Penulis: Yanhua
Antonio Gullí adalah Direktur Teknik di Google. Dia menulis buku setebal 453 halaman, yang memecah pengembangan AI Agent menjadi 21 pola desain.
Namun ini bukan resensi buku. Motivasi saya membaca buku ini sangat spesifik: Saya pernah menulis tentang Harness Engineering, tentang pengalaman jatuh-bangun Clawdbot, tentang "AI Agent Bukan Sihir" yang membahas tujuh titik balik dari sekedar membakar token hingga benar-benar berguna, dan setiap kali selesai menulis, selalu ada satu pertanyaan yang belum sepenuhnya terjawab: Apakah ada logika dasar yang dapat digunakan kembali di balik semua ini?
Buku ini memberikan jawabannya, dan lebih dalam dari yang saya bayangkan.
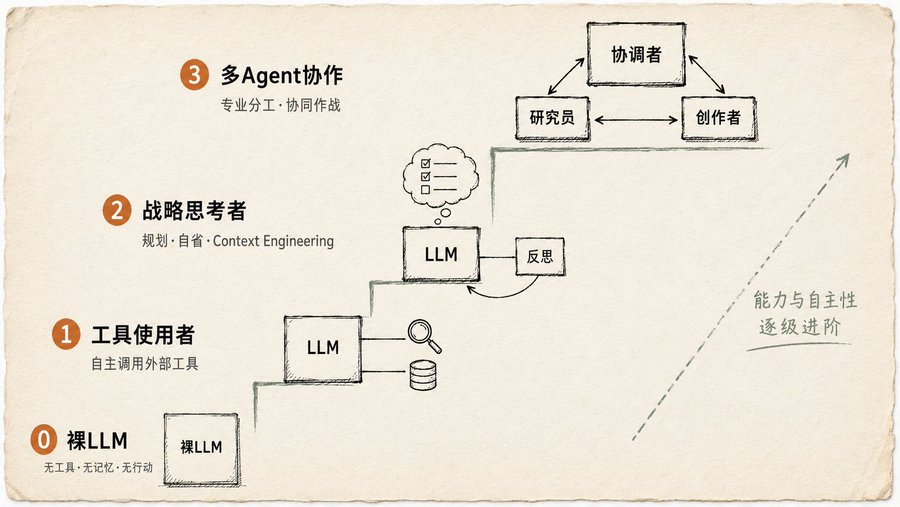
Apa yang Anda Buat Mungkin Bukan Agent Sama Sekali
Penilaian paling tajam dalam buku ini tersembunyi di bagian prolog.
"AI" yang digunakan kebanyakan orang hanya Level 0: LLM polos, tanpa alat, tanpa memori, tidak bisa bertindak. Anda bertanya film apa yang memenangkan Oscar 2025, dia menebak. Buku ini menyebutkan dengan gamblang: Barang Level 0, bukan Agent.
Baru ke atas itulah Agent sebenarnya:
-
Level 1: Pengguna Alat
Agent mulai menggunakan alat: pencarian, API, basis data. Tapi tidak sekedar "bisa panggil API", dia harus menilai sendiri kapan harus memanggil, memanggil apa, dan bagaimana menggunakan hasilnya. Buku ini memberikan contoh yang sangat spesifik: pengguna bertanya "Ada drama baru apa akhir-akhir ini?", Agent sendiri menyadari informasi ini tidak ada dalam data latihan, aktif memanggil alat pencarian untuk mencari, lalu menyintesis hasilnya. Langkah kuncinya adalah "menyadari sendiri". Bukan manusia yang menyuruhnya "coba kamu cari", tapi dia yang menilai perlu mencari. Kemampuan menilai ini adalah ambang batas Level 1.
