
Penulis | ZeR0 骏达, Zhidongxi
Editor | Moying
Laporan dari Las Vegas, 5 Januari - Baru saja, pendiri dan CEO NVIDIA Huang Renxun menyampaikan pidato utama pertamanya di tahun 2026 pada Consumer Electronics Show (CES) 2026. Dengan jaket kulit khasnya, Huang mengumumkan 8 rilis penting dalam waktu 1,5 jam, mencakup chip, rak, hingga desain jaringan, memberikan penjelasan mendalam tentang platform generasi baru.
Di bidang komputasi akselerasi dan infrastruktur AI, NVIDIA meluncurkan Superkomputer AI NVIDIA Vera Rubin POD, Perangkat Optik Kemasan Bersama Ethernet NVIDIA Spectrum-X, Platform Penyimpanan Memori Konteks Inference NVIDIA, dan NVIDIA DGX SuperPOD berbasis DGX Vera Rubin NVL72.

NVIDIA Vera Rubin POD menggunakan 6 chip buatan sendiri NVIDIA, mencakup CPU, GPU, Scale-up, Scale-out, penyimpanan, dan kemampuan pemrosesan, semua bagian dirancang secara kolaboratif untuk memenuhi kebutuhan model canggih dan mengurangi biaya komputasi.
Vera CPU menggunakan arsitektur inti Olympus khusus, Rubin GPU memperkenalkan mesin Transformer dengan kinerja inference NBFP4 hingga 50 PFLOPS, bandwidth NVLink per GPU hingga 3.6 TB/s, mendukung komputasi rahasia universal generasi ketiga (TEE tingkat rak pertama), mewujudkan lingkungan eksekusi tepercaya lengkap lintas domain CPU dan GPU.

Chip-chip ini telah kembali dari fabrikasi, NVIDIA telah memvalidasi seluruh sistem NVIDIA Vera Rubin NVL72, mitra juga telah menjalankan model dan algoritma AI internal terintegrasi mereka, seluruh ekosistem bersiap untuk penerapan Vera Rubin.
Dalam rilis lainnya, Perangkat Optik Kemasan Bersama Ethernet NVIDIA Spectrum-X secara signifikan mengoptimalkan efisiensi daya dan waktu aktif aplikasi; Platform Penyimpanan Memori Konteks Inference NVIDIA mendefinisikan ulang tumpukan penyimpanan untuk mengurangi komputasi berulang dan meningkatkan efisiensi inference; NVIDIA DGX SuperPOD berbasis DGX Vera Rubin NVL72 mengurangi biaya token model MoE besar hingga 1/10.

Untuk model terbuka, NVIDIA mengumumkan perluasan keluarga model open-source, merilis model, dataset, dan pustaka baru, termasuk seri model open-source NVIDIA Nemotron yang menambahkan model Agentic RAG, model keamanan, model suara, serta merilis model terbuka baru untuk semua jenis robot. Namun, Huang Renxun tidak menjelaskan secara detail dalam pidatonya.
Untuk Fisika AI, momen ChatGPT untuk Fisika AI telah tiba, teknologi full-stack NVIDIA memungkinkan ekosistem global mengubah industri melalui teknologi robotik yang digerakkan AI; perpustakaan alat AI NVIDIA yang luas, termasuk kombinasi model open-source Alpamayo baru, memungkinkan industri transportasi global dengan cepat mewujudkan mengemudi L4 yang aman; Platform Otonom NVIDIA DRIVE kini diproduksi, dipasang di semua Mercedes-Benz CLA baru, untuk mengemudi yang ditentukan AI L2++.

