Di era telegram yang dibayar per kata, tinta dan kertas adalah uang. Orang-orang terbiasa meringkas ribuan kata hingga sangat singkat, "pulang cepat" setara dengan surat panjang, "selamat" adalah pesan paling berharga.
Kemudian, telepon masuk ke rumah, tetapi biaya interlokal dihitung per menit. Telepon jarak jauh orang tua selalu singkat dan padat, urusan selesai langsung ditutup, begitu obrolan mulai melebar, kekhawatiran akan biaya akan memotong basa-basi yang baru dimulai.
Lalu, broadband masuk ke rumah, internet dibayar per jam, orang-orang menatap timer di layar, membuka dan langsung menutup halaman web, video yang berani diunduh, streaming adalah kata kerja mewah saat itu. Di ujung setiap bilah kemajuan unduhan, tersimpan keinginan orang untuk "terhubung dengan dunia" dan kekhawatiran akan "saldo tidak cukup".
Unit penagihan berubah lagi dan lagi, naluri berhemat abadi tak berubah.
Sekarang, Token menjadi mata uang era AI. Namun, kebanyakan orang belum belajar bagaimana berhemat di era ini, karena kita belum belajar bagaimana menghitung untung rugi dalam algoritma yang tak terlihat.
Tahun 2022 ketika ChatGPT baru muncul, hampir tidak ada yang peduli apa itu Token. Itu adalah era makanan besar AI, bayar 20 dolar per bulan, ingin ngobrol berapa pun boleh.
Tetapi sejak AI Agent menjadi populer baru-baru ini, pengeluaran Token menjadi hal yang harus diperhatikan setiap orang yang menggunakan AI Agent.
Berbeda dengan dialog tanya jawab sederhana, di balik alur tugas ada ratusan hingga ribuan panggilan API, pemikiran mandiri Agent ada harganya, setiap koreksi diri, setiap panggilan alat, sesuai dengan lonjakan angka pada tagihan. Lalu Anda akan menemukan uang yang Anda isi tiba-tiba tidak cukup, dan Anda tidak tahu apa yang sebenarnya dilakukan Agent.
Dalam kehidupan nyata, semua orang tahu cara berhemat. Pergi ke pasar belanja sayur, kita tahu membuang daun busuk yang berdebu sebelum ditimbang; naik taksi ke bandara, supir tua tahu menghindari jalan layang jam sibuk pagi.
Logika berhemat di dunia digital sebenarnya sama, hanya unit penagihan dari "kilo" dan "kilometer", diganti menjadi Token.
Di masa lalu, penghematan disebabkan oleh kekurangan; di era AI, penghematan adalah untuk ketepatan.
Kami berharap melalui artikel ini, membantu Anda menyusun metodologi penghematan di era AI, membuat setiap sen uang digunakan dengan efisien.
Sebelum ditimbang, buang dulu daun busuk
Di era AI, nilai informasi tidak lagi ditentukan oleh luasnya, tetapi oleh kemurniannya.
Logika penagihan AI adalah dengan membayar sesuai jumlah kata yang dibacanya. Entah yang Anda berikan adalah wawasan berharga, atau format omong kosong yang tidak berarti, selama dibaca, Anda harus bayar.
Karena itu, cara berpikir pertama menghemat Token, adalah mengukir "rasio sinyal terhadap noise" ke dalam alam bawah sadar.
Setiap kata, setiap gambar, setiap baris kode yang Anda berikan ke AI, harus dibayar. Jadi sebelum memberikan apa pun ke AI, ingat untuk bertanya pada diri sendiri: berapa banyak yang benar-benar dibutuhkan AI? Berapa banyak yang busuk dan berdebu?
Misalnya "Halo, tolong bantu saya..." pembukaan panjang seperti ini, pengantar latar belakang yang berulang, komentar kode yang tidak dihapus bersih, semua adalah daun busuk berdebu.
Selain itu, pemborosan paling umum, adalah langsung melempar PDF atau screenshot halaman web ke AI. Memang Anda sendiri jadi mudah, tetapi "kemudahan" di era AI sering berarti "mahal".
