Penulis: Li Hailun, Su Yang
Pada 6 Januari waktu Beijing, CEO NVIDIA Jensen Huang sekali lagi berdiri di panggung utama CES2026 dengan jakta kulit ikoniknya.
Pada CES 2025, NVIDIA memamerkan chip Blackwell yang diproduksi massal dan stack teknologi AI fisik yang lengkap. Dalam acara tersebut, Huang menekankan bahwa era 'AI Fisik' sedang dimulai. Dia menggambarkan masa depan yang penuh imajinasi: mobil otonom memiliki kemampuan bernalar, robot dapat memahami dan berpikir, AI Agent (agen cerdas) dapat menangani tugas konteks panjang dengan jutaan token.
Sekitar satu tahun telah berlalu, industri AI telah mengalami evolusi dan perubahan besar. Huang, dalam konferensi persnya, ketika meninjau perubahan tahun ini, secara khusus menyebutkan model sumber terbuka.
Dia mengatakan, model inferensi sumber terbuka seperti DeepSeek R1, membuat seluruh industri menyadari: ketika keterbukaan dan kolaborasi global benar-benar dimulai, penyebaran AI akan sangat cepat. Meskipun model sumber terbuka masih tertinggal sekitar enam bulan dalam hal kemampuan keseluruhan dibandingkan model paling mutakhir, mereka terus mengejar setiap enam bulan, dan jumlah unduhan serta penggunaannya telah mengalami pertumbuhan eksplosif.

Dibandingkan dengan tahun 2025 yang lebih banyak menunjukkan visi dan kemungkinan, kali ini NVIDIA mulai secara sistematis berharap memecahkan masalah 'bagaimana mewujudkannya': berpusat pada AI inferensi, melengkapi infrastruktur komputasi, jaringan, dan penyimpanan yang dibutuhkan untuk menjalankan jangka panjang, secara signifikan menekan biaya inferensi, dan menanamkan kemampuan ini langsung ke dalam skenario nyata seperti mobil otonom dan robot.
Pidato Huang di CES kali ini, dibangun di sekitar tiga garis besar:
● Pada tingkat sistem dan infrastruktur, NVIDIA merestrukturisasi arsitektur komputasi, jaringan, dan penyimpanan di sekitar kebutuhan inferensi jangka panjang. Dengan platform Rubin, NVLink 6, Spectrum-X Ethernet, dan platform penyimpanan memori konteks inferensi sebagai inti, pembaruan ini langsung menargetkan hambatan seperti biaya inferensi yang tinggi, konteks yang sulit dipertahankan, dan skalabilitas yang terbatas, memecahkan masalah AI agar dapat 'berpikir lebih lama', 'terjangkau secara komputasi', dan 'berjalan lebih lama'.
● Pada tingkat model, NVIDIA menempatkan AI inferensi (Reasoning / Agentic AI) pada posisi inti. Melalui model dan alat seperti Alpamayo, Nemotron, Cosmos Reason, mendorong AI dari 'menghasilkan konten' menuju kemampuan untuk terus berpikir, dari 'model yang merespons sekali' beralih ke 'agen cerdas yang dapat bekerja dalam jangka panjang'.
● Pada tingkat aplikasi dan implementasi, kemampuan ini diperkenalkan langsung ke dalam skenario AI fisik seperti mobil otonom dan robot. Baik sistem mobil otonom yang digerakkan oleh Alpamayo, maupun ekosistem robot GR00T dan Jetson, semuanya mendorong penyebaran skala besar melalui kerja sama dengan platform tingkat perusahaan dan penyedia cloud.

01 Dari Peta Jalan ke Produksi Massal: Rubin Ungkap Data Kinerja Lengkap untuk Pertama Kalinya
Pada CES kali ini, NVIDIA untuk pertama kalinya mengungkapkan detail teknis lengkap dari arsitektur Rubin.
