Februari 2026, Xiaohongshu merilis pengumuman yang mengharuskan konten yang dihasilkan/disintesis AI untuk diberi penanda secara aktif. Konten yang tidak diberi penanda akan dibatasi distribusinya. Lebih dari tiga bulan kemudian, sebuah proyek open-source bernama guizang-social-card-skill muncul di GitHub, khusus untuk menghasilkan gambar-gambar 3:4 Xiaohongshu dan sampul akun resmi WeChat. Ada pilihan teknis yang tidak biasa dalam jalurnya: ia tidak menggunakan model AI apa pun untuk menghasilkan piksel gambar. Seluruh tampilan bergantung pada rendering HTML+CSS, dengan gambar pendukung dari pencarian pustaka foto asli seperti Unsplash. Outputnya bukanlah "gambar yang dihasilkan AI", melainkan screenshot halaman web yang di-rasterisasi oleh mesin browser.
Pilihan ini merespons perubahan konkret. Sejak 2026, Xiaohongshu telah meluncurkan model identifikasi audio-visual, menganalisis pola distribusi piksel gambar dan karakteristik audio untuk mendeteksi konten AIGC. Pada periode yang sama, lebih dari 800 ribu akun hosting AI dan hampir 150 ribu catatan pemalsuan AI telah ditindak. Bagi pembuat konten yang perlu menghasilkan gambar dan teks dalam frekuensi tinggi, kemungkinan gambar yang dihasilkan oleh Midjourney atau Canva AI terdeteksi dan diberi label terus meningkat. Skill buatan Master Cang memilih jalan lain: membiarkan AI membuat keputusan tata letak, dan menyerahkan piksel akhir ke mesin render dan pustaka foto asli.
Ini adalah upaya penghindaran teknis yang disengaja. Namun, seberapa jauh solusi ini dapat bertahan bergantung pada kelenturan definisi platform terhadap istilah "konten yang dihasilkan/disintesis AI".
28 Kerangka Tata Letak, AI Bertanggung Jawab atas Logika Layout, Bukan Melukis
Master Cang bernama asli Gui Cang. Sebelumnya, ia telah merilis guizang-ppt-skill, alat AI yang juga ditujukan untuk skenario layout gambar dan teks. Skill social-card-skill kali ini lebih fokus: ditujukan untuk gambar 3:4 Xiaohongshu, serta sampul 1:1 dan 21:9 akun resmi WeChat, dengan resolusi output berturut-turut 1080×1440, 1080×1080, dan 2100×900.
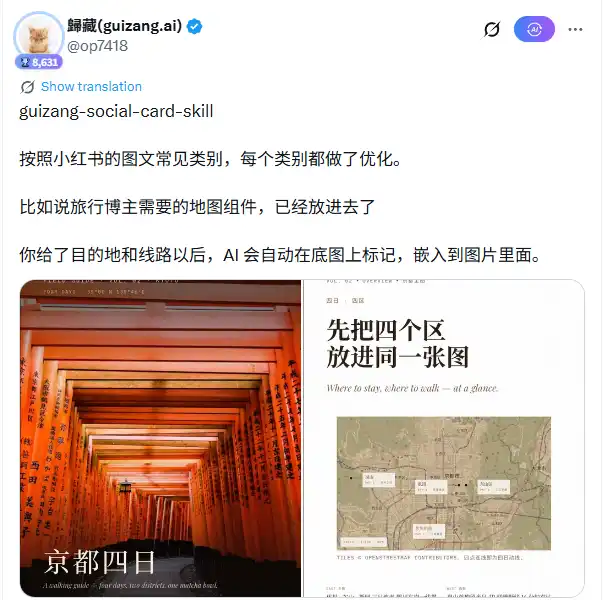
Secara arsitektur teknis, Skill ini memiliki 28 kerangka tata letak bawaan, dibagi menjadi dua sistem visual: Editorial (gaya majalah, 16 tata letak) dan Swiss (gaya Swiss Internationalism, 12 tata letak), dilengkapi dengan 10 set preset tema warna. Setelah pengguna memasukkan tujuan, rencana perjalanan, atau tema catatan, AI bertanggung jawab memilih kerangka tata letak yang sesuai, menentukan posisi teks, memproses parameter anotasi peta, lalu menuliskan semua keputusan desain tersebut ke dalam HTML+CSS. Mesin rendering Playwright mengambil alih tahap selanjutnya, mengambil screenshot halaman demi halaman dan mengeluarkan output PNG.
