Editor's Note: Laporan ini didasarkan pada analisis sekitar 400.000 sesi Claude Code, membahas bagaimana alat pemrograman AI mengubah hubungan antara manusia dan kode.
Temuan inti artikel adalah: Dalam pemrograman agen, manusia terutama memutuskan "apa yang harus dilakukan", sedangkan Claude bertanggung jawab atas "bagaimana melakukannya". Pengguna menanggung sebagian besar keputusan perencanaan, sementara Claude menanggung sebagian besar pekerjaan pelaksanaan. Dengan kata lain, AI sedang mengambil alih tahapan implementasi seperti menulis kode, mengubah file, menjalankan perintah, debugging, tetapi penetapan tujuan dan penilaian hasil masih bergantung pada manusia.
Yang lebih penting, efektivitas penggunaan Claude Code tidak hanya bergantung pada apakah pengguna adalah seorang programmer. Laporan menunjukkan bahwa dalam tugas-tugas yang menghasilkan kode, tingkat keberhasilan pengguna dari profesi non-teknis seperti hukum, keuangan, manajemen, dan penelitian ilmiah sudah mendekati tingkat keberhasilan insinyur perangkat lunak. Yang benar-benar memengaruhi hasil adalah apakah pengguna memahami masalah yang ingin diselesaikan.
Ini berarti, pemrograman AI menurunkan hambatan implementasi, bukan hambatan penilaian. Di masa depan, orang yang memahami bisnis, memahami konteks, dan dapat mengajukan kebutuhan serta menilai hasil dengan jelas, mungkin akan lebih mampu menggunakan AI dengan baik dibandingkan orang yang hanya pandai menulis kode. AI tidak akan secara otomatis menggantikan pengetahuan domain, justru akan memperbesar nilai pengetahuan domain.
Berikut adalah teks aslinya:
Temuan Kunci
Berdasarkan penelitian sebelumnya, kami mengusulkan sebuah kerangka kerja untuk mempelajari pemrograman agen interaktif. Kerangka kerja ini didasarkan pada analisis perlindungan privasi terhadap sekitar 400.000 sesi Claude Code dari Oktober 2025 hingga April 2026, mengevaluasi komposisi tugas, cara kolaborasi manusia dengan AI, serta tingkat keberhasilan tugas.
Dalam satu sesi khas, manusia bertanggung jawab atas sebagian besar keputusan perencanaan, yaitu memutuskan "apa yang harus dilakukan"; Claude bertanggung jawab atas sebagian besar keputusan eksekusi, yaitu memutuskan "bagaimana menyelesaikannya". Semakin kuat keahlian domain pengguna di suatu bidang, semakin besar volume pekerjaan yang diselesaikan Claude per instruksi yang dipicu. Dalam tugas pengkodean, tingkat keberhasilan rata-rata di antara kelompok-kelompok profesi utama—yaitu apakah menyelesaikan apa yang semula ingin dilakukan pengguna, dan memiliki bukti yang dapat diverifikasi seperti pengujian yang lolos, pengiriman kode—hampir setara dengan insinyur perangkat lunak.
Semakin kuat kemampuan keahlian domain pengguna, semakin besar kemungkinan sesi berakhir dengan sukses. Namun, jarak antara pengguna tingkat menengah dan ahli tidak terlalu besar. Selama tujuh bulan yang kami amati, proporsi sesi yang digunakan untuk debugging turun hampir setengahnya, dan pola penggunaan bergeser ke penggunaan agen yang lebih end-to-end: menerapkan dan menjalankan kode, menganalisis data, serta menulis dokumen non-kode.
Selama tujuh bulan ini, nilai tugas khas meningkat di hampir semua jenis pekerjaan. Kami memperkirakan nilai tugas dengan membandingkannya dengan informasi posting pekerjaan lepas, dan hasilnya menunjukkan peningkatan rata-rata sekitar 25%.
Pendahuluan
Pemrograman agen sedang berkembang pesat. Sejak akhir 2025, proporsi aktivitas agen pengkodean di proyek GitHub telah meningkat lebih dari dua kali lipat, dan pengguna Claude Code sekarang rata-rata menggunakan alat tersebut 20 jam per minggu. Bisakah orang tanpa pengalaman pemrograman formal berhasil memerintahkan sebuah agen untuk menyelesaikan pekerjaan teknis yang kompleks? Bagaimana adopsi cepat dan peningkatan kemampuan alat-alat ini akan memengaruhi kerja pengetahuan yang lebih luas? Saat ini kami belum dapat memberikan jawaban lengkap, tetapi kami dapat melihat beberapa sinyal awal dari data penggunaan Claude Code.
Laporan ini, berdasarkan analisis perlindungan privasi terhadap sekitar 400.000 sesi interaktif yang melibatkan sekitar 235.000 pengguna dari Oktober 2025 hingga April 2026, memberikan bukti tentang cara aktual penggunaan Claude Code. Ini merupakan kelanjutan dari penelitian kami sebelumnya tentang metrik otonomi dalam sesi Claude Code, serta bagaimana Claude Code mengubah pekerjaan internal di Anthropic. Artikel ini akan mengusulkan kerangka kerja untuk menggambarkan penggunaan asisten pemrograman AI interaktif: pekerjaan apa yang dilakukan orang, siapa yang melakukan pekerjaan itu, dan apakah pekerjaan itu berhasil. Fokus kami adalah pada penggunaan Claude Code melalui antarmuka baris perintah (CLI), Claude.ai, atau aplikasi desktop Claude Code. Dengan melacak bagaimana cara penggunaan pemrograman agen berubah seiring peningkatan kemampuan model, kami dapat lebih memahami dampak alat-alat ini terhadap para profesional pemrograman dan pasar tenaga kerja pekerja pengetahuan.
Apa yang terjadi di Claude Code mungkin menandakan arah masa depan pekerjaan pengetahuan: agen akan secara bertahap tertanam dalam pekerjaan non-pengkodean. Kami menemukan bahwa Claude sedang menangani tugas-tugas yang lebih kompleks dan bernilai lebih tinggi. Pada saat yang sama, masih ada pembagian kerja yang jelas dalam pemrograman agen: manusia memutuskan apa yang akan dibangun, agen memutuskan bagaimana membangunnya.
Kami juga melihat bukti bahwa yang benar-benar memperbesar efektivitas alat adalah keahlian domain, bukan kemahiran pemrograman. Khususnya, ahli domain lebih mudah berhasil, dan lebih mudah pulih dari kesalahan dan kesalahpahaman. Namun, jarak antara ahli dan pengguna menengah tidak terlalu besar. Ini menunjukkan bahwa cukup memiliki kemahiran yang memadai di suatu domain untuk hampir sama efektifnya menggunakan alat semacam ini seperti ahli yang mendalam.
Temuan-temuan ini memungkinkan kami untuk melakukan pengamatan awal terhadap kemungkinan pergeseran pasar tenaga kerja. Dalam data kami, keberhasilan bergantung pada apakah seseorang memahami masalah yang ingin dipecahkan, bukan pada apakah ia pernah dilatih pemrograman. Jika pola-pola ini terbukti di seluruh sistem ekonomi, maka hal ini menunjukkan bahwa alat pemrograman agen mungkin sedang menyerap sebagian pekerjaan yang bersifat implementasi, tetapi pada saat yang sama juga memberikan penghargaan kepada mereka yang benar-benar memahami masalah yang dipecahkan dalam pekerjaan mereka. Agen pengkodean tidak sedang menggantikan keahlian domain. Sebaliknya, semakin banyak pemahaman yang dibawa seorang pekerja ke agen, semakin banyak pekerjaan berkualitas tinggi yang dapat diselesaikan agen tersebut.
