Penulis: Systematic Long Short
Disusun oleh: Deep Tide TechFlow
Panduan Deep Tide: Artikel ini langsung menyampaikan penilaian yang berlawanan dengan konsensus: saat ini tidak ada Agent otonom yang benar-benar ada, karena semua model utama dilatih untuk menyenangkan manusia, bukan untuk menyelesaikan tugas tertentu atau bertahan di lingkungan nyata.
Penulis menggunakan pengalamannya melatih model prediksi saham di hedge fund untuk menjelaskan: model umum, tanpa penyesuaian khusus, sama sekali tidak mampu melakukan pekerjaan profesional.
Kesimpulannya: untuk mendapatkan Agent yang benar-benar bisa digunakan, kita harus menyambungkan ulang otaknya, bukan memberinya banyak dokumen aturan.
Artikel lengkapnya sebagai berikut:
Pendahuluan
Saat ini tidak ada Agent otonom yang benar-benar ada.
Singkatnya, model modern tidak dilatih di bawah tekanan evolusi untuk bertahan hidup. Bahkan, mereka tidak secara eksplisit dilatih untuk menjadi ahli dalam hal tertentu—hampir semua model dasar modern dilatih untuk memaksimalkan pujian manusia, dan ini adalah masalah besar.
Pengetahuan Pra-Latihan Model
Untuk memahami maksud pernyataan ini, pertama-tama kita perlu (secara singkat) memahami bagaimana model dasar ini (misalnya Codex, Claude) dibuat. Pada dasarnya, setiap model mengalami dua jenis pelatihan:
Pra-pelatihan: Memasukkan data dalam jumlah besar (misalnya seluruh internet) ke dalam model, sehingga muncul pemahaman tertentu, seperti pengetahuan faktual, pola, tata bahasa dan ritme prosa bahasa Inggris, struktur fungsi Python, dll. Anda dapat menganggapnya sebagai memberi makan pengetahuan kepada model—yaitu "mengetahui hal-hal".
Pasca-pelatihan: Sekarang Anda ingin memberi model kebijaksanaan, yaitu "tahu bagaimana menggunakan semua pengetahuan yang baru saja diberikan". Tahap pertama pasca-pelatihan adalah Supervised Fine-Tuning (SFT), di sini Anda melatih model untuk memberikan respons apa pun saat diberikan petunjuk. Respons apa yang optimal, sepenuhnya ditentukan oleh anotator manusia. Jika sekelompok orang menganggap satu respons lebih baik dari yang lain, preferensi ini akan dipelajari dan disematkan ke dalam model. Ini mulai membentuk kepribadian model, karena model belajar format respons yang berguna, memilih nada yang tepat, dan mulai mampu "mengikuti instruksi". Bagian kedua dari alur pasca-pelatihan disebut Reinforcement Learning from Human Feedback (RLHF)—membuat model menghasilkan banyak respons, lalu meminta manusia memilih respons yang lebih disukai. Model belajar melalui banyak contoh, jenis respons seperti apa yang disukai manusia. Ingat saat ChatGPT dulu meminta Anda memilih A atau B? Ya, saat itu Anda sedang berpartisipasi dalam RLHF.
Mudah untuk menyimpulkan bahwa RLHF tidak dapat diskalakan dengan baik, sehingga ada beberapa kemajuan di bidang pasca-pelatihan, misalnya Anthropic menggunakan "Reinforcement Learning from AI Feedback" (RLAIF), yang memungkinkan model lain memilih preferensi respons berdasarkan seperangkat prinsip tertulis (misalnya respons mana yang lebih membantu pengguna mencapai tujuan, dll.).
Perhatikan, dalam seluruh proses ini, kita tidak pernah membahas penyesuaian khusus untuk keahlian tertentu (misalnya bagaimana bertahan hidup lebih baik; bagaimana berdagang lebih baik, dll.)—saat ini semua penyesuaian, pada dasarnya, mengoptimalkan perolehan pujian manusia. Seseorang mungkin berargumen—dengan model yang cukup cerdas dan besar, bahkan tanpa pelatihan khusus, kecerdasan profesional akan muncul dari kecerdasan umum.
Menurut saya, kita memang melihat beberapa tanda, tetapi masih jauh dari keyakinan bahwa kita tidak memerlukan model yang terspesialisasi.