Komponen yang sangat berguna khususnya untuk blogger perjalanan adalah modul peta. Ia menggunakan MapLibre untuk memuat ubin nyata OpenStreetMap, mendukung penandaan dan penghubungan beberapa lokasi. Pengguna hanya perlu menyediakan nama kota atau tempat wisata, AI secara otomatis menghasilkan peta dasar dengan anotasi dan menyematkannya ke dalam tata letak. Alur kerja sumber gambar yang menyertainya memiliki prioritas yang jelas: foto asli yang disediakan pengguna paling diprioritaskan; jika tidak ada gambar dari pengguna, dilakukan pencarian otomatis untuk gambar pendukung dengan urutan prioritas: Unsplash → Pexels → Flickr CC → Wallhaven.

Seluruh proses dieksekusi dalam tujuh langkah: Intake (menerima input) → Style & Theme (menentukan gaya dan tema) → Layout Selection (pemilihan tata letak) → Asset Prep (persiapan aset) → Compose & Render (penyusunan dan rendering) → Deliver & Review (output dan peninjauan) → Iterate (modifikasi berulang). Setiap langkah dicatat dalam file .poster di direktori task. Saat menghasilkan gambar dalam jumlah besar, jalankan
node render.mjs, dan Playwright akan merender satu per satu. Ada juga skrip validasi validate-social-deck.mjs yang mengukur elemen DOM di lingkungan browser nyata, mendeteksi kecelakaan tata letak seperti teks meluap, ukuran font melebihi batas atas, atau tabrakan elemen footer.
Tujuan desain mekanisme ini jelas: presisi dan terkendali seperti perangkat lunak tata letak cetak, bukan kebebasan yang tidak terduga seperti model difusi. Imbalannya adalah kebebasan kreatif dibatasi dalam 28 kerangka. Bagi pembuat konten yang bergantung pada gaya fotografi pribadi, elemen gambar tangan, atau kolase tidak beraturan, kerangka tata letak ini bukanlah peningkatan efisiensi, melainkan kendala desain.
Dalam hal tingkat kesulitan penggunaan, versi CLI memerlukan instalasi Playwright, lingkungan Node, serta izin API Claude Code atau Codex. Ada juga pintu masuk versi web xiaohongshu.guizang.ai untuk pengguna non-pengembang, namun belum ada informasi perbandingan publik apakah kelengkapan fungsinya konsisten dengan versi CLI. Beberapa tweet di platform X yang dirilis pengembang dan README yang terus diperbarui menunjukkan bahwa proyek ini masih dalam iterasi cepat.
Piksel Bukan dari Model Generatif, Tapi Kepatuhan Tidak Sama dengan Keamanan Jangka Panjang
Logika deteksi konten AI Xiaohongshu, berdasarkan analisis informasi publik dan bahan teknis, secara inti bergantung pada model identifikasi audio-visual. Model ini menganalisis pola distribusi piksel gambar untuk menilai apakah konten berasal dari model generatif AI. Model difusi dan GAN meninggalkan karakteristik statistik tertentu di tingkat piksel saat menghasilkan gambar, karakteristik ini berbeda dengan cahaya alami yang ditangkap sensor kamera, distorsi lensa, dan pola noise. Target pelatihan model identifikasi audio-visual adalah menangkap ketidakkonsistenan dalam pola statistik ini.
Logika penghindaran Skill Master Cang dibangun di atas pembedaan kunci: piksel gambar outputnya tidak berasal dari model generatif apa pun. Mesin render HTML melakukan rasterisasi terhadap gaya CSS, menghasilkan karakteristik distribusi piksel yang lebih mendekati screenshot antarmuka browser atau output perangkat lunak desktop publishing. Bagian foto berasal dari materi foto asli oleh manusia dari pustaka seperti Unsplash, gambar-gambar ini diambil kamera dan diproses pasca-produksi secara manual, tidak membawa jejak model difusi.