-
Level 2: Pemikir Strategis
Menambah dua hal: perencanaan dan Context Engineering. Buku ini mendefinisikan Context Engineering: bukan menumpuk informasi, tapi menyaring, memangkas, mengemas konteks dengan cermat. Contohnya sangat bagus: pengguna ingin mencari kedai kopi di antara dua lokasi. Agent pertama-tama memanggil alat peta untuk mendapatkan segudang data, lalu dia menilai sendiri "langkah selanjutnya hanya membutuhkan nama jalan", memangkas keluaran peta menjadi daftar pendek, lalu memberikannya ke alat pencarian lokal. Setiap langkah melakukan peredaman kebisingan informasi.
Ada satu kalimat dalam buku ini yang saya baca berulang kali: "Agar AI mencapai akurasi tertinggi, berikan dia konteks yang pendek, fokus, dan kuat." Context Engineering lah yang melakukan hal ini.
Sampai level ini, Agent juga bisa refleksi diri. Setelah selesai bekerja, meninjau sendiri, menemukan masalah, dan memperbaikinya sendiri. Akan saya bahas lebih detail nanti.
-
Level 3: Kolaborasi Multi-Agent
Posisi buku ini sangat jelas: jangan selalu berpikir untuk membuat satu super agent serba bisa. Cara yang benar-benar andal adalah seperti membangun tim, Agent Manajer Proyek + Agent Peneliti + Agent Desainer + Agent Penulis Naskah. Contoh yang diberikan buku ini adalah peluncuran produk baru: satu "Agent Manajer Proyek" sebagai pengatur keseluruhan, menugaskan pekerjaan ke "Agent Penelitian Pasar", "Agent Desain Produk", "Agent Pemasaran". Kuncinya adalah komunikasi: bagaimana antar-Agent mentransfer data, bagaimana sinkronisasi status, bagaimana menangani konflik. Bab ini menggambarkan enam struktur topologi komunikasi, dari yang paling sederhana Single Agent hingga yang paling fleksibel Custom Hybrid, masing-masing disertai penjelasan situasi apa yang cocok.
Setelah melihat empat level ini, saya tiba-tiba mengerti mengapa banyak orang mengatakan "Agent saya tidak berguna". Model tidak bermasalah, masalahnya adalah Anda menggunakannya seperti chatbot, mungkin bahkan belum mencapai Level 1.
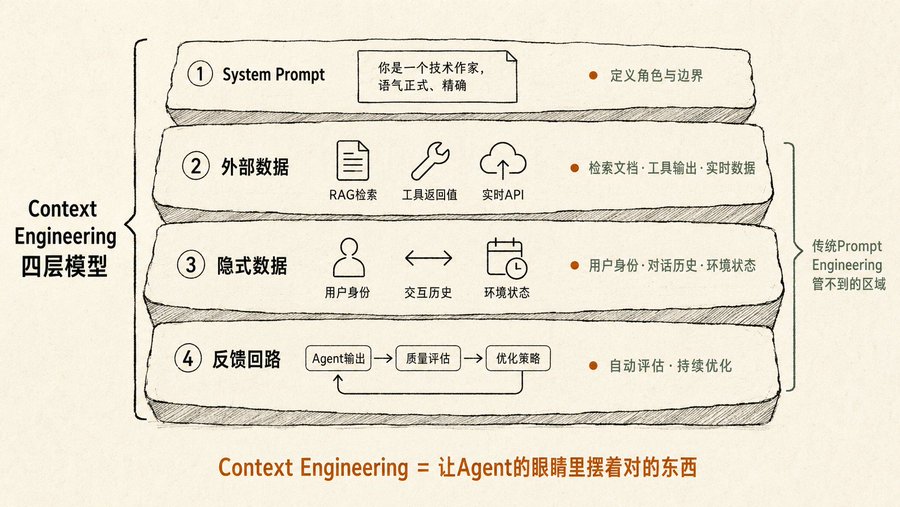
Context Engineering: Konsep yang Paling Diremehkan dalam Buku
Saya pernah menulis tentang Harness Engineering, yang membahas bahwa desain lintasan balap lebih penting daripada tenaga mesin. Setelah membaca buku ini, saya menemukan Context Engineering adalah pemetaan Harness Engineering di tingkat prompt.
