Oleh | Xiang Xianzhi
Luo Fuli mengirimkan sebuah postingan di X, untuk memberikan titik akhir pada polemik diskon MiMo.
Pada 26 Mei, akun resmi Xiaomi MiMo mengunggah sebuah pengumuman di X: Harga API seri MiMo-V2.5 turun permanen, dengan potongan harga tertinggi mencapai 99%. Semua panjang konteks diberi harga tetap, paket Token ditingkatkan 5-8 kali.
Pengumuman ini memenuhi lingkaran AI domestik selama seminggu penuh. Reaksi pertama industri terbagi menjadi beberapa aliran. Aliran terbesar menyebutnya "perang harga lagi" – dalam dua tahun terakhir, dari Zhipu, DeepSeek, Byte Doubao hingga Alibaba Tongyi, model besar domestik bergiliran menurunkan harga, semua sedang berlomba.
Aliran lain melihatnya dari sisi pesimis: Xiaomi baru saja mengumumkan laba tahun ini turun separuh, saat ini masih membakar 60 miliar ke AI, API langsung dipotong 90% – tipikal "merebut pasar dengan merugi". Ada juga yang menganggap ini kelanjutan efek DeepSeek – yang telah menyeret tolok ukur harga seluruh industri ke lantai dasar, siapa yang tidak mengikuti akan tersingkir.
Oleh karena itu, sebagai penanggung jawab MiMo, Luo Fili tadi malam langsung mengeluarkan sebuah blog teknis 5000 kata, membuka rincian teknis diskon tersebut kepada semua orang.
"Lihat, ini kemampuan rekayasa nyata, bukan sekadar alat pemasaran".
Untuk memahami apa yang dikatakan Luo Fuli, pertama-tama harus mengerti apa sebenarnya yang didiskon 99% itu.
Bukan seluruh model yang didiskon. Diskon 99% khusus ditujukan pada satu kategori harga bernama Input (Cache Hit) – yaitu bagian "ketika pengguna membaca ulang konteks historis dalam percakapan panjang". Potongan harga untuk input baru biasa (No Cache Hit) jauh lebih kecil, dan untuk output model (Output) paling kecil.
Jika Anda membayangkan model seperti kedai kopi, hal ini akan lebih mudah dipahami.
Anda memesan satu cangkir latte setengah gula, kedai kopi memiliki dua cara: setiap kali menggiling biji kopi, mengukur sirup, menuang susu dari awal, bahan dan tenaga kerja dibayar sekali; tetapi model tahu Anda akan minum latte setengah gula yang sama setiap hari minggu ini, jadi langsung membuat satu teko besar dan menyimpannya di lemari es, lain kali cukup ambil satu cangkir. Yang dilakukan MiMo kali ini adalah yang terakhir – mengubah bagian yang dibaca ulang pengguna dari "dihitung ulang" menjadi "diambil langsung", sehingga biaya nyata bagian ini mendekati 0, dan wajar jika bisa memberi diskon 99%.
Untuk mencapai "diambil langsung", blog teknis membahas enam upaya rekayasa, masing-masing tidak boleh dihilangkan. Mari kita bahas satu per satu di bawah ini.
Rekayasa Satu: Mengompres "memori" model menjadi 1/7
Saat model berbicara dengan Anda, setiap token harus menghitung sebuah "status perantara", disimpan untuk digunakan pada langkah berikutnya. Ini disebut KVCache – dapat dipahami sebagai "buku catatan memori jangka pendek" model. Setiap kali mengucapkan satu kalimat, model mencatat ringkasan kalimat itu di buku catatan, lain kali langsung membuka catatan, tidak perlu mendengarkan semua yang Anda katakan dari awal.
Model tradisional setiap lapisan melakukan "Full Attention" – yaitu setiap token harus melihat semua token dalam seluruh percakapan, buku catatan semakin tebal. MiMo-V2.5-Pro mengubah arsitektur: dari 70 lapisan, 60 lapisan hanya melihat 128 token terbaru (SWA, Sliding Window Attention), hanya 10 lapisan "arsiparis" yang melihat semuanya.
Hasilnya adalah volume KVCache langsung terkompresi menjadi 1/7 dari Full Attention, dengan perhitungan yang sama yaitu 1/7.