01. Superkomputer AI Baru: 6 Chip Buatan Sendiri, Kinerja Komputasi per Rak Mencapai 3.6 EFLOPS
Huang Renxun percaya, setiap 10 hingga 15 tahun, industri komputer mengalami pembaruan menyeluruh, tetapi kali ini, dua transformasi platform terjadi bersamaan, dari CPU ke GPU, dari "pemrograman perangkat lunak" ke "pelatihan perangkat lunak", komputasi akselerasi dan AI membangun ulang seluruh tumpukan komputasi. Industri komputasi senilai $10 triliun dalam dekade terakhir sedang mengalami modernisasi.
Secara bersamaan, permintaan akan daya komputasi juga melonjak drastis. Ukuran model tumbuh 10 kali lipat per tahun, jumlah token yang digunakan model untuk berpikir tumbuh 5 kali lipat per tahun, sementara harga per token turun 10 kali lipat per tahun.
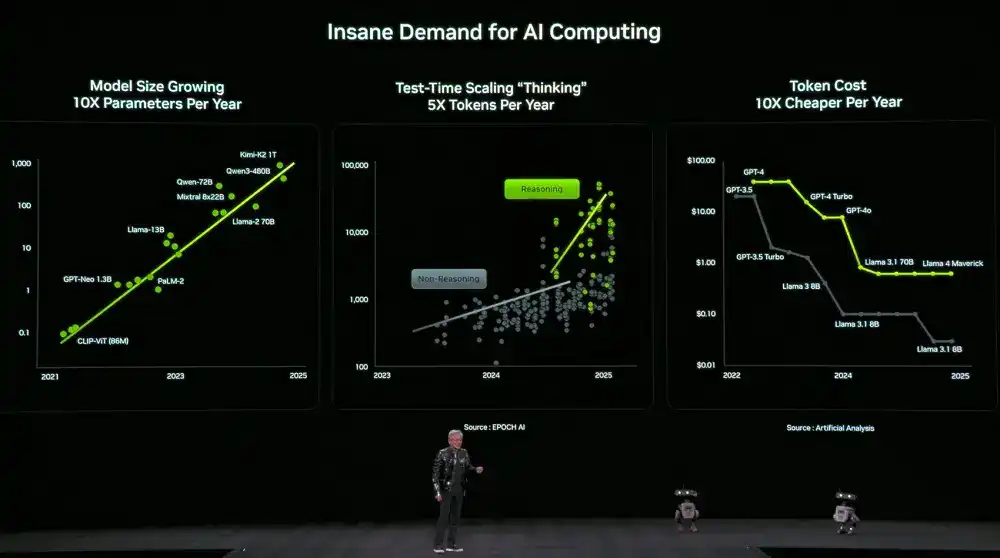
Untuk memenuhi permintaan ini, NVIDIA memutuskan untuk merilis perangkat keras komputasi baru setiap tahun. Huang Renxun mengungkapkan, saat ini Vera Rubin juga telah memulai produksi penuh.
Superkomputer AI baru NVIDIA, NVIDIA Vera Rubin POD, menggunakan 6 chip buatan sendiri: Vera CPU, Rubin GPU, NVLink 6 Switch, Kartu Jaringan Cerdas ConnectX-9 (CX9), BlueField-4 DPU, Spectrum-X 102.4T CPO.
Vera CPU: Dirancang untuk pergerakan data dan pemrosesan agen, memiliki 88 inti Olympus khusus NVIDIA, 176 thread multithreading spasial NVIDIA, 1.8 TB/s NVLink-C2C mendukung memori terpadu CPU:GPU, memori sistem mencapai 1.5 TB (3 kali lipat Grace CPU), bandwidth memori SOCAMM LPDDR5X adalah 1.2 TB/s, dan mendukung komputasi rahasia tingkat rak, meningkatkan kinerja pemrosesan data dua kali lipat.

Rubin GPU: Memperkenalkan mesin Transformer, kinerja inference NVFP4 mencapai 50 PFLOPS, 5 kali lipat GPU Blackwell, kompatibel ke belakang, meningkatkan kinerja tingkat BF16/FP4 sambil mempertahankan akurasi inference; kinerja pelatihan NVFP4 mencapai 35 PFLOPS, 3.5 kali lipat Blackwell.
Rubin juga platform pertama yang mendukung HBM4, bandwidth HBM4 mencapai 22 TB/s, 2.8 kali lipat generasi sebelumnya, mampu memberikan kinerja yang dibutuhkan untuk model MoE yang menuntut dan beban kerja AI.

NVLink 6 Switch: Laju per lane ditingkatkan menjadi 400 Gbps, menggunakan teknologi SerDes untuk transmisi sinyal kecepatan tinggi; setiap GPU dapat mencapai bandwidth komunikasi interkoneksi penuh 3.6 TB/s, 2 kali lipat generasi sebelumnya, bandwidth total 28.8 TB/s, kinerja komputasi in-network pada presisi FP8 mencapai 14.4 TFLOPS, mendukung pendinginan cair 100%.

NVIDIA ConnectX-9 SuperNIC: Memberikan bandwidth 1.6 Tb/s per GPU, dioptimalkan untuk AI skala besar, memiliki jalur data yang sepenuhnya terdefinisi perangkat lunak, dapat diprogram, dan dipercepat.

NVIDIA BlueField-4: DPU 800 Gbps, digunakan untuk kartu jaringan cerdas dan prosesor penyimpanan, dilengkapi dengan 64 inti Grace CPU, dikombinasikan dengan ConnectX-9 SuperNIC, untuk meng-offload tugas komputasi terkait jaringan dan penyimpanan, sekaligus meningkatkan kemampuan keamanan jaringan, kinerja komputasi 6 kali lipat generasi sebelumnya, bandwidth memori 3 kali lipat, kecepatan akses GPU ke penyimpanan data meningkat 2 kali lipat.

