Oleh | Alter
Pada pagi hari 24 April, DeepSeek V4 yang telah lama dinantikan akhirnya menunjukkan wujud aslinya.
Pada hari yang sama, DeepSeek-V4-Pro langsung menduduki puncak daftar model open-source Hugging Face, dengan dua "inovasi bom nuklir" yang banyak dibicarakan:
Pertama, konteks ultra-panjang hingga jutaan token, tetapi KV cache hanya 10% dari V3.2, dipuji oleh insinyur Amazon sebagai solusi untuk masalah kelangkaan HBM;
Kedua, adaptasi dengan chip domestik, bekerja sama erat dengan Huawei dalam proses pengembangan, dan langsung mengadaptasi chip domestik seperti Ascend dan Cambricon.
Kebetulan, peringkat kedua di daftar model open-source Hugging Face adalah Kimi K2.6 yang dirilis dan dibuka-sumberkan pada larut malam 20 April.
Jika berada di seberang Samudra Pasifik, "bentroknya" dua model dengan parameter triliunan ini pasti akan saling menyerang terkait valuasi dan peta bisnis, tetapi di Tiongkok terjadi adegan yang sangat berbeda: tidak ada drama saling membongkar rahasia, tidak ada perang PR yang tersembunyi, bahkan terjadi "pertukaran" di lapisan teknologi inti.
Di balik "ketidaklaziman" ini, tersembunyi perbedaan pendekatan teknologi AI antara Tiongkok dan AS: Silicon Valley sedang gila-gilaan "mendirikan tembok tinggi", berusaha mempertahankan keuntungan yang sudah didapat dengan sistem tertutup; sedangkan vendor model besar Tiongkok memilih "membongkar tembok", dan berevolusi secara kolaboratif di tanah open-source.
01 Silicon Valley Terjerat dalam "Permainan Kekuasaan"
Berbeda dengan jalur open-source model besar Tiongkok yang berkembang pesat, OpenAI, Anthropic, dan Google Gemini sebagai pemimpin AI Silicon Valley, semuanya adalah pendukung sistem tertutup.
Ketika inovasi teknologi mutakhir terkunci di pusat data masing-masing, di bawah tekanan berat biaya komputasi dan harapan pasar modal, "semangat Silicon Valley" yang terkenal dengan keterbukaan dan kolaborasi perlahan menghilang, dan para pelaku tak terhindarkan terjebak dalam "permainan kekuasaan" zero-sum.
Dalam dua tahun terakhir, "perang dingin" teknologi telah berubah menjadi saling membongkar secara terbuka, dengan cara paling khas adalah saling "mencuri perhatian": pada momen kunci pesaing merilis produk baru, dengan cepat meluncurkan pembaruan berat dari produk sendiri untuk meredam suara pihak lain, telah menjadi operasi rutin di Silicon Valley.
Sejak Mei 2024, OpenAI dan Google pernah merilis produk AI baru secara bersamaan, satu pihak mengatakan GPT-4o terdepan di dunia, pihak lain mengatakan keluarga Gemini dapat mencakup seluruh ekosistem dan jalur. Akhirnya CEO kedua perusahaan tidak tahan, dan secara terbuka mengejek satu sama lain di media sosial.
Tidak hanya "pertarungan" dengan Google, persaingan OpenAI dengan Anthropic juga memanas: pada 16 April, Anthropic baru saja merilis model baru Claude Opus 4.7, OpenAI dua jam lebih kemudian mengumumkan pembaruan besar Codex, dengan slogan "Codex for (almost) everything". Jelas bagi yang tahu, bentrokan waktu ini bukan kebetulan, tetapi merupakan "penyergapan" yang direncanakan matang oleh OpenAI terhadap Anthropic.
Selain "pertarungan intelek" di medan opini, "pertarungan fisik" saling membongkar rahasia juga menjadi hal biasa di Silicon Valley.
Anthropic pada 7 April dengan gegap gempita mengumumkan pendapatan tahunan mencapai 30 miliar dolar AS, berhasil melampaui 25 miliar dolar AS OpenAI.
Seminggu kemudian, Kepala Pendapatan OpenAI dalam surat internal kepada semua karyawan dengan terus terang指出: pendapatan tahunan 30 miliar dolar AS yang diklaim Anthropic mengandung air, karena menggunakan "metode kotor", memasukkan bagi hasil yang diberikan kepada penyedia layanan cloud seperti Amazon dan Google, juga dihitung penuh ke dalam total pendapatannya, menyebabkan pendapatan tahunan dilebih-lebihkan sekitar 8 miliar dolar AS.