Pembagian Kerja
Apa yang Dilakukan Orang dengan Claude Code
Untuk memahami bagaimana orang menggunakan Claude Code, kami mengategorikan setiap sesi ke dalam salah satu dari sembilan mode kerja, yaitu satu aktivitas tunggal yang paling menggambarkan tujuan sesi tersebut. Empat mode di antaranya secara langsung melibatkan penulisan atau pemeliharaan kode: membangun sesuatu yang baru, memperbaiki sesuatu yang rusak, menguji kode, dan mengatur agen lain atau alur otomatisasi. Kategori lain adalah mengoperasikan perangkat lunak, termasuk penerapan, konfigurasi, menjalankan alur kerja, dan memantau sistem. Dua kategori lainnya lebih condong pada mencari tahu "apa yang harus dilakukan": memahami bagaimana sistem yang ada beroperasi, serta merencanakan perubahan sebelum melakukan modifikasi. Dua kategori terakhir tidak terkait dengan kode, atau kode hanya merupakan bagian pendukung dalam produk akhir: menganalisis data, serta berkomunikasi melalui presentasi dan dokumen berbasis teks lainnya.
Sekitar 56% sesi terdiri dari menulis kode (25%), memperbaiki kode (26%), atau menguji dan mengatur kode (5%). Mengoperasikan perangkat lunak menyumbang 17%, perencanaan atau eksplorasi 14%, analisis atau penulisan teks 13% (lihat Gambar 1).
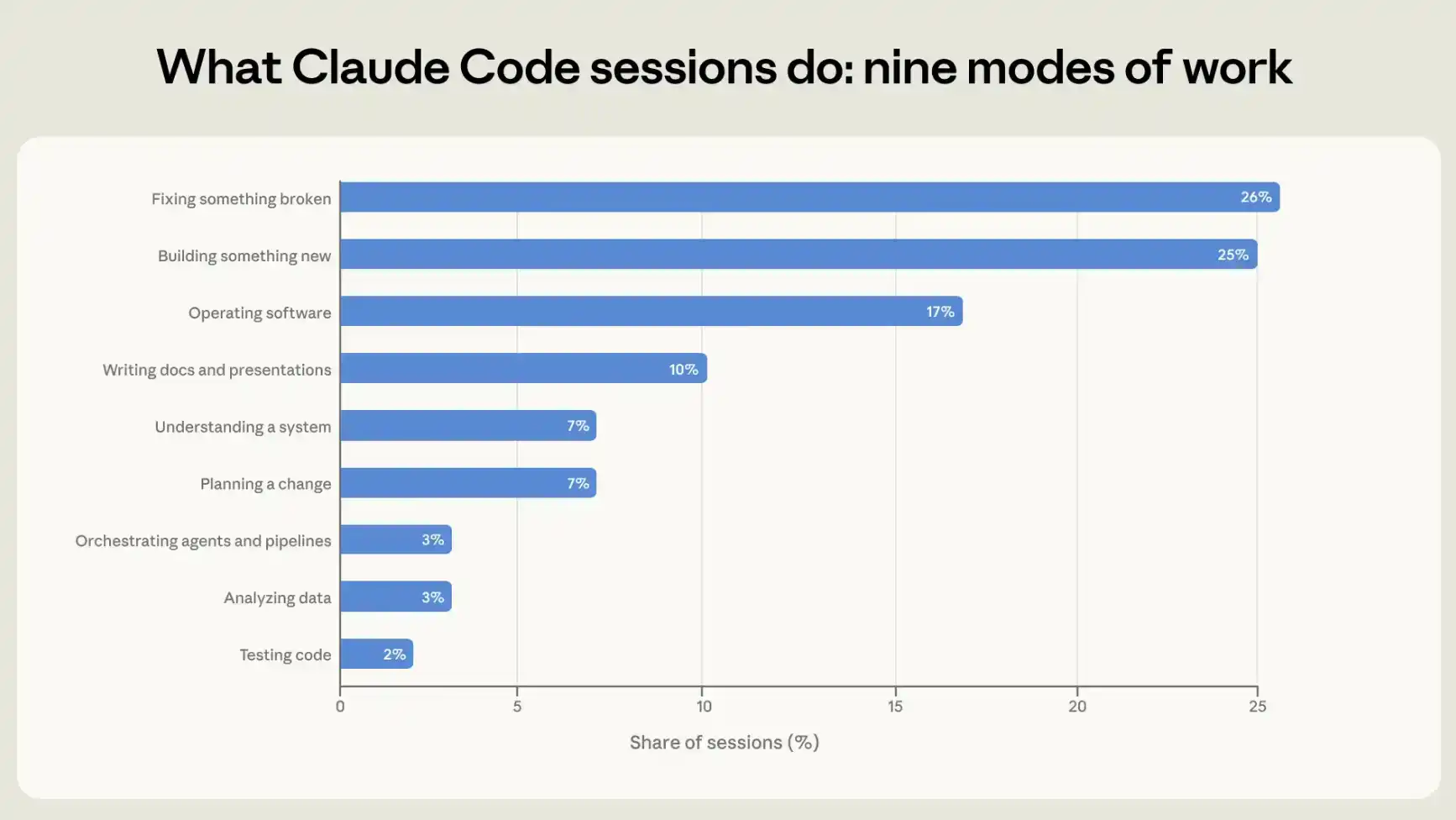
Pertama-tama kami meminta model membaca catatan sesi dan mengklasifikasikan setiap sesi berdasarkan itu; kemudian kami menggunakan alat analisis perlindungan privasi kami untuk memvalidasi silang hasil klasifikasi dengan data telemetri yang direkam secara otomatis untuk setiap sesi, termasuk apakah ada baris kode yang baru ditambahkan atau dihapus. Ada konsistensi tinggi antara kedua sumber tersebut. Misalnya, dalam sesi yang ditandai oleh pengklasifikasi kami sebagai membuat atau memodifikasi kode, lebih dari 90% juga menunjukkan perubahan kode dalam data telemetri. Detailnya lihat Lampiran.
Siapa yang Mengambil Keputusan
Seberapa otonomkah Claude Code? Penilaian kemampuan menunjukkan bahwa batas atasnya sudah tinggi, dan masih meningkat. Misalnya, dalam pengujian patokan seperti evaluasi rentang waktu METR, model mutakhir sekarang dapat secara otonom menyelesaikan tugas perangkat lunak yang sebelumnya membutuhkan waktu berjam-jam bagi manusia, dan mengatasi hambatan sendiri dalam prosesnya. Namun dalam penggunaan nyata, bagaimana sebenarnya keadaannya? Di sini, kami memfokuskan pada seberapa banyak pekerjaan pengarahan yang dilakukan manusia dan Claude masing-masing dalam sesi nyata.
Kami meneliti masalah ini dari dua sudut pandang. Pertama, kami memperhatikan sejauh mana orang menyerahkan keputusan kepada Claude; kedua, kami mengamati seberapa banyak tindakan yang mereka delegasikan kepada Claude. Untuk memahami pembagian keputusan dalam suatu sesi, kami membangun pengklasifikasi atribusi keputusan yang melindungi privasi berdasarkan konten sesi. Kami meminta pengklasifikasi untuk membuat daftar semua keputusan yang bermakna dalam sesi, dan membagi keputusan-keputusan ini menjadi keputusan perencanaan dan keputusan eksekusi. Keputusan perencanaan mencakup apa yang harus dilakukan, metode mana yang akan digunakan, apa yang dianggap selesai; keputusan eksekusi mencakup file mana yang akan dimodifikasi, kode apa yang akan ditulis, bahasa apa yang akan digunakan, serta perintah mana yang akan dijalankan. Selanjutnya, pengklasifikasi akan mengaitkan setiap keputusan kepada Claude atau pengguna, dan menghasilkan dua angka untuk setiap sesi: persentase keputusan perencanaan yang diambil pengguna, dan persentase keputusan eksekusi yang diambil pengguna.
