Bidang generasi gambar dari teks telah menjadi lautan merah, tampaknya sudah sangat padat dan kompetitif.
Apa yang Anda butuhkan untuk melatih model generasi gambar dari teks yang sangat baik saat ini?
Jika memulai dari solusi utama saat ini, diperlukan: pengkode-dekode VAE yang telah dilatih sebelumnya, penyambungan pengkode teks, mekanisme injeksi kondisi yang dirancang dengan hati-hati, data dalam jumlah besar, tahap penjajaran RL atau DPO......
Secara keseluruhan, semua orang tampaknya menerima premis: membuat gambar dari teks harus serumit ini.
Namun, tim He Kaiming mengambil pendekatan berbeda, melakukan pemikiran baru di bidang model generasi gambar dari teks. Mereka merilis MiniT2I —— model generasi gambar dari teks ruang piksel yang sengaja mengejar kesederhanaan ekstrem.
Tidak ada pengkode-dekode VAE, tidak ada injeksi kondisi AdaLN, tidak ada fungsi kerugian tambahan, tidak ada data privat, tidak ada penjajaran RL/DPO, target pencocokan aliran murni dilatih langsung pada piksel. Versi B/16 dengan 258M parameter mencapai 0,87 pada GenEval dan 84,2 pada DPG-Bench, mengungguli model ruang piksel sejenis dengan parameter beberapa kali lebih besar.

Klaim inti MiniT2I adalah: Jika kondisi teks dianggap sebagai 'token konteks dengan informasi semantik' yang disuntikkan ke model, pada dasarnya tidak ada perbedaan besar antara generasi gambar dari teks dan generasi ImageNet dengan kondisi kategori —— arsitektur bisa serupa, daya komputasi bisa sebanding, bahkan skala data juga bisa disejajarkan.

- Judul makalah: A Minimalist Baseline for Text-to-Image Generation
- Blog teknis: https://peppaking8.github.io/#/post/minit2i
- Alamat sumber terbuka: https://github.com/PeppaKing8/minit2i-jax
Jalur Teknis: Setiap Langkah Melakukan Pengurangan
Langsung Keluar dari Ruang Piksel, Tanpa VAE
Pilihan desain pertama MiniT2I cukup radikal: membuang VAE, melakukan denoising langsung pada piksel RGB.
Model difusi laten (Latent Diffusion) adalah paradigma utama saat ini, pertama-tama mengompresi gambar ke ruang berdimensi rendah dengan autoencoder baru melakukan difusi. Ini memang membuat resolusi tinggi menjadi layak, tetapi mengorbankan kesalahan rekonstruksi, tahap pelatihan tambahan, dan masalah ketidakselarasan target antara encoder dan denoiser.
Alasan MiniT2I memilih ruang piksel sangat praktis: untuk resolusi 512×512, menggunakan patch 16×16 untuk memotong gambar menjadi 1024 token, panjang urutan sepenuhnya berada dalam zona nyaman Transformer. Setelah menghapus VAE, perhitungan satu langkah maju turun dari ~1379 GFLOPs menjadi ~570 GFLOPs (pengaturan B/16), dan tidak ada masalah batas atas akurasi rekonstruksi —— sebaik apa kemampuan denoiser, sebaik itu pula keluarannya.
Eksperimen juga mengonfirmasi hal ini: Dengan anggaran parameter yang sama, FID model piksel setara dengan model ruang laten (18,7 vs 19,0), tetapi biaya per langkah lebih rendah 5 kali lipat.

Arsitektur MM-JiT: Kembali ke Transformer Sederhana
MM-DiT dari SD3 menggunakan AdaLN (Adaptive Layer Normalization) di setiap blok untuk menyuntikkan langkah waktu dan pengkode teks terpooling ke jaringan —— setiap sub-blok perlu menghitung parameter skala, shift, dan gate, yang dihasilkan melalui MLP tambahan dari vektor kondisi. Ini adalah mekanisme modulasi yang canggih, tetapi MiniT2I menemukan bahwa itu tidak wajib.