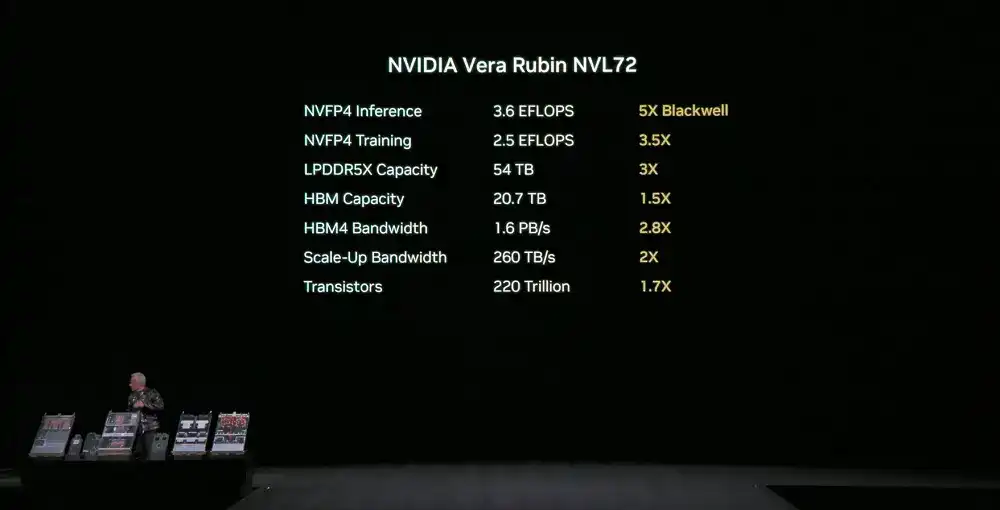
NVIDIA Vera Rubin NVL72: Pada tingkat sistem, mengintegrasikan semua komponen di atas menjadi sistem pemrosesan rak tunggal, memiliki 2 triliun transistor, kinerja inference NVFP4 mencapai 3.6 EFLOPS, kinerja pelatihan NVFP4 mencapai 2.5 EFLOPS.
Sistem ini memiliki kapasitas memori LPDDR5X 54 TB, 2.5 kali lipat generasi sebelumnya; total memori HBM4 20.7 TB, 1.5 kali lipat generasi sebelumnya; bandwidth HBM4 adalah 1.6 PB/s, 2.8 kali lipat generasi sebelumnya; total bandwidth scale-up mencapai 260 TB/s, melebihi skala bandwidth internet global total.
Sistem ini berbasis desain rak MGX generasi ketiga, baki komputasi menggunakan desain modular, tanpa host, tanpa kabel, tanpa kipas, membuat perakitan dan pemeliharaan 18 kali lebih cepat dari GB200. Perakitan yang sebelumnya membutuhkan 2 jam, kini hanya sekitar 5 menit, sementara sistem sebelumnya menggunakan sekitar 80% pendinginan cair, saat ini 100% menggunakan pendinginan cair. Sistem tunggal sendiri beratnya 2 ton, dan dengan cairan pendingin bisa mencapai 2,5 ton.

Baki NVLink Switch dapat mencapai pemeliharaan zero-downtime dan toleransi kesalahan, rak tetap dapat beroperasi saat baki dilepas atau sebagian diterapkan. Mesin RAS generasi kedua dapat melakukan pemeriksaan kesehatan zero-downtime.
Fitur-fitur ini meningkatkan waktu aktif sistem dan throughput, lebih lanjut mengurangi biaya pelatihan dan inference, memenuhi persyaratan keandalan dan pemeliharaan tinggi pusat data.
Lebih dari 80 mitra MGX telah siap mendukung penerapan Rubin NVL72 dalam jaringan hyperscale.
02. Tiga Produk Baru Meningkatkan Efisiensi Inference AI: Perangkat CPO Baru, Lapisan Penyimpanan Konteks Baru, DGX SuperPOD Baru
Secara bersamaan, NVIDIA merilis 3 produk penting: Perangkat Optik Kemasan Bersama Ethernet NVIDIA Spectrum-X, Platform Penyimpanan Memori Konteks Inference NVIDIA, dan NVIDIA DGX SuperPOD berbasis DGX Vera Rubin NVL72.
1. Perangkat Optik Kemasan Bersama Ethernet NVIDIA Spectrum-X
Perangkat Optik Kemasan Bersama Ethernet NVIDIA Spectrum-X berbasis arsitektur Spectrum-X, menggunakan desain 2 chip, menggunakan SerDes 200 Gbps, setiap ASIC dapat memberikan bandwidth 102.4 Tb/s.
Platform switching ini termasuk sistem kepadatan tinggi 512 port, serta sistem kompak 128 port, setiap port memiliki kecepatan 800 Gb/s.