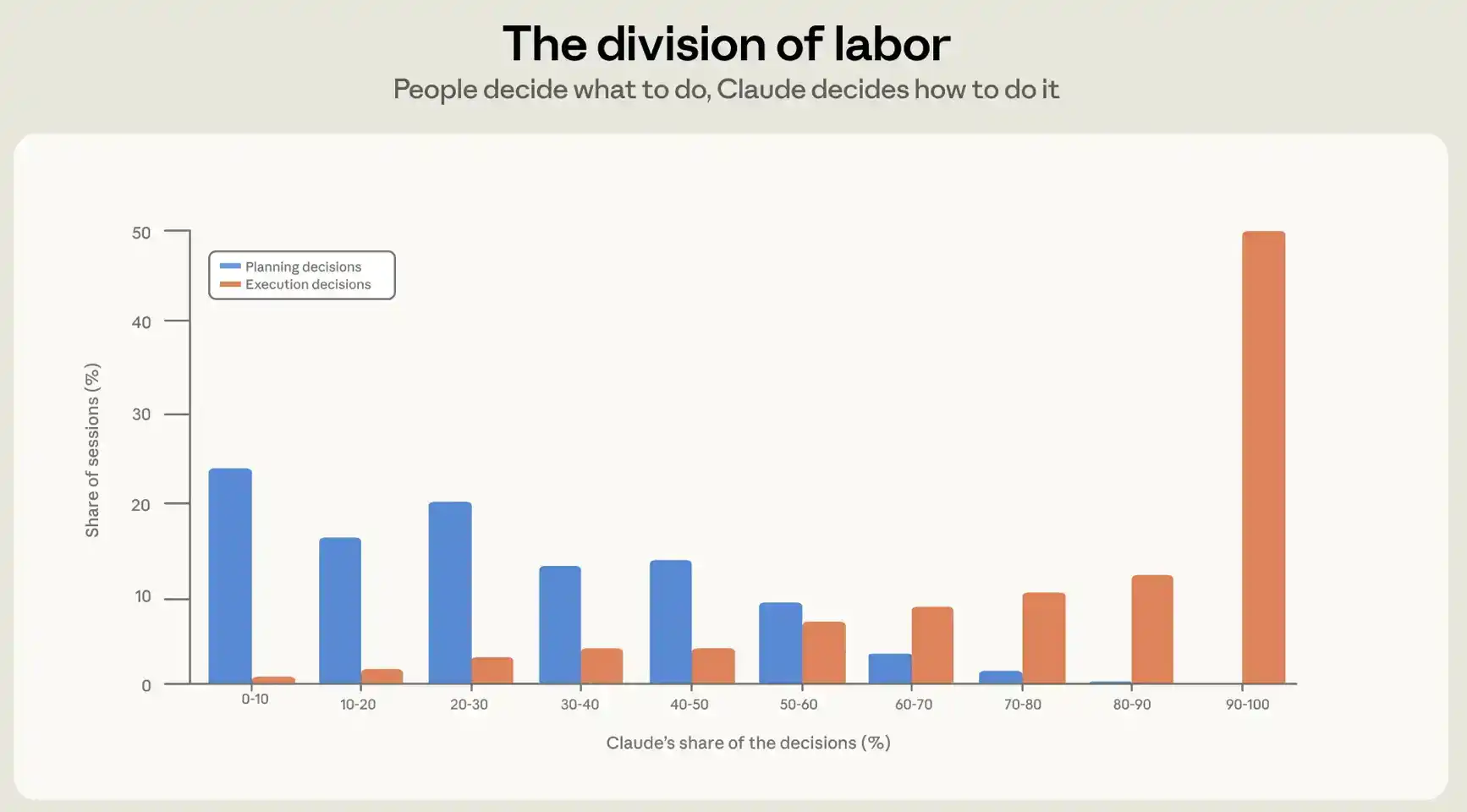
Rata-rata, manusia membuat sekitar 70% keputusan perencanaan, tetapi hanya membuat 20% keputusan eksekusi (lihat Gambar 2). Dalam penggunaan nyata, pemrograman agen membentuk pembagian kerja yang jelas: manusia memutuskan apa yang akan dibangun, agen memutuskan bagaimana membangunnya.
Untuk memahami tingkat pendelegasian tindakan dalam suatu sesi, kami tidak melihat konten, melainkan struktur sesi. Sesi Claude Code terdiri dari interaksi bolak-balik antara Claude dan pengguna: pengguna mengirim prompt, Claude menjalankan tindakan; kemudian pengguna mengirim prompt berikutnya, dan seterusnya. Dalam sesi khas, terdapat sekitar empat putaran seperti ini. Dalam data historis kami dari Oktober hingga April, setiap prompt yang dikirim pengguna rata-rata memicu Claude untuk menjalankan sekitar 10 tindakan, terkadang bahkan lebih dari 100 tindakan. Dalam setiap putaran, Claude membaca file, mengedit kode, menjalankan perintah, dan rata-rata menghasilkan 2400 kata.
Seberapa banyak pekerjaan yang diselesaikan Claude di antara pemeriksaan pengguna sangat bergantung pada siapa yang mengambil keputusan. Ketika pengguna mempertahankan kendali atas proses eksekusi, yaitu ketika pengguna membuat lebih dari 80% keputusan eksekusi, Claude menjalankan lebih sedikit tindakan per putaran, sekitar 8 tindakan. Namun, ketika Claude memegang kendali perencanaan, yaitu ketika Claude membuat lebih dari 80% keputusan perencanaan, jumlah tindakan yang diambilnya paling tinggi, sekitar 16 tindakan.