Dalam pidatonya, Huang memulai dengan Test-time Scaling (Penskalaan Waktu Uji), konsep ini dapat dipahami sebagai, jika ingin AI menjadi lebih pintar, tidak hanya membuatnya 'belajar lebih giat', tetapi dengan 'berpikir lebih lama ketika menghadapi masalah'.
Di masa lalu, peningkatan kemampuan AI terutama bergantung pada tahap pelatihan dengan lebih banyak daya komputasi, membuat model semakin besar; sedangkan sekarang, perubahan baru adalah bahkan jika model tidak terus membesar, asalkan diberi lebih banyak waktu dan daya komputasi untuk berpikir setiap kali digunakan, hasilnya juga bisa menjadi jauh lebih baik.
Bagaimana membuat 'AI berpikir lebih lama' menjadi layak secara ekonomi? Platform komputasi AI generasi baru arsitektur Rubin hadir untuk memecahkan masalah ini.
Huang memperkenalkan, ini adalah一套 sistem komputasi AI generasi berikutnya yang lengkap, melalui desain bersama Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, Spectrum-6, untuk mencapai penurunan biaya inferensi yang revolusioner.

NVIDIA Rubin GPU adalah chip inti dalam arsitektur Rubin yang bertanggung jawab untuk komputasi AI, bertujuan untuk secara signifikan mengurangi biaya unit inferensi dan pelatihan.
Singkatnya, tugas inti Rubin GPU adalah 'membuat AI lebih hemat dan lebih pintar digunakan'.
Kemampuan inti Rubin GPU terletak pada: GPU yang sama dapat melakukan lebih banyak pekerjaan. Ia dapat memproses lebih banyak tugas inferensi sekaligus, mengingat konteks yang lebih panjang, dan komunikasi dengan GPU lain juga lebih cepat, yang berarti banyak skenario yang sebelumnya mengandalkan 'penumpukan multi-kartu keras', sekarang dapat diselesaikan dengan lebih sedikit GPU.
Hasilnya adalah, inferensi tidak hanya lebih cepat, tetapi juga jelas lebih murah.
Huang di tempat memberikan ulasan parameter keras NVL72 arsitektur Rubin: berisi 220 triliun transistor, bandwidth 260 TB/detik, merupakan platform pertama di industri yang mendukung komputasi kerahasiaan skala rak.

Secara keseluruhan, dibandingkan dengan Blackwell, Rubin GPU mencapai lompatan generasi dalam indikator kunci: Kinerja inferensi NVFP4 meningkat menjadi 50 PFLOPS (5 kali lipat), kinerja pelatihan meningkat menjadi 35 PFLOPS (3.5 kali lipat), bandwidth memori HBM4 meningkat menjadi 22 TB/s (2.8 kali lipat), bandwidth interkoneksi NVLink per GPU menjadi dua kali lipat menjadi 3.6 TB/s.
Peningkatan ini bekerja sama, memungkinkan satu GPU menangani lebih banyak tugas inferensi dan konteks yang lebih panjang, pada dasarnya mengurangi ketergantungan pada jumlah GPU.

Vera CPU adalah komponen inti yang dirancang khusus untuk perpindahan data dan pemrosesan Agentic, mengadopsi 88 inti Olympus yang dikembangkan sendiri oleh NVIDIA, dilengkapi dengan memori sistem 1.5 TB (3 kali lipat dari CPU Grace generasi sebelumnya), melalui teknologi NVLink-C2C 1.8 TB/s mencapai akses memori yang konsisten antara CPU dan GPU.
Berbeda dengan CPU tujuan umum tradisional, Vera berfokus pada penjadwalan data dan pemrosesan logika inferensi multi-langkah dalam skenario inferensi AI, pada dasarnya adalah koordinator sistem yang memungkinkan 'AI berpikir lebih lama' berjalan efisien.