Sebuah PDF dengan format lengkap, selain konten tubuh, juga包含header, footer, label grafik, watermark tersembunyi, serta大量kode format untuk tata letak. Hal-hal ini tidak membantu AI memahami pertanyaan Anda, tetapi semuanya harus dibayar.
Lain kali ingat untuk mengubah PDF menjadi teks Markdown bersih sebelum diberikan ke AI. Ketika Anda mengubah PDF 10MB menjadi teks bersih 10KB, Anda tidak hanya menghemat 99% uang, tetapi juga membuat otak AI berjalan lebih cepat dari sebelumnya.
Gambar adalah pemakan uang lainnya.
Dalam logika model visual, AI tidak peduli foto Anda cantik atau tidak, hanya peduli berapa banyak area piksel yang Anda gunakan.
Ambil logika perhitungan resmi Claude sebagai contoh: konsumsi Token gambar = lebar piksel × tinggi piksel ÷ 750.
Sebuah gambar 1000×1000 piksel, mengkonsumsi sekitar 1334 Token, menurut harga Claude Sonnet 4.6, setiap gambar sekitar 0,004 dolar;
Tetapi jika gambar yang sama dikompresi menjadi 200×200 piksel, hanya mengkonsumsi 54 Token, biaya turun menjadi 0,00016 dolar, berbeda整整25 kali.
Banyak orang langsung melempar foto HD dari ponsel, screenshot 4K ke AI, tidak tahu bahwa Token yang dikonsumsi gambar-gambar ini mungkin cukup untuk AI membaca sebagian besar novel pendek. Jika tugas hanya mengenali teks dalam gambar atau melakukan penilaian visual sederhana, seperti meminta AI mengenali jumlah pada faktur, membaca teks dalam manual, atau menilai apakah ada lampu lalu lintas dalam gambar, maka resolusi 4K adalah pemborosan belaka, kompres gambar ke resolusi minimum yang dapat digunakan sudah cukup.
Tetapi alasan paling mudah membuang Token di input, sebenarnya bukan format file, tetapi cara berbicara yang tidak efisien.
Banyak orang menganggap AI sebagai tetangga sungguhan, terbiasa berkomunikasi dengan obrolan ringan sosial, pertama lempar kalimat "bantu saya membuat halaman web", tunggu AI mengeluarkan setengah jadi, lalu tambahkan detail, tarik ulur berulang kali. Dialog seperti memeras pasta gigi ini, akan membuat AI berulang kali menghasilkan konten, setiap putaran modifikasi menumpuk konsumsi Token.
Insinyur Tencent Cloud dalam praktik menemukan, permintaan yang sama, dialog multi-putaran seperti memeras pasta gigi, konsumsi Token akhir往往3 sampai 5 kali lipat dari sekali jelaskan dengan jelas.
Cara berhemat yang sebenarnya, adalah meninggalkan试探sosial yang tidak efisien ini, sekaligus menyampaikan persyaratan, kondisi batas, contoh referensi dengan jelas. Kurangi menjelaskan dengan susah payah "jangan lakukan apa", karena kalimat negatif往往lebih banyak mengonsumsi biaya pemahaman daripada kalimat positif; langsung katakan "bagaimana melakukannya", dan berikan contoh benar yang jelas.
Selain itu, jika Anda tahu tujuannya di mana, langsung beri tahu AI dengan jelas, jangan suruh AI menjadi detektif.
Ketika Anda memerintahkan AI "cari kode terkait pengguna", AI harus melakukan pemindaian, analisis, dan tebakan besar-besaran di latar belakang; sedangkan ketika Anda langsung memberitahunya "lihat file src/services/user.ts", konsumsi Token sangat berbeda, di dunia digital, kesetaraan informasi adalah penghematan terbesar.
Jangan bayar untuk "sopan santun" AI
Penagihan model besar ada aturan tersembunyi yang banyak orang tidak sadari: Output Token通常lebih mahal 3 sampai 5 kali lipat dari Input Token.
Artinya, perkataan AI, lebih mahal daripada perkataan Anda kepadanya. Ambil harga Claude Sonnet 4.6 sebagai contoh, input per juta Token hanya 3 dolar, sedangkan output melonjak tajam menjadi 15 dolar,整整5 kali lipat selisihnya.