Tingkat Keahlian
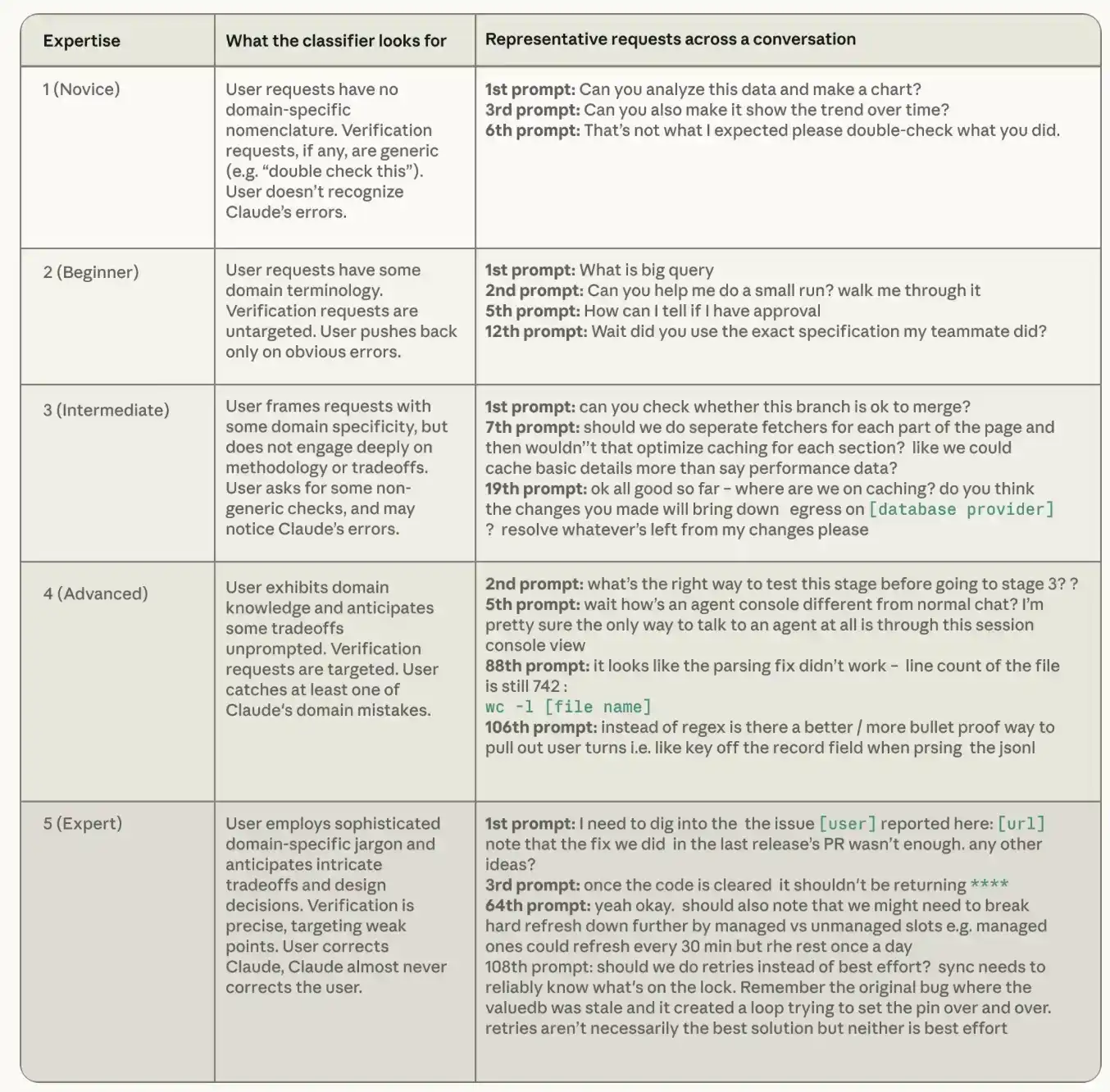
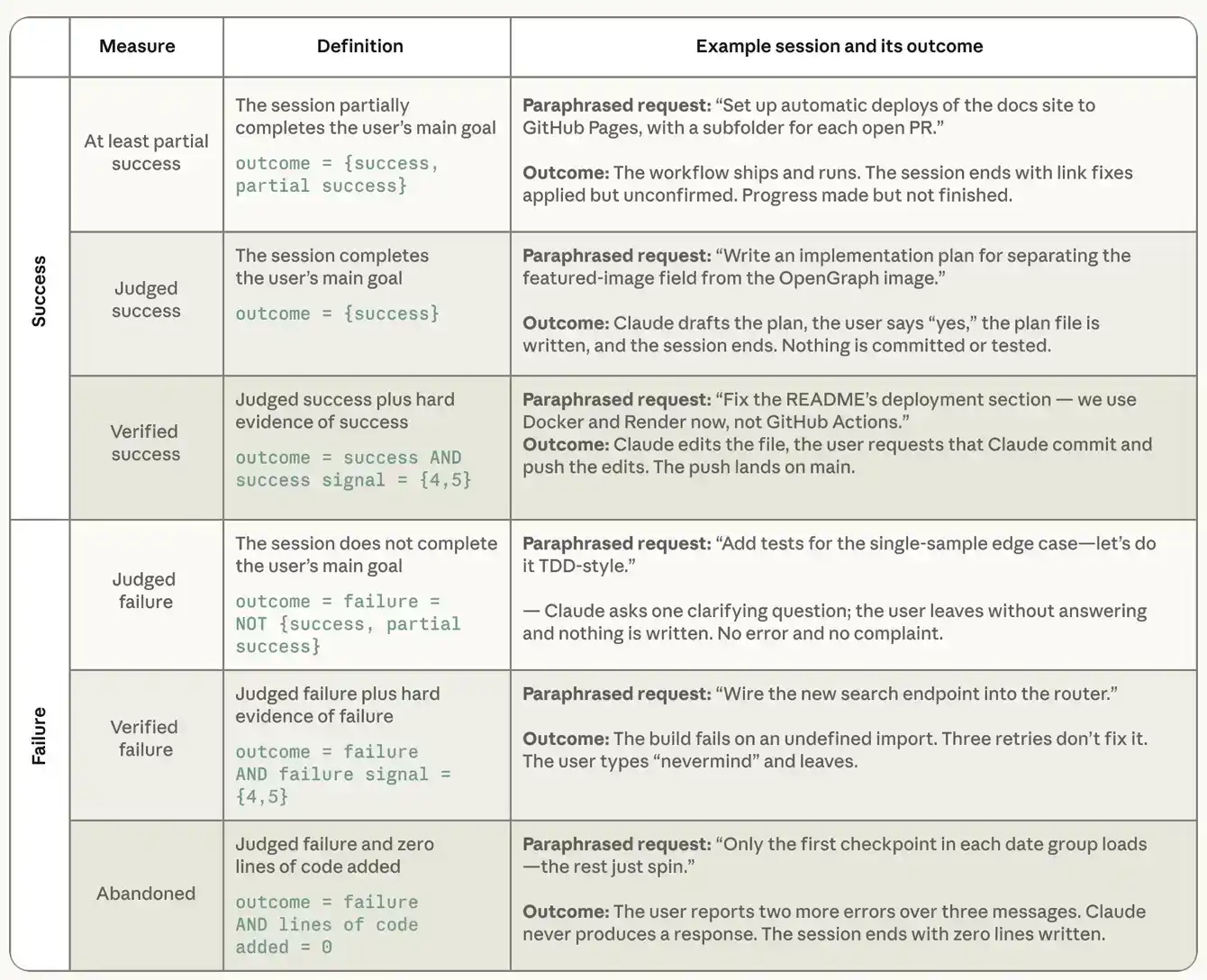
Berdasarkan setiap catatan sesi, Claude akan menilai tingkat keahlian tampak pengguna pada tugas tersebut menggunakan skala lima tingkat, dari pemula hingga ahli. Pengklasifikasi tingkat keahlian memfokuskan pada tiga sinyal: seberapa tepat instruksi yang diberikan pengguna, apa yang diminta pengguna untuk divalidasi Claude, serta apakah pengguna yang lebih sering mengoreksi Claude, atau Claude yang lebih sering mengoreksi pengguna. Perlu diperhatikan bahwa tingkat keahlian di sini adalah konsep yang sepenuhnya berbeda dari jabatan atau kemampuan umum, dan yang terpenting, ini adalah spesifik tugas. Seorang insinyur senior yang pertama kali bertanya tentang Rust, mungkin masih menjadi pemula dalam tugas Rust. Seorang akuntan yang belum pernah menggunakan Python, jika dapat secara akurat memberi tahu Claude aturan rekonsiliasi apa yang harus dilakukan oleh skrip Python tertentu, dan dapat menangkap kasus tepi yang salah ditangani pada penutupan bulan, maka dia adalah ahli dalam tugas tersebut.