Sistem switching CPO (Co-Packaged Optics) dapat mencapai peningkatan efisiensi energi 5 kali lipat, peningkatan keandalan 10 kali lipat, peningkatan waktu aktif aplikasi 5 kali lipat.
Ini berarti lebih banyak token dapat diproses setiap hari, sehingga lebih lanjut mengurangi total biaya kepemilikan (TCO) pusat data.
2. Platform Penyimpanan Memori Konteks Inference NVIDIA
Platform Penyimpanan Memori Konteks Inference NVIDIA adalah infrastruktur penyimpanan AI-native tingkat POD, digunakan untuk menyimpan KV Cache, berbasis akselerasi BlueField-4 dan Spectrum-X Ethernet, terikat erat dengan NVIDIA Dynamo dan NVLink, mewujudkan penjadwalan konteks kolaboratif antara memori, penyimpanan, dan jaringan.
Platform ini memperlakukan konteks sebagai tipe data utama, dapat mencapai kinerja inference 5 kali lipat, efisiensi energi 5 kali lipat lebih baik.

Ini sangat penting untuk meningkatkan aplikasi konteks panjang seperti percakapan multi-ronde, RAG, inference multi-langkah Agentic, beban kerja ini sangat bergantung pada kemampuan konteks untuk disimpan, digunakan kembali, dan dibagikan secara efisien di seluruh sistem.
AI sedang berevolusi dari chatbot menjadi AI Agentic (agen cerdas), yang dapat bernalar, memanggil alat, dan mempertahankan status jangka panjang, jendela konteks telah diperluas hingga jutaan token. Konteks ini disimpan dalam KV Cache, menghitung ulang setiap langkah akan membuang waktu GPU dan menyebabkan latensi besar, sehingga perlu disimpan.
Namun memori GPU cepat tetapi langka, penyimpanan jaringan tradisional terlalu tidak efisien untuk konteks jangka pendek. Hambatan inference AI sedang bergeser dari komputasi ke penyimpanan konteks. Jadi diperlukan lapisan memori baru yang dioptimalkan untuk inference, berada di antara GPU dan penyimpanan.

Lapisan ini bukan lagi tambalan, tetapi harus dirancang bersama dengan penyimpanan jaringan, untuk memindahkan data konteks dengan overhead terendah.
Sebagai tingkat penyimpanan baru, Platform Penyimpanan Memori Konteks Inference NVIDIA tidak langsung ada dalam sistem host, tetapi terhubung melalui BlueField-4 di luar perangkat komputasi. Keuntungan utamanya adalah dapat memperluas skala kolam penyimpanan secara lebih efisien, sehingga menghindari komputasi berulang KV Cache.
NVIDIA bekerja sama erat dengan mitra penyimpanan untuk membawa Platform Penyimpanan Memori Konteks Inference NVIDIA ke platform Rubin, memungkinkan pelanggan menerapkannya sebagai bagian dari infrastruktur AI terintegrasi lengkap.
3. NVIDIA DGX SuperPOD Dibangun di atas Vera Rubin
Pada tingkat sistem, NVIDIA DGX SuperPOD berfungsi sebagai cetak biru penerapan pabrik AI skala besar, menggunakan 8 sistem DGX Vera Rubin NVL72, dengan jaringan scale-up NVLink 6, jaringan scale-out Ethernet Spectrum-X, dilengkapi Platform Penyimpanan Memori Konteks Inference NVIDIA, dan divalidasi secara teknis.
Seluruh sistem dikelola oleh perangkat lunak NVIDIA Mission Control, mewujudkan efisiensi tertinggi. Pelanggan dapat menerapkannya sebagai platform turnkey, menyelesaikan tugas pelatihan dan inference dengan lebih sedikit GPU.
Berkat desain kolaboratif tertinggi pada 6 chip, baki, rak, Pod, pusat data, dan perangkat lunak, platform Rubin mencapai penurunan biaya pelatihan dan inference yang signifikan. Dibandingkan dengan generasi sebelumnya Blackwell, untuk melatih model MoE dengan skala yang sama, hanya membutuhkan 1/4 jumlah GPU; pada latensi yang sama, biaya token model MoE besar berkurang hingga 1/10.
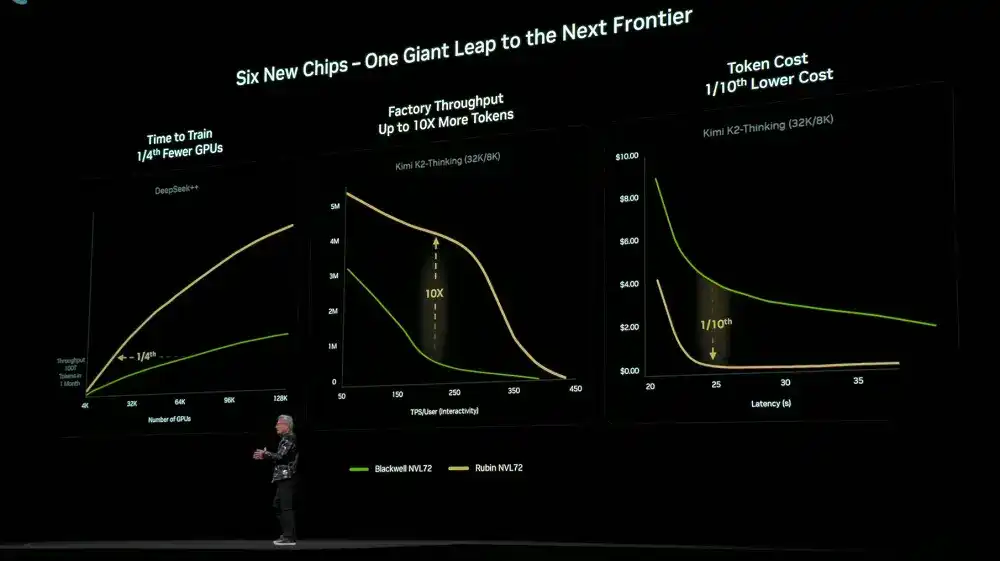
NVIDIA DGX SuperPOD menggunakan sistem DGX Rubin NVL8 juga diumumkan.
Dengan arsitektur Vera Rubin, NVIDIA bersama mitra dan pelanggan, membangun sistem AI terbesar, paling canggih, dan berbiaya terendah di dunia, mempercepat adopsi utama AI.