Ini adalah fondasi pertama penghematan biaya. Misalnya, awalnya setiap karyawan diwajibkan mengingat semua catatan rapat, hasilnya otak setiap orang tidak cukup dan efisiensi rendah. Peraturan baru mengurangi beban otak 60 karyawan menjadi 1/7, hanya menyisakan 10 arsiparis yang mengelola semua sejarah – kemampuan mengingat keseluruhan perusahaan tidak turun, tetapi efisiensi meningkat 7 kali lipat.
Rekayasa Dua: Memastikan ruang yang dihemat SWA benar-benar dapat digunakan
Langkah pertama adalah mengompres buku catatan menjadi 1/7 secara arsitektur, tetapi untuk mewujudkan "1/7 secara teori" menjadi "1/7 secara nyata", masih ada satu kendala.
Sistem KVCache tradisional mengalokasikan memori untuk semua lapisan secara seragam berdasarkan "penggunaan maksimum yang mungkin". Artinya: meskipun 60 lapisan SWA hanya membutuhkan buku catatan kecil, sistem juga mengalokasikan untuk semua lapisan berdasarkan "buku catatan besar arsiparis" – ruang yang dihemat SWA disisihkan sia-sia, sama saja tidak menghemat.
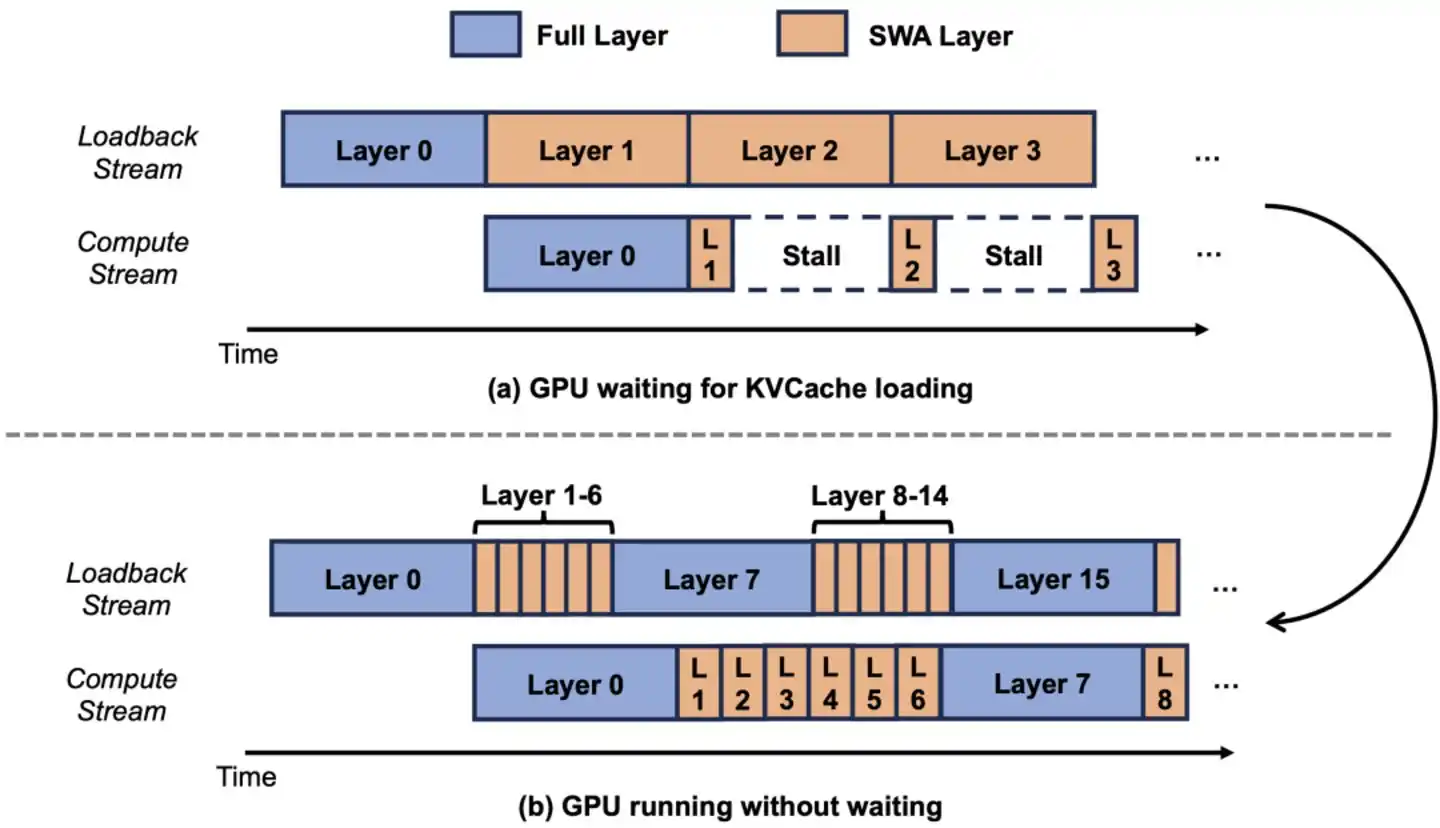
Cara yang dilakukan tim Luo Fuli adalah membagi KVCache menjadi dua kolam independen. 10 lapisan Full Attention menggunakan "kolam besar", dialokasikan berdasarkan panjang penuh; 60 lapisan SWA menggunakan "kolam kecil", dialokasikan hanya berdasarkan jendela 128 token.