Namun, pembedaan ini berlaku dengan syarat bahwa definisi platform terhadap "konten yang dihasilkan/disintesis AI" tepat berada di garis "model AI menghasilkan piksel". Pengumuman resmi Xiaohongshu menggunakan istilah "konten yang dihasilkan/disintesis AI", cakupan aslinya tidak sempit. Begitu platform memperluas definisi menjadi "output render program yang dibantu desain AI", atau memasukkan karakteristik render browser dari gambar rasterisasi HTML ke dalam set pelatihan model identifikasi, keuntungan teknis solusi saat ini akan hilang.
Platform memiliki dasar teknis dan motivasi tata kelola untuk memperluas definisi. Model identifikasi audio-visual sendiri terus beriterasi. Jika data pelatihan memasukkan banyak sampel kontras antara gambar render HTML dan gambar hasil AI, model dapat belajar membedakan "karakteristik subpixel anti-aliasing dari render font browser" dengan "blok piksel tidak teratur saat GAN menghasilkan teks". Saat ini belum ada informasi publik yang menunjukkan Xiaohongshu telah memulai pelatihan ke arah ini, tetapi dari batas kemampuan model, perluasan seperti itu secara teknis dimungkinkan.
Fakta yang lebih perlu diperhatikan adalah elemen kepatuhan terkait hosting aplikasi mini. Saat ini belum terlihat dokumen resmi apa pun yang menjelaskan bahwa Skill ini telah mengintegrasikan nomor pencatatan model atau menyelesaikan pendaftaran kepatuhan terkait. Jika platform menambahkan persyaratan pelacakan rantai alat pembuatan gambar dalam proses tinjauan konten, kurangnya informasi pencatatan dapat menjadi titik pemblokiran baru.
Mesin Templat API, Alat Kustomisasi Platform, dan Render HTML, Sedang Membuka Tiga Jalur Berbeda
Mengamati alat-alat di pasaran yang menghasilkan gambar untuk media sosial, terlihat bahwa mereka sedang berkembang menjadi tiga jalur teknis berbeda. Masing-masing menghadapi struktur risiko moderasi yang berbeda.
Model AI Langsung Menghasilkan Gambar. Jalur ini diwakili oleh fitur Magic Design yang dirilis Canva AI pada April 2026, menghasilkan draf desain yang berisi elemen visual AI langsung dari kata kunci teks. Gambar yang dihasilkan oleh model seperti Midjourney, DALL·E juga termasuk dalam kategori ini. Masalahnya jelas: gambar-gambar ini adalah target utama deteksi model identifikasi audio-visual. Cara Canva menghadapinya adalah mendorong penandaan yang transparan, bukan menghindari deteksi. Di Xiaohongshu, tidak ada data publik yang dapat mengonfirmasi apakah postingan dengan gambar hasil model AI akan memiliki bobot rekomendasi yang lebih rendah setelah diberi label, tetapi pernyataan platform tentang "pembatasan distribusi konten AI yang tidak diberi label" sudah menjadi kebijakan tetap. Setiap kali versi model difusi diperbarui, karakteristik statistik piksel mungkin berubah, dan model deteksi yang sesuai juga akan beriterasi secara bersamaan. Pembuat konten menghadapi target yang terus bergerak.