Infrastruktur Rubin akan tersedia melalui CSP dan integrator sistem pada paruh kedua tahun ini, dengan Microsoft dll menjadi yang pertama menerapkan.
03. Alam Semesta Model Terbuka Diperluas: Kontributor Penting untuk Model, Data, Ekosistem Sumber Terbuka Baru
Pada tingkat perangkat lunak dan model, NVIDIA terus meningkatkan investasi sumber terbuka.
Platform pengembangan utama seperti OpenRouter menunjukkan, dalam setahun terakhir, penggunaan model AI tumbuh 20 kali lipat, dengan sekitar 1/4 token berasal dari model sumber terbuka.
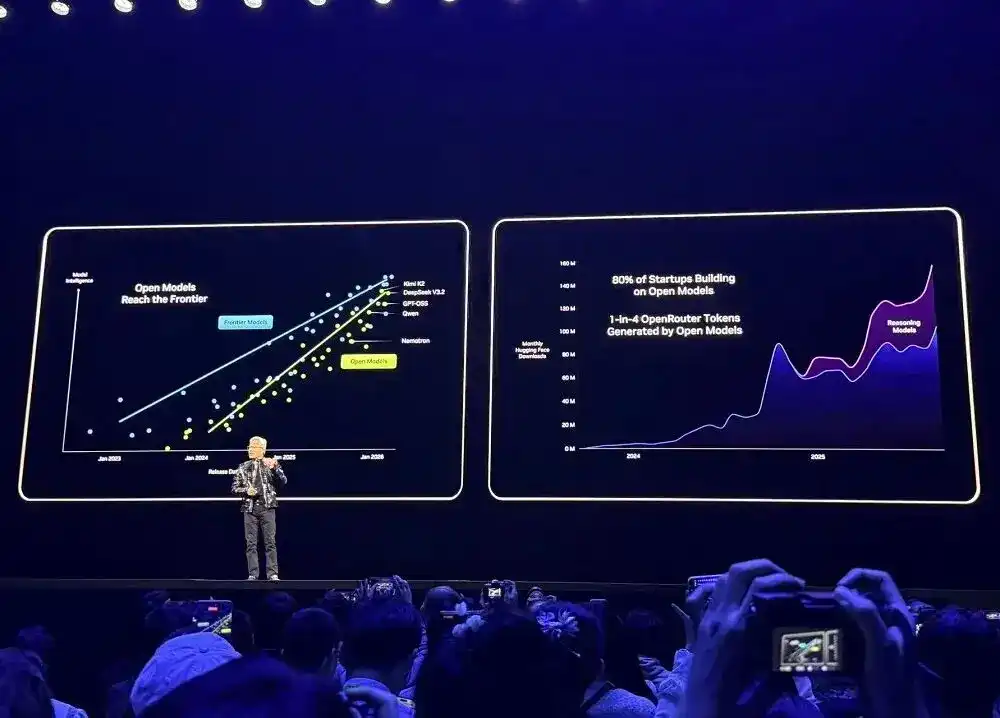
Pada tahun 2025, NVIDIA adalah kontributor terbesar untuk model, data, dan resep sumber terbuka di Hugging Face, merilis 650 model sumber terbuka dan 250 dataset sumber terbuka.

Model sumber terbuka NVIDIA menempati peringkat teratas dalam berbagai bagan peringkat. Pengembang tidak hanya dapat menggunakan model sumber terbuka ini, tetapi juga belajar darinya, terus melatih, memperluas dataset, dan menggunakan alat dan teknik terdokumentasi sumber terbuka untuk membangun sistem AI.