NVLink 6 melalui bandwidth 3.6 TB/s dan kemampuan komputasi dalam jaringan, memungkinkan 72 GPU dalam arsitektur Rubin bekerja sama seperti satu super GPU, ini adalah infrastruktur kunci untuk mencapai pengurangan biaya inferensi.
Dengan demikian, data dan hasil antara yang dibutuhkan AI selama inferensi dapat dengan cepat beredar di antara GPU, tanpa harus menunggu, menyalin, atau menghitung ulang berulang kali.


Dalam arsitektur Rubin, NVLink-6 bertanggung jawab untuk komputasi bersama internal GPU, BlueField-4 bertanggung jawab untuk penjadwalan konteks dan data, sedangkan ConnectX-9 mengambil alih koneksi jaringan berkecepatan tinggi sistem ke luar. Ini memastikan sistem Rubin dapat berkomunikasi secara efisien dengan rak lain, pusat data, dan platform cloud, merupakan prasyarat untuk kelancaran menjalankan tugas pelatihan dan inferensi skala besar.
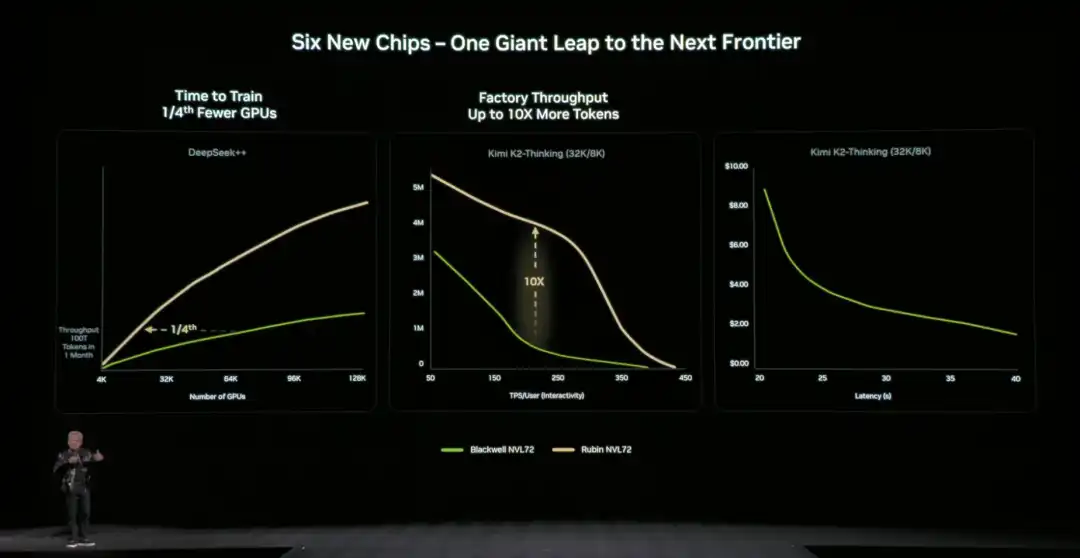
Dibandingkan dengan arsitektur generasi sebelumnya, NVIDIA juga memberikan data yang intuitif dan spesifik: Dibandingkan dengan platform NVIDIA Blackwell, dapat mengurangi biaya token pada tahap inferensi hingga 10 kali lipat, dan mengurangi jumlah GPU yang dibutuhkan untuk melatih model ahli campuran (MoE) menjadi 1/4 dari sebelumnya.
NVIDIA secara resmi menyatakan, saat ini Microsoft telah berkomitmen untuk menyebarkan ratusan ribu chip Vera Rubin di pabrik super AI Fairwater generasi berikutnya, penyedia layanan cloud seperti CoreWeave akan menyediakan instance Rubin pada paruh kedua tahun 2026, infrastruktur 'membuat AI berpikir lebih lama' ini sedang bergerak dari demonstrasi teknologi menuju komersialisasi skala besar.

