En février 2026, Xiaohongshu a publié une annonce exigeant que les contenus synthétiques générés par IA soient identifiés de manière proactive, les contenus non identifiés étant soumis à une distribution limitée. Plus de trois mois plus tard, un projet open-source nommé guizang-social-card-skill est apparu sur GitHub, spécialisé dans la génération de graphiques 3:4 pour Xiaohongshu et de couvertures pour les comptes publics. Son approche technique présente un choix inhabituel : aucune génération de pixels d'image par un modèle d'IA, l'ensemble de la scène est rendu via HTML+CSS, et les illustrations proviennent de recherches dans des banques d'images comme Unsplash. Le résultat n'est pas une "image générée par IA", mais une capture d'écran d'une page web rastérisée par un moteur de navigateur.
Ce choix correspond à un changement spécifique. Depuis 2026, Xiaohongshu a déployé des modèles de reconnaissance audio-visuelle, analysant la distribution des pixels et les caractéristiques audio pour détecter les contenus AIGC. Durant la même période, plus de 800 000 comptes hébergeant de l'IA et près de 150 000 notes falsifiées par IA ont été traités. Pour les créateurs de contenu graphique nécessitant une production à haute fréquence, la probabilité que les images générées par Midjourney ou Canva AI soient détectées et étiquetées ne cesse d'augmenter. Le Skill de Cang Shifu a choisi une autre voie : laisser l'IA prendre les décisions de mise en page et confier les pixels finaux au moteur de rendu et aux banques d'images réelles.
Il s'agit d'une stratégie technique consciente de contournement. Mais la portée de cette solution dépend de la flexibilité de la définition du terme "contenu synthétique généré par IA" par la plateforme.
28 squelettes de mise en page, l'IA responsable de la logique de composition, pas du dessin
Le vrai nom de Cang Shifu est Guizang, qui avait précédemment publié guizang-ppt-skill, également un outil IA pour la mise en page graphique. Ce social-card-skill est plus ciblé : destiné aux graphiques 3:4 de Xiaohongshu, aux formats carré 1:1 et paysage 21:9 des comptes publics, avec des résolutions de sortie de 1080×1440, 1080×1080 et 2100×900 respectivement.
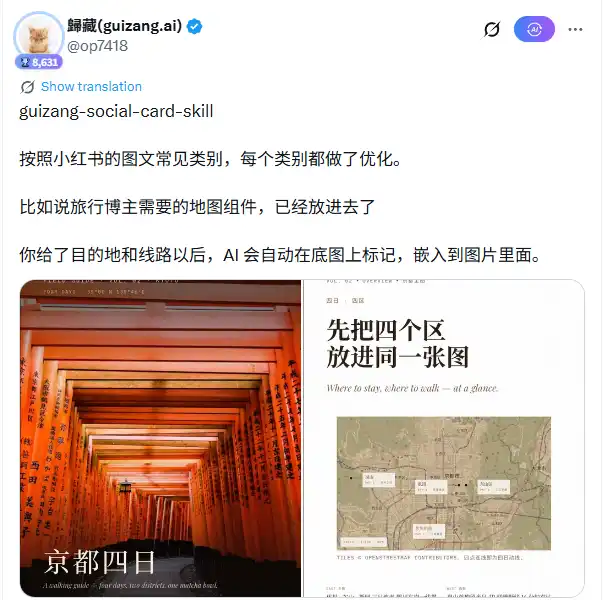
Sur le plan architectural, ce Skill intègre 28 squelettes de mise en page, répartis en deux systèmes visuels : Editorial (style magazine, 16 mises en page) et Swiss (style typographique international suisse, 12 mises en page), accompagnés de 10 jeux de couleurs prédéfinis. Après que l'utilisateur saisisse une destination, un itinéraire ou un thème de note, l'IA choisit le squelette de mise en page approprié, décide de l'emplacement du texte, traite les paramètres d'annotation cartographique, puis écrit toutes ces décisions de conception en HTML+CSS. Le moteur de rendu Playwright prend ensuite le relais, capturant des captures d'écran page par page pour produire des PNG.
Un composant particulièrement utile pour les blogueurs de voyage est le module de carte. Il utilise MapLibre pour charger des tuiles réelles d'OpenStreetMap, prenant en charge le marquage et la connexion de plusieurs lieux. L'utilisateur n'a qu'à fournir un nom de ville ou de site, l'IA génère automatiquement une carte de fond annotée et l'intègre dans la mise en page. Le flux de travail pour les sources d'images a une priorité claire : les photos réelles fournies par l'utilisateur sont prioritaires ; en leur absence, recherche automatique d'illustrations selon l'ordre Unsplash → Pexels → Flickr CC → Wallhaven.

Le processus complet s'exécute en sept étapes : Intake (réception des entrées) → Style & Theme (détermination du style et du thème) → Layout Selection (sélection de la mise en page) → Asset Prep (préparation des éléments) → Compose & Render (composition et rendu) → Deliver & Review (livraison et revue) → Iterate (itérations et modifications). Chaque étape est enregistrée dans des fichiers .poster du répertoire task. Pour une production par lots, exécuter
node render.mjs, Playwright effectue le rendu un par un. Un autre script de validation, validate-social-deck.mjs, mesure les éléments DOM dans un environnement de navigateur réel, détectant les débordements de texte, les tailles de police excessives, les collisions d'éléments de pied de page, etc.L'objectif de conception de ce mécanisme est clair : un contrôle précis comme un logiciel de PAO, et non une liberté imprévisible comme un modèle de diffusion. Le