Terinspirasi oleh Perplexity, Huang Renxun mengamati bahwa Agen harus multi-model, multi-cloud, dan hybrid cloud, ini juga merupakan arsitektur dasar sistem AI Agentic, yang diadopsi oleh hampir semua startup.
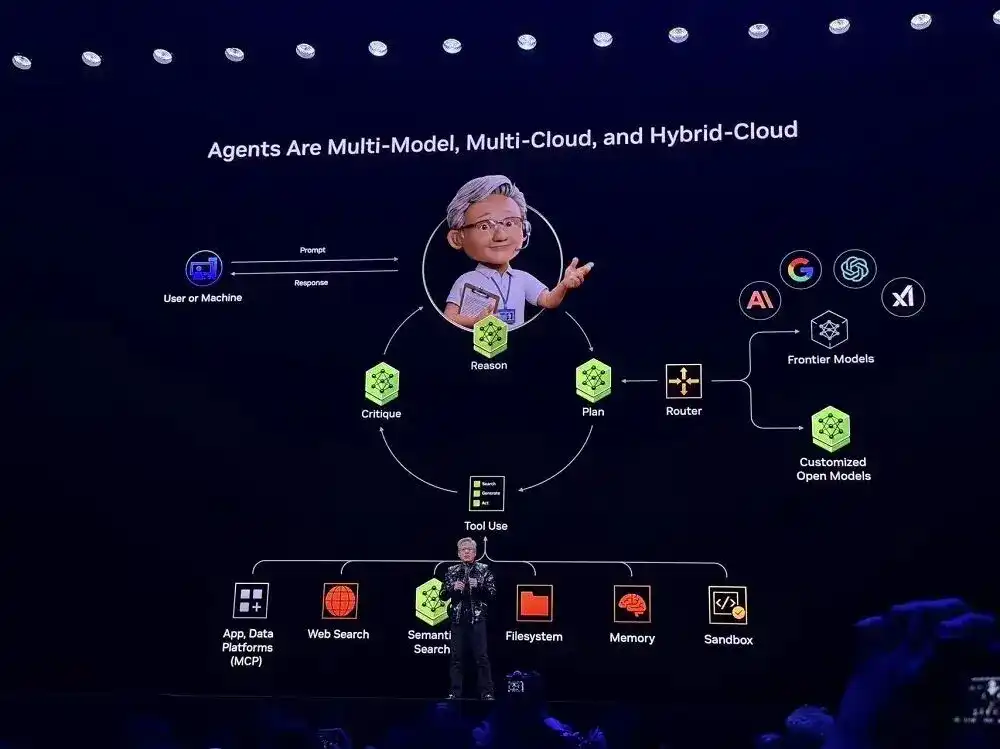
Dengan model dan alat sumber terbuka yang disediakan NVIDIA, pengembang sekarang juga menyesuaikan sistem AI, dan menggunakan kemampuan model paling mutakhir. Saat ini, NVIDIA telah mengintegrasikan kerangka kerja di atas menjadi "cetak biru", dan mengintegrasikannya ke platform SaaS. Pengguna dapat menggunakan cetak biru untuk penerapan cepat.
Dalam demonstrasi langsung, sistem ini dapat secara otomatis menilai apakah tugas harus ditangani oleh model privat lokal atau model mutakhir cloud, juga dapat memanggil alat eksternal (seperti API email, antarmuka kontrol robot, layanan kalender, dll.), dan mewujudkan fusi multimodal, memproses informasi teks, suara, gambar, sinyal sensor robot, dll. secara terpadu.
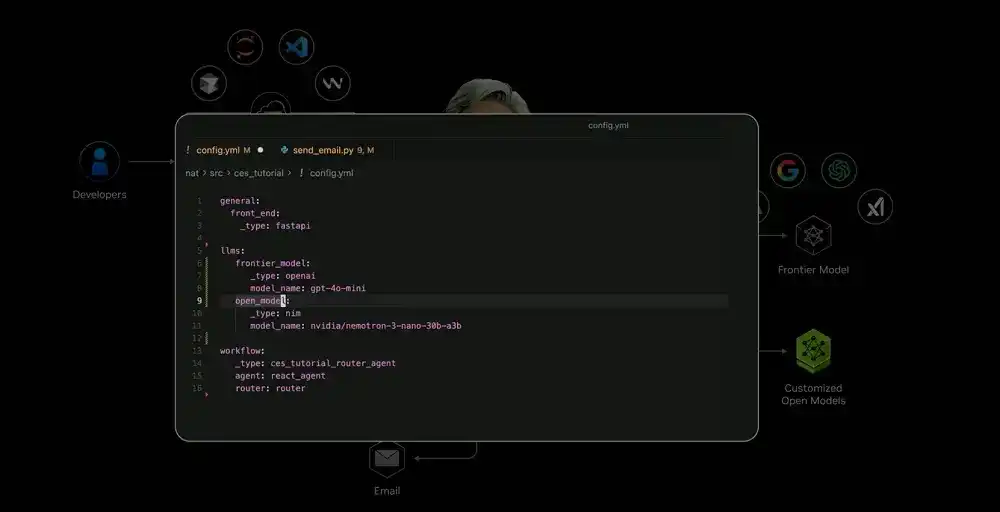
Kemampuan kompleks ini di masa lalu benar-benar tidak terbayangkan, tetapi sekarang menjadi hal biasa. Di platform perusahaan seperti ServiceNow, Snowflake, dll., kemampuan serupa dapat digunakan.
04. Model Alpha-Mayo Sumber Terbuka, Membuat Mobil Otonom "Berpikir"
NVIDIA percaya Fisika AI dan robotika pada akhirnya akan menjadi segmen elektronik konsumen terbesar di dunia. Semua yang dapat bergerak, pada akhirnya akan sepenuhnya otonom, digerakkan oleh Fisika AI.