02 Bagaimana 'Hambatan Penyimpanan' Dipecahkan?
Membuat AI 'berpikir lebih lama' juga menghadapi tantangan teknis kunci: di mana data konteks harus disimpan?
Ketika AI menangani tugas kompleks yang membutuhkan percakapan multi-putaran, inferensi multi-langkah, akan menghasilkan sejumlah besar data konteks (KV Cache). Arsitektur tradisional要么 memasukkannya ke dalam memori GPU yang mahal dan kapasitasnya terbatas,要么 meletakkannya di penyimpanan biasa (akses terlalu lambat). 'Hambatan penyimpanan' ini jika tidak dipecahkan, GPU sekuat apa pun akan terbebani.
Menanggapi masalah ini, NVIDIA pada CES kali ini untuk pertama kalinya mengungkapkan secara lengkap platform penyimpanan memori konteks inferensi (Inference Context Memory Storage Platform) yang digerakkan oleh BlueField-4, tujuan intinya adalah menciptakan 'lapisan ketiga' antara memori GPU dan penyimpanan tradisional. Cukup cepat, memiliki kapasitas yang memadai, dan dapat mendukung operasi jangka panjang AI.
Dari sudut pandang realisasi teknis, platform ini bukanlah komponen tunggal yang berperan, tetapi merupakan hasil desain bersama:
- BlueField-4 bertanggung jawab untuk mempercepat manajemen dan akses data konteks pada tingkat perangkat keras, mengurangi pemindahan data dan overhead sistem;
- Spectrum-X Ethernet menyediakan jaringan berkinerja tinggi, mendukung berbagi data berkecepatan tinggi berbasis RDMA;
- Komponen perangkat lunak seperti DOCA, NIXL, dan Dynamo, bertanggung jawab untuk mengoptimalkan penjadwalan pada tingkat sistem, mengurangi latensi, meningkatkan throughput keseluruhan.
Kita dapat memahami, cara platform ini adalah, memperluas data konteks yang sebelumnya hanya dapat disimpan di memori GPU, ke 'lapisan memori' independen, berkecepatan tinggi, dan dapat dibagikan. Di satu sisi melepaskan tekanan GPU, di sisi lain dapat dengan cepat berbagi informasi konteks ini di antara beberapa node, beberapa agen cerdas AI.
Dalam hal efek aktual, data yang diberikan oleh NVIDIA resmi adalah: Dalam skenario tertentu, cara ini dapat meningkatkan jumlah token yang diproses per detik hingga 5 kali lipat, dan mencapai optimasi efisiensi energi yang setara.
Huang dalam rilisnya berulang kali menekankan, AI sedang berevolusi dari 'chatbot percakapan sekali pakai menjadi kolaborator cerdas yang sebenarnya: mereka perlu memahami dunia nyata, terus bernalar, memanggil alat untuk menyelesaikan tugas, dan sekaligus mempertahankan memori jangka pendek dan jangka panjang. Ini adalah karakteristik inti dari Agentic AI. Platform penyimpanan memori konteks inferensi, dirancang khusus untuk bentuk AI yang berjalan jangka panjang, berpikir berulang kali, melalui perluasan kapasitas konteks, mempercepat berbagi antar node, membuat percakapan multi-putaran dan kolaborasi multi-agen cerdas lebih stabil, tidak 'semakin lambat saat dijalankan'.

03 DGX SuperPOD Generasi Baru: Mendorong 576 GPU Bekerja Sama
NVIDIA pada CES kali ini mengumumkan peluncuran DGX SuperPOD (simpul super) generasi baru berbasis arsitektur Rubin, memperluas Rubin dari rak tunggal ke solusi lengkap seluruh pusat data.
Apa itu DGX SuperPOD?
Jika Rubin NVL72 adalah 'rak super' yang berisi 72 GPU, maka DGX SuperPOD adalah menghubungkan beberapa rak seperti itu bersama-sama, membentuk cluster komputasi AI yang lebih besar. Versi yang dirilis kali ini terdiri dari 8 rak Vera Rubin NVL72, setara dengan 576 GPU yang bekerja sama.
