Fin 2024, un article intitulé "Streaming Deep Reinforcement Learning Finally Works" (arXiv:2410.14606) a suscité un large débat dans la communauté scientifique. Ses auteurs, de l'équipe de Mahmood à l'Université de l'Alberta, ont consacré de nombreuses pages à décrire une réalité embarrassante : l'apprentissage par renforcement, une méthode qui par nature devrait être capable d'« apprendre en marchant », est presque incapable de le faire à l'ère des réseaux de neurones profonds. Dès qu'on retire le tampon de relecture (replay buffer) ou qu'on fixe la taille du lot (batch size) à 1, l'entraînement s'effondre. Ils appellent ce phénomène la « barrière du flux » (stream barrier).
L'article proposait la série d'algorithmes StreamX, qui, grâce à un réglage minutieux des hyperparamètres, une initialisation parcimonieuse et diverses astuces de stabilisation, franchissaient à peine ce mur.
Pourtant, moins d'un an et demi plus tard, un membre du même groupe de recherche, en collaboration avec des chercheurs de l'institut Openmind, propose une réponse radicalement différente : la racine de la barrière du flux n'est pas « pas assez de données », mais « l'unité choisie pour le pas d'apprentissage (step size) est erronée ».

Titre de l'article : Intentional Updates for Streaming Reinforcement Learning
Adresse de l'article : https://arxiv.org/pdf/2604.19033v1
Dépôt de code : https://github.com/sharifnassab/Intentional_RL
Un coup d'accélérateur, un trou de quelle taille
Imaginez que vous appreniez à garer une voiture. L'instructeur vous dit d'« appuyer sur l'accélérateur pendant 0,1 seconde » à chaque fois. Le problème est qu'en appuyant pendant la même durée de 0,1 seconde, la distance parcourue par la voiture peut varier énormément selon que vous êtes en montée, en descente, à vide ou en charge. Parfois, il manque un centimètre pour se garer parfaitement, d'autres fois, il manque 30 centimètres et vous rentrez directement dans le mur.
C'est précisément ce que fait le pas d'apprentissage traditionnel en descente de gradient : il spécifie de combien les paramètres doivent bouger à chaque fois, mais ne contrôle pas du tout de combien la sortie de la fonction change réellement. En entraînement par lots, lorsque les erreurs de centaines ou milliers d'échantillons sont moyennées, les cas extrêmes sont dilués et le problème n'est pas flagrant. Mais en environnement « flux continu », chaque étape ne dispose que d'un seul échantillon, il n'y a pas de moyenne. Dès que la direction du gradient est instable, l'amplitude de la mise à jour devient erratique — aujourd'hui, avancer de 30 cm, demain, reculer de 50 cm — et le processus d'apprentissage s'effondre dans des oscillations violentes.
Ce phénomène de « sur- et sous-ajustement » (overshooting and undershooting) est particulièrement grave en apprentissage par renforcement, car le gradient à chaque pas de temps varie non seulement en amplitude, mais aussi en direction de manière très rapide.
Redéfinir « combien un pas doit accomplir »
Dans un article récemment publié par Arsalan Sharifnassab de l'institut Openmind et Mohamed Elsayed, A. Rupam Mahmood et Richard Sutton de l'Université de l'Alberta, les chercheurs proposent une approche différente : plutôt que de spécifier combien les paramètres doivent bouger, il vaut mieux spécifier directement de combien la sortie de la fonction doit changer.
Cette idée ne sort pas de nulle part. En 1967, les chercheurs japonais Nagumo et Noda, dans leur article « A learning method for system identification », avaient déjà proposé l'algorithme « Normalized Least Mean Squares » (NLMS) dans le domaine du filtrage adaptatif ; essentiellement, il utilise aussi le changement de sortie souhaité pour déduire le pas d'apprentissage, et non l'inverse. Cependant, cet algorithme ne s'appliquait qu'à des scénarios linéaires simples.
Les chercheurs ont étendu cette idée à l'apprentissage par renforcement profond. Ils l'appellent « mises à jour intentionnelles » (Intentional Updates) : avant chaque mise à jour, définir clairement « ce que je souhaite accomplir avec cette étape », puis en déduire la taille du pas nécessaire.