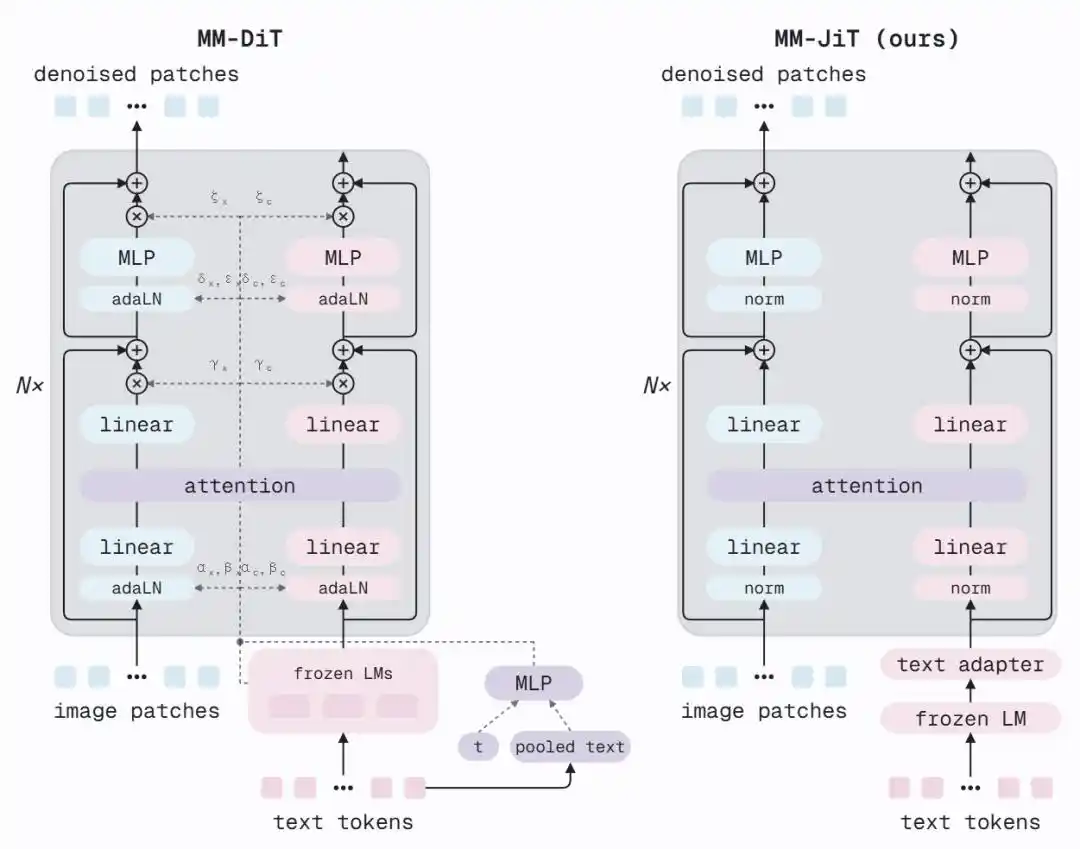
Arsitektur MM-JiT yang diusulkan MiniT2I melakukan dua hal:
1. Menambahkan dua adaptor teks: Sebelum perhatian gabungan, sisipkan dua blok Transformer ringan, biarkan fitur T5 yang dibekukan 'beradaptasi' terlebih dahulu dengan kebutuhan denoiser.
2. Menghapus cabang AdaLN: Tidak lagi menyuntikkan informasi langkah waktu dan teks global melalui jalur tambahan. Model masih dapat merasakan tingkat noise —— karena gambar yang tercemar noise itu sendiri membawa informasi langkah waktu.
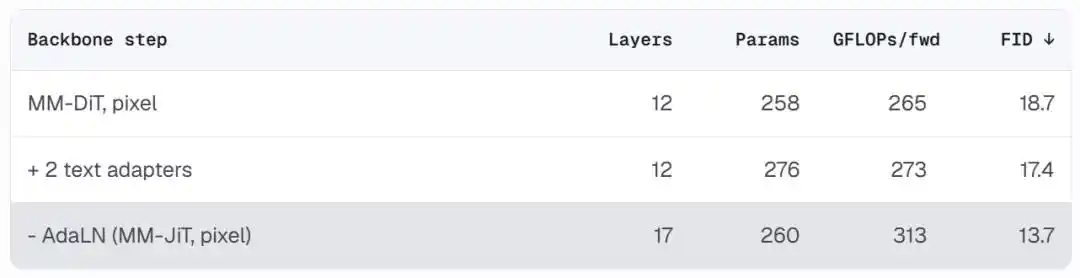
Hasilnya adalah arsitektur bersih yang mendekati Transformer pra-normalisasi standar. Setelah menghapus AdaLN, parameter berkurang, tetapi anggaran daya komputasi yang sama dapat ditukar dengan lebih banyak lapisan (12 lapis → 17 lapis). FID turun dari 18,7 menjadi 13,7, sementara arsitektur itu sendiri lebih mudah dipahami dan dimodifikasi.