Ketika skala tugas AI terus meluas, 576 GPU rak tunggal mungkin masih belum cukup. Misalnya melatih model skala sangat besar, melayani ribuan agen cerdas Agentic AI secara bersamaan, atau menangani tugas kompleks yang membutuhkan konteks jutaan token. Saat itulah dibutuhkan kerja sama multi-rak, dan DGX SuperPOD dirancang untuk skenario ini sebagai solusi standar.
Bagi perusahaan dan penyedia layanan cloud, DGX SuperPOD menyediakan solusi infrastruktur AI skala besar 'siap pakai'. Tidak perlu meneliti sendiri bagaimana menghubungkan ratusan GPU, bagaimana mengkonfigurasi jaringan, bagaimana mengelola penyimpanan, dll.
Lima komponen inti DGX SuperPOD generasi baru:
○ 8 rak Vera Rubin NVL72 - menyediakan inti kemampuan komputasi, setiap rak 72 GPU, total 576 GPU;
○ Jaringan ekspansi NVLink 6 - memungkinkan 576 GPU dalam 8 rak ini bekerja sama seperti satu super GPU raksasa;
○ Jaringan ekspansi Spectrum-X Ethernet - menghubungkan SuperPOD yang berbeda, serta terhubung ke penyimpanan dan jaringan eksternal;
○ Platform penyimpanan memori konteks inferensi - menyediakan penyimpanan data konteks bersama untuk tugas inferensi jangka panjang;
○ Perangkat lunak NVIDIA Mission Control - mengelola penjadwalan, pemantauan, dan optimasi seluruh sistem.
Kali ini peningkatan, dasar SuperPOD berinti pada sistem tingkat rak DGX Vera Rubin NVL72. Setiap NVL72 sendiri adalah superkomputer AI lengkap, di dalamnya melalui NVLink 6 menghubungkan 72 GPU Rubin bersama-sama, dapat menyelesaikan tugas inferensi dan pelatihan skala besar dalam satu rak. DGX SuperPOD baru, terdiri dari beberapa NVL72, membentuk cluster tingkat sistem yang dapat berjalan jangka panjang.
Ketika skala komputasi berkembang dari 'rak tunggal' ke 'multi-rak', hambatan baru muncul: bagaimana mentransmisikan data dalam jumlah besar antar rak dengan stabil dan efisien. Terkait masalah ini, NVIDIA pada CES kali ini secara bersamaan merilis switch Ethernet generasi baru berbasis chip Spectrum-6, dan untuk pertama kalinya memperkenalkan teknologi 'Co-Packaged Optics' (CPO).
Secara sederhana, ini adalah memasang modul optik yang sebelumnya dapat dipasang langsung di samping chip switch, mempersingkat jarak transmisi sinyal dari beberapa meter menjadi beberapa milimeter, sehingga secara signifikan mengurangi konsumsi daya dan latensi, juga meningkatkan stabilitas keseluruhan sistem.