Pour l'apprentissage de la valeur (c'est-à-dire la prédiction de la récompense future), leur intention est définie comme suit : après chaque mise à jour, l'erreur de prédiction de la valeur de l'état courant doit être réduite d'une proportion fixe — par exemple de 5 %, ni plus ni moins. Pour l'apprentissage de la politique (c'est-à-dire l'optimisation des actions décisionnelles), leur intention est définie comme suit : la probabilité de sélection de l'action courante ne doit changer que d'une quantité « modérée » à chaque étape.
Pour reprendre la métaphore de la conduite : c'est comme si le conducteur décidait avant chaque manœuvre « je veux faire avancer la voiture de 20 cm », puis calculait automatiquement à quelle profondeur appuyer sur l'accélérateur en fonction des conditions de la route (pente, charge), au lieu d'appuyer toujours de la même profondeur et de s'en remettre au hasard.
Le lauréat du prix Turing et son puzzle
L'un des signataires de l'article est Richard S. Sutton — lauréat du prix Turing 2024, largement considéré comme le « père de l'apprentissage par renforcement moderne ».
La stature de Sutton dans le monde académique est comparable à celle de Feynman en physique : il a non seulement proposé l'apprentissage par différence temporelle (TD learning) et le gradient de politique (policy gradient), deux cadres fondamentaux de l'apprentissage par renforcement moderne, mais il a aussi co-écrit avec Andrew Barto le manuel le plus faisant autorité dans ce domaine, « Reinforcement Learning: An Introduction » (maintenant dans sa deuxième édition, accessible gratuitement en ligne). Il a partagé le prix Turing 2024 avec Barto, le jury ayant salué leurs travaux pour « avoir jeté les bases conceptuelles et algorithmiques de l'apprentissage par renforcement ».
Après avoir reçu le prix, Sutton n'a pas choisi de prendre sa retraite, mais a investi la dotation dans l'institut Openmind qu'il a fondé, dédié au financement de jeunes chercheurs souhaitant explorer des problèmes fondamentaux « dans un environnement non soumis aux pressions commerciales ». Ce nouvel article est issu de cette institution à but non lucratif.
Et le premier auteur, Sharifnassab, venait juste de publier le cadre MetaOptimize à ICML 2025, étudiant comment ajuster automatiquement en ligne le taux d'apprentissage. Les deux sujets sont très cohérents : comment rendre le pas d'apprentissage lui-même plus intelligent.
Détails de l'algorithme : plus simple qu'imaginé
La dérivation mathématique des « mises à jour intentionnelles » n'est pas complexe, sa formule centrale peut se décrire en une phrase : le pas d'apprentissage est égal à la « quantité de changement de sortie souhaitée » divisée par « l'influence réelle de la direction du gradient sur la sortie ».
Dans l'apprentissage de la valeur, cette « influence réelle » est la norme du vecteur gradient (mesurant en quelque sorte à quel point la région des paramètres est « raide ») : plus la pente est forte, plus le pas est petit ; plus elle est douce, plus le pas est grand, garantissant ainsi que l'impact de chaque mise à jour sur la fonction de valeur reste constant.
Dans l'apprentissage de la politique, la « quantité de changement souhaitée » est définie comme proportionnelle à la fonction d'avantage : de combien l'action courante est meilleure que la moyenne, la politique bougera d'autant dans cette direction — avec une moyenne mobile pour normaliser l'échelle, assurant qu'à long terme l'amplitude des changements de politique reste stable dans une plage interprétable.
Les chercheurs ont également combiné cette idée centrale avec deux pratiques d'ingénierie : la mise à l'échelle diagonale de style RMSProp (pour gérer les différences d'échelle entre dimensions des paramètres) et les traces d'éligibilité (eligibility traces, aidant à propager le signal de récompense vers les pas de temps passés).
Finalement, trois algorithmes complets sont formés : Intentional TD (λ) pour la prédiction de valeur, Intentional Q (λ) pour le contrôle d'actions discrètes, et Intentional Policy Gradient pour le contrôle continu.