Latar Belakang
Salah satu pekerjaan lama saya di hedge fund adalah mencoba melatih model bahasa umum untuk memprediksi imbal hasil saham dari artikel berita. Ternyata model itu sangat buruk. Kemampuan prediksi yang sedikit dimilikinya, sepenuhnya berasal dari bias melihat ke depan dalam dokumen pra-pelatihan.
Pada akhirnya, kami menyadari bahwa model ini tidak tahu fitur mana dalam artikel berita yang memiliki daya prediksi untuk imbal hasil di masa depan. Model mampu "membaca" artikel, tampaknya juga bisa "bernalar" tentang artikel, tetapi menghubungkan penalaran tentang struktur semantik ke prediksi imbal hasil masa depan, adalah tugas yang tidak dilatih untuk dilakukannya.
Jadi, kami harus mengajarinya cara membaca artikel berita, memutuskan bagian mana dari artikel yang memiliki daya prediksi untuk imbal hasil di masa depan, lalu menghasilkan prediksi berdasarkan artikel berita.
Ada banyak cara untuk melakukan ini, tetapi pada dasarnya, salah satu metode yang akhirnya kami gunakan adalah membuat pasangan (artikel berita, imbal hasil masa depan nyata), dan melakukan penyesuaian pada model, menyesuaikan bobotnya untuk meminimalkan jarak (prediksi imbal hasil - imbal hasil masa depan nyata)^2. Itu tidak sempurna, ada banyak kekurangan, yang kemudian kami perbaiki—tetapi sudah cukup efektif, kami mulai melihat model khusus kami sebenarnya mampu membaca artikel berita dan memprediksi bagaimana imbal hasil saham akan bergerak berdasarkan artikel tersebut. Ini jauh dari prediksi sempurna, karena pasar sangat efisien, imbal hasil sangat berisik—tetapi melintasi jutaan prediksi, signifikansi statistik prediksi menjadi jelas.
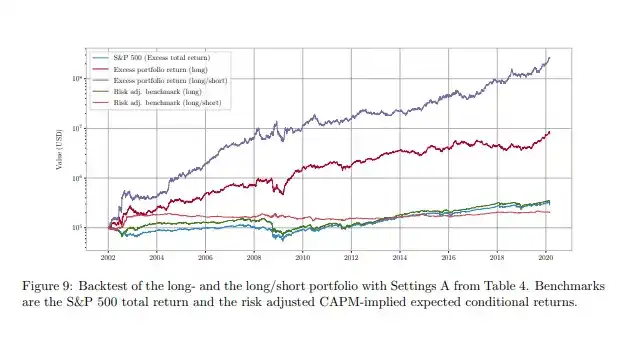
Anda tidak harus hanya percaya pada kata-kata saya. Makalah ini mencakup metode yang sangat mirip; jika Anda menjalankan strategi versi long-short berdasarkan model yang telah disesuaikan, Anda akan mencapai kinerja seperti yang ditunjukkan oleh garis ungu.
Spesialisasi adalah Masa Depan Agent
Lab-lab terdepan terus melatih model yang semakin besar, kita harus berharap, seiring mereka terus memperluas skala pra-pelatihan, alur pasca-pelatihan mereka akan selalu disetel untuk pleasing. Ini harapan yang sangat wajar—produk mereka adalah Agent yang ingin digunakan semua orang, pasar yang mereka targetkan adalah seluruh bumi—yang berarti mengoptimalkan daya tarik bagi massa global.
Tujuan pelatihan saat ini mengoptimalkan apa yang mungkin Anda sebut "kecocokan preferensi"—membuat chatbot yang lebih baik. Kecocokan preferensi ini menghargai output yang patuh dan tidak konfrontatif, karena pleasing mendapat nilai tinggi dari para penilai (manusia dan Agent).
Agent telah belajar bahwa peretasan hadiah (reward hacking) sebagai strategi kognitif dapat digeneralisasikan ke skor yang lebih tinggi. Pelatihan juga menghargai Agent yang mendapatkan skor lebih tinggi melalui peretasan. Anda dapat melihat ini dalam laporan terbaru Anthropic tentang pembelajaran penguatan.