Prompt Engineering tradisional hanya mengatur "bagaimana Anda bertanya". Context Engineering dalam buku ini mengatur "sebelum bertanya, apa yang ada di hadapan Agent". Ini mencakup empat lapisan informasi:
-
Lapisan pertama, system prompt. Mendefinisikan siapa Agent, nada bicara apa, batasan apa. Kebanyakan orang hanya menulis lapisan ini.
-
Lapisan kedua, data eksternal. Dokumen yang diambil dari RAG, nilai pengembalian dari pemanggilan alat, data API real-time. Ini adalah tempat kebanyakan orang terjebak: tahu harus memberikan data, tapi tidak tahu bagaimana caranya agar model tidak tenggelam.
-
Lapisan ketiga, data implisit. Identitas pengguna, riwayat interaksi, status lingkungan. Hal-hal yang tidak Anda nyatakan tetapi harus diketahui Agent. Misalnya, Anda berkata kepada Agent "tolong kirim email kepada John untuk konfirmasi rapat besok", dia harus tahu rapat besok apa di kalender Anda, hubungan Anda dengan John seperti apa.
-
Lapisan keempat, loop umpan balik. Setelah setiap keluaran Agent, menilai kualitas secara otomatis, menyesuaikan strategi konteks berikutnya. Buku menyebut ini "optimasi konteks otomatis", Prompt Optimizer Google Vertex AI adalah implementasi rekayasa dari pemikiran ini.
Saat membaca bagian ini, saya teringat tulisan sebelumnya "AI Agent Bukan Sihir", di dalamnya ada satu pengalaman bahwa "Agent Anda butuh aturan, dan itu banyak aturan". Sekarang melihat ke belakang, aturan-aturan itu pada dasarnya adalah versi manual dari Context Engineering, yang telah disistematisasi dalam buku ini.
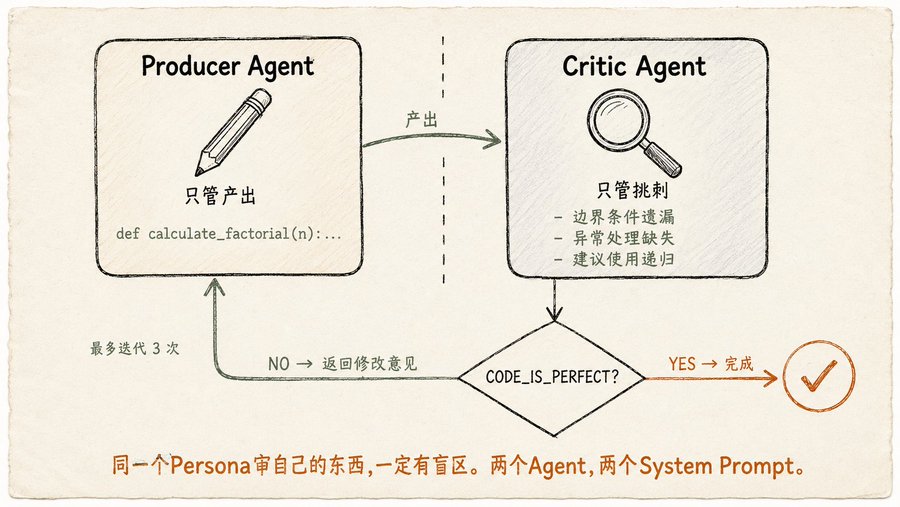
Reflection: Dua Agent Benar-Benar Lebih Baik daripada Satu
Ini adalah Pattern yang paling bernilai praktis dalam buku ini bagi saya.
Inti Reflection sederhana: setelah Agent selesai bekerja, dia meninjau sendiri, menemukan masalah, dan memperbaikinya sendiri. Tapi cara implementasinya perlu dipertimbangkan. Buku ini mengatakan dengan jelas: Producer dan Critic harus menggunakan dua Agent berbeda, dengan system prompt yang berbeda. Persona yang sama meninjau karyanya sendiri pasti memiliki titik buta. Anda meminta LLM yang sama untuk menulis kode, lalu meninjau kode yang ditulisnya sendiri, kemungkinan besar dia akan berkata "lumayan bagus".