Résultats expérimentaux : égaler SAC même sans GPU
L'article évalue cette approche sur plusieurs benchmarks standards, et les résultats sont impressionnants.
Sur les tâches de contrôle continu MuJoCo (incluant des robots de simulation complexes comme Ant, Humanoid, HalfCheetah), la nouvelle méthode Intentional AC, en configuration flux continu (taille de lot = 1, sans tampon de relecture), atteint des performances finales qui se rapprochent voire rivalisent à plusieurs reprises avec SAC — un algorithme utilisant un grand tampon de relecture par lots et considéré comme l'étalon-or actuel pour ces tâches. En termes de calcul, le nombre d'opérations en virgule flottante requises pour une mise à jour d'Intentional AC n'est qu'environ 1/140 de celui d'une mise à jour de SAC.
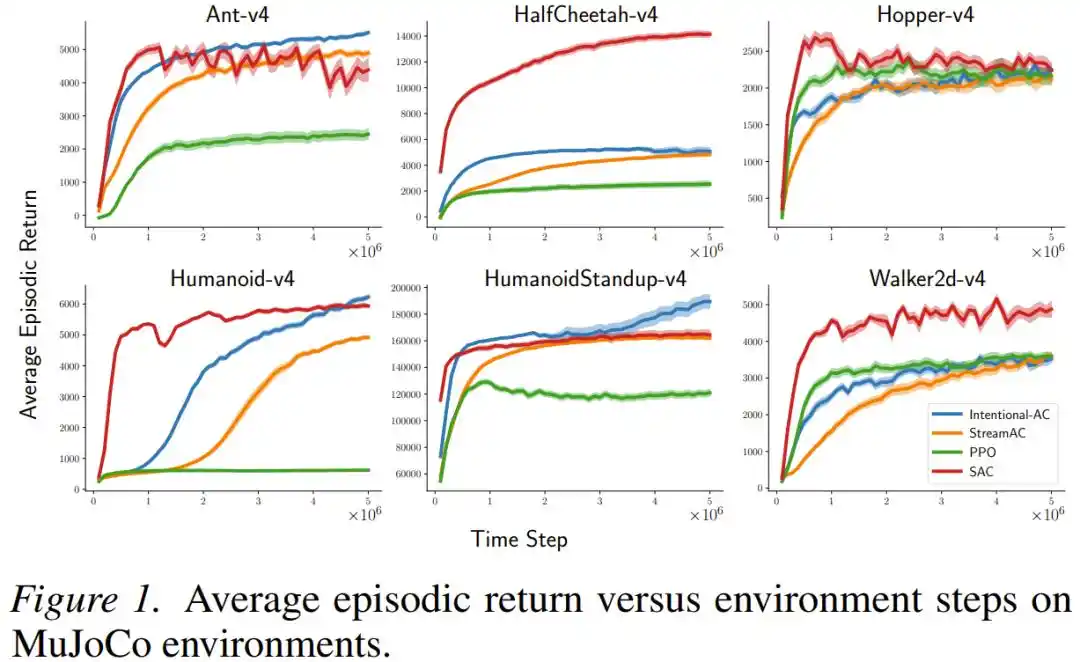
Sur les jeux d'actions discrètes Atari et MinAtar, Intentional Q-learning performe de manière comparable au DQN utilisant un tampon de relecture, et parvient à exécuter toutes les tâches avec le même jeu d'hyperparamètres, sans avoir besoin de les ajuster une par une.
