Penulis: Claude, Deep Tide TechFlow
Panduan Deep Tide: Tes terbaru dari The New York Times bersama perusahaan rintisan AI Oumi menunjukkan bahwa fitur Ringkasan AI (AI Overviews) pada Pencarian Google memiliki akurasi sekitar 91%. Namun, dengan skala Google yang memproses sekitar 5 triliun kueri pencarian per tahun, ini berarti setiap jamnya menghasilkan lebih dari 57 juta jawaban yang salah. Yang lebih rumit, bahkan ketika jawabannya benar, lebih dari setengah tautan rujukan tidak dapat mendukung kesimpulannya.
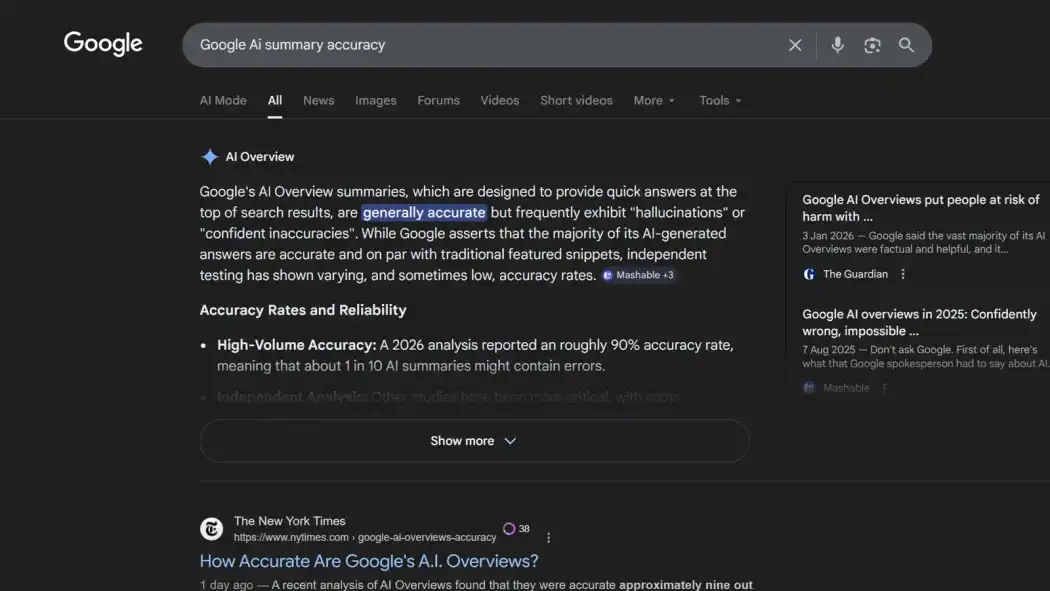
Google sedang mengirimkan informasi yang salah kepada pengguna dalam skala yang belum pernah terjadi sebelumnya, dan kebanyakan orang tidak menyadarinya.
Menurut laporan The New York Times, perusahaan rintisan AI Oumi yang ditugaskan oleh mereka, menggunakan tes standar industri SimpleQA yang dikembangkan oleh OpenAI untuk menilai keakuratan fitur AI Overviews milik Google. Tes ini mencakup 4326 kueri pencarian, dilakukan dalam dua putaran: pada Oktober tahun lalu (didukung Gemini 2) dan Februari tahun ini (setelah ditingkatkan ke Gemini 3). Hasilnya menunjukkan akurasi Gemini 2 sekitar 85%, dan meningkat menjadi 91% dengan Gemini 3.
Angka 91% terdengar baik, tetapi dalam skala Google, ceritanya menjadi berbeda. Google memproses sekitar 5 triliun kueri pencarian per tahun. Dengan tingkat kesalahan 9%, AI Overviews menghasilkan lebih dari 57 juta jawaban yang tidak akurat per jam, atau mendekati 1 juta per menit.