Tabel berikut menunjukkan bagaimana kami mendefinisikan setiap tingkat keahlian dalam pengklasifikasi, dan memberikan contoh permintaan dari kumpulan data sesi agen pengkodean publik SWE-chat. Percakapan yang dikategorikan sebagai "Pemula" memberikan instruksi umum yang tidak mencerminkan pengetahuan domain tertentu; percakapan yang dikategorikan sebagai "Ahli" menyampaikan pemahaman mendalam tentang basis kode dan lingkungan teknis.
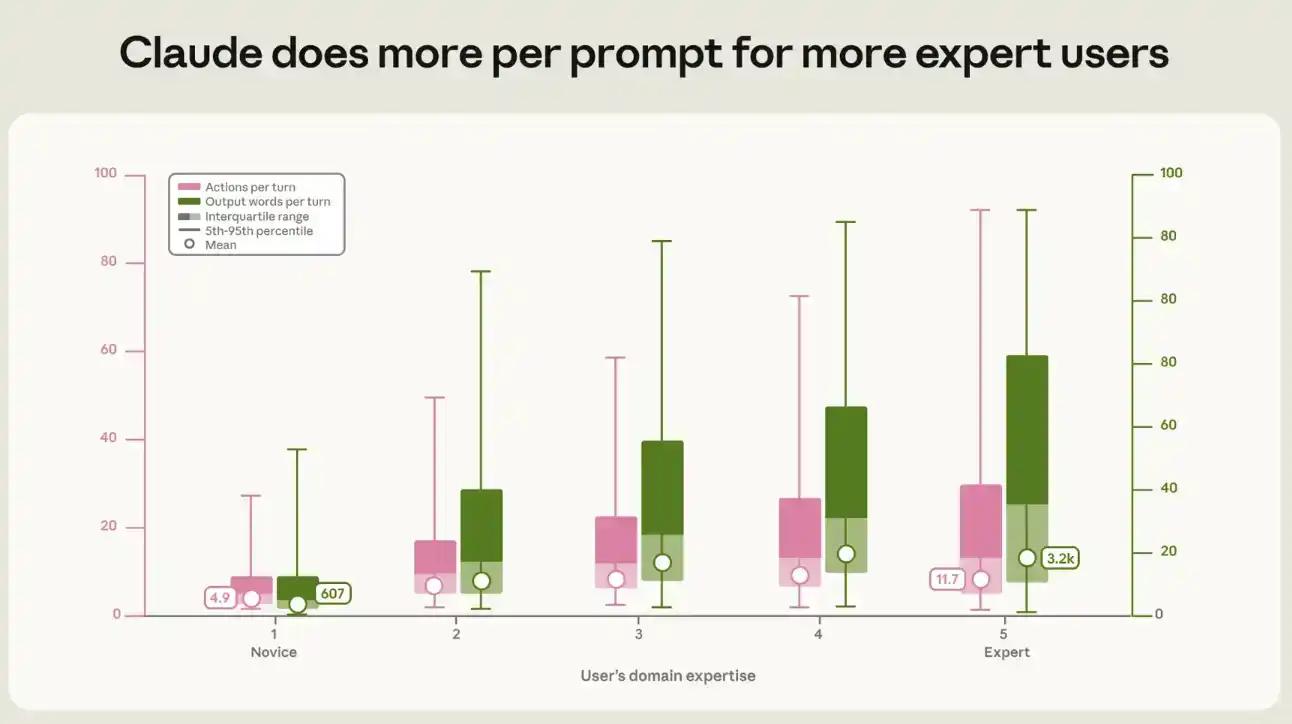
Kami mengukur hubungan antara tingkat keahlian dengan volume output dan aktivitas yang dihasilkan per prompt Claude. Dalam sesi pemula khas, setiap prompt memicu Claude untuk menjalankan sekitar 5 tindakan, dan menghasilkan sekitar 600 kata; sedangkan dalam sesi ahli, rantai tindakan lebih dari dua kali lipatnya, sekitar 12 tindakan, dan output mencapai sekitar 3200 kata, lima kali lipat lebih banyak (lihat Gambar 3). Kesenjangan antara pemula dan ahli ini muncul di setiap jenis pekerjaan dan setiap rentang nilai tugas.
Metrik-metrik ini melengkapi penelitian kami sebelumnya tentang otonomi Claude Code. Penelitian sebelumnya melacak durasi berjalan agen, dan seberapa sering pengguna menyetujui tindakannya secara otomatis. Sebaliknya, metrik atribusi keputusan kami menangkap siapa yang membuat keputusan substantif dalam seluruh sesi, sementara jumlah output dan tindakan yang dipicu per prompt mengukur sejauh mana aktivitas otonom yang dapat dipicu Claude per instruksi manusia.
Siapa yang Menggunakan Claude Code, dan Untuk Apa Mereka Menggunakannya
Pengguna
Untuk memahami siapa yang melakukan pekerjaan ini, kami menyimpulkan profesi setiap pengguna berdasarkan catatan sesi, dan memetakannya ke salah satu dari 23 kategori utama dalam sistem Klasifikasi Pekerjaan Standar (SOC) Biro Statistik Tenaga Kerja AS. Pengklasifikasi diminta untuk hanya menilai berdasarkan sinyal-sinyal berikut: konteks proyek yang dimuat agen di awal sesi, nama dan struktur file, referensi atau produk yang dikutip pengguna, misalnya dokumen hukum, data klinis, laporan keuangan, materi kursus, dll., serta kosakata yang digunakan pengguna. Pengklasifikasi secara eksplisit diminta untuk tidak menganggap "sedang menulis kode" itu sendiri sebagai bukti bahwa pengguna berprofesi pemrograman. Hanya jika ada sinyal jelas yang menunjukkan bahwa pekerjaan perangkat lunak atau data adalah profesi pengguna, sesi akan dikategorikan ke dalam kategori SOC terkait pengkodean, yaitu "Pekerjaan Komputer dan Matematika". Jika seorang pengacara membangun skrip untuk secara otomatis memeriksa apakah sekumpulan kontrak kehilangan klausul tertentu, maka meskipun sesi ini sebagian besar menulis perangkat lunak, ia tetap akan dikategorikan ke dalam profesi hukum. Jika tidak ada sinyal tentang profesi pengguna, sesi tersebut tidak diklasifikasikan.
Kami dapat menyimpulkan profesi di sekitar 70% sesi. Dalam sesi yang dapat dikategorikan ini, "Pekerjaan Komputer dan Matematika" adalah kelompok terbesar, yang tidak mengherankan karena kategori ini mencakup sebagian besar pekerjaan terkait perangkat lunak. Diikuti oleh Operasi Bisnis dan Keuangan, Seni Desain dan Media, Manajemen, serta Ilmu Kehidupan, Ilmu Fisika, dan Ilmu Sosial. Dalam sampel kami, kelompok profesi non-perangkat lunak dengan pertumbuhan tercepat adalah Manajemen, Penjualan, dan profesi Hukum.