Misalnya, awalnya perusahaan memberi setiap karyawan "lemari arsip yang bisa menampung dokumen 100 tahun" – tetapi 60 karyawan sebenarnya hanya membutuhkan "lemari kecil yang menampung dokumen satu minggu", 99% ruang di lemari besar itu kosong. Cara baru mengalokasikan lemari berdasarkan kebutuhan nyata. Hasilnya, seluruh kantor bisa menampung lebih dari 5 kali lipat kolega untuk bekerja – GPU yang sama dapat melayani jumlah pengguna bersamaan meningkat 5 kali lipat.
Langkah ini tampak sederhana, tetapi tanpanya, keunggulan desain arsitektur SWA sebelumnya sama saja tidak berguna.
Rekayasa Tiga: Memastikan "pembacaan ulang oleh pengguna lama" benar-benar mengenai cache
Buku catatan dikompresi menjadi 1/7 + ruang benar-benar dapat digunakan, langkah selanjutnya adalah menyelesaikan masalah lama: tingkat keberhasilan cache awalan.
Banyak percakapan pengguna memiliki awal yang sama – system prompt yang sama, basis kode yang sama, dokumen panjang yang sama. Sistem akan menyimpan hasil perhitungan ini, lain kali jika cocok langsung digunakan kembali. Mekanisme ini disebut cache awalan.
Namun, dalam mode SWA muncul sebuah masalah: dua permintaan token yang sama, tidak berarti KV masih ada. Mungkin awalan sudah dihitung, tetapi bagian di luar jendela SWA sudah lama dieliminasi. Jika sistem masih menggunakan aturan lama "token sama berarti berhasil" untuk digunakan kembali, akan membaca data yang tidak valid atau tertimpa, efek model akan langsung rusak.
Tim Luo Fuli meningkatkan aturan menjadi "panjang aman jendela" – hanya menjanjikan "bagian yang bisa Anda pinjam secara lengkap".
Misalnya, perpustakaan memiliki 1 juta buku, Anda ingin meminjam seri lengkap "Tiga Tubuh" yang terdiri dari tiga buku. Arsitektur lama akan memberi tahu "buku ini ada", Anda datang dan menemukan rak hanya berisi sampul dan buku pertama, dua buku berikutnya sudah dipinjam. "Keberhasilan palsu" ini membuat Anda datang sia-sia dan harus meminjam ulang. Aturan sistem baru hanya menjanjikan bagian yang bisa Anda pinjam secara lengkap – pertama memberi Anda buku pertama, lalu mengatur dua buku berikutnya untuk Anda.
Kedengarannya tampak lebih ketat, tingkat keberhasilan mungkin turun. Namun sebaliknya: karena SWA membuat volume KVCache terkompresi menjadi 1/7, ruang penyimpanan yang sama dapat menampung beberapa kali lipat lebih banyak konten, tingkat keberhasilan nyata justru meningkat secara signifikan.
Luo Fuli memberikan angka pengujian nyata daring dalam blog: Rata-rata tingkat keberhasilan cache sisi server dalam kerangka harness utama adalah 93%, pengguna siklus panjang frekuensi tinggi dapat mencapai di atas 95%.
Terjemahan dari angka ini: 95% permintaan "pembacaan ulang" sama sekali tidak perlu dihitung GPU, langsung diambil dari cache. Inilah dasar fisik dari diskon 99%.