Data Pelatihan: Sepenuhnya Publik, Dua Tahap
Data pelatihan MiniT2I juga mengejar kesederhanaan ekstrem:
- Pra-pelatihan: LLaVA-recaptioned CC12M (dataset yang diberi label ulang oleh VLM yang tersedia secara publik), 250K langkah
- Penyetelan halus: ~120 ribu pasangan gambar-teks berkualitas tinggi (BLIP3o-60K + LAION DALL・E 3 Discord set + ShareGPT-4o-Image), 40K langkah
Mode 'pra-pelatihan - penyetelan halus' dua tahap ini sepenuhnya menyamai paradigma pelatihan LLM: pra-pelatihan untuk cakupan, penyetelan halus untuk mengajari model apa jawaban yang baik. Ablasi menunjukkan keduanya tidak dapat dipisahkan —— hanya pra-pelatihan, kualitas gambar bisa baik tetapi pemahaman prompt buruk; hanya penyetelan halus, dunia yang dilihat model terlalu sempit, keragaman generasi kolaps.
Hasil: Model Kecil, Performa Besar
Dalam perbandingan generasi gambar dari teks ruang piksel, rasio harga-kinerja MiniT2I sangat menonjol:
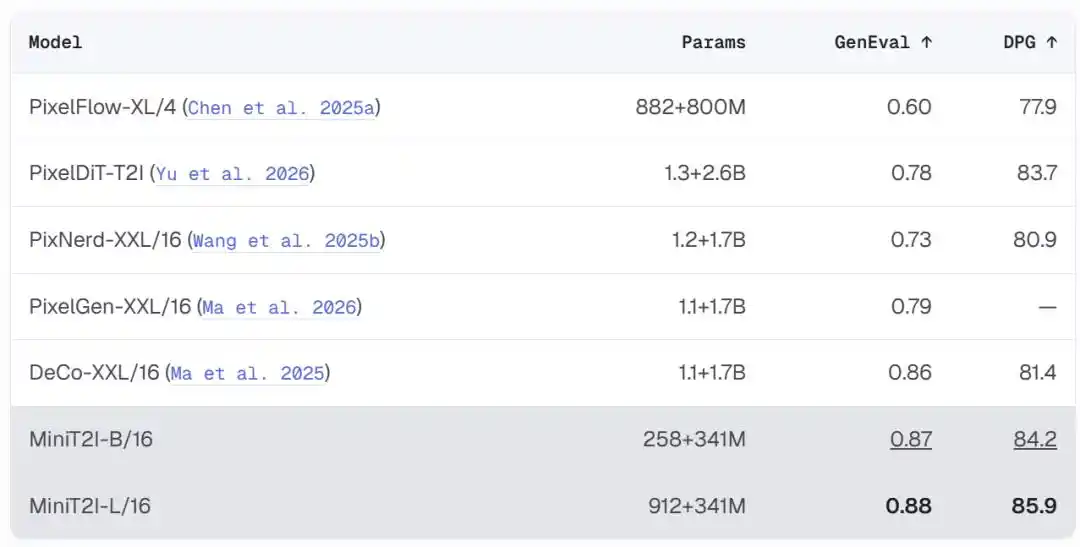
MiniT2I-B/16 hanya menggunakan total ~600M parameter (termasuk pengkode teks), telah mengungguli model dengan parameter 3-4 kali lebih besar darinya pada GenEval dan DPG-Bench. Dan biaya pelatihan sangat rendah: model ablasi B/32 hanya membutuhkan sekitar 3 hari pada 8 H100, total FLOPs pelatihan setara dengan eksperimen standar 200 epoch ImageNet.
