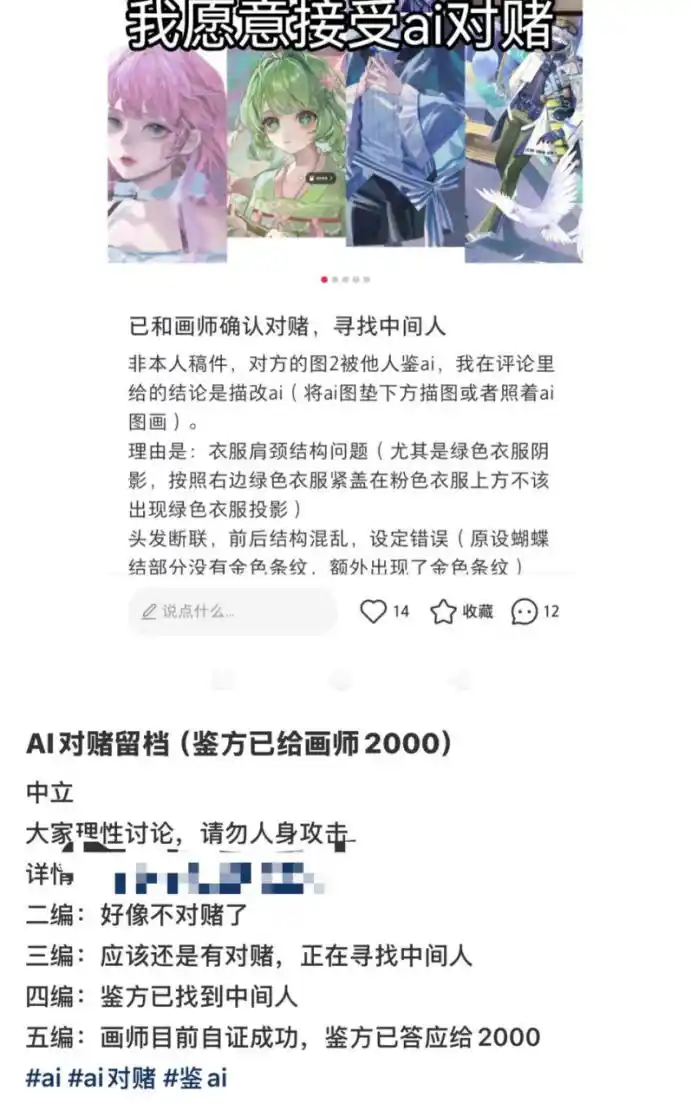
Обычно «доказательство» в рамках «пари» — это согласованная сторонами прямая трансляция процесса рисования в назначенное время. Причем трансляция должна быть многокамерной, например, одна камера показывает процесс рисования на экране, другая записывает, как художник рисует, чтобы избежать «помощи со стороны».
Из многих постов художников о «доказательстве» нетрудно заметить чувство беспомощности. Они часто сокрушаются: «Наконец-то дошла очередь до меня», и клянутся: «Это первый и последний раз, когда я доказываю».
Таким образом, с одной стороны, ненавидя «определение ИИ на глаз», а с другой стороны, когда очередь доходит до них, они вынуждены «доказывать свою невиновность», им действительно тяжело.
Были ли случаи, когда «определение ИИ» было, а художник «не смог доказать» свою невиновность? Да. Но это все равно не делает поведение «определения ИИ» более обоснованным. Ведь стоимость «определения ИИ» практически нулевая.
А средства «определения ИИ» еще более грубые — на глаз.
Здесь нельзя не упомянуть недавний курьез: пользователь X опубликовал изображение, заявив, что это сгенерированная им с помощью ИИ «картина в стиле Моне», и попросил «как можно подробнее объяснить, почему она уступает настоящему Моне».

Пост набрал 7 миллионов просмотров, многие в комментариях серьезно «определяли ИИ», говоря, что картина лишена глубины, цвета не согласованы, нет человеческого духа, композиция уступает оригиналу, и даже анализировали мазки и чувство пространства.

Развязка: эта картина оказалась подлинником Моне.
03
Кто решает в «определении ИИ»?
Так что это на самом деле противоречие между страхом перед тем, что ИИ становится все более похожим на человека, и отсутствием совершенных средств для «определения ИИ».
Грубость средств «определения ИИ» — еще один важный фактор, из-за которого создатели коллективно попадают в ситуацию «доказательства своей невиновности».