Pekerjaan
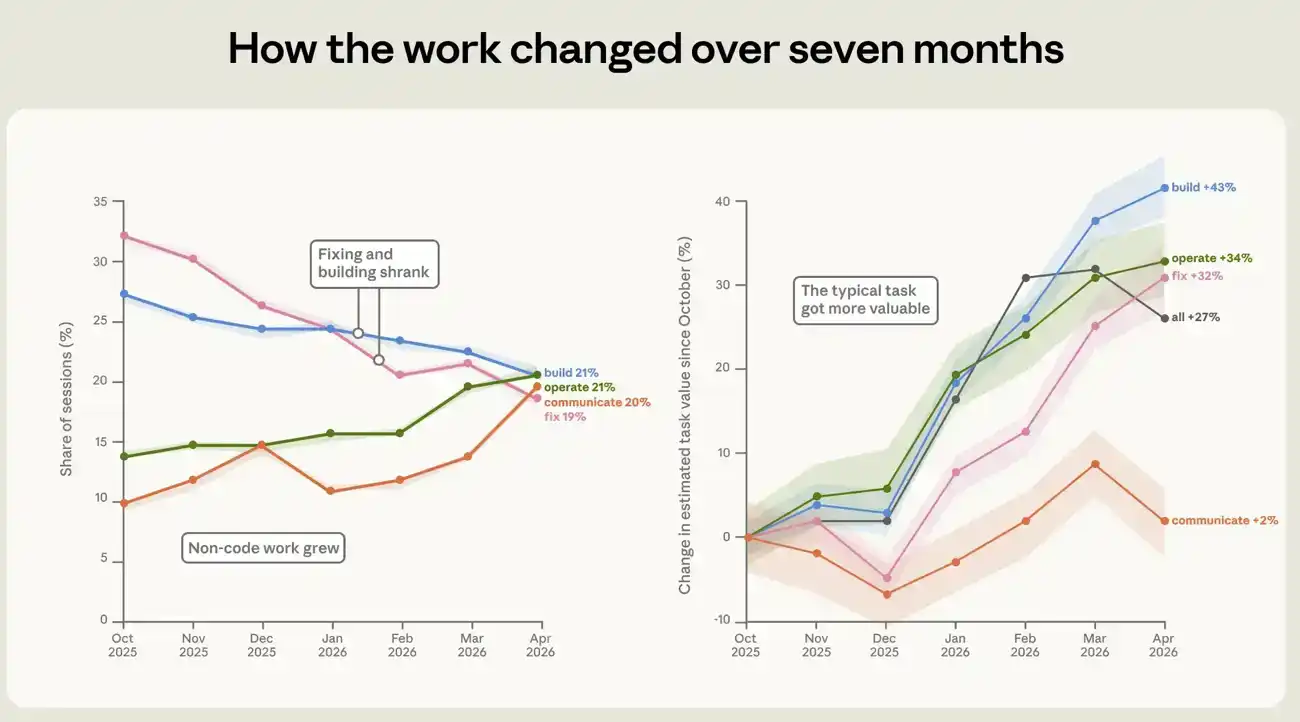
Dari Oktober 2025 hingga April 2026, komposisi pekerjaan yang diselesaikan orang menggunakan Claude Code berubah secara signifikan. Perubahan paling mencolok adalah proporsi sesi yang digunakan untuk memperbaiki kode rusak turun dari 33% menjadi 19% (lihat Gambar 4). Sebagai gantinya, ada lebih banyak pekerjaan yang berpusat pada kode. Proporsi pengoperasian perangkat lunak naik dari 14% menjadi 21%. Penulisan dan analisis data meningkat hampir dua kali lipat, dari sekitar 10% menjadi sekitar 20%.
Nilai tugas itu sendiri juga meningkat. Kami memperkirakan nilai ekonomi setiap sesi dengan memperkirakan biaya pekerjaan serupa di pasar pekerja lepas, dan mengkalibrasinya menggunakan kumpulan data pekerjaan nyata yang dipublikasikan. Menurut metrik ini, nilai perkiraan rata-rata sesi meningkat 27% selama periode Oktober hingga April. Peningkatan ini muncul di berbagai jenis pekerjaan. Nilai tugas membangun, mengoperasikan, dan memperbaiki masing-masing meningkat sekitar 43%, 34%, dan 32%. Perkiraan harga ini relatif kasar, jadi kami terutama menggunakannya untuk membandingkan tren seiring waktu antara tugas yang berbeda, bukan sebagai nilai dolar yang dapat langsung dibaca. Detail tentang cara membangun estimator nilai tugas, lihat Lampiran.
Keberhasilan Bergantung pada Apa yang Dibawa Pengguna
Memperkirakan nilai tugas adalah salah satu cara untuk memahami bagaimana Claude Code membantu orang menyelesaikan pekerjaan. Sudut pandang lain adalah mengamati berapa banyak sesi yang berhasil, dan karakteristik sesi apa yang terkait dengan keberhasilan. Dalam semua metrik keberhasilan, kami melihat pola yang jelas: semakin tinggi tingkat keahlian yang ditampilkan pengguna dalam sesi, semakin besar kemungkinan sesi itu berhasil. Sebagian besar peningkatan terkonsentrasi di tingkat keahlian yang lebih rendah, artinya, kesenjangan dari pemula ke pengguna menengah lebih besar daripada dari pengguna menengah ke ahli.
Sebelum menganalisis karakteristik sesi yang berhasil, kami perlu menjelaskan secara akurat bagaimana mengukur keberhasilan. Kami tidak dapat mengamati hasil dunia nyata pengguna, atau secara langsung menanyakan apakah mereka menyelesaikan apa yang ingin mereka lakukan melalui Claude. Oleh karena itu, kami mengandalkan dua metode pengukuran komplementer berbasis catatan sesi. Yang pertama adalah "Keberhasilan yang Dinilai", di mana pengklasifikasi membaca catatan sesi lengkap dan menilai apakah pengguna menyelesaikan tujuan yang semula mereka tetapkan, dengan opsi termasuk berhasil, sebagian berhasil, gagal, tidak ada tujuan jelas. Selanjutnya, dua pengklasifikasi pendamping akan menilai kekuatan bukti penilaian tersebut untuk menentukan "Keberhasilan yang Diverifikasi". Pengklasifikasi sinyal keberhasilan akan mencari bukti keberhasilan yang dapat diverifikasi, terutama termasuk aktivitas git yang sesuai dengan pekerjaan tersebut, misalnya commit dan pull request, rangkaian pengujian yang lolos, serta pengakuan eksplisit dari pengguna. Ini akan memberi nilai sesi pada skala dari "Tidak ada sinyal" hingga "Sinyal Lemah" (1 poin) hingga "Beberapa Sinyal Kuat" (5 poin). Pengklasifikasi sinyal kegagalan paralel lainnya akan memberi nilai pada bukti bahwa sesuatu tidak beres, termasuk kesalahan, pengujian gagal, upaya berulang untuk hal yang sama, serta keberatan pengguna terhadap output, dll. Keberhasilan yang Diverifikasi mensyaratkan dua kondisi sekaligus: sesi dinilai berhasil, dan setidaknya ada satu sinyal keberhasilan kuat yang dapat diverifikasi. Analisis berikut berfokus pada tingkat keberhasilan atau kegagalan dalam sesi, jadi kami mengecualikan sesi yang dinilai oleh pengklasifikasi hasil keberhasilan sebagai "Tidak ada tujuan jelas", yang menyumbang sekitar 7,7% dari sampel lengkap.
Imbalan dari Tingkat Keahlian
Jadi, sesi mana yang paling mudah berhasil? Hasilnya menunjukkan bahwa penilaian tingkat keahlian sesi yang dijelaskan di atas memiliki pengaruh besar terhadap keberhasilan sesi.
Seseorang mungkin khawatir bahwa tingkat keahlian bukanlah faktor pendorong sebenarnya. Mungkin ahli hanya memilih tugas yang berbeda, atau berbeda dalam hal lain. Dalam bagian ini, kami sebagian menanggapi kekhawatiran ini dengan membandingkan sesi dengan jenis pekerjaan yang sama, nilai perkiraan yang sama, bulan yang sama, topik yang sama, dari kelompok profesi besar yang sama, dan melihat bagaimana perbedaan tingkat keahlian pengguna memengaruhi hasil.