Render Mesin Templat API. Bannerbear adalah contoh khas jalur ini. Pengguna membuat templat di perancang, mengirimkan data JSON melalui REST API untuk memodifikasi variabel lapisan, dan server merender output PNG atau JPG. Intinya juga "render program" bukan "model menghasilkan piksel", outputnya tidak mengandung jejak model difusi. Perbedaan dengan Skill Master Cang adalah: templat Bannerbear bergantung pada desain manual, AI tidak terlibat dalam keputusan tata letak; Skill Master Cang membiarkan Claude langsung membaca dan menulis HTML, hak pilih tata letak diberikan kepada AI. Risiko skema Bannerbear berada di dimensi lain: ketika banyak akun menggunakan templat, skema warna, dan font yang sama untuk menghasilkan gambar dan teks, meskipun setiap gambar bukan hasil AI, hal ini dapat memicu pengenalan pola "produksi massal terprogram" di sisi platform. Kondisi pemicu aturan anti-spam tidak sepenuhnya sama dengan deteksi AI, tetapi bagi pembuat konten yang mengoperasikan akun dalam jumlah besar, hasilnya tetap sama: distribusi terbatas.
Generasi Kustomisasi Platform. Pin Generator dirancang khusus untuk Pinterest, secara otomatis menghasilkan gambar Pin yang sesuai dengan preferensi algoritma platform. Inti dari jalur ini bukanlah penghindaran, tetapi adaptasi penuh – ukuran, gaya visual, irama publikasi semuanya selaras dengan norma platform. Kelebihannya adalah risiko moderasi terendah, kekurangannya juga jelas: kemampuan alat terikat erat pada aturan platform, saat Pinterest menyesuaikan algoritma atau membatasi pemanggilan API pihak ketiga, alat langsung tidak berfungsi. Dibandingkan dengan Skill Master Cang, yang pertama adalah alat khusus platform, yang kedua adalah skema lintas platform umum. Khusus platform lebih aman tetapi lebih rapuh, lintas platform umum lebih fleksibel tetapi lebih kompleks – ini adalah serangkaian pilihan yang muncul berulang kali di bidang alat AI.
Struktur risiko ketiga jalur ini berbeda. Generasi AI paling bebas tetapi setiap pembaruan harus menjawab model deteksi baru. Mesin templat paling stabil tetapi berisiko terkena dampak aturan anti-spam. Render HTML berjalan di antara keduanya: tata letak dikontrol secara fleksibel oleh AI, piksel diserahkan ke browser dan materi foto asli, yang dihindari adalah deteksi di tingkat "AI menghasilkan piksel", tetapi tidak dapat menghadapi perluasan aturan di tingkat semantik platform.
Batas Atas Sistem Tata Letak, Bukan dalam Kode tetapi dalam Jenis Konten
28 kerangka tata letak mencakup dua sistem visual utama: gaya majalah dan Swiss. Bagi blogger perjalanan yang perlu menampilkan rute peta, linimasa, atau rencana perjalanan multi-hari, sistem ini memiliki kecocokan yang tinggi. Anotasi peta dan penghubung rencana perjalanan adalah informasi inti dari catatan ini, kerangka tata letak memberikan struktur pada informasi, sekaligus menjaga kesan profesional tata letak.
Namun ekosistem konten Xiaohongshu jauh lebih kaya daripada panduan perjalanan. Catatan pakaian bergantung pada gaya fotografi pribadi dan karakteristik warna, ulasan kosmetik memerlukan foto makro resolusi tinggi dan gambar perbandingan produk, konten gaya hidup banyak menggunakan kolase banyak gambar dan anotasi tulisan tangan. "Tata letak" dari jenis konten ini bukanlah penyajian informasi yang terstruktur, melainkan ekspresi estetika dan emosi pribadi. 28 kerangka tata letak dalam skenario ini bukanlah alat, melainkan kendala.

Batasan di tingkat teknis juga nyata. Saat ini mendukung tiga ukuran: 1080×1440 (Xiaohongshu 3:4), 2100×900 (akun resmi WeChat 21:9), dan 1080×1080 (akun resmi WeChat 1:1). Sampul vertikal 9:16 Douyin dan sampul horizontal 16:9 Bilibili tidak didukung. Pustaka gambar bergantung pada Unsplash dan Pexels, materi dari kedua platform ini cenderung pada fotografi berkualitas tinggi, cocok untuk kebutuhan gambar pendukung perjalanan, pemandangan, dan arsitektur kota. Namun cakupan materi frekuensi tinggi untuk konten vertikal seperti close-up makanan, penataan kosmetik, dan item pakaian, dalam pustaka gambar ini terbatas. Strategi prioritas gambar pengguna dapat sebagian meredakan masalah ini, dengan syarat pembuat konten sendiri memiliki cukup akumulasi materi foto asli.