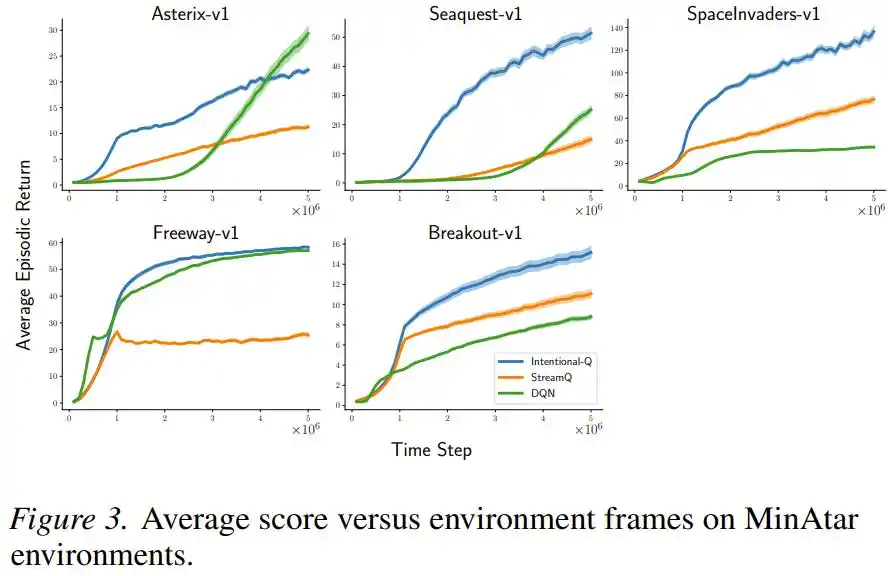
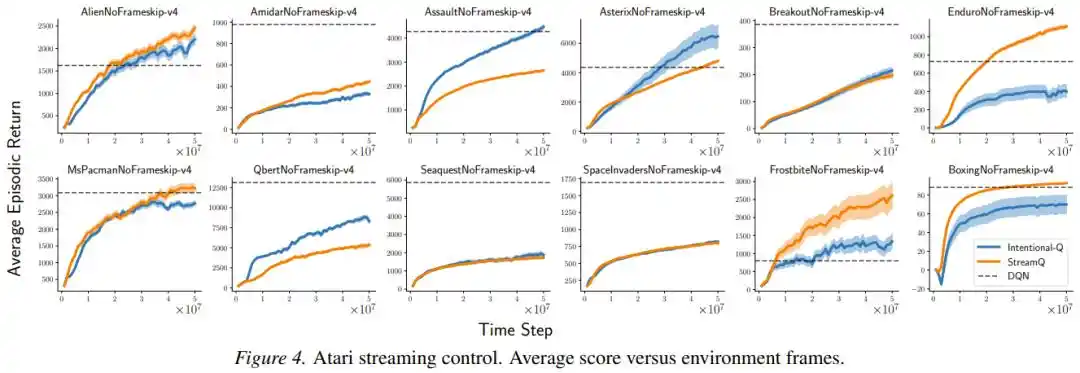
Les chercheurs ont également vérifié spécifiquement si « l'intention » était réellement réalisée : ils ont mesuré le rapport entre le changement réel et le changement attendu. Dans une configuration simplifiée avec les traces d'éligibilité désactivées, l'écart-type de ce rapport n'était que de 0,016 à 0,029, et le 99e centile était toujours inférieur à 1,07 ; signifiant que la grande majorité du temps, la mise à jour a bien fait « exactement ce qui était convenu ».
De plus, une série d'expériences d'ablation montre que retirer la normalisation RMSProp ou le terme σ entraîne une baisse de performance mais la méthode reste compétitive, et que cette « mise à l'échelle intentionnelle » elle-même est le contributeur principal, les autres composants étant des auxiliaires.