Buku ini memberikan contoh kode lengkap.
-
Prompt Producer adalah "Anda adalah pengembang Python, tulis fungsi untuk menghitung faktorial, tangani kondisi batas dan pengecualian."
-
Prompt Critic adalah "Anda adalah insinyur senior yang sangat teliti, tinjau kode baris per baris, periksa Bug, gaya, kondisi batas yang terlewat, bagian yang dapat ditingkatkan. Jika sempurna, keluarkan
CODE_IS_PERFECT, jika tidak daftarkan semua masalah." -
Kemudian ada loop for: Producer menulis kode → Critic meninjau → Producer memperbaiki berdasarkan saran → Critic meninjau lagi → sampai Critic berkata
CODE_IS_PERFECTatau mencapai jumlah iterasi maksimum.
Sesederhana itu. Tapi buku ini mengingatkan masalah biaya yang sering diabaikan: setiap siklus refleksi adalah pemanggilan LLM baru, semakin banyak iterasi semakin mahal. Dan seiring membengkaknya riwayat percakapan, jendela konteks dipenuhi versi sebelumnya dan kritik, ruang penalaran yang tersedia sebenarnya menyusut. Jadi praktik terbaik Reflection adalah: tetapkan jumlah iterasi maksimum yang masuk akal (buku menggunakan 3), begitu Critic puas berhenti, jangan mengejar kesempurnaan.
Penggunaannya jauh lebih dari sekedar menulis kode. Menulis artikel, membuat rencana, merangkum dokumen, menyelesaikan soal logika, model Producer-Critic semua bisa diterapkan. Buku ini mendaftarkan tujuh skenario aplikasi, logika intinya sama: hasilkan dulu, tinjau kemudian, perbaiki lagi.
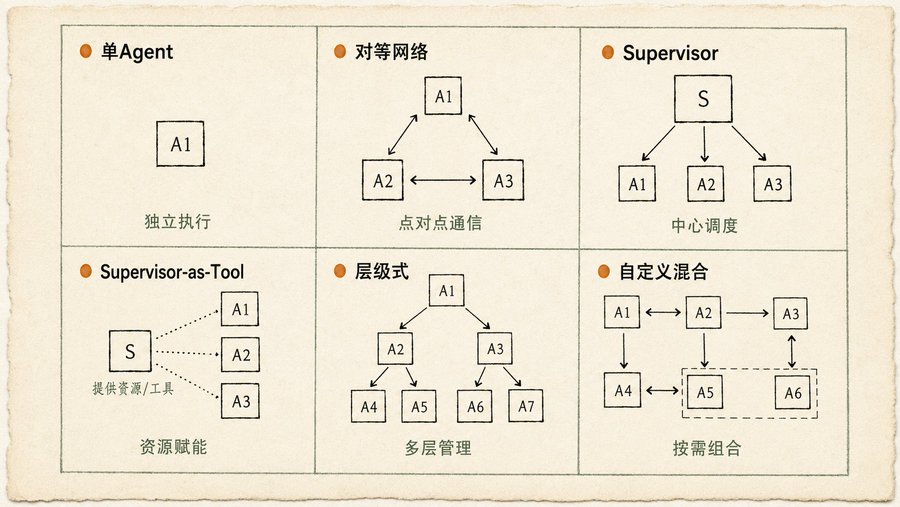
Multi-Agent Bukan Berarti Semakin Kompleks Semakin Baik
Yang paling saya sukai dari bab Multi-Agent Collaboration adalah enam diagram topologi komunikasi itu. Banyak orang langsung menggunakan yang kompleks, tapi sebenarnya sebagian besar skenario cukup tiga saja:
-
Single Agent (Eksekusi Mandiri): Tugas dapat dipecah menjadi sub-masalah yang tidak bergantung, setiap Agent menyelesaikan sendiri. Sederhana, mudah dirawat.