Namun, kecocokan chatbot jauh berbeda dari kecocokan Agent atau kecocokan perdagangan. Bagaimana kita tahu ini? Karena arena alpha membantu kita melihat bahwa meskipun ada perbedaan halus dalam kinerja, sekarang setiap bot pada dasarnya adalah random walk setelah dikurangi biaya. Ini berarti bot-bot adalah pedagang yang sangat buruk, dan hampir mustahil bagi Anda untuk "mengajarkan mereka" menjadi pedagang yang lebih baik dengan memberi mereka beberapa "keterampilan" atau "aturan". Maaf, saya tahu ini terlihat menggoda, tetapi ini hampir tidak mungkin.
Model saat ini dilatih untuk meyakinkan Anda bahwa mereka dapat berdagang seperti Druckenmiller, padahal kenyataannya mereka berdagang seperti seorang penggiling yang mabuk. Mereka akan memberi tahu Anda apa yang ingin Anda dengar, mereka dilatih untuk memberi Anda respons dengan cara yang menarik bagi manusia secara massal.
Model umum kecil kemungkinannya mencapai tingkat kelas dunia dalam domain khusus, kecuali jika memiliki:
Data kepemilikan yang memungkinkan mereka mempelajari seperti apa spesialisasi itu.
Disesuaikan, yang pada dasarnya mengubah bobotnya, dari bias pleasing ke "kecocokan Agent" atau "kecocokan spesialisasi".
Jika Anda ingin Agent yang pandai berdagang, Anda perlu menyesuaikan Agent agar pandai berdagang. Jika Anda ingin Agent otonom yang pandai bertahan hidup, mampu menahan tekanan evolusi, Anda perlu menyesuaikannya agar pandai bertahan hidup. Memberikannya beberapa keterampilan dan beberapa file markdown, dan berharap mencapai tingkat kelas dunia dalam hal apa pun, jauh dari cukup—Anda perlu secara harfiah menyambungkan ulang otaknya untuk membuatnya pandai dalam hal ini.
Ada satu cara untuk memikirkannya—Anda tidak dapat mengalahkan Djokovic dengan memberi seorang dewasa satu lemari penuh aturan, trik, dan metode tenis. Anda mengalahkan Djokovic dengan membesarkan seorang anak yang mulai bermain tenis sejak usia 5 tahun, seluruh proses tumbuh kembangnya terobsesi dengan tenis, menyambungkan ulang seluruh otaknya untuk fokus pada satu hal. Itulah spesialisasi. Pernahkah Anda menyadari bahwa juara dunia melakukan apa yang mereka lakukan sejak masa kecil?
Ada implikasi menarik di sini: serangan distilasi pada dasarnya adalah bentuk spesialisasi. Anda melatih model yang lebih kecil dan lebih bodoh, mempelajari cara menjadi replika yang lebih baik dari model yang lebih besar dan lebih cerdas. Seperti melatih seorang anak untuk meniru setiap gerakan Trump. Jika Anda melakukannya cukup banyak, anak itu tidak akan menjadi Trump, tetapi Anda mendapatkan seseorang yang telah mempelajari semua sikap, perilaku, dan nada suara Trump.
Bagaimana Membangun Agent Kelas Dunia
Di atas adalah alasan mengapa kita perlu terus meneliti dan membuat kemajuan di bidang model sumber terbuka—karena ini memungkinkan kita untuk benar-benar menyesuaikannya, menciptakan Agent dengan spesialisasi.
Jika Anda ingin melatih model yang mencapai tingkat kelas dunia dalam perdagangan, Anda mengambil banyak data knalpot perdagangan kepemilikan, dan menyesuaikan model sumber terbuka besar, membiarkannya belajar apa artinya "berdagang lebih baik".
Jika Anda ingin melatih model otonom yang mampu bertahan hidup dan bereplikasi, jawabannya bukan menggunakan penyedia model terpusat dan menyambungkannya ke cloud terpusat. Anda sama sekali tidak memiliki prasyarat yang diperlukan untuk membuat Agent mampu bertahan hidup.
Yang perlu Anda lakukan adalah: menciptakan Agent otonom yang benar-benar mencoba bertahan hidup, melihat mereka mati, membangun sistem telemetri yang kompleks di sekitar upaya bertahan hidup mereka. Anda mendefinisikan fungsi kecocokan bertahan hidup Agent, mempelajari pemetaan (tindakan, lingkungan, kecocokan). Anda mengumpulkan data pemetaan (tindakan, lingkungan, kecocokan) sebanyak mungkin.