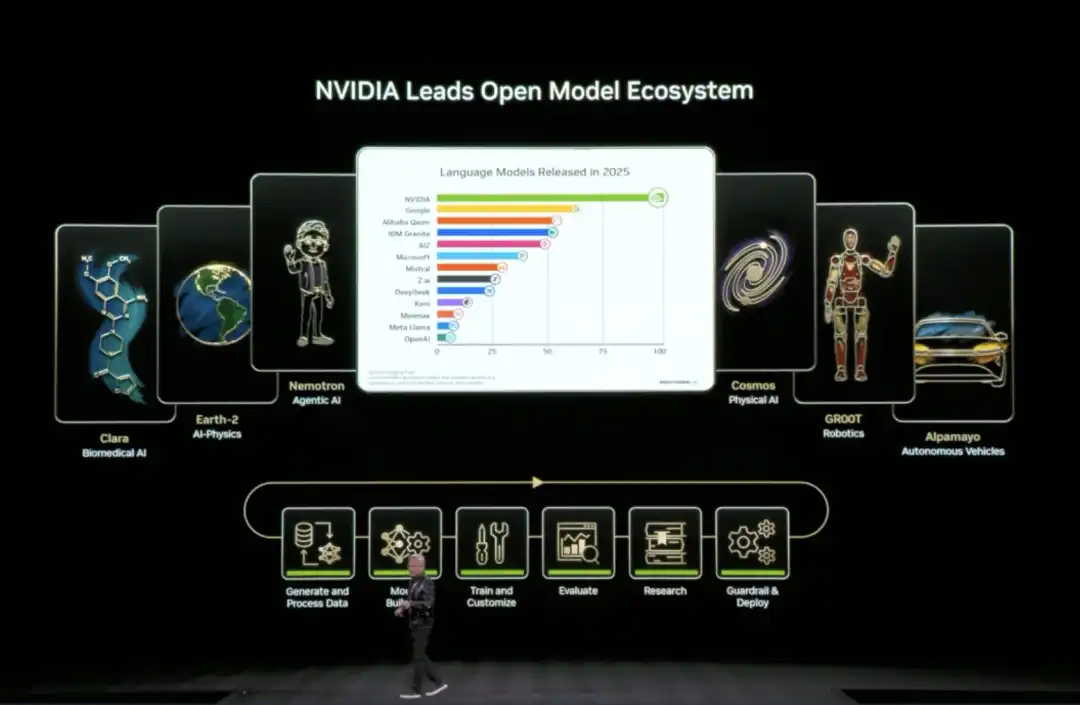
04 'Paket Lengkap' Sumber Terbuka AI NVIDIA: Lengkap dari Data ke Kode
Pada CES kali ini, Huang mengumumkan perluasan ekosistem model sumber terbuka (Open Model Universe), menambahkan dan memperbarui serangkaian model, kumpulan data, repositori kode, dan alat. Ekosistem ini mencakup enam bidang: AI biomedis (Clara), simulasi fisika AI (Earth-2), Agentic AI (Nemotron), AI fisik (Cosmos), robotika (GR00T) dan mobil otonom (Alpamayo).
Melatih model AI tidak hanya membutuhkan daya komputasi, tetapi juga membutuhkan kumpulan data berkualitas tinggi, model pra-latihan, kode pelatihan, alat evaluasi, dan整套 infrastruktur. Bagi kebanyakan perusahaan dan lembaga penelitian, membangun ini dari awal terlalu memakan waktu.
Secara spesifik, NVIDIA membuka sumber enam tingkat konten: platform komputasi (DGX, HGX, dll.), kumpulan data pelatihan di berbagai bidang, model dasar pra-latihan, repositori kode inferensi dan pelatihan, skrip alur pelatihan lengkap, dan templat solusi ujung ke ujung.
Seri Nemotron adalah fokus pembaruan kali ini, mencakup empat arah aplikasi.
Dalam arah inferensi, termasuk model inferensi kecil seperti Nemotron 3 Nano, Nemotron 2 Nano VL, serta alat pelatihan pembelajaran penguatan seperti NeMo RL, NeMo Gym. Dalam arah RAG (Retrieval Augmented Generation), menyediakan Nemotron Embed VL (model embedding vektor), Nemotron Rerank VL (model pengurutan ulang), kumpulan data terkait dan NeMo Retriever Library (pustaka pengambilan). Dalam arah keamanan, ada model keamanan konten Nemotron Content Safety dan kumpulan data pendamping, pustaka pagar NeMo Guardrails.