Помимо метода «определения на глаз», как упоминалось ранее в случае с произведением победителя литературного конкурса, другим основным методом «определения ИИ» является сторонний инструмент обнаружения Pangram.
Инструменты обнаружения ИИ часто используются в текстовой сфере, создавая иллюзию: они выдают процент, например, «80% сгенерировано ИИ», «100% сгенерировано ИИ». Эта цифра выглядит как вывод, даже как своего рода техническая экспертиза.

Но определение текста — это не анализ ДНК. Оно определяет, скорее, «на что статистически больше похож этот текст».
Инструменты обнаружения ИИ также смотрят на то, «похоже ли это на написанное ИИ».
Pangram объясняет на своем сайте, что его детектор ИИ использует технологии обработки естественного языка и большое количество данных человеческого и ИИ-письма для анализа структуры, стиля и семантических паттернов в текстах ИИ. Технический отчет Pangram также утверждает, что его ядро — это классификатор на основе нейронной сети Transformer, цель обучения которого — различать тексты, написанные крупными языковыми моделями, и тексты, написанные людьми.
Другими словами, такие инструменты не ищут статью в «базе данных текстов ИИ», чтобы проверить, совпадает ли она с известным образцом.
Это больше похоже на распознавание паттернов. Выбор слов, ритм предложений, структура, способы семантической связи в этом тексте больше похожи на человеческие тексты, которые он видел, или на тексты ИИ, которые он видел.
Что еще хуже, существует слишком много особых случаев. Если статья написана человеком в черновике, а затем несколько предложений отредактированы ИИ, как считать? Если план сгенерирован ИИ, а человек переписал его в полный текст, как считать? Если английские материалы переведены на китайский ИИ, а автор затем вручную отредактировал их, сможет ли инструмент обнаружения определить? Если студент и так является неродным говорящим на английском, и его предложения более правильные, шаблонные, не будет ли он легче случайно пострадать?
То же самое и в области рисования. Некоторые художники просто стонут — да, структура нарисована с ошибками, но это потому, что мне еще нужно совершенствовать мастерство, а не потому, что это нарисовано ИИ!
В 2023 году исследователи Стэнфордского университета протестировали 7 детекторов текста ИИ.
Они выбрали 91 эссе студентов-неносителей английского языка, написанное для TOEFL — эти эссе взяты из официального корпуса экзамена TOEFL, изначально написанного студентами в реальных условиях экзамена, поэтому можно с уверенностью сказать, что они не сгенерированы ИИ.
Результат: 89 из них были помечены хотя бы одним детектором как сгенерированные ИИ; средний уровень ложных срабатываний составил 61,22%; еще 18 эссе были единогласно определены 7 детекторами как сгенерированные ИИ. Другими словами, эти студенты, пишущие на иностранном языке, из-за более правильного, шаблонного выражения были приняты инструментами за машины.
Конечно, детекторы 2023 и 2024 годов нельзя просто приравнять к сегодняшним. За последние годы коммерческие детекторы действительно развивались, и некоторые новые инструменты в определенных тестах показывают явное улучшение.
Но проблема не решена.
Пока «ошибки» не устранены полностью, останется зазор для противоречий.
В конце концов, инструмент выдает вероятность, но когда дело доходит до человека, это превращается в обвинение.
04
А как же обещанные «водяные знаки»?
Более серьезная проблема в том, должны ли компании ИИ делать «маркировку происхождения»?
Разве нельзя решить проблему определения, поставив на весь контент ИИ изначальный «водяной знак», который невозможно удалить?
Многие, услышав «водяной знак», все еще представляют себе логотип в углу изображения, идентификатор платформы на видео или слова «Сгенерировано ИИ».
Но сегодняшние водяные знаки ИИ давно перестали быть такими видимыми невооруженным глазом метками.
В индустрии существуют в основном два подхода: один — метаданные, такие как C2PA и Content Credentials, что эквивалентно прикреплению «описания идентичности» к цифровому контенту, записывающего, каким инструментом он создан, когда создан, какие редактирования прошел;
Другой — невидимые водяные знаки, встраивающие сигналы, незаметные для человеческого глаза, но обнаруживаемые машиной, в изображения, аудио, видео и даже текст.
В области изображений и видео эти решения уже начинают внедряться.
SynthID от Google DeepMind может встраивать невидимые водяные знаки в контент, сгенерированный такими инструментами, как Imagen, Veo, Lyria, Gemini и т.д.