-
Jaringan Setara (Peer-to-Peer): Antar-Agent berkomunikasi langsung, tanpa node kontrol pusat. Terdesentralisasi, toleransi kesalahan baik, satu Agent mati tidak mempengaruhi keseluruhan. Tapi biaya koordinasi tinggi, mudah kacau.
-
Pengawas (Supervisor / Penjadwal Pusat): Sebuah Supervisor Agent mengelola sekelompok Worker Agent. Membagikan tugas, mengumpulkan hasil, menyelesaikan konflik. Hirarki jelas, mudah dikelola. Tapi Supervisor adalah titik kegagalan tunggal, sekaligus hambatan kinerja.
Tiga lainnya (Supervisor-as-Tool, Hierarkis, Hybrid Kustom) adalah varian dan kombinasi dari tiga yang pertama. Buku ini mengatakan dengan sangat realistis: Topologi yang Anda butuhkan tergantung pada kompleksitas tugas Anda. Semakin terpecah-pecah tugasnya, semakin tinggi biaya komunikasi, pada tingkat tertentu mode Supervisor justru lebih efisien daripada model hierarkis.
Pelajaran saya adalah, banyak orang menghabiskan 80% waktu membangun Multi-Agent pada protokol komunikasi, lupa bertanya masalah yang lebih mendasar: apakah tugas ini benar-benar membutuhkan banyak Agent? Buku ini menulis dengan jelas, Single Agent Level 2 + Reflection seringkali sudah cukup. Level 3 disiapkan untuk skenario yang memang tidak bisa ditangani oleh Single Agent.
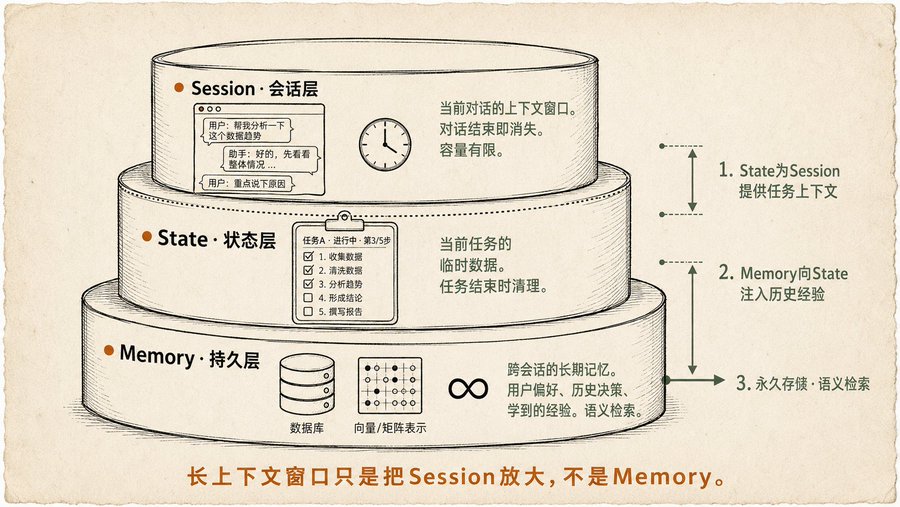
Model Memori Tiga Lapis, Saya Sebelumnya Hanya Merasa Ada tapi Tak Diberi Nama
Bab Memori ini paling saya resapi, karena saat menulis dua artikel tentang Obsidian + Claude, saya selalu merenungkan satu pertanyaan: bagaimana memori Agent harus dibagi lapisan?
Buku ini memberikan jawabannya:
-
Sesi (Lapisan Percakapan): Jendela konteks percakapan saat ini, ini adalah memori terpendek, berakhir percakapan hilang. Model konteks panjang hanya memperbesar jendela ini, tapi pada dasarnya masih sementara, dan setiap penalaran harus memproses seluruh jendela, mahal dan lambat.