Dalam arah suara, berisi pengenalan suara otomatis Nemotron ASR, kumpulan data suara Granary Dataset dan pustaka pemrosesan suara NeMo Library. Ini berarti perusahaan ingin membuat sistem layanan pelanggan AI dengan RAG, tidak perlu melatih model embedding dan pengurutan ulang sendiri, dapat langsung menggunakan kode yang sudah dilatih dan dibuka sumber oleh NVIDIA.
05 Bidang AI Fisik, Menuju Implementasi Komersial
Bidang AI fisik juga memiliki pembaruan model - Cosmos untuk memahami dan menghasilkan video dunia fisik, model dasar robot umum Isaac GR00T, model visi-bahasa-aksi mobil otonom Alpamayo.

Huang di CES menyatakan, 'momen ChatGPT' AI fisik akan segera tiba, tetapi menghadapi banyak tantangan: dunia fisik terlalu kompleks dan berubah, mengumpulkan data nyata lambat dan mahal, selamanya tidak cukup.
Bagaimana solusinya? Data sintetis adalah salah satu jalannya. Maka NVIDIA meluncurkan Cosmos.
Ini adalah model dasar dunia AI fisik sumber terbuka, saat ini telah menggunakan sejumlah besar video, data mengemudi dan robotika nyata, serta simulasi 3D untuk pra-latihan. Ia dapat memahami bagaimana dunia beroperasi, dapat menghubungkan bahasa, gambar, 3D, dan aksi.
Huang menyatakan, Cosmos dapat mewujudkan banyak keterampilan AI fisik, seperti menghasilkan konten, melakukan inferensi, memprediksi lintasan (bahkan hanya memberinya satu gambar). Ia dapat menghasilkan video yang realistis berdasarkan adegan 3D, menghasilkan gerakan yang sesuai dengan hukum fisika berdasarkan data mengemudi, juga dapat menghasilkan video panorama dari simulator, gambar multi-kamera atau deskripsi teks. Bahkan skenario langka, juga dapat direkonstruksi.
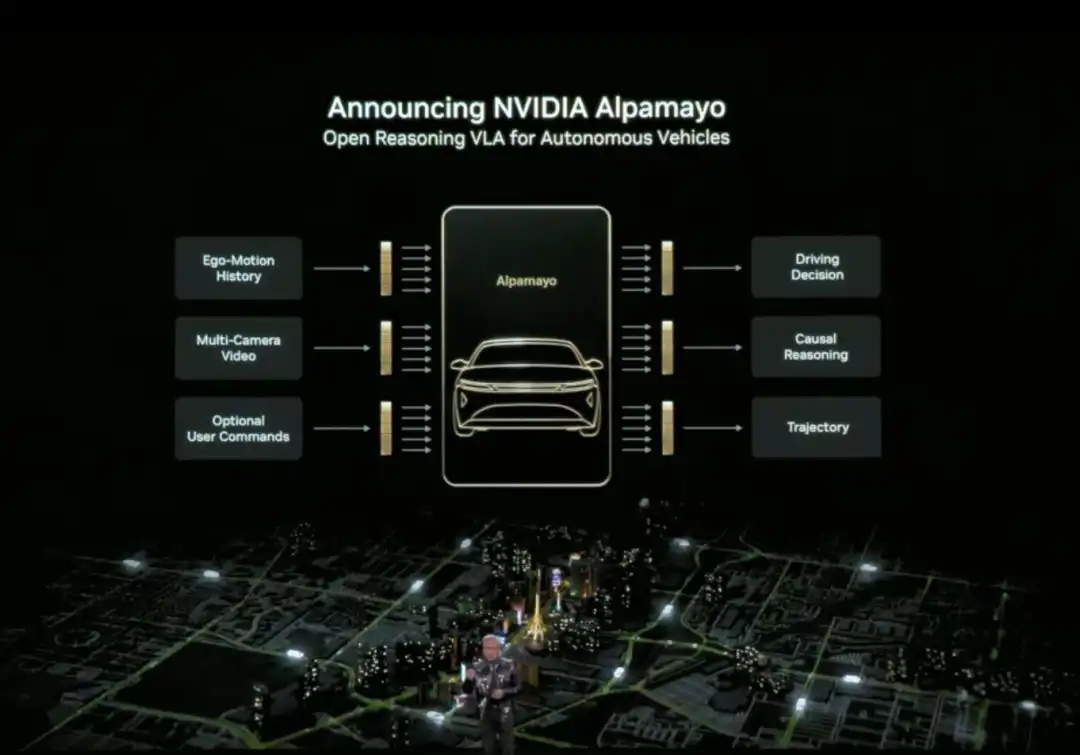
Huang juga secara resmi merilis Alpamayo. Alpamayo adalah rantai alat sumber terbuka untuk bidang mobil otonom, juga merupakan model inferensi visi-bahasa-aksi (VLA) sumber terbuka pertama. Berbeda dengan sebelumnya yang hanya membuka sumber kode, NVIDIA kali ini membuka sumber daya pengembangan lengkap dari data hingga penyebaran.
