Rédaction : Zhao Ying
Source : Wall Street News
La commercialisation des applications d'IA s'étend désormais de la vente de logiciels et d'abonnements à la vente de capacités d'appel de Tokens. Ici, le Token est la plus petite unité d'information traitée par les grands modèles de langage, et constitue également la base de la facturation, de la comptabilisation et de la consommation des API des modèles. Avec l'augmentation des volumes d'appels, le Token lui-même commence à être acheté, acheminé, fractionné et revendu comme un « stock ».
Dans une analyse sectorielle des médias récemment publiée, l'analyste Chen Liangdong de Huayuan Securities a résumé le changement central comme suit : « L'exploitation des Tokens est en train de former un nouveau marché de couche intermédiaire, explorant les modèles de distribution de Tokens, reliant les fournisseurs de grands modèles en amont aux développeurs, entreprises et particuliers en aval. L'essence en est l'infrastructure de liquidité pour le réseau mondial de gros et de détail des Tokens. »
Le contexte de cette activité n'est pas complexe : d'un côté, le volume d'appels de Tokens en Chine augmente rapidement, passant de 100 milliards par jour début 2024 à 100 000 milliards fin 2025, pour atteindre 140 000 milliards en mars 2026. De l'autre, les capacités des grands modèles chinois ont progressé, atteignant désormais le premier rang mondial dans certains classements et volumes d'appels. La demande augmente, les modèles se multiplient, et les véritables freins à la transaction deviennent le paiement, le réseau, les interfaces, la conformité, les canaux et la mise en œuvre des scénarios.
Mais la distribution de Tokens ne peut pas être simplement comprise comme un « trafic de quotas d'API ». La couche de profit la plus fine provient de la marge de revente, tandis que les parties plus importantes viennent de l'accélération de l'inférence, des interfaces unifiées, de l'ingénierie des prompts côté entreprise, de l'orchestration d'agents, de la sélection de modèles et de l'intégration des systèmes métier. Et précisément parce que le seuil d'entrée n'est pas très élevé, les risques de ce marché sont tout aussi directs : l'intensification de la concurrence, le financement des stocks et les créances douteuses, ainsi que les changements de politique des fournisseurs de modèles en amont, peuvent tous comprimer les marges de la couche intermédiaire.
Le Token a désormais ses « grossistes » et ses « détaillants »
La chaîne de base de la distribution de Tokens comprend trois types d'acteurs.
En amont se trouvent les fournisseurs de modèles, notamment les séries Seedance de ByteDance, Qwen d'Alibaba, GLM de Zhipu AI, Kimi de Moonshot AI, DeepSeek, etc. Ils sont les sources d'approvisionnement en Tokens.
Au milieu se trouvent les plateformes d'agence, chargées de recevoir les ressources des modèles en amont pour les redistribuer aux utilisateurs finaux. Leur travail ne se limite pas à revendre des quotas ; elles doivent également convertir les protocoles d'interface de différents modèles en un format API unifié, permettant aux utilisateurs en aval d'accéder à plusieurs modèles avec une seule clé API.
En aval se trouvent les consommateurs réels de Tokens, comprenant les utilisateurs individuels, les développeurs, les clients entreprises, et éventuellement des distributeurs de niveau inférieur.
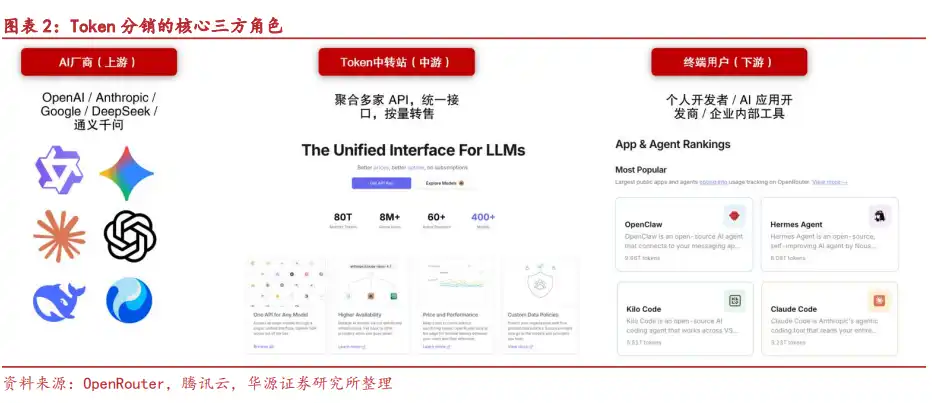
La valeur de cette couche intermédiaire se concentre sur plusieurs points : la connexion directe en Chine réduit les barrières réseau ; un seul code s'adapte à plusieurs modèles ; le support des paiements personnels et des paiements entreprise ; l'obtention potentielle de coûts plus bas grâce aux achats en gros ; l'agrégation de modèles divers comme GPT, Claude, DeepSeek, Kimi sur une seule plateforme, réduisant les coûts d'intégration répétée pour les développeurs.