Praktik merusak lawan dalam surat internal tidak umum di industri teknologi, tujuannya tidak lain adalah memberi tahu investor — mitos pertumbuhan Anthropic mengandung air.
Dan sekali permusuhan tumbuh, akan mempengaruhi setiap keputusan tanpa celah.
Setelah Anthropic "berselisih" dengan Pentagon karena menolak menghapus klausul keamanan tertentu dalam kontrak, OpenAI beberapa jam kemudian dengan gegap gempita mengumumkan telah menjalin kerja sama dengan Departemen Pertahanan AS.
Pada "Super Bowl" 2026, Anthropic memasang iklan dengan biaya besar, kontennya adalah "Iklan sedang memasuki bidang AI, tetapi tidak akan masuk ke Claude." Bisa dibilang menantang langsung OpenAI yang baru mulai menguji fungsi iklan.......
Mengapa "saudara seperguruan" masa lalu, sampai pada titik yang tidak bisa didamaikan?
Akar masalahnya terletak pada logika固有 model bisnis tertutup: akar kelangsungan hidup tertutup terletak pada membangun parit pertahanan, dan prasyarat membangun parit pertahanan adalah memblokir difusi teknologi, memonopoli produktivitas paling canggih. Ditambah dengan ketidakcocokan rute teknologi, narasi produk yang bertentangan, secara alami membentuk keseimbangan Nash: siapa yang "gencatan senjata" dulu, narasi mereknya akan runtuh, akhirnya semakin terperosok dalam kubangan konsumsi internal.
02 "Evolusi Kolaboratif" Kubu Open-Source
Alihkan pandangan ke Tiongkok, alur naskahnya sangat berbeda.
Kembali ke waktu lebih dari setahun yang lalu, kemunculan mendadak DeepSeek-R1, menginjak rem untuk lomba startup model besar yang sedang berlari kencang, "enam harimau kecil" model besar yang masuk babak final menjadi sasaran pertama. Perbedaan terbesar dengan Silicon Valley, DeepSeek tidak berperan sebagai "hiu" yang memakan semua ikan di kolam, tetapi seperti ikan lele yang mengaktifkan seluruh ekosistem model besar Tiongkok, semua orang ramai-ramai merangkul open-source.
Contoh langsung adalah lintasan pertumbuhan yang sangat重合 dengan DeepSeek adalah Moonlight AI (Bulan Gelap) keduanya adalah tim startup yang dimulai pada 2023, keduanya mempertahankan struktur tim yang sangat sedikit orang tetapi kepadatan talenta tinggi, dan keduanya adalah pendukung setia Scaling Law.
Pada Juli 2025, Moonlight AI merilis model open-source pertama di dunia dengan parameter triliunan Kimi K2, dalam laporan teknisnya tanpa tedeng aling-aling mengatakan mengadopsi arsitektur MLA open-source DeepSeek. Untuk model besar, mimpi buruk terbesar menangani teks ultra-panjang adalah tembok memori, dan keunggulan arsitektur MLA terletak pada kompresi KV Cache yang mencapai 93% lebih.
Dengan "standar industri" yang disumbangkan DeepSeek, tim model besar termasuk Moonlight AI tidak perlu mengulang membuat roda, dengan cepat menurunkan biaya inferensi.
Kisah tidak berhenti di sini.
Melihat dokumen teknis DeepSeek V4, dijelaskan secara rinci arsitektur model, salah satu peningkatan penting adalah mengganti pengoptimal sebagian besar modul dari AdamW ke Muon, mencapai kecepatan konvergensi lebih cepat, stabilitas pelatihan lebih optimal.