Terobosan terbesar Alpamayo terletak pada kenyataan bahwa itu adalah model mobil otonom 'tipe inferensi'. Sistem mobil otonom tradisional adalah arsitektur saluran pipa 'persepsi-perencanaan-kontrol', melihat lampu merah lalu mengerem, melihat pejalan kaki lalu melambat, mengikuti aturan yang telah ditetapkan. Sedangkan Alpamayo memperkenalkan kemampuan 'inferensi', memahami hubungan sebab-akibat dalam skenario kompleks, memprediksi niat kendaraan dan pejalan kaki lain, bahkan dapat menangani keputusan yang membutuhkan pemikiran multi-langkah.
Misalnya di persimpangan, ia tidak hanya mengidentifikasi 'ada mobil di depan', tetapi dapat menyimpulkan 'mobil itu mungkin akan belok kiri, jadi saya harus menunggunya lewat dulu'. Kemampuan ini membuat mobil otonom meningkat dari 'berkendara sesuai aturan' ke 'berpikir seperti manusia'.
Huang mengumumkan sistem NVIDIA DRIVE secara resmi memasuki tahap produksi massal, aplikasi pertama adalah Mercedes-Benz CLA baru, rencananya akan diluncurkan di AS pada tahun 2026. Mobil ini akan dilengkapi dengan sistem mengemudi otonom level L2++, mengadopsi arsitektur hybrid 'model AI ujung ke ujung + saluran pipa tradisional'.
Bidang robotika juga memiliki kemajuan substantif.
Huang menyatakan termasuk Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics dan XRlabs在内的 perusahaan robotika terkemuka global, sedang mengembangkan produk berdasarkan platform Isaac NVIDIA dan model dasar GR00T, mencakup berbagai bidang dari robot industri, robot bedah hingga robot humanoid, robot konsumen.

Di lokasi konferensi pers, di belakang Huang berdiri penuh dengan robot berbagai bentuk dan kegunaan, mereka dipajang secara terkonsentrasi di panggung berlapis: dari robot humanoid, robot layanan berkaki dua dan beroda, hingga lengan robot industri, mesin teknik, drone dan peralatan bantu bedah, menampilkan 'gambaran ekosistem robotika'.
Dari aplikasi AI fisik ke platform komputasi RubinAI,再到 platform penyimpanan memori konteks inferensi dan 'paket lengkap' AI sumber terbuka.
Tindakan yang ditampilkan NVIDIA di CES ini, membentuk narasi NVIDIA untuk infrastruktur AI era inferensi. Seperti yang ditekankan Huang berulang kali, ketika AI fisik perlu terus berpikir, berjalan jangka panjang, dan benar-benar memasuki dunia nyata, masalahnya tidak lagi hanya apakah daya komputasi cukup, tetapi siapa yang dapat benar-benar membangun整套 sistem.
CES 2026, NVIDIA telah memberikan jawaban.