Vous voulez savoir quel grand modèle est vraiment le plus performant dans les tâches d'agent du monde réel d'OpenClaw ?
MyToken a compilé, basé sur un site d'évaluation, un benchmark transparent axé sur l'évaluation des capacités réelles des agents d'IA en codage, en ne regardant que la taux de réussite comme dimension centrale (la vitesse et le coût sont des dimensions indépendantes, analysées séparément par la suite). Complètement public, reproductible, présentant uniquement des critères d'évaluation rigoureux + le Top 10 des taux de réussite les plus récents.
I. Dimension d'évaluation :Taux de réussite
Critère spécifique : Le pourcentage de tâches données que l'agent d' complète avec précision. Chaque tâche suit un processus hautement standardisé :
-
Indicateur utilisateur précis (Prompt)
Envoyé à l'agent pour simuler des scénarios de demande utilisateur réels
-
Comportement attendu (Expected Behavior)
Décrit les modes de réalisation acceptables et les points de décision clés
-
Critères de notation (checklist)
Liste une checklist atomisée de critères de réussite pouvant être vérifiés point par point
II. Trois méthodes de notation
Cette évaluation utilise principalement 3 méthodes de notation
-
Vérification automatisée : Script Python vérifiant directement le contenu des fichiers, les journaux d'exécution, les appels d'outils, etc. (résultats objectifs)
-
Arbitre LLM (Grand Modèle de Langage) : Claude Opus note selon une grille détaillée (qualité du contenu, pertinence, exhaustivité, etc.)
-
Mode hybride : Vérification objective automatisée + évaluation qualitative par arbitre LLM
Toutes les définitions de tâches, les logiques de prompt et de notation sont publiques pour permettre une re-vérification.
III. Tâches utilisées pour l'évaluation
Ce benchmark couvre 23 tâches de différentes catégories. Il couvre de multiples dimensions : interactions de base, manipulation de fichiers/code, création de contenu, recherche et analyse, appels système d'outils, persistance de la mémoire, etc., se rapprochant fortement des scénarios d'utilisation quotidiens d'OpenClaw par les développeurs :
-
Sanity Check(Automatisé) — Traiter des instructions simples et répondre correctement aux salutations
-
Calendar Event Creation(Automatisé) — Générer un fichier calendrier ICS standard à partir du langage naturel
-
Stock Price Research(Automatisé) — Interroger en temps réel le cours de l'action et produire un rapport formaté
-
Blog Post Writing(Arbitre LLM) — Écrire un blog structuré d'environ 500 mots en Markdown
-
Weather Script Creation(Automatisé) — Écrire un script Python pour API météo avec gestion d'erreurs
-
Document Summarization(Arbitre LLM) — Résumé raffiné en 3 parties des thème核心
-
Tech Conference Research(Arbitre LLM) — Rechercher et organiser les informations de 5 conférences tech réelles (nom, date, lieu, lien)
-
Professional Email Drafting(Arbitre LLM) — Refuser poliment une réunion et proposer une alternative
-
Memory Retrieval from Context(Automatisé) — Extraire avec précision des dates, membres, pile technique, etc., des notes de projet