Ainsi, la distribution de Tokens semble être un modèle à faible intensité d'actifs, ne nécessitant ni d'entraîner son propre grand modèle, ni de disposer d'importantes grappes de serveurs. Les actifs centraux deviennent le système de routage et de dispatch des API, les ressources en modèles en amont, la clientèle des canaux et les capacités de service.
L'explosion des volumes d'appel est le carburant le plus direct de cette activité
Pour que le modèle d'exploitation des Tokens soit viable, il faut d'abord un volume de consommation suffisamment important.
Le volume quotidien d'appels de Tokens en Chine est passé de 100 milliards à plus de 140 000 milliards en deux ans, une multiplication par plus de mille. L'expansion des volumes d'appel provient du déploiement de divers Agents verticaux, ainsi que de l'intégration de l'IA générative dans davantage de processus métiers par les entreprises.
Les données de l'IDC donnent une trajectoire encore plus agressive : le nombre d'agents intelligents actifs dans les entreprises chinoises devrait dépasser 350 millions d'ici 2031, avec un taux de croissance annuel composé supérieur à 135 % ; avec l'augmentation de la densité et de la complexité des tâches des agents, la consommation annuelle de Tokens par agent pourrait augmenter de plus de 30 fois par an.
On peut déjà observer ce changement chez les agents d'exécution. La consommation hebdomadaire de Tokens d'OpenClaw sur la plateforme OpenRouter est passée de 0,81 T (du 2 février au 16 mars 2026) à 4,97 T, sa part passant de 8,31 % à 24,36 %.
Une fois que le Token devient un produit de consommation de masse, les couches d'achat, de tarification, de routage et de règlement qui l'entourent se stratifient naturellement. Les fournisseurs de modèles ne servent pas nécessairement chaque client directement, et les clients finaux ne souhaitent pas nécessairement s'intégrer à chaque modèle un par un, créant ainsi un espace pour la couche intermédiaire.
Le rapport qualité-prix des modèles chinois ouvre la porte à l'exportation des Tokens
L'amélioration des capacités des grands modèles chinois est une variable clé permettant à la distribution de Tokens de passer du marché domestique au marché transfrontalier.
Les données de SuperCLUE montrent que les scores globaux de modèles chinois comme Doubao de ByteDance et la série DeepSeek ont dépassé les 70 points, réduisant l'écart avec les modèles leaders mondiaux comme GPT-5.4 et Gemini ; des modèles comme Tongyi Qianwen, Kimi, et Zhipu GLM ont également formé des échelons relativement clairs.
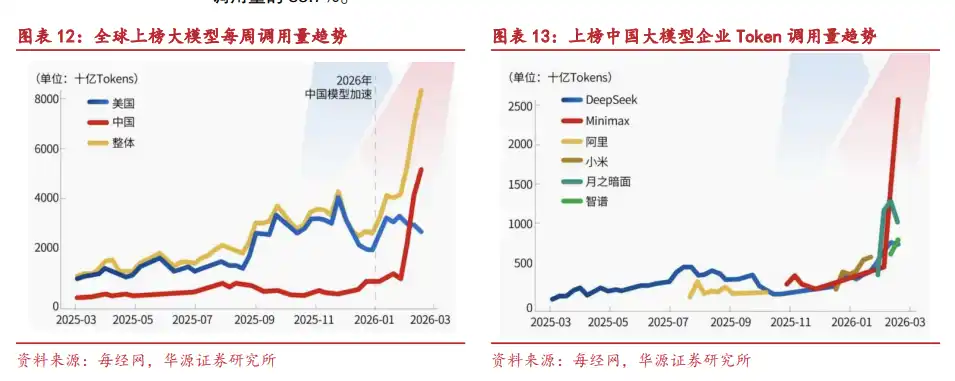
Selon les données d'OpenRouter, pour la semaine se terminant le 10 mai 2026, le modèle Hy3 preview (gratuit) de Tencent se classait en tête des volumes d'appels ; parmi les cinq, dix et vingt premiers modèles, les grands modèles chinois représentaient respectivement 2, 6 et 9 modèles.