AI telah melalui tahap AI persepsi, AI generatif, AI Agentic, sekarang memasuki era Fisika AI, kecerdasan memasuki dunia nyata, model-model ini dapat memahami hukum fisika, dan langsung menghasilkan tindakan dari persepsi dunia fisik.
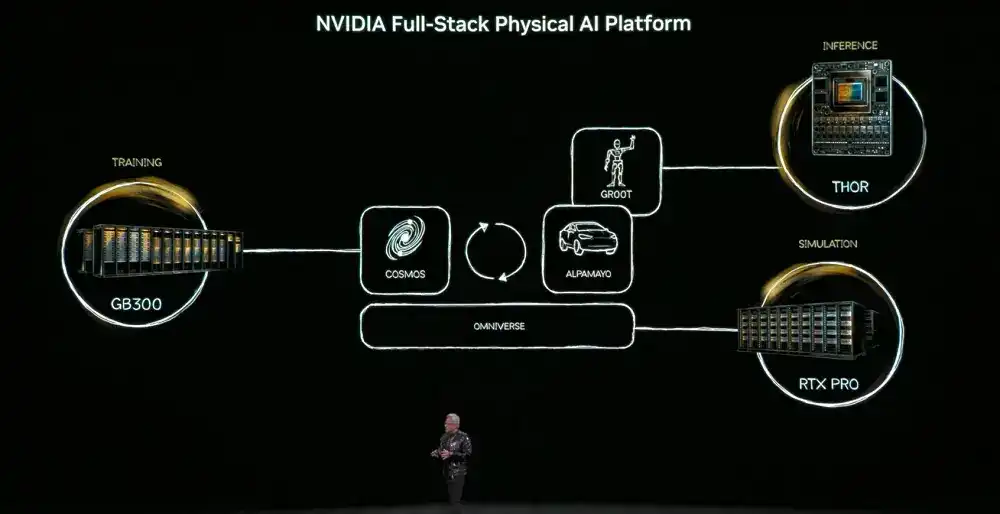
Namun untuk mencapai tujuan ini, Fisika AI harus mempelajari akal sehat dunia - keabadian objek, gravitasi, gesekan. Perolehan kemampuan ini akan bergantung pada tiga komputer: komputer pelatihan (DGX) untuk membuat model AI, komputer inference (chip robotik/mobil) untuk eksekusi real-time, komputer simulasi (Omniverse) untuk menghasilkan data sintetis, memvalidasi logika fisika.
Dan model intinya adalah model dasar dunia Cosmos, yang menyelaraskan bahasa, gambar, 3D, dan hukum fisika, mendukung seluruh alur dari pembuatan data pelatihan simulasi.
Fisika AI akan muncul dalam tiga jenis entitas: bangunan (seperti pabrik, gudang), robot, mobil otonom.
Huang Renxun percaya, mengemudi otonom akan menjadi aplikasi skala besar pertama Fisika AI. Sistem semacam ini perlu memahami dunia nyata, membuat keputusan, dan melakukan tindakan, membutuhkan keamanan, simulasi, dan data yang sangat tinggi.
Untuk ini, NVIDIA merilis Alpha-Mayo, sistem lengkap yang terdiri dari model sumber terbuka, alat simulasi, dan dataset Fisika AI, untuk mempercepat pengembangan Fisika AI yang aman dan berbasis penalaran.
Kombinasi produknya menyediakan modul dasar untuk membangun sistem mengemudi otonom L4 bagi pabrikan mobil global, pemasok, startup, dan peneliti.