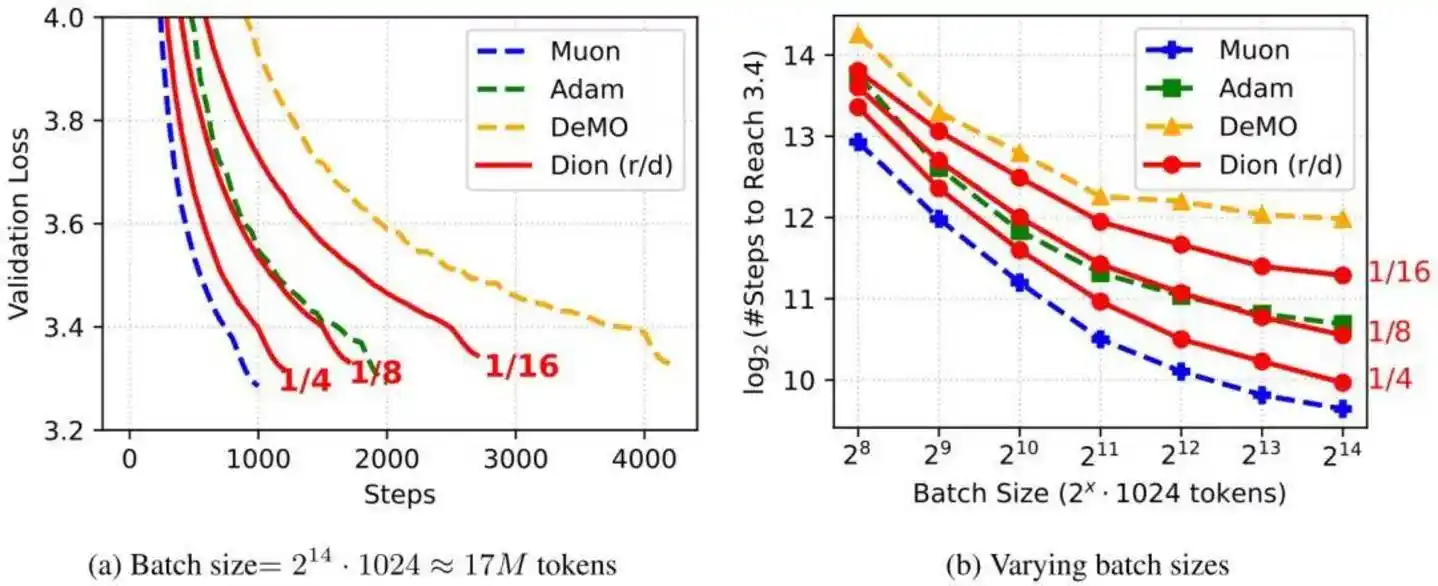
Dalam dokumen teknis Kimi K2.6, juga disebutkan pengoptimal Muon, dalam pelatihan yang sama mencapai peningkatan efisiensi 2 kali lipat.
Pengoptimal Muon yang disebutkan kedua model, pertama kali diusulkan oleh peneliti independen Keller Jordan dalam blog akhir 2024. Tim Moonlight AI yang juga terganggu oleh AdamW, pada awal 2025 melakukan peningkatan teknis kunci pada Muon, menambah kemampuan Weight Decay, kontrol RMS, dan menamakannya MuonClip.
Moonlight AI pada Kimi K2 memimpin memvalidasi stabilitas pengoptimal Muon, mencapai pelatihan pra-latihan "zero Loss Spike". DeepSeek saat melatih model besar V4, juga mengadopsi pengoptimal Muon yang telah divalidasi.
Perlu dijelaskan, "evolusi kolaboratif" model open-source tidak jatuh ke dalam keseragaman, sedang menuju jalan "harmoni dalam perbedaan".
Misalnya DeepSeek-V4 fokus pada kemampuan inti model dasar,进一步 memperkuat langit-langit kinerja model open-source global, menyediakan dasar dasar dengan kinerja menyamai flagship tertutup untuk seluruh industri; Kimi K2.6 mendalami rekayasa Agent, memecahkan titik nyeri eksekusi otonom jarak jauh model besar, membuka jalan penting untuk model besar masuk ke skenario produksi nyata.
Seluruh proses ini, tidak ada negosiasi bisnis yang berlarut-larut, tidak ada perebutan paten yang tegang. Di kubu open-source, inovasi teknologi sedang mengalir bebas seperti air, siapa yang bagus, semua orang pakai.
Menyerap nutrisi dalam ekosistem open-source, saling melengkapi dalam rute teknologi. Vendor model besar Tiongkok, dengan tindakan mendemonstrasikan kemungkinan lain di luar Silicon Valley kepada dunia.
03 AS "Membangun Tembok", Tiongkok "Membuka Jalan"
Sambil mengagumi evolusi kolaboratif open-source, harus menghadapi realitas bisnis.
Saat ini pendapatan tahunan OpenAI dan Anthropic均已 mencapai di atas 10 miliar dolar AS, sedangkan pendapatan vendor model besar terkemuka Tiongkok, baru melangkahi pintu 100 juta dolar AS tahunan.
Valuasi OpenAI di pasar sekunder sekitar 880 miliar dolar AS, valuasi Anthropic telah melonjak ke sekitar 1 triliun dolar AS, sedangkan valuasi putaran pendanaan baru Kimi dan DeepSeek, masing-masing 18 miliar dolar AS dan 20 miliar dolar AS.