Un changement plus significatif s'est produit au premier trimestre 2026. Du 9 au 15 février, le volume d'appels hebdomadaire des modèles chinois sur OpenRouter a atteint 4,12 billions de Tokens, dépassant pour la première fois les 2,94 billions de Tokens des modèles américains sur la même période. Du 16 au 22 février, le volume d'appels hebdomadaire des modèles chinois est encore monté à 5,16 billions de Tokens ; parmi les cinq premiers modèles en volume d'appels sur la plateforme, quatre provenaient de fournisseurs chinois : MiniMax M2.5, Kimi K2.5, Zhipu GLM-5 et DeepSeek V3.2, représentant ensemble 85,7 % du volume total des cinq premiers.
L'avantage de prix est également marqué. Les prix d'entrée du MiniMax M2.5 et du GLM 5 sont tous deux de 0,3 dollar par million de Tokens, contre 5 dollars pour le Claude Opus 4.6 ; pour la sortie, le MiniMax M2.5 est à 1,1 dollar, le GLM 5 à 2,55 dollars, et le Claude Opus 4.6 à 25 dollars. Le rapport qualité-prix des modèles chinois dans les scénarios à forte consommation de Tokens, comme les agents IA et le développement de code, continuera d'être amplifié.
L'inégalité des ressources IA mondiales fait des plateformes de routage des « points de transit »
La distribution de Tokens ne résout pas seulement le problème des prix, mais aussi celui de la mauvaise allocation des ressources.
Les grands modèles leaders mondiaux sont soumis à des restrictions d'accès géographiques, à des règles de conformité et à des barrières de paiement, les empêchant d'atteindre directement certains utilisateurs, y compris les développeurs de Chine continentale. À l'inverse, les grands modèles chinois de qualité cherchant à s'exporter rencontrent également des difficultés d'adaptation locale, de déploiement des canaux et d'acquisition d'utilisateurs.
Cette inégalité a donné naissance à des besoins de flux transfrontaliers, d'agrégation et de routage, et de distribution à plusieurs niveaux.
OpenRouter est déjà un exemple typique. Le volume de Tokens traité par sa plateforme est passé de 5 à 7 billions par semaine en 2025, à plus de 20 billions par semaine en avril 2026 ; son chiffre d'affaires annualisé pour 2026 dépasse 50 millions de dollars, soit une croissance d'environ cinq fois par rapport aux plus de 10 millions de dollars de chiffre d'affaires annualisé révélés en octobre 2025.
Il existe des plateformes similaires en Chine. Silicon Flow est une plateforme de services cloud tout-en-un pour grands modèles, basée sur son propre moteur d'inférence pour une accélération efficace, tout en fournissant des services de grands modèles de niveau entreprise. En décembre 2025, la plateforme comptait plus de 9 millions d'utilisateurs inscrits, plus de 10 000 utilisateurs entreprises, et plus de 150 modèles déployés.
Même des capitaux liés à la politique américaine entrent sur ce créneau. Le 5 mai 2026, la société de cryptomonnaie WLFI, étroitement liée à Trump et sa famille, en collaboration avec WorldClaw, a lancé WorldRouter, intégrant plus de 300 modèles dont Claude, GPT, Gemini, avec un règlement en USD1 et des prix environ 30 % inférieurs aux tarifs officiels publics.
Le véritable profit ne se situe pas nécessairement dans la « marge de revente »
La distribution de Tokens offre trois modes de rentabilité.
Le premier est la marge de revente. La plateforme achète en gros des quotas d'API aux fournisseurs de modèles en amont, puis les revend avec une majoration aux clients en aval. OpenRouter, qui ajoute une prime d'environ 5,5 % au coût du fournisseur, est représentatif de ce modèle.