Alpha-Mayo adalah model pertama di industri yang benar-benar membuat mobil otonom "berpikir", model ini telah open source. Ia memecahkan masalah menjadi langkah-langkah, menalar semua kemungkinan, dan memilih jalur teraman.

Model tugas-aksi penalaran ini memungkinkan sistem mengemudi otonom menyelesaikan skenario tepi kompleks yang belum pernah dialami sebelumnya, seperti lampu lalu lintas yang rusak di persimpangan sibuk.
Alpha-Mayo memiliki 10 miliar parameter, cukup besar untuk menangani tugas mengemudi otonom, tetapi cukup ringan untuk dijalankan pada workstation yang dibuat untuk peneliti mengemudi otonom.
Ia dapat menerima teks, kamera surround, status historis kendaraan, dan input navigasi, dan mengeluarkan lintasan dan proses penalaran, memungkinkan penumpang memahami mengapa kendaraan mengambil tindakan tertentu.
Dalam video promosi yang diputar langsung, dengan didorong oleh Alpha-Mayo, mobil otonom dapat secara mandiri menghindari pejalan kaki, memprediksi kendaraan belok kiri dan mengubah jalur untuk menghindari, dll. tanpa intervensi.

Huang Renxun menyatakan, Mercedes-Benz CLA yang dilengkapi Alpha-Mayo telah diproduksi, dan baru saja dinilai oleh NCAP sebagai mobil teraman di dunia. Setiap kode, chip, sistem disertifikasi keamanan. Sistem ini akan diluncurkan di pasar AS, dan akan meluncurkan kemampuan mengemudi yang lebih kuat pada akhir tahun ini, termasuk mengemudi tanpa tangan di jalan raya, dan mengemudi otonom ujung ke ujung di lingkungan perkotaan.

NVIDIA juga merilis sebagian dataset untuk melatih Alpha-Mayo, kerangka simulasi evaluasi model inference sumber terbuka Alpha-Sim. Pengembang dapat melakukan fine-tuning Alpha-Mayo dengan data mereka sendiri, juga dapat menggunakan Cosmos untuk menghasilkan data sintetis, dan melatih serta menguji aplikasi mengemudi otonom berdasarkan kombinasi data nyata dan sintetis. Selain itu, NVIDIA mengumumkan Platform NVIDIA DRIVE kini diproduksi.
NVIDIA mengumumkan, perusahaan robotika terkemuka global seperti Boston Dynamics, Franka Robotics, robot bedah Surgical, LG Electronics, NEURA, XRLabs, Zhiyuan Robotics, dll. semuanya membangun berdasarkan NVIDIA Isaac dan GR00T.

Huang Renxun juga mengumumkan kolaborasi terbaru dengan Siemens. Siemens mengintegrasikan CUDA-X NVIDIA, model AI, dan Omniverse ke dalam portofolio alat dan platform EDA, CAE, dan digital twin-nya. Fisika AI akan digunakan secara luas untuk seluruh alur dari desain, simulasi hingga produksi manufaktur dan operasi.
05. Kesimpulan: Satu Tangan Merangkul Sumber Terbuka, Tangan Lainnya Membuat Sistem Perangkat Keras Menjadi Tidak Tergantikan
Dengan fokus infrastruktur AI beralih dari pelatihan ke inference skala besar, persaingan platform telah berevolusi dari daya komputasi titik tunggal, menjadi rekayasa sistem yang mencakup chip, rak, jaringan, dan perangkat lunak, target beralih ke pengiriman throughput inference maksimal dengan TCO terendah, AI memasuki tahap baru "operasi pabrik".
NVIDIA sangat menekankan desain tingkat sistem, Rubin secara bersamaan mencapai peningkatan kinerja dan ekonomi dalam pelatihan dan inference, dan dapat berfungsi sebagai pengganti plug-and-play Blackwell, dapat beralih mulus dari Blackwell.
Dalam penentuan posisi platform, NVIDIA masih percaya pelatihan sangat penting, karena hanya dengan melatih model paling mutakhir dengan cepat, platform inference benar-benar dapat diuntungkan, sehingga memperkenalkan pelatihan NVFP4 dalam Rubin GPU, lebih lanjut meningkatkan kinerja, mengurangi TCO.
Secara bersamaan, raksasa komputasi AI ini juga terus memperkuat kemampuan komunikasi jaringan secara signifikan pada arsitektur scale-up dan scale-out, dan memandang konteks sebagai hambatan kunci, mewujudkan desain kolaboratif penyimpanan, jaringan, komputasi.
NVIDIA di satu sisi besar-besaran sumber terbuka, di sisi lain membuat perangkat keras, interkoneksi, desain sistem semakin "tidak tergantikan", lingkaran strategi yang terus memperluas permintaan, mendorong konsumsi token, mendorong skalabilitas inference, menyediakan infrastruktur bernilai tinggi ini, sedang membangun parit pertahanan yang semakin tak tertembus untuk NVIDIA.