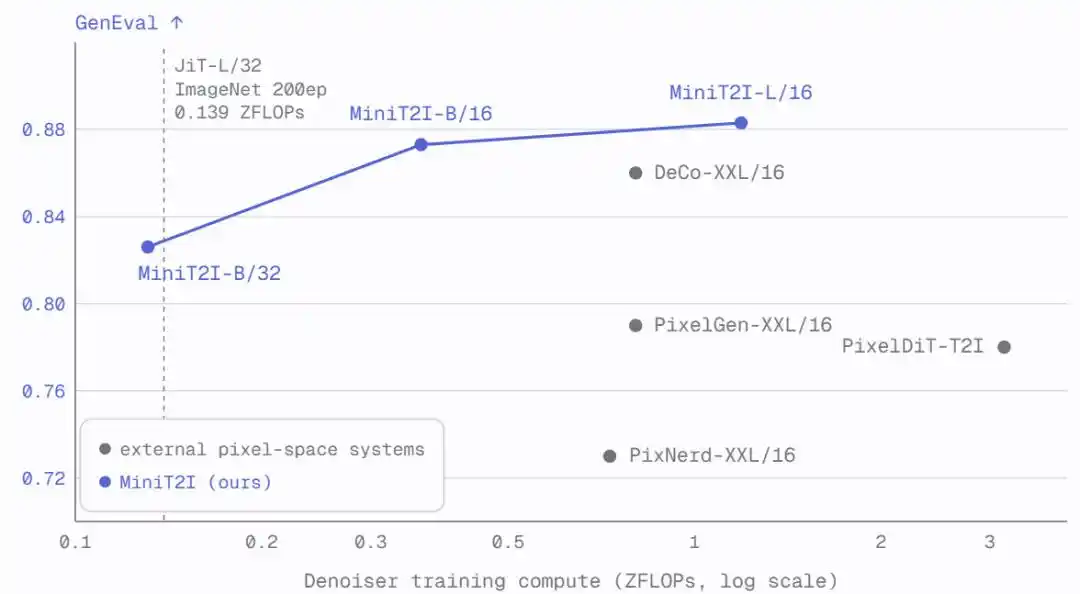
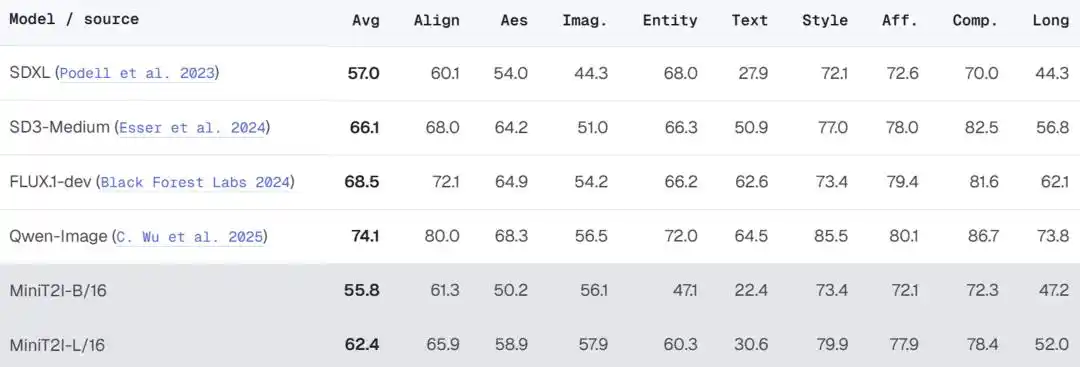
Setelah diskalakan ke L/16 (912M parameter), model menunjukkan kemajuan yang jelas dalam keragaman gaya, hubungan spasial, dan rendering teks, dengan kualitas generasi pada skenario imajinatif setara atau bahkan lebih baik dari SD3-Medium (~2B parameter).
Dalam evaluasi PRISM-Bench yang lebih komprehensif, MiniT2I-L/16 menunjukkan kinerja luar biasa dalam dimensi gaya, komposisi, dan imajinasi (79,9, 78,4, 57,9), sudah mendekati level SD3-Medium. Namun, masih tertinggal dalam rendering teks (30,6 vs 50,9 SD3) dan entitas bernama (60,3 vs 66,3) —— tim dengan jujur mengakui ini adalah keterbatasan bawaan dari formula data publik, memerlukan data khusus untuk menutupinya.
Keterbatasan dan Prospek
MiniT2I adalah bukti konsep dari suatu jalur teknis, bukan produk akhir. Tim dengan jujur menunjukkan beberapa masalah yang belum terpecahkan:
- Artefak patch di ruang piksel: Terdapat ketidakkontinuan yang terukur di batas patch (gradien di batas 17-22% lebih tinggi daripada bukan batas), model ruang laten tidak memiliki masalah ini
- Efek samping CFG di ruang piksel: Koefisien panduan tinggi (~6) akan mendorong token lokal menjauhi manifold data, tanpa 'pelunakan' decoder, langsung terpapar sebagai cacat visual
- Batas atas resolusi: Saat ini bekerja baik pada 512×512, mendorong ke 4K+ memerlukan urutan yang lebih panjang atau mekanisme perhatian yang lebih efisien
- Kendala data: Rendering teks dan entitas bernama masih lebih lemah daripada sistem industri, memerlukan data khusus untuk diperkuat
MiniT2I membuktikan bahwa generasi gambar dari teks pada tahap saat ini bukan hanya permainan bagi laboratorium industri papan atas.
Ketika model 258M parameter, menggunakan data murni publik, dilatih dalam 3 hari dengan daya komputasi tingkat akademik dapat mengalahkan lawan dengan ukuran beberapa kali lebih besar, mungkin generasi gambar dari teks sedang mengalami transformasi paradigma dari 'menumpuk materi' ke 'memurnikan'.
'T2I bukan lagi tembok yang tak terjangkau. Selamat menggunakan dan meningkatkannya, membangun baseline yang lebih sederhana.'
Artikel ini berasal dari akun WeChat "机器之心"