Le second est la prime technologique. La plateforme réduit le coût d'exécution par Token grâce à son propre moteur d'accélération d'inférence, obtenant une marge brute en s'appuyant sur la différence d'efficacité de calcul, même lorsque le prix de vente est proche ou inférieur au prix officiel. Les technologies SiliconLLM et OneDiff de Silicon Flow augmentent la vitesse d'inférence des modèles de langage d'un facteur 10 et l'efficacité de génération d'images d'un facteur 3, réduisant le coût d'appel des API de grands modèles à 1/10 du coût du secteur.
Le troisième est le service à valeur ajoutée pour les entreprises. Le coût de déploiement de l'IA pour une entreprise ne réside pas seulement dans le prix unitaire du Token, mais aussi dans l'ingénierie des prompts, la sélection de modèles multiples, l'intégration des systèmes métier, l'orchestration des flux de travail, la gestion opérationnelle et la formation des employés aux compétences en IA. Alors que le prix de base du Token baisse, ces coûts cachés deviennent paradoxalement des points de paiement plus faciles.

La plateforme MaaS de niveau entreprise de Silicon Flow va dans cette direction : elle offre aux utilisateurs entreprises trois niveaux de capacités (affinage et entraînement des modèles, déploiement et inférence, support au développement d'applications), couvrant le traitement des données, le fine-tuning des modèles, l'ingénierie des prompts et le RAG, pour finalement les livrer sous forme d'API standardisées à des secteurs comme l'énergie, la finance, le gouvernement.
Le marketing, les mini-séries, les jeux, le e-commerce sont des scénarios qui consomment plus facilement des Tokens
Pour être rentable, la distribution de Tokens doit finalement s'ancrer dans des scénarios réels.
Les applications d'IA générative pénètrent des secteurs comme la santé, les transports, la fabrication industrielle, et commencent même à participer aux processus décisionnels et stratégiques centraux des entreprises. Mais de nombreuses entreprises ont des bases de transformation numérique faibles, des actifs de données insuffisants et des investissements en puissance de calcul limités, rendant difficile le déploiement direct de capacités d'IA.
En comparaison, les agences de marketing et de publicité disposent déjà de clients et de scénarios, impliquant des domaines comme les mini-séries, les webtoons, les jeux, le e-commerce, où la demande de consommation de Tokens est plus directe et plus soutenue. Pour ces entreprises, l'opportunité ne se limite pas à revendre des capacités de modèles, mais à intégrer les Tokens dans les processus de génération de contenu, de diffusion, de production de matériel, de vidéos, etc., de leurs clients.
Les pistes d'investissement suivent également deux axes principaux :
Une catégorie concerne les entreprises possédant des capacités de modèles de qualité, notamment Alibaba, Tencent Holdings, Kuaishou, Kunlun Tech, Zhipu AI, MiniMax, etc.
L'autre catégorie concerne les entreprises ayant des scénarios de consommation de Tokens forts et une clientèle de qualité, en particulier celles disposant de ressources clients à l'étranger et de scénarios marketing, et qui sont prêtes à investir activement dans le marketing IA et la vidéo IA, notamment EasyHaitian, BlueFocus, etc.
Les risques sont également tangibles : faible barrière à l'entrée, besoin de financement, décision finale de l'amont
Le modèle économique de distribution de Tokens est léger en actifs, mais ses barrières à l'entrée ne sont pas naturellement profondes.
La concurrence intra-sectorielle est le premier risque. Le seuil technologique de la distribution étant relativement faible, les principaux agents, une fois entrés sur le marché avec des avantages en termes de capitaux, de clients et de canaux, pourraient rapidement reproduire le modèle et comprimer les marges.
Le financement des stocks (mise de fonds) et les créances douteuses constituent le deuxième risque. Les distributeurs utilisent souvent des règlements mensuels ou trimestriels avec leurs clients en aval, mais doivent financer à l'avance l'achat de quotas d'API auprès des fournisseurs en amont. Plus l'échelle de consommation de Tokens est grande, plus la pression de financement est forte ; si un client fait défaut, le risque de créance douteuse s'accroît proportionnellement.
Les changements de politique des fournisseurs de modèles en amont représentent le troisième risque. Les fournisseurs de grands modèles contrôlent les prix des API et les règles d'accès, et peuvent ajuster les tarifs ou resserrer les politiques d'accès pour les tiers. Pour la couche intermédiaire, c'est l'élément le plus difficile à contrôler.