Rekayasa Empat: Memasukkan "Cache" ke SSD Bawaan GPU
Tingkat keberhasilan meningkat, masalah selanjutnya: di mana cache ini disimpan.
Memori video (memori HBM pada GPU) sangat mahal dan terbatas – satu mesin H100 delapan kartu hanya memiliki 640GB memori video, tetapi KVCache yang perlu disimpan MiMo mungkin dalam skala puluhan TB. Oleh karena itu, harus berlapis: yang baru digunakan disimpan di memori video (L1), yang agak lama disimpan di memori CPU (L2), data dingin disimpan di cache terdistribusi (L3).
Sama seperti Anda mengelola uang. Uang tunai di dompet adalah memori video – langsung digunakan tetapi tidak bisa menyimpan banyak. Saldo kartu bank adalah memori CPU – mengambil sekali butuh 30 detik tetapi bisa menyimpan banyak. Deposito berjangka adalah cache terdistribusi L3 – mengambil sekali butuh 2 menit tetapi jauh lebih murah.
Praktik umum industri adalah membangun kluster penyimpanan terpisah untuk L3, mesin khusus, ruang server khusus, membayar sewa setiap bulan.
Cara yang dilakukan tim penyimpanan Xiaomi berbeda. Mereka mengembangkan sendiri cache terdistribusi bernama GCache, langsung diterapkan pada SSD bawaan mesin GPU – dideploy bersama tugas pelatihan dan tugas inferensi dalam mesin yang sama.
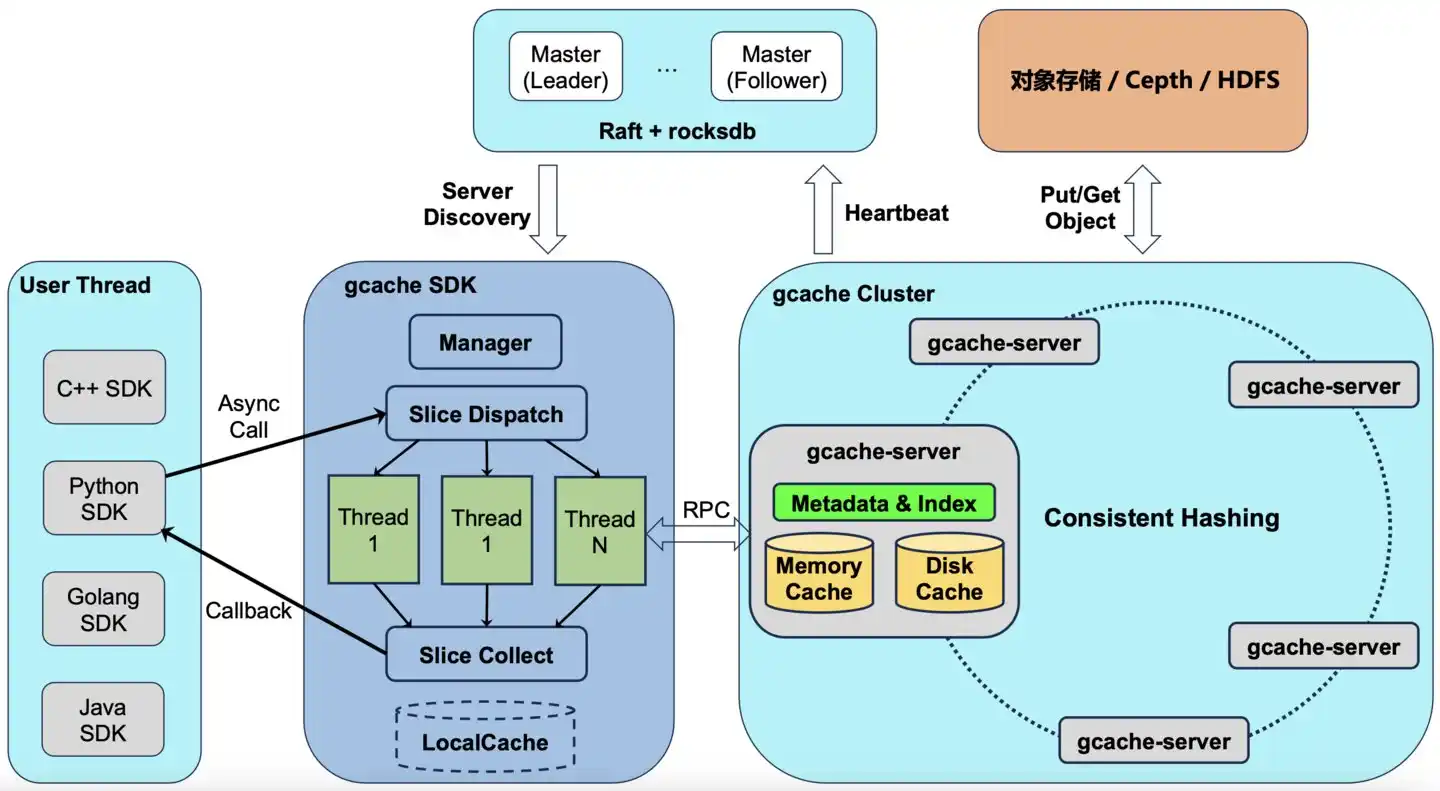
Terjemahan sederhana: orang lain menyewa gudang khusus untuk menyimpan data dalam jumlah besar; Xiaomi menemukan garasi mesin GPU sebenarnya kosong, langsung menyimpan data di dalamnya. Sewa bulanan dihemat.
Kata asli blog teknis adalah: "Biaya penyimpanan tambahan adalah 0."
Kekuatan hal ini lebih besar dari yang terlihat. Dalam "perhitungan daya komputasi perusahaan AI" konvensional, biaya penyimpanan adalah item pengeluaran tetap – semakin besar model Anda, semakin banyak pengguna, tagihan penyimpanan semakin panjang. Cara GCache ini langsung menghilangkan item ini. Digabungkan dengan volume kecil SWA + tingkat keberhasilan 93-95%, waktu hidup (TTL) KVCache di L3 diperpanjang dari beberapa menit menjadi beberapa jam bahkan beberapa hari – semakin panjang TTL, semakin luas jendela yang dapat berhasil untuk konteks historis, semakin tinggi tingkat keberhasilan cache, semakin kuat dasar diskon 99% tersebut.
Rekayasa Lima: Membuat Permintaan yang Mengenai Cache Menempuh Jalur Terpendek
Cache dapat disimpan, dapat diperiksa, dan murah, langkah terakhir adalah: bagaimana membuat permintaan yang benar dirutekan ke mesin yang benar.
Xiaomi mengembangkan sistem penjadwalan sendiri bernama LLM-Router, melakukan tiga hal:
Pertama, Penjadwalan Afinitas. Permintaan dengan awalan yang sama dirutekan ke mesin yang sama, memaksimalkan penggunaan kembali cache.
Kedua, Pengelompokan Panjang. Permintaan pendek (0-64K), menengah (64K-256K), dan panjang (256K-1M) dibagi ke saluran pemrosesan berbeda, menghindari permintaan pendek tertahan oleh permintaan panjang.
Ketiga, Optimasi TTFT. Dalam antrian yang menunggu inferensi, memprioritaskan penjadwalan permintaan dengan volume komputasi nyata kecil (yaitu permintaan yang banyak mengenai cache) – menghindari mereka diblokir oleh permintaan "input baru" yang berat secara komputasi.
Misalnya, dalam penjadwalan bandara konvensional, semua penumpang dengan tujuan yang sama dikumpulkan di ruang tunggu yang sama, berbagi proses pengambilan bagasi – ini adalah penjadwalan afinitas. Yang membawa tas kabin dan yang membawa 3 koper besar dengan bagasi tercatat berjalan di dua jalur keamanan terpisah, yang cepat tidak tertahan oleh yang lambat – ini adalah pengelompokan panjang. Saat naik pesawat, memprioritaskan penumpang yang hanya membawa tas kabin, mereka cepat naik, memungkinkan pesawat lepas landas lebih awal – ini adalah optimasi TTFT.
Strategi penjadwalan ini dalam pengujian nyata meningkatkan tingkat keberhasilan cache L2 sebesar 25%, throughput input per mesin meningkat 30%, penundaan P90 permintaan panjang berkurang 30%.
Terjemahannya adalah: GPU yang sama dapat melayani lebih banyak pengguna. Setengah logika lain dari diskon berada di sini – keluaran efektif daya komputasi per unit lebih tinggi, biaya per pengguna per unit lebih rendah.