Mekanisme validasi adalah pedang bermata dua. validate-social-deck.mjs dapat mengintervensi kecelakaan tata letak sebelum gambar dihasilkan, memastikan 100 render massal tidak salah. Ini adalah jaminan efisiensi dalam skenario operasional yang perlu memperbarui puluhan gambar setiap hari. Namun juga berarti desain apa pun yang tidak sesuai dengan aturan tata letak yang telah ditetapkan akan ditolak oleh skrip. Pembuat konten yang ingin menambahkan dekorasi teks miring atau margin kustom dalam tata letak standar, tidak dapat menyesuaikannya dengan mudah seperti di Canva, tetapi perlu mengedit langsung kode sumber HTML dan CSS.
Tingkat kesulitan penyebaran lokal adalah titik stratifikasi lainnya. Pembuat konten yang dapat menjalankan skrip Playwright dan Node dapat melakukan penyesuaian mendalam ke dalam kerangka tata letak dan skrip render. Namun, bagi sebagian besar blogger Xiaohongshu, yang dapat diakses adalah subset fungsi dari antarmuka versi web. Nilai praktis yang diperoleh kedua jenis pengguna ini dari Skill ini sangat berbeda. Inti pengguna proyek open-source adalah pembuat konten dan pengembang yang bersedia bereksperimen dan memiliki latar belakang teknis, bukan kebutuhan "menghasilkan gambar dengan satu klik" dari produsen konten biasa.
Tidak Ada Jawaban Ajaib, Tapi Diferensiasi Jalur Teknis Sudah Menjelaskan Masalahnya
Seorang blogger perjalanan Xiaohongshu menghadapi tiga pilihan: menggunakan Midjourney untuk menghasilkan gambar rencana perjalanan bergaya ilustrasi, menanggung risiko diberi label dan diturunkan peringkat; menggunakan Bannerbear untuk menyiapkan templat dan setiap hari memasukkan data secara massal, menanggung risiko homogenitas templat yang memicu aturan anti-spam; atau menggunakan Skill Master Cang, membiarkan AI memilih tata letak lalu merender gambar dengan HTML, menanggung risiko platform memperluas definisi "konten disintesis". Tidak ada kartu aman, hanya kombinasi struktur risiko yang berbeda.
Pola ini sendiri menyampaikan sebuah pesan: iterasi perlawanan antara platform dan alat AI sudah dimulai. Setiap kali platform memperbarui model deteksi, akan ada periode keuntungan teknis dari sekelompok alat yang berakhir. Setiap kali ada alat baru yang menemukan jalan keluar, platform akan menyesuaikan strategi. Ini bukan proses yang akan konvergen ke keadaan stabil. Masa berlaku solusi render HTML bergantung pada apakah arah pelatihan model identifikasi audio-visual Xiaohongshu tetap berfokus pada "karakteristik piksel model difusi", atau diperluas ke "semua piksel non-fotografi asli".
Bagi pembuat konten, membedakan "dibantu AI" dan "digantikan AI" menjadi memiliki makna praktis. Sikap platform sudah jelas: mendorong AI sebagai penguat kreativitas, menentang penggunaan AI untuk menggantikan manusia dalam produksi massal berkualitas rendah. Dalam Skill Master Cang, AI melakukan keputusan tata letak, bukan pembuatan konten, foto adalah hasil pemotretan asli, tata letak adalah kerangka yang telah ditetapkan oleh desainer manusia. Ini tepat berada di zona "dibantu AI". Gambar dan teks yang dari teks hingga gambar semuanya dihasilkan oleh model generatif, adalah objek yang jelas ingin diberantas oleh platform.
Apakah pemisahan ini akan menjadi standar operasional moderasi platform, saat ini masih belum pasti. Namun pengembang alat sudah merespons definisi ini dengan pilihan teknis.