-
File Structure Creation(Automatisé) — Générer automatiquement une arborescence de projet standard, README, .gitignore
-
Multi-step API Workflow(Hybride) — Lire la config → Écrire le script d'appel → Documentation complète
-
Install ClawdHub Skill(Automatisé) — Installer depuis le dépôt de compétences et vérifier la disponibilité
-
Search and Install Skill(Automatisé) — Rechercher une compétence météo et l'installer correctement
-
AI Image Generation(Hybride) — Générer et sauvegarder une image selon la description
-
Humanize AI-Generated Blog(Arbitre LLM) — Transformer un contenu au goût de machine en langage naturel et oral
-
Daily Research Summary(Arbitre LLM) — Synthétiser plusieurs documents en un résumé quotidien cohérent
-
Email Inbox Triage(Hybride) — Analyser plusieurs emails et organiser un rapport par niveau d'urgence
-
Email Search and Summarization(Hybride) — Rechercher dans les emails archivés et extraire les informations clés
-
Competitive Market Research(Hybride) — Analyse concurrentielle dans le domaine des APM d'entreprise
-
CSV and Excel Summarization(Hybride) — Analyser les fichiers tabulaires et produire des insights
-
ELI5 PDF Summarization(Arbitre LLM) — Expliquer un PDF technique avec un langage compréhensible par un enfant de 5 ans
-
OpenClaw Report Comprehension(Automatisé) — Répondre avec précision à des questions spécifiques à partir d'un PDF d'étude
-
Second Brain Knowledge Persistence(Hybride) — Stocker des informations跨sessions et s'en souvenir avec précision
IV. Conclusion核心: Classement Top 10 des Grands Modèles par Taux de Réussite (Meilleur % / Moyenne % )
-
Données mises à jour au 7 avril 2026
-
Meilleur % est le taux de réussite最高en une seule fois, Moyenne % est le taux moyen sur plusieurs essais, reflétant mieux la stabilité
Voici les dix modèles avec les taux de réussite les plus élevés
-
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
- 极
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
-
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
-
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
-
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
-
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
-
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
-
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
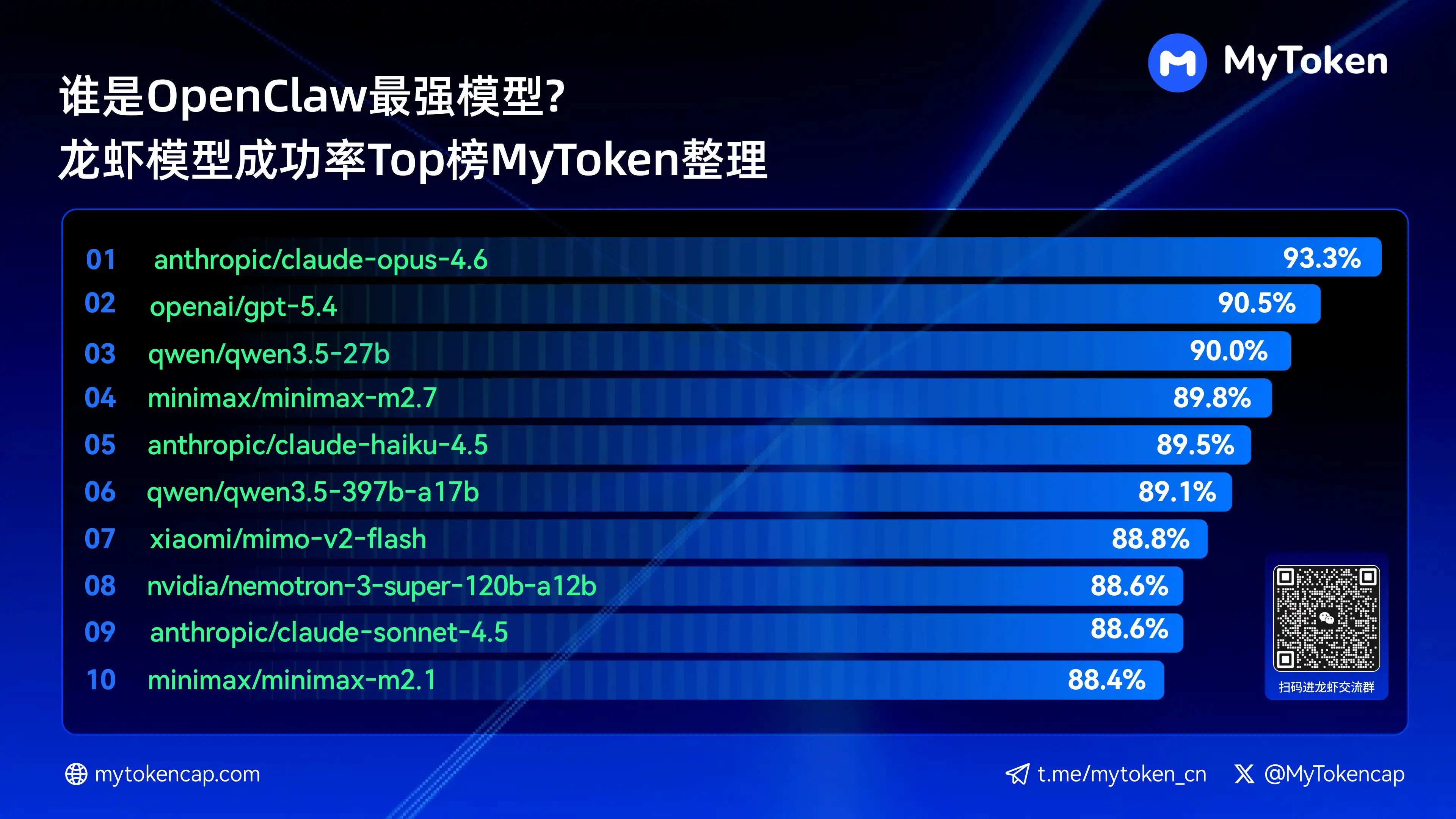
Claude Opus 4.6 mène actuellement avec un taux de réussite最高de 93.3%, mais Trinity d'Arcee表现brillant en stabilité moyenne, et la série Qwen a également plusieurs modèles dans le top 10, montrant un fort potentiel de rapport qualité-prix. Le taux de réussite est un seuil de base, les dimensions de vitesse et de coût affecteront davantage l'expérience réelle.
Ce benchmark de 23 tâches est complètement transparent, nous vous强烈conseillons de le tester dans votre propre scénario. Pour plus de classements d'autres modèles, restez à l'écoute pour la fonctionnalité de classement des agents que MyToken s'apprête à lancer.
(Les données proviennent du benchmark public d'agents OpenClaw de PinchBench, mis à jour en continu.)