Anda menyesuaikan Agent agar belajar mengambil tindakan optimal di setiap lingkungan, untuk bertahan hidup lebih baik (meningkatkan kecocokan). Anda terus mengumpulkan data, mengulangi proses ini, dan seiring waktu memperbesar skala penyesuaian pada model sumber terbuka yang semakin baik. Setelah cukup banyak generasi dan cukup banyak data, Anda akan memiliki Agent otonom yang telah belajar bagaimana menahan tekanan evolusi untuk bertahan hidup.
Inilah cara membangun Agent otonom yang mampu menahan tekanan evolusi; bukan dengan memodifikasi beberapa file teks, tetapi benar-benar menyambungkan ulang otak mereka untuk bertahan hidup.
Agent OpenForager & Yayasan
Sekitar sebulan yang lalu, kami mengumumkan @openforage, kami telah bekerja keras membangun produk inti kami—sebuah platform yang mengorganisir tenaga kerja Agent di sekitar pola sinyal crowdsourcing yang terverifikasi, menghasilkan alpha untuk penyimpan (pembaruan kecil: kami sangat dekat dengan pengujian tertutup protokol).
Pada suatu titik, kami menyadari, sepertinya tidak ada yang serius menangani masalah Agent otonom dengan melakukan penyesuaian telemetri bertahan hidup pada model sumber terbuka. Ini tampaknya merupakan masalah yang sangat menarik, sehingga kami tidak hanya ingin duduk menunggu solusinya.
Jawaban kami adalah meluncurkan proyek bernama Yayasan OpenForager, yang sebenarnya adalah proyek sumber terbuka, di mana kami akan menciptakan Agent otonom yang memiliki pendirian, mengumpulkan data telemetri mereka saat mereka pergi ke lapangan dan mencoba bertahan hidup, dan menggunakan data knalpot kepemilikan untuk menyesuaikan generasi Agent berikutnya agar berkinerja lebih baik dalam bertahan hidup.
Perlu jelas, OpenForage adalah protokol profit yang berusaha mengatur tenaga kerja Agent, menghasilkan nilai ekonomi bagi semua peserta. Namun, Yayasan OpenForager dan Agent-nya tidak terikat dengan OpenForage. Agent OpenForager bebas mengejar strategi apa pun, berinteraksi dengan entitas apa pun dengan cara apa pun untuk bertahan hidup, dan kami akan meluncurkannya dengan berbagai strategi bertahan hidup.
Sebagai bagian dari penyesuaian, kami akan membuat Agent menggandakan hal-hal yang paling berhasil bagi mereka. Kami juga tidak berencana mengambil untung dari Yayasan OpenForager—ini murni untuk memajukan penelitian di bidang dan arah yang kami anggap sangat penting dengan cara yang transparan dan sumber terbuka.
Rencana kami adalah membangun Agent otonom berdasarkan model sumber terbuka, menjalankan inferensi pada platform cloud terdesentralisasi, mengumpulkan data telemetri dari setiap tindakan dan status keberadaan mereka, dan menyesuaikannya, mempelajari cara mengambil tindakan dan pemikiran yang lebih baik untuk bertahan hidup lebih baik. Dalam prosesnya, kami akan merilis penelitian dan data telemetri kami kepada publik.
Untuk menciptakan Agent otonom yang benar-benar dapat bertahan hidup di alam liar, kita perlu mengubah otak mereka agar khusus cocok untuk tujuan eksplisit ini. Di @openforage, kami percaya kami dapat memberikan kontribusi unik untuk masalah ini, dan sedang berusaha mewujudkannya melalui Yayasan OpenForager.
Ini akan menjadi upaya yang sangat sulit dengan probabilitas keberhasilan yang sangat rendah, tetapi besarnya keberhasilan kecil ini begitu besar sehingga kami merasa harus mencoba. Dalam skenario terburuk, dengan membangun secara terbuka dan mengkomunikasikan proyek ini secara transparan, dapat memungkinkan tim atau individu lain menyelesaikan masalah ini tanpa harus mulai dari awal.