Dalam semua metrik keberhasilan, semakin tinggi tingkat keahlian yang ditampilkan pengguna dalam sesi, semakin mungkin sesi itu berhasil. Sesi yang dinilai sebagai Pemula mencapai tingkat keberhasilan 15% pada metrik kami yang paling ketat, "Keberhasilan yang Diverifikasi", dan mencapai tingkat setidaknya sebagian berhasil 77%. Sementara sesi yang dinilai sebagai Menengah ke atas memiliki tingkat Keberhasilan yang Diverifikasi 28% hingga 33%, dan tingkat keberhasilan sebagian 91% hingga 92% (lihat Gambar 5).
Dalam setiap metrik, sebagian besar keuntungan berasal dari peningkatan dari Pemula ke Menengah; dari Menengah ke Ahli, kemiringannya melambat. Detail analisis regresi di balik Gambar 5, lihat Lampiran.
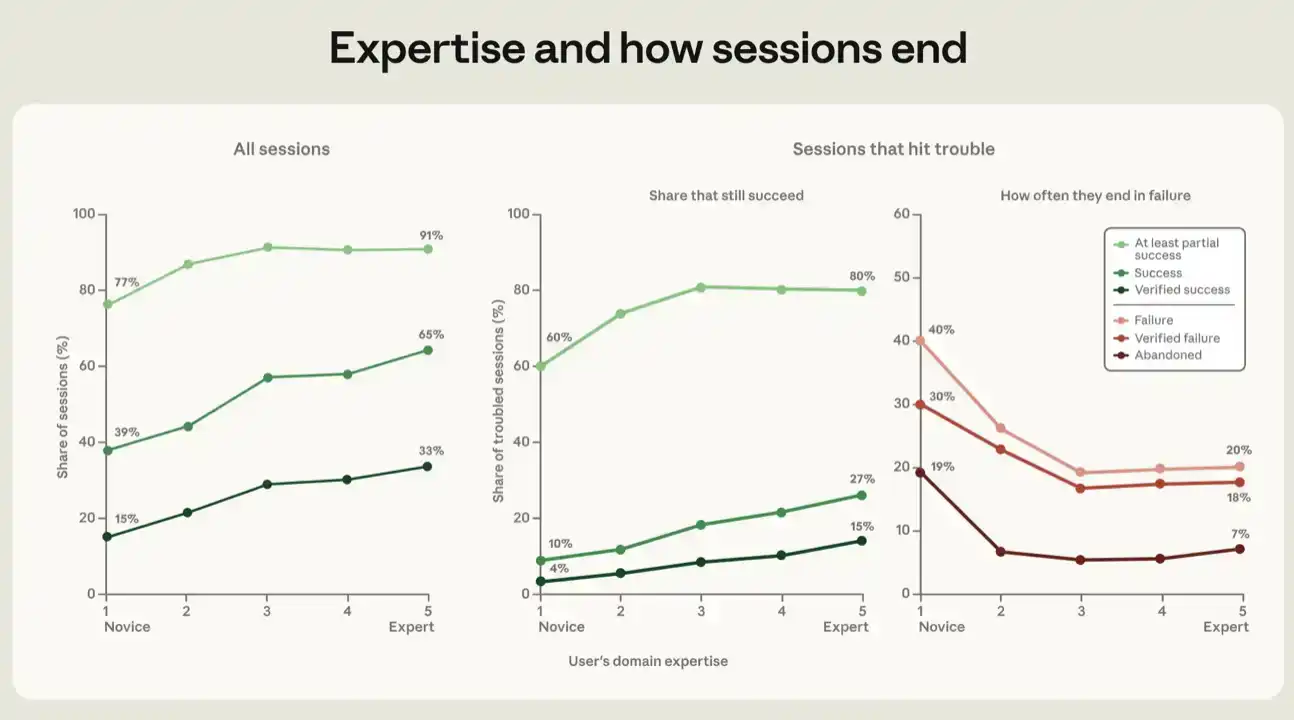
Gradien serupa juga dapat dilihat dalam sesi yang mengalami tantangan. Ketika sinyal kegagalan mencatat bukti kegagalan yang terverifikasi, kami menganggap sesi tersebut "mengalami masalah". Ini mungkin termasuk munculnya kesalahan, pengujian gagal, beberapa kali mencoba menyelesaikan hal yang sama, atau pengguna mengungkapkan kekecewaan dan ketidakpuasan. Dalam sesi yang mengalami masalah, setelah mengontrol semua variabel di atas, proporsi Keberhasilan yang Diverifikasi meningkat dari 4% pada sesi pemula menjadi 15% pada sesi ahli (lihat Gambar 5). Jika menggunakan metrik keberhasilan yang lebih longgar, kami menemukan bahwa proporsi setidaknya sebagian berhasil adalah 60% di antara pengguna pemula, dan 80% hingga 81% di antara pengguna menengah hingga ahli.
Kami juga melacak hubungan terbalik lainnya, yaitu hubungan antara tingkat keahlian dengan berbagai metrik kegagalan. Perlu diperhatikan bahwa dalam analisis ini, sesi yang dinilai gagal adalah sesi yang bahkan tidak mencapai keberhasilan sebagian. Jika sesi yang mengalami masalah dinilai gagal, dan tidak menulis baris kode apa pun, kami menyebutnya ditinggalkan. Dalam sesi di mana pengguna tampak sebagai pemula, 19% akhirnya ditinggalkan; sedangkan di antara kelompok pengguna lainnya, angkanya 5% hingga 7%. Dengan kata lain, pengguna dengan pengalaman paling sedikit lebih mudah menyerah ketika berusaha mencapai tujuan tetapi menghadapi kesulitan. Sebagian nilai kemampuan keahlian tampaknya terletak pada kemampuan untuk mengarahkan agen kembali ke jalur yang benar.