Ada yang berteriak valuasi vendor model besar Tiongkok diremehkan, ada juga yang berpendapat: "Apakah bisa mengubah reputasi teknologi menjadi uang sungguhan, adalah ujian hidup mati yang dihadapi vendor Tiongkok." Seketika, diskusi tentang "rasio harga-kinerja" open-source ramai.
Untuk melihat akhir, atau bisa dimulai dari tahap persaingan model besar:

Tahap pertama adalah "adu parameter, adu Benchmark". Pada akhir April 2026, tahap ini基本 berakhir, skor masing-masing di daftar sudah tidak bisa membedakan jarak substansial.
Tahap kedua adalah "adu efisiensi pelatihan, adu biaya inferensi, adu inovasi arsitektur". Ini正是 tahap yang sedang dijalani, juga hasil必然 dari tekanan biaya komputasi.
Tahap ketiga akan adalah "adu sistem Agent, adu ekosistem, adu pengembang". Ketika Token dari流量 gratis menjadi "bahan bakar" menjalankan tugas, kemakmuran ekosistem akan menentukan hidup mati.
Model open-source Tiongkok berada di niche ekosistem apa? Kami menemukan dua组 data perbandingan直观.
Satu adalah biaya pelatihan.
GPT-5 yang dirilis Agustus 2025, biaya pelatihan超过 500 juta dolar AS; Kimi K2 Thinking pada periode yang sama, biaya pelatihan sekitar 4,6 juta dolar AS; DeepSeek tidak mengumumkan biaya pelatihan model seri V4, tetapi model V3 hanya menghabiskan 5,576 juta dolar AS...... Vendor model besar Tiongkok hanya menggunakan sumber daya kurang dari sisa OpenAI, melatih model dengan level yang sama.
Lainnya adalah volume panggilan.
Memasuki 2026, data platform agregasi multi-model OpenRouter menunjukkan: didorong oleh produk Agent yang diwakili OpenClaw, konsumsi Token global menunjukkan pertumbuhan eksponensial, "tim impian" open-source Tiongkok, dengan reputasi "bagus dan murah", volume panggilan telah连续 melampaui AS selama beberapa minggu.
Alasannya tidak sulit dijelaskan.
Kubu open-source Tiongkok telah menjalankan "roda umpan balik positif": Perusahaan A open-source teknologi底层, Perusahaan B mengadopsi dan melakukan optimasi rekayasa, kemudian mengembalikan hasil dan pengalaman optimasi ke seluruh ekosistem. Jika evolusi model tertutup dibangun di atas pertumbuhan linear tumpukan komputasi海量, yang menunggu rute open-source,将是 difusi eksponensial yang dibawa tabrakan inovasi teknologi.
Menurut laporan penelitian Morgan Stanley, antara 2025-2030 konsumsi token inferensi AI Tiongkok akan mencapai tingkat pertumbuhan tahunan gabungan约 330%,将从 10 triliun token 2025, melonjak ke 3900 triliun token 2030, skala pertumbuhan 370 kali lipat.
Artinya, 2026 masih处于 tahap awal ledakan AI, masih ada peluang pertumbuhan ratusan kali lipat 5 tahun ke depan, jauh dari saatnya untuk menarik kesimpulan.
Justru kepercayaan diri pada peluang jangka panjang, saat raksasa Silicon Valley拼命 membangun tembok, vendor model besar Tiongkok memilih dengan cara kolaborasi saling melengkapi, terus memperkuat jalan menuju AGI.
04 Ditutup
Dalam gelombang AI yang menggemparkan ini, siapa yang akan tertawa terakhir? Jawabannya tidak hanya terkait model, tetapi juga terkait otonomi dan kendali komputasi. Jika model diibaratkan "bom atom", maka komputasi domestik yang terbebas dari blokade teknologi eksternal adalah "roket" yang mengantarkan bom atom ke langit.
Yang menggembirakan, integrasi model domestik dan komputasi domestik semakin erat: dalam dokumen teknis DeepSeek V4, NPU Ascend dan GPU NVIDIA并列 ditulis dalam daftar verifikasi perangkat keras; Moonlight AI dalam makalah terbaru menjalankan pra-pengisian dan dekode inferensi model besar pada chip yang berbeda, membuka pintu bagi partisipasi besar-besaran chip domestik dalam inferensi model.
Awal 2025, DeepSeek R1 memperoleh kesempatan untuk model besar domestik naik ke meja permainan; sampai 2026, kubu model besar open-source Tiongkok,正在 dalam kolaborasi terus menciptakan更多 modal keras yang mendefinisikan aturan meja.