Rekayasa Enam: Membuat Model "Mengetik" Juga Lebih Cepat
Lima hal sebelumnya mengoptimalkan sisi "baca" – membuat biaya pembacaan ulang konteks historis oleh pengguna mendekati 0. Hal keenam adalah mengoptimalkan sisi "tulis" – yaitu proses model menghasilkan token berikutnya.
Model tradisional hanya dapat menghasilkan 1 token sekaligus. MiMo mendukung asli 3 lapisan MTP (Multi-Token Prediction) – memprediksi 3 token berikutnya sekaligus, jika prediksi di tengah benar, langsung melewati perhitungan tengah.
Misalnya, mengetik tradisional adalah mengetik satu kata demi satu kata – Anda ingin mengetik "cuaca hari ini", harus menekan 4 kali. MTP seperti memiliki pelengkapan otomatis yang menebak 1-2 kata berikutnya Anda – jika tebakan benar, Anda tidak perlu menekan dua kali itu.
MTP MiMo dalam pengujian nyata skenario agen: percepatan decode 128 token pertama 2.3 kali lipat, token 128-256 percepatan 1.5 kali lipat.
Makna hal ini adalah, diskon 99% khusus mengacu pada Input (Cache Hit), tetapi saat model melayani pengguna sebenarnya, input dan output terjadi dalam permintaan yang sama – jika output tidak dihemat, biaya permintaan keseluruhan hanya dihemat setengah. MTP membuat setengah output juga turun, model profitabilitas diskon keseluruhan baru menjadi tertutup.
Menyambung enam hal menjadi rantai penghematan biaya:
Arsitektur SWA → KVCache 1/7 → Kolam ganda benar-benar melepaskan kapasitas → GPU yang sama dapat menampung 5+ kali lipat konkurensi → Tingkat keberhasilan cache awalan 93-95% → 95% permintaan hampir tidak perlu dihitung → GCache membuat biaya penyimpanan menjadi nol → Penjadwalan memprioritaskan permintaan yang berhasil → MTP membuat pembuatan juga hemat → Waktu GPU per permintaan turun satu orde magnitudo → Biaya per unit turun 95%+ → Harga turun 99%, margin kotor masih positif.
Kehilangan satu bagian, rantai ini putus di suatu bagian. Diskon 99% bukan angka pemasaran, adalah efek kumulatif dari enam pilar rekayasa ditumpuk + verifikasi nyata daring.
Melihat kembali beberapa interpretasi awal industri, masing-masing memiliki sebagian kebenaran. Perang harga antara perusahaan model besar China dalam dua tahun ini nyata; laba Xiaomi turun separuh dan masih berinvestasi besar di AI nyata; DeepSeek menyeret harga industri ke lantai dasar juga nyata.
Namun, Luo Fuli kali ini mempublikasikan blog teknis dan membongkar detail teknis secara rinci, tanpa diragukan berharap membalas pernyataan tentang perang harga, membuat "masalah teknis dikembalikan ke ranah teknis, masalah pemasaran dikembalikan ke ranah pemasaran."
Dia menulis dalam blog, efisiensi inferensi seri model MiMo-V2.5 bukan berasal dari terobosan satu titik di satu tautan, tetapi hasil optimasi kolaboratif multidimensi. Hybrid SWA menguntungkan prefill dan decode secara bersamaan, tetapi implementasi KVCache yang tidak dioptimalkan penuh justru akan meningkatkan biaya di setiap tautan. Berdasarkan target ini, tim MiMo secara sistematis merekonstruksi manajemen KVCache, cache berlapis, pohon cache awalan, mengatasi masalah inti SWA KVCache, mengoptimalkan strategi penjadwalan dan tautan Prefill / Decode, dan melalui pemeriksaan skenario nyata daring, akhirnya mewujudkan keunggulan efisiensi teoritisnya ke lingkungan produksi. Hingga saat ini, Hybrid SWA baru mengeluarkan keunggulan arsitektur yang kuat dan efisien dalam inferensi teks panjang. Ditambah dengan konfigurasi MoE dan berbagai optimasi inferensi multimodal, secara signifikan meningkatkan kinerja layanan inferensi daring.
Ini adalah pendekatan sistematis rekayasa AI, dan juga sarana penghematan biaya yang patut dijadikan referensi bersama oleh industri.
Perang harga tidak perlu menulis blog, mewujudkan rekayasa yang perlu.