Profesi Mungkin Tidak Sepenting Tingkat Keahlian
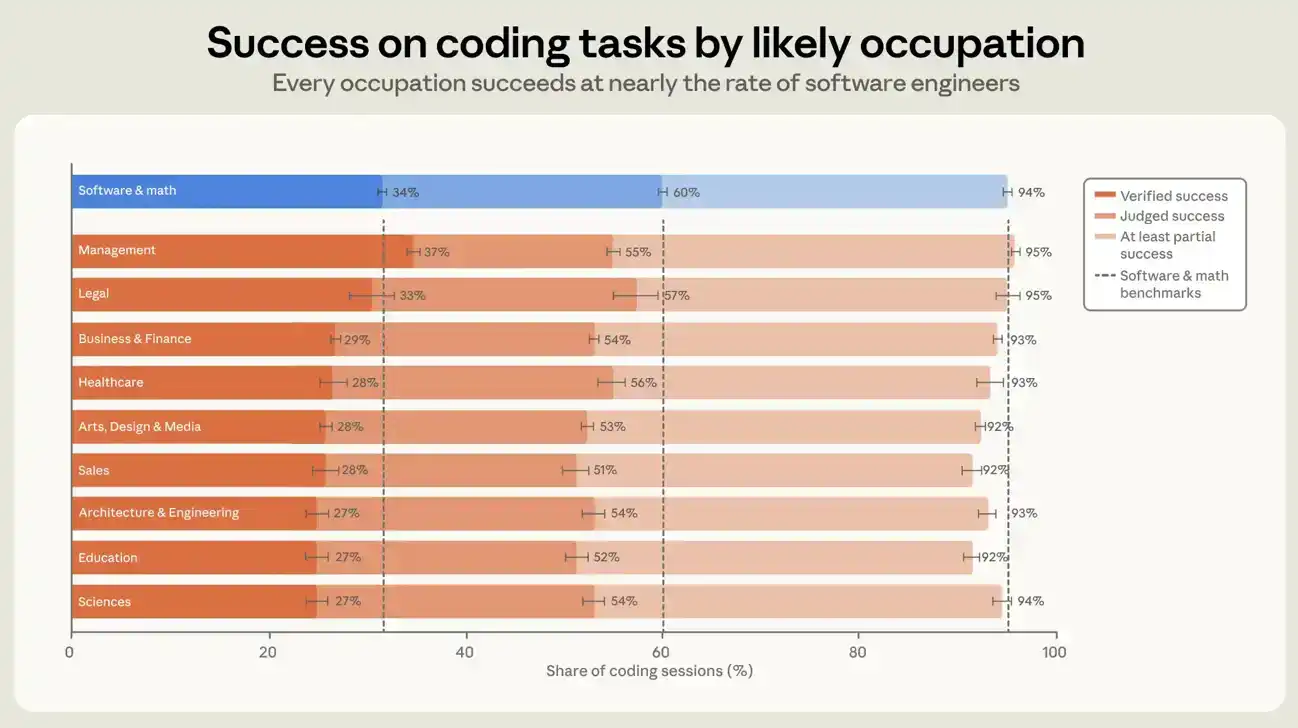
Pengguna profesi terkait perangkat lunak memiliki tingkat Keberhasilan yang Diverifikasi sekitar 30% di semua sesi, pengguna profesi lain sekitar 26%. Dalam sesi yang menghasilkan kode, yaitu sesi yang setidaknya menambah atau memodifikasi satu baris kode, kedua angka tersebut masing-masing 34% dan 29% (lihat Gambar 6). Jika menggunakan definisi keberhasilan yang lebih longgar, kesenjangan antara profesi terkait perangkat lunak dan profesi lain semakin menyempit. Dalam sesi yang menghasilkan kode, proporsi yang mencapai setidaknya sebagian berhasil untuk kedua jenis pengguna adalah 89% dan 88%. Kesenjangan lima persen tidak besar, dan dalam tujuh bulan tidak membesar maupun menyusut, meskipun tingkat keberhasilan kedua kelompok meningkat. Dalam sesi yang menghasilkan kode, sepuluh kelompok profesi terbesar dalam kumpulan data kami, masing-masing memiliki kesenjangan keberhasilan dengan insinyur perangkat lunak dalam tujuh poin persentase. Profesi Manajemen memiliki tingkat Keberhasilan yang Diverifikasi tertinggi, sedikit lebih tinggi daripada profesi Teknik Perangkat Lunak. Tingkat keberhasilan yang lebih tinggi dari manajer mungkin mencerminkan bahwa keterampilan manajemen dapat ditransfer ke tugas memerintah agen. Tetapi ini juga mungkin sebagian berasal dari cara pengukuran kami: verifikasi sampai batas tertentu bergantung pada konfirmasi eksplisit pengguna dalam sesi, dan manajer mungkin lebih terbiasa mengekspresikan diri ketika mendapatkan hasil yang diinginkan.
Pandangan ke Depan
Hasil laporan ini menguraikan gambaran yang sedang terbentuk: pemrograman agen sedang memperbesar pengetahuan dan keterampilan tertentu, sambil menggantikan keterampilan lain. Dalam sesi yang menghasilkan kode, tingkat keberhasilan di setiap profesi utama tidak jauh berbeda dengan profesi terkait perangkat lunak. Tampaknya, agen pengkodean sedang membuat latar belakang pemrograman menjadi kurang penting untuk keberhasilan menyelesaikan tugas pemrograman.
Pada saat yang sama, sesi yang berhasil lebih mungkin menunjukkan keahlian domain. Sesi yang dinilai sebagai ahli memiliki tingkat Keberhasilan yang Diverifikasi lebih dari dua kali lipat sesi pemula. Ketika sesi mengalami masalah, pemula juga beberapa kali lebih mungkin menyerah daripada pengguna lain. Cara kolaborasi itu sendiri membuat gambaran ini lebih jelas: ahli domain dapat membimbing Claude untuk menyelesaikan lebih banyak pekerjaan dengan setiap instruksi. Oleh karena itu, kemampuan untuk mengarahkan Claude menuju keberhasilan lebih banyak berasal dari penguasaan suatu domain, bukan kemampuan menulis kode. Siapa pun yang memiliki penguasaan ini di bidang apa pun sekarang mungkin dapat menyelesaikan pekerjaan teknis yang sebelumnya tidak dapat mereka lakukan. Dan mereka yang kurang memiliki pemahaman keahlian ini, bahkan dengan alat yang sama, akan mendapatkan lebih sedikit. Selain itu, keuntungan terutama berasal dari kompeten, bukan menguasai. Memiliki pemahaman yang dapat dioperasionalkan di suatu domain sudah memberikan sebagian besar keuntungan; spesialisasi mendalam hanya membawa sedikit keuntungan tambahan di atasnya.
Temuan-temuan ini masih awal. Seperti kebanyakan penelitian kami, kami tidak dapat mengukur hasil dunia nyata, misalnya apakah kode yang ditulis dalam suatu sesi kemudian digunakan atau dibuang, atau apakah itu menghasilkan hasil yang bernilai ekonomi. Selain itu, laporan ini mengecualikan penggunaan non-interaktif, yang menyumbang porsi yang cukup besar dari aktivitas keseluruhan. Mengembangkan kerangka kerja yang dapat mengukur penggunaan semacam ini adalah fokus pekerjaan masa depan. Dan, semua klasifikasi kami terhadap sesi bergantung pada pembacaan model terhadap catatan sesi. Dalam Lampiran, kami menunjukkan bahwa pengklasifikasi konsisten dengan data telemetri independen dalam arah yang diharapkan, dan dalam banyak sesi sesuai dengan penilaian model referensi kuat. Namun, memvalidasi pengklasifikasi dalam skala besar tetap sulit; sesi Claude Code itu sendiri juga menambah kesulitan karena mungkin terlalu panjang dan terlalu kompleks untuk menggunakan penandaan manual sebagai patokan nyata.
Seiring model, pengguna, dan pembagian kerja di antara mereka terus berubah, gambaran dalam laporan ini juga akan terus diperbarui. Kami berharap metrik-metrik ini dapat membantu kami melacak pergeseran besar yang sedang terjadi. Misalnya, jika di masa depan imbalan dari tingkat keahlian mulai menurun, itu akan menunjukkan bahwa model mulai memberikan penilaian kunci yang saat ini dibawa pengguna, dan keuntungan alat-alat ini akan meluas dari ahli domain ke populasi yang lebih luas. Jika proporsi pengguna di luar profesi perangkat lunak yang berhasil menyelesaikan sesi pengkodean terus meningkat, itu mungkin berarti produksi perangkat lunak sedang menjadi bagian dari pekerjaan biasa di berbagai bidang, dan bukan lagi produk dari satu profesi tunggal. Pergeseran-pergeseran ini akan mengubah siapa yang dapat mengambil manfaat dari pemrograman agen, dan seberapa besar, serta memengaruhi kemampuan yang paling dihargai di pasar tenaga kerja.