Meta заявляет, что к изображениям, сгенерированным или отредактированным Meta AI, будут добавлены видимые водяные знаки, невидимые водяные знаки и метаданные; OpenAI также добавила сертификаты происхождения C2PA к изображениям, сгенерированным DALL·E 3 и ChatGPT, а позже внедрила невидимые водяные знаки SynthID. Такие компании, как Adobe, Microsoft, Google, Meta, OpenAI, также участвуют в экосистеме C2PA и Content Credentials.

Это показывает, что компании ИИ также понимают, что полагаться только на определение «похоже на ИИ» недостаточно. Они уже пытаются использовать метаданные, сертификаты происхождения, невидимые водяные знаки и платформенные метки, чтобы оставить машиночитаемые сигналы происхождения для контента, сгенерированного ИИ.
Но эти решения не идеальны. Метаданные могут потеряться при скриншотах, сжатии, пересылке, повторной загрузке; видимые водяные знаки можно обрезать или замазать; невидимые водяные знаки более устойчивы, но также могут быть ослаблены последующей обработкой, искажением или повторной генерацией.
Что еще важнее, эти решения обычно могут идентифицировать только контент, который подключен к соответствующей системе и сохранил соответствующие метки. То есть SynthID от Google в основном идентифицирует контент с SynthID, сертификаты происхождения OpenAI в основном указывают на контент из системы OpenAI. Пока контент поступает от моделей, не подключенных к маркировке, или проходит многократную пересылку, цепочка происхождения может прерваться.
С текстом проблема еще сложнее.
Текст, конечно, тоже можно снабдить водяным знаком. Его принцип заключается в том, чтобы при генерации текста моделью незаметно изменять вероятность выбора определенных слов, заставляя итоговый текст проявлять статистическую модель, нечитаемую для человеческого глаза, но обнаруживаемую детектором. Проще говоря, это заставляет ИИ оставлять свой «лексический отпечаток».
Google уже представила SynthID-Text, заявляя, что она может встраивать водяные знаки в текст, сгенерированный Gemini. OpenAI также давно ожидают решения этой проблемы. В июле 2023 года OpenAI, Google, Meta, Amazon, Anthropic, Microsoft и другие компании взяли на себя добровольные обязательства, заявив, что будут разрабатывать механизмы, помогающие пользователям распознавать контент, созданный ИИ, включая водяные знаки и маркировку происхождения.
Но прошло несколько лет, решения для маркировки изображений, аудио и видео постоянно продвигаются, а для текста до сих пор нет четкого, включенного по умолчанию, общедоступного универсального ответа.
OpenAI в 2023 году выпустила AI Text Classifier для определения, написан ли текст ИИ, но при запуске предупредила пользователей не использовать его в качестве единственного основания для решений.
Через полгода OpenAI сняла его с эксплуатации из-за низкой точности.
В 2024 году The Wall Street Journal сообщила, что внутри OpenAI уже разработали инструмент текстовых водяных знаков, эффективность которого на достаточно длинных текстах, сгенерированных ChatGPT, может достигать 99,9%. Но OpenAI в итоге не выпустила его публично.
Причина не только в технических проблемах. В отчете упоминается, что OpenAI беспокоится, что текстовые водяные знаки вызовут негативную реакцию пользователей, повлияют на использование продукта, а также что пользователи, не являющиеся носителями английского языка, столкнутся с дополнительной стигматизацией.
Кроме того, опросы показали, что почти 30% пользователей ChatGPT заявили, что могут сократить использование, если будут включены текстовые водяные знаки.
В конце концов, возвращаясь к противостоянию между стороной «определяющей ИИ» и стороной «доказывающей свою невиновность», все вышеупомянутые решения с водяными знаками еще не могут обеспечить полную гарантию.
У людей есть поговорка: «На каждое действие есть противодействие», и еще одна: «Где закон, там и лазейка». Пока люди верят в эти поговорки, «определение ИИ» не прекратится.
Возможно, однажды «участие ИИ» станет состоянием по умолчанию, а «человеческое оригинальное творчество» станет чрезвычайно редким, и это масштабное противостояние между «определением ИИ» и «доказательством своей невиновности» потеряет смысл.
Эта статья взята с официального аккаунта WeChat «直面AI» (ID: faceaiband), автор: Сяо Цзинья, редактор: Ван Цзин.