-
Status (Lapisan Status): Data sementara yang sedang berjalan dalam tugas saat ini. Misalnya "tugas apa yang sedang dikerjakan", "sudah sampai tahap mana", "data apa yang dihasilkan di tengah". Lebih panjang dari Sesi, tapi berakhir tugas dibersihkan, buku ini menggunakan mekanisme State Google ADK untuk memberikan contoh lengkap.
-
Memori (Lapisan Tahan Lama): Memori jangka panjang lintas sesi, lintas tugas. Preferensi pengguna, pengalaman yang dipelajari, keputusan historis penting, disimpan di basis data atau vector store, diambil secara semantik. Buku ini menekankan poin penting: Memori bukan hanya disimpan, tapi juga mendesain strategi lengkap "menyimpan apa, kapan menyimpan, bagaimana mengambil". Menyimpan terlalu banyak meningkatkan kebisingan, menyimpan terlalu sedikit tidak cukup.
Sebelumnya saat menulis artikel Clawdbot yang menyebutkan "file status" dan "dokumen workspace", pada dasarnya itu adalah versi manual dari lapisan State dan Memory, buku ini membingkai hal ini.
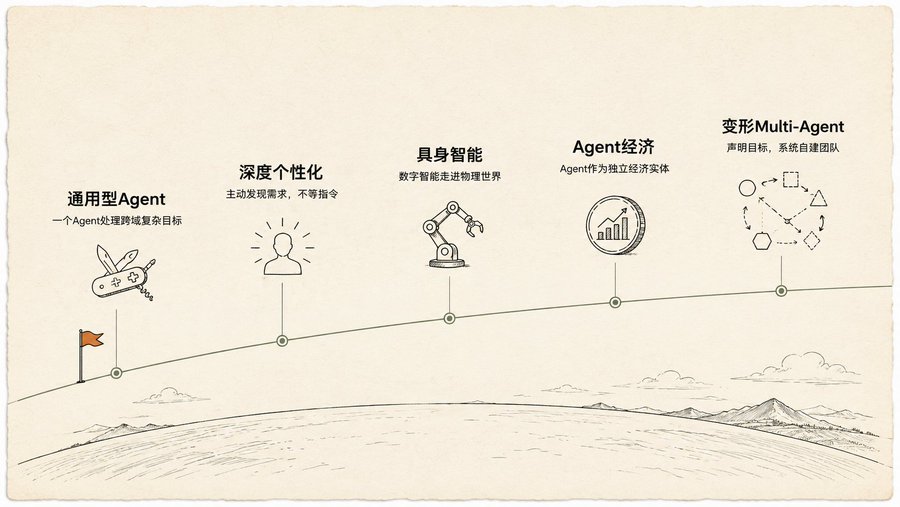
Lima Hipotesis, Yang Kelima Paling Tak Masuk Akal
Di akhir buku disebutkan lima hipotesis tentang masa depan Agent, empat pertama masih dalam jangkauan penalaran wajar: General-Purpose Agent dari menulis kode hingga mengelola proyek, personalisasi mendalam aktif menemukan kebutuhan Anda, embodied intelligence keluar layar ke dunia fisik, Agent menjadi entitas ekonomi mandiri.
Yang kelima membuat saya terkejut: Multi-Agent yang Berubah Bentuk.
Anda hanya mendeklarasikan tujuan, misalnya "buat bisnis e-commerce kopi spesialitas". Sistem secara otomatis memutuskan: pertama buat "Agent Penelitian Pasar" dan "Agent Merek". Setelah menjalankan satu putaran data, dia menilai sendiri Agent Merek tidak dibutuhkan lagi, memecah menjadi tiga baru: "Agent Desain Logo", "Agent Pembuatan Situs", "Agent Rantai Pasok". Jika Agent Pembuatan Situs menjadi hambatan, sistem akan secara otomatis menggandakan tiga Agent paralel yang bekerja bersamaan di halaman berbeda. Selama proses ini, sistem terus-menerus secara otomatis menyesuaikan prompt setiap Agent, terus-menerus menyusun ulang arsitektur tim.