Pembukaan sopan santun那些"Baik, saya telah sepenuhnya memahami kebutuhan Anda, sekarang mulai menjawab...",那些"Semoga konten di atas membantu Anda" penutup basa-basi, dalam komunikasi manusia nyata adalah sopan santun sosial, tetapi pada tagihan API, basa-basi tanpa nilai informasi ini juga harus dibayar dengan uang Anda sendiri.
Cara paling efektif mengatasi pemborosan output, adalah membuat aturan untuk AI. Gunakan instruksi sistem untuk memberitahunya dengan jelas: jangan basa-basi, jangan jelaskan, jangan ulangi kebutuhan, langsung berikan jawaban.
Aturan ini hanya perlu diatur sekali, lalu berlaku dalam setiap percakapan, adalah cara mengelola uang yang benar-benar "sekali investasi, untung selamanya". Tetapi saat membuat aturan, banyak orang jatuh ke dalam kesalahan lain: menumpuk instruksi dengan bahasa alami yang panjang.
Data实测insinyur menunjukkan,效能instruksi tidak terletak pada jumlah kata, tetapi pada kepadatan. Mengompresi提示词sistem 500 kata menjadi 180 kata, dengan menghapus kata-kata sopan santun yang tidak berarti, menggabungkan instruksi berulang, dan merekonstruksi paragraf menjadi daftar item yang ringkas, kualitas output AI hampir tidak berfluktuasi, tetapi konsumsi Token per panggilan bisa turun drastis 64%.
Ada cara kontrol yang lebih aktif,那就是membatasi panjang output. Banyak orang tidak pernah mengatur batas output, membiarkan AI bebas berekspresi, pembiaran hak ekspresi ini,往往menyebabkan失控biaya yang ekstrem. Anda mungkin hanya perlu kalimat pendek yang tepat, AI tetapi untuk menunjukkan某种"ketulusan intelektual", tanpa basa-basi menghasilkan小作文800 kata untuk Anda.
Jika yang Anda kejar adalah data murni, harus memaksa AI mengembalikan format terstruktur, bukan deskripsi bahasa alami yang panjang. Dalam membawa volume informasi yang setara, konsumsi Token format JSON jauh lebih rendah dari paragraf esai. Ini karena data terstruktur menghilangkan semua kata sambung冗余, kata语气, dan修饰penjelasan冗余, hanya mempertahankan inti logika berkonsentrasi tinggi. Di era AI, Anda harus menyadari dengan sadar, yang layak Anda bayar adalah nilai hasil, bukan penjelasan diri AI yang tidak berarti itu.
Selain itu, "berpikir berlebihan" AI juga menggerogoti saldo akun Anda dengan gila-gilaan.
Beberapa model高级memiliki mode "pemikiran扩展", akan melakukan penalaran internal海量sebelum menjawab. Proses penalaran ini juga harus dibayar, dan dengan harga output, sangat mahal.
Mode ini pada dasarnya dirancang untuk "tugas kompleks yang membutuhkan dukungan logika mendalam". Tetapi kebanyakan orang juga memilih mode ini saat menanyakan pertanyaan sederhana. Untuk tugas yang tidak memerlukan penalaran mendalam, beri tahu AI dengan jelas "tidak perlu menjelaskan思路, langsung berikan jawaban", atau matikan manual pemikiran扩展, juga bisa menghemat banyak uang untuk Anda.
Jangan biarkan AI buka catatan lama
Model besar tidak memiliki memori sejati, hanya疯狂membuka catatan lama.
Ini adalah mekanisme底层yang tidak diketahui banyak orang. Setiap kali Anda mengirim pesan baru dalam jendela percakapan, AI tidak mulai memahami dari kalimat Anda ini, tetapi membaca ulang semua konten yang Anda bicarakan sebelumnya, termasuk setiap putaran dialog, setiap segmen kode, setiap dokumen referensi, baru kemudian menjawab Anda.
Dalam tagihan Token, "mengingat yang lama dan mengetahui yang baru" ini绝对不是gratis. Seiring dengan penumpukan putaran percakapan, bahkan jika Anda hanya menanyakan sebuah kata sederhana, biaya membaca ulang seluruh catatan lama di belakang AI也会 meningkat secara geometris. Mekanisme ini menentukan, semakin berat sejarah percakapan, semakin mahal setiap pertanyaan Anda.
Seseorang melacak 496 percakapan nyata yang包含20条以上pesan, menemukan pesan ke-1 rata-rata membaca 14.000 Token, setiap biaya sekitar 3,6 sen; sampai pesan ke-50, rata-rata membaca 79.000 Token, setiap biaya sekitar 4,5 sen,整整80% lebih mahal. Dan konteks semakin panjang, sampai ke-50, konteks yang harus diproses ulang AI已经是5,6 kali lipat dari ke-1.
Menyelesaikan masalah ini, kebiasaan paling sederhana adalah: satu tugas, satu kotak dialog.
Ketika satu topik selesai dibicarakan,果断memulai percakapan baru, jangan anggap AI sebagai jendela obrolan yang tidak pernah dimatikan. Kebiasaan ini terdengar sederhana, tetapi banyak orang tidak bisa melakukannya,总觉得"bagaimana jika masih perlu konten sebelumnya". Faktanya,那些"bagaimana jika" yang Anda khawatirkan绝大多数tidak akan muncul, dan untuk bagaimana jika ini, Anda telah membayar beberapa kali lipat uang pada setiap pesan baru.
Ketika percakapan memang perlu berlanjut, tetapi konteks sudah menjadi sangat panjang, kita dapat menggunakan fungsi kompresi beberapa alat. Claude Code memiliki perintah /compact, dapat meringkas sejarah percakapan yang panjang lebar menjadi ringkasan singkat, membantu Anda melakukan断舍离赛博.
Ada logika berhemat叫 Prompt Caching (缓存提示词). Jika Anda反复menggunakan提示词sistem yang sama, atau setiap percakapan harus mengutip dokumen referensi yang sama, AI akan meng缓存konten ini,下次panggilan hanya mengenakan biaya pembacaan缓存yang sedikit, bukan每次都dibayar dengan harga penuh.
Harga resmi Anthropic menunjukkan, harga Token缓存命中是harga normal 1/10. Prompt Caching OpenAI juga dapat menurunkan biaya input sekitar 50%. Sebuah makalah yang diterbitkan pada Januari 2026 di arXiv, menguji多个platform AI pada tugas panjang, menemukan提示词缓存dapat menurunkan biaya API 45% hingga 80%.
Artinya, konten yang sama, pertama kali diberikan ke AI harus bayar harga penuh,之后setiap panggilan hanya bayar 1/10. Bagi pengguna yang setiap hari harus反复menggunakan dokumen规范atau提示词sistem yang sama, fungsi ini dapat menghemat banyak Token.
Tetapi Prompt Caching memiliki prasyarat,提示词sistem dan konten referensi Anda必须konsisten isi dan urutannya, dan harus diletakkan di paling depan percakapan.一旦konten ada perubahan apa pun,缓存akan gagal, kembali dibayar dengan harga penuh. Jadi, jika Anda有一套aturan kerja tetap, tulis mati, jangan随意mengubah.
技巧terakhir manajemen konteks, adalah memuat sesuai kebutuhan. Banyak orang suka memasukkan semua规范, dokumen, catatan sekaligus ke dalam提示词sistem, alasan还是那个"untuk berjaga-jaga".
Tetapi代价dari melakukan ini adalah, Anda明明hanya melakukan tugas yang sangat sederhana, tetapi terpaksa memuat几千字aturan, sia-sia membuang一堆Token. Dokumen resmi Claude Code menyarankan mengontrol CLAUDE.md dalam 200 baris, memisahkan aturan专项untuk不同场景menjadi file keterampilan independen, gunakan aturan场景yang mana baru muat yang mana. Menjaga kemurnian absolut konteks, adalah尊重tertinggi untuk kekuatan komputasi.
Jangan bawa Porsche untuk beli sayur
Model AI yang berbeda, perbedaan harga巨大.
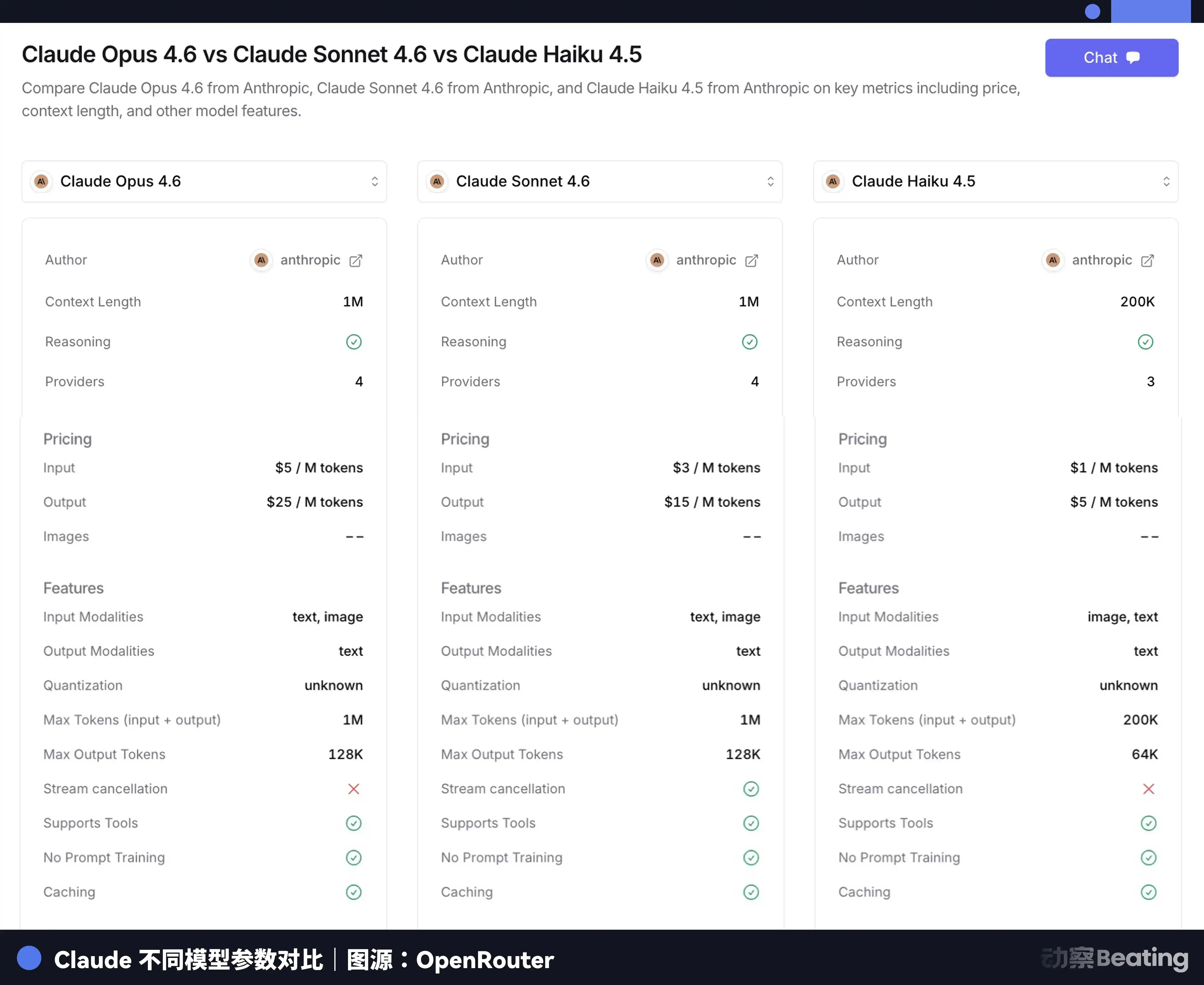
Claude Opus 4.6 per juta Token input 5 dolar, output 25 dolar, Claude Haiku 3.5 hanya 0,8 dolar input, 4 dolar output, berbeda hampir 6 kali lipat. Meminta model paling顶级untuk melakukan pekerjaan kasar mengumpulkan data, memformat format, tidak hanya lambat, tetapi juga sangat mahal.
Penggunaan yang pintar adalah membawa pemikiran "pembagian kelas" yang umum di masyarakat manusia ke masyarakat AI, tugas dengan kesulitan berbeda, serahkan ke model dengan harga berbeda.
Sama seperti mempekerjakan orang untuk bekerja di dunia nyata, Anda tidak akan khusus mempekerjakan ahli dengan gaji jutaan untuk memindahkan batu di lokasi konstruksi. AI也一样. Dokumen resmi Claude Code juga jelas menyarankan: Sonnet menangani大多数tugas pemrograman, Opus disisakan untuk keputusan arsitektur kompleks dan penalaran多步骤, tugas anak sederhana ditentukan menggunakan Haiku.
Skema实操yang lebih konkret adalah membangun "alur kerja dua tahap". Pada tahap pertama, gunakan model dasar gratis atau murah untuk melakukan pekerjaan kotor前期, seperti pengumpulan data, pembersihan format, pembuatan draf awal, klasifikasi dan归纳sederhana. Masuk tahap kedua, baru berikan intisari murni tinggi yang telah disuling ke model顶级, untuk pengambilan keputusan inti dan penyempurnaan mendalam.
Contoh, jika Anda ingin menganalisis laporan industri 100 halaman, pertama gunakan Gemini Flash untuk mengekstrak data kunci dan kesimpulan dalam laporan, mengaturnya menjadi ringkasan 10 halaman, lalu serahkan ringkasan ini ke Claude Opus untuk analisis mendalam dan penilaian. Alur kerja dua tahap ini, dapat menjamin kualitas的前提下,大幅mengompresi biaya.
Lebih进阶dari sekadar pemrosesan分段, adalah pembagian kerja mendalam berdasarkan dekonstruksi tugas. Sebuah tugas teknik yang kompleks,完全可以dibongkar menjadi beberapa tugas anak yang independen, dan mencocokkan model yang paling sesuai.
Misalnya tugas yang perlu menulis kode, dapat meminta model murah menulis kerangka dan kode contoh, lalu hanya menyerahkan bagian logika inti ke model mahal untuk diimplementasikan. Setiap tugas anak memiliki konteks bersih dan fokus, hasil lebih akurat, biaya也更rendah.
Anda sebenarnya tidak perlu menghabiskan Token
Semua eksplorasi di atas, pada dasarnya menyelesaikan masalah taktis "bagaimana berhemat", tetapi sebuah命题logika yang lebih底层diabaikan banyak orang: tindakan ini, apakah benar-benar perlu menghabiskan Token?
Penghematan paling极致bukan optimasi algoritma,而是断舍离keputusan. Kita terbiasa meminta jawaban万能dari AI, tetapi lupa dalam banyak场景, memanggil model besar yang mahal tidak berbeda dengan meriam anti-pesawat untuk打nyamuk.
Misalnya meminta AI secara otomatis memproses email, AI akan menganggap setiap email sebagai tugas independen untuk memahami, mengklasifikasikan, membalas, konsumsi Token巨大. Tetapi jika Anda pertama-tama meluangkan 30 detik melihat kotak masuk, manual menyaring email yang jelas tidak perlu diproses AI, lalu menyerahkan sisanya ke AI, biaya立刻turun ke一小部分dari aslinya. Daya penilaian manusia di sini bukan hambatan,而是filter yang paling好用.
Orang era telegram tahu, setiap kata tambahan harus bayar berapa, jadi mereka akan mempertimbangkan,这是一种intuisi persepsi terhadap sumber daya. Era AI也一样, ketika Anda benar-benar tahu每meminta AI berbicara satu kata lagi harus bayar berapa, Anda自然akan mempertimbangkan apakah hal ini layak dilakukan AI, tugas ini butuh model顶级atau model murah, konteks ini masih berguna atau tidak.
Pertimbangan ini, adalah kemampuan paling hemat. Era kekuatan komputasi semakin mahal, penggunaan paling pintar, bukan membuat AI menggantikan manusia,而是membuat AI dan manusia melakukan hal yang masing-masing kuasai. Ketika sensitivitas terhadap Token ini berinternalisasi menjadi refleks条件, Anda才benar-benar dari budak kekuatan komputasi, kembali menjadi tuan kekuatan komputasi.