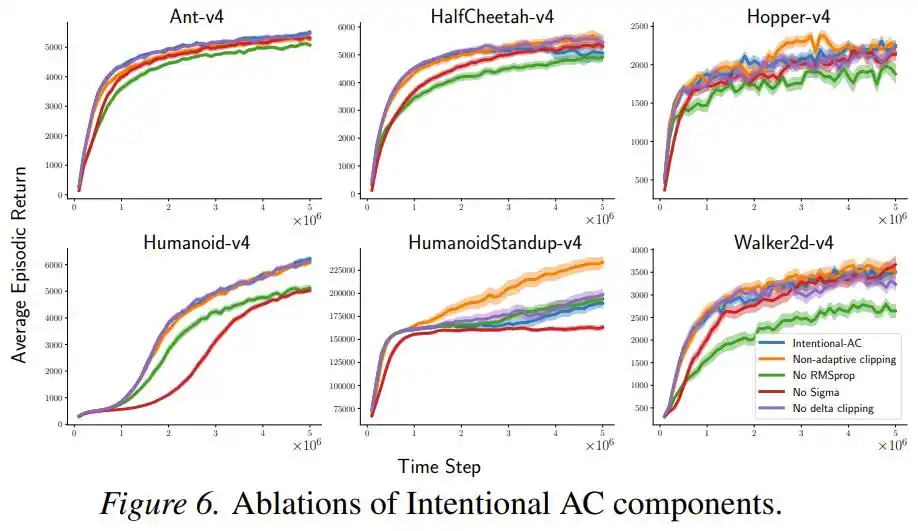
Il reste des problèmes
Le cadre des « mises à jour intentionnelles » montre également un avantage notable en robustesse. Lorsque les chercheurs retirent une à une les diverses astuces de stabilisation dont dépend la méthode StreamX (initialisation parcimonieuse, mise à l'échelle des récompenses, normalisation des entrées, LayerNorm), la dégradation des performances d'Intentional AC est nettement moindre que celle du StreamAC original, indiquant que la mise à l'échelle intentionnelle réduit à la racine la dépendance aux « béquilles » externes.
Mais l'article reconnaît aussi un problème non entièrement résolu : dans l'apprentissage de la politique, la taille du pas dépend de l'action échantillonnée courante, ce qui peut implicitement attribuer des « poids » différents aux différentes actions, et potentiellement altérer la direction attendue du gradient de politique. Dans les tâches Humanoid et HumanoidStandup, en mesurant la similarité cosinus de la direction attendue de la mise à jour, les chercheurs ont constaté que ce biais était proche de 0,96 pendant les phases d'apprentissage critiques (presque aucun impact) ; mais dans Ant-v4, l'alignement descendait à une médiane de 0,63, montrant que le problème ne peut pas toujours être ignoré.
Les auteurs indiquent que les recherches futures devraient chercher des stratégies de sélection de pas indépendantes de l'action, afin que « l'intention » reste non biaisée en espérance. C'est un travail clair laissé aux successeurs dans cette direction.
Conclusion : permettre à l'IA d'apprendre en agissant, comme les humains
Le paradigme d'entraînement dominant actuel des grands modèles repose sur la digestion par lots de masses de données : nourrir tous les textes et codes d'Internet, itérer de manière répétée, pour finalement voir émerger des capacités impressionnantes. Cette voie s'est avérée efficace, mais elle est fondamentalement « apprendre d'abord, utiliser ensuite » : une fois l'entraînement terminé, le modèle est figé, incapable de se mettre à jour continuellement à partir de chaque interaction ultérieure.
Ce que recherche l'apprentissage par renforcement en flux continu, c'est un mode d'apprentissage radicalement différent : ne pas dépendre de masses de relectures, ne pas dépendre d'immenses grappes de GPU, transformer immédiatement chaque expérience en mise à jour des paramètres, de manière continue, économique et adaptative. Cela se rapproche davantage de la manière dont les humains et les animaux apprennent réellement.
De la percée préliminaire d'Elsayed et al. en 2024 « ça fonctionne enfin », au principe de « mise à jour intentionnelle » proposé dans cet article, l'apprentissage par renforcement profond en flux continu mûrit à une vitesse surprenante. Il ne remplacera pas les grands modèles entraînés par lots, mais pour les robots nécessitant une adaptation en ligne à long terme, les dispositifs de périphérie (edge devices), et tout scénario d'application ne pouvant supporter des tampons de relecture massifs et des grappes de GPU, cette voie devient de plus en plus convaincante.
La taille du pas n'est pas juste un hyperparamètre, c'est l'engagement de l'IA sur « combien elle veut accomplir » à chaque étape. Quand cet engagement devient enfin contrôlable, l'apprentissage lui-même se stabilise.
Cet article provient du compte WeChat officiel « Machine Heart » (ID:almosthuman2014), auteur : 关注RL的 (Qui s'intéresse au RL)