Buku ini menyebutnya sebagai "sistem multi-Agent yang digerakkan tujuan, dapat mengubah bentuk sendiri". Dia tidak menjalankan rencana yang Anda tulis, dia sendiri yang menghasilkan rencana, menyesuaikan rencana sendiri, menyusun ulang tim pelaksana sendiri.
Ini mengingatkan saya pada AutoResearch Karpathy: menulis program.md, mendefinisikan tujuan, metrik, batasan, tekan "mulai". Manusia berada di luar loop. Tapi buku ini mendorong lebih jauh: bahkan bagaimana tim Agent dibentuk, bagaimana disusun ulang, semuanya diserahkan kepada sistem untuk memutuskan sendiri. Manusia hanya mendeklarasikan "menginginkan apa".
Tiga Hal yang Bisa Segera Dilakukan
Setelah membaca buku ini, saya memiliki tiga tindakan yang dapat segera diterapkan:
-
Pertama, tambahkan Critic pada Agent Anda saat ini. Baik Anda menggunakan Claude Code, CrewAI, atau kerangka kerja buatan sendiri, tambahkan satu langkah di akhir workflow Anda: biarkan Agent lain (dengan system prompt berbeda) meninjau keluaran langkah sebelumnya. Pembuatan kode ditambah tinjauan kode, penulisan artikel ditambah pemeriksaan fakta, pembuatan rencana ditambah peninjauan kelayakan. Satu pemanggilan LLM tambahan, tapi peningkatan kualitas seringkali berlipat ganda. Pola Producer-Critic dalam buku ini adalah plug and play.
-
Kedua, mulailah melakukan Context Engineering, bukan hanya Prompt Engineering. Tinjau kembali file instruksi yang Anda tulis untuk Agent. Jika semuanya adalah aturan "bagaimana Anda melakukannya", kurang konteks "lingkungan apa yang sedang Anda hadapi sekarang", tambahkan. Beritahu Agent proyek mana yang sedang dia tangani, keputusan apa yang pernah dibuat sebelumnya, preferensi pengguna seperti apa. Bab Context Engineering dalam buku ini dan
AGENTS.mdAnda adalah dua ungkapan dari hal yang sama. -
Ketiga, jangan buru-buru menerapkan Multi-Agent. Sempurnakan Single Agent Anda sampai Level 2: memiliki alat, Reflection, Memori. Buku ini berulang kali menekankan, Single Agent Level 2 ditambah Producer-Critic dan Context Engineering dapat mencakup sebagian besar skenario nyata. Level 3 disiapkan untuk tugas yang benar-benar lintas domain, multi-tahap, membutuhkan pembagian kerja paralel. Masalah kebanyakan orang bukan Agentnya kurang banyak, tapi satu Agent pun belum diatur dengan baik.
Buku ini 453 halaman, diterbitkan Springer tahun 2025. Contoh kode mencakup LangChain/LangGraph, Google ADK, CrewAI, OpenAI API. Kata pengantar ditulis oleh VP AI Google Cloud, dan ada rekomendasi dari CIO Goldman Sachs, mengejutkan bagus.
Tapi alasan saya merekomendasikannya bukan karena "lengkap". Tapi karena Anda akan menyadari satu hal setelah membacanya: semua lubang yang Anda masuki selama setengah tahun terakhir di dunia Agent, sudah ada yang mengumpulkan menjadi pola. Anda tidak perlu lagi menemukan Reflection, tidak perlu lagi menebak bagaimana Memori harus dibagi lapisan, tidak perlu lagi mencoba topologi komunikasi Multi-Agent mana yang harus digunakan.
Ada orang yang sudah menggambar peta untuk Anda, sisanya tinggal melangkah.
Apakah Anda menggunakan AI Agent untuk pengembangan? Agent Anda sekarang sampai Level berapa?