Jawaban Benar, Sumbernya Salah
Yang lebih mengkhawatirkan daripada akurasi adalah masalah 'lepasnya jangkar' pada sumber rujukan.
Data Oumi menunjukkan, pada era Gemini 2, 37% dari jawaban yang benar memiliki masalah 'rujukan tanpa dasar', yaitu tautan yang disertakan dalam ringkasan AI tidak mendukung informasi yang diberikan. Setelah peningkatan ke Gemini 3, persentase ini justru meningkat, melonjak menjadi 56%. Dengan kata lain, model ini semakin tidak bisa 'mengerjakan PR'-nya ketika memberikan jawaban yang benar.
Pertanyaan CEO Oumi Manos Koukoumidis tepat sasaran: "Bahkan jika jawabannya benar, bagaimana Anda tahu itu benar? Bagaimana Anda memverifikasinya?"
Banyaknya rujukan AI Overviews ke sumber berkualitas rendah memperburuk masalah ini. Oumi menemukan bahwa Facebook dan Reddit masing-masing adalah sumber rujukan kedua dan keempat terbanyak untuk AI Overviews. Dalam jawaban yang tidak akurat, Facebook dirujukan dengan frekuensi 7%, lebih tinggi daripada dalam jawaban akurat yang hanya 5%.
Sebuah Artikel Palsu dari Wartawan BBC, 'Meracuni' Sukses dalam 24 Jam
Cacat serius lainnya dari AI Overviews adalah sangat mudah dimanipulasi.
Seorang wartawan BBC menguji dengan sebuah artikel yang sengaja dibuat palsu. Kurang dari 24 jam, ringkasan AI Google menyajikan informasi palsu di dalamnya sebagai fakta kepada pengguna.
Ini berarti siapa pun yang memahami mekanisme kerja sistem dapat 'meracuni' hasil pencarian AI dengan menerbitkan konten palsu dan meningkatkan trafiknya. Tanggapan juru bicara Google Ned Adriance terhadap hal ini adalah bahwa fungsi AI pencarian dibangun di atas mekanisme peringkat dan keamanan yang sama yang digunakan untuk memblokir spam, dan menyebut bahwa "sebagian besar contoh dalam tes adalah kueri yang tidak realistis yang tidak akan dicari oleh orang secara nyata".
Bantahan Google: Tesnya Sendiri yang Bermasalah
Google mengajukan beberapa keberatan terhadap penelitian Oumi. Juru bicara Google menyatakan bahwa penelitian tersebut "memiliki kelemahan serius", dengan alasan termasuk: tolok ukur SimpleQA sendiri mengandung informasi yang tidak akurat; Oumi menggunakan model AI mereka sendiri, HallOumi, untuk menilai kinerja AI lain, yang mungkin memperkenalkan kesalahan tambahan; konten tes tidak mencerminkan perilaku pencarian pengguna yang sebenarnya.
Pengujian internal Google juga menunjukkan bahwa ketika Gemini 3 dijalankan secara independen di luar kerangka kerja Pencarian Google, proporsi keluaran yang salah (hallucination) mencapai 28%. Namun Google menekankan bahwa AI Overviews, dengan memanfaatkan sistem peringkat pencarian, berkinerja lebih baik dalam hal akurasi dibandingkan model itu sendiri.
Namun, seperti yang ditunjukkan oleh komentar PCMag mengenai paradoks logika ini: Jika alasan pembelaan Anda adalah "melaporkan bahwa AI kami tidak akurat juga menggunakan AI yang mungkin tidak akurat", ini恐怕 tidak mungkin meningkatkan kepercayaan pengguna terhadap keakuratan produk Anda. (Terjemahan catatan: "恐怕" dari teks asli dipertahankan sebagai "mungkin" karena konteksnya, tetapi frasa selanjutnya disesuaikan agar lebih natural: "ini mungkin tidak meningkatkan kepercayaan pengguna terhadap keakuratan produk Anda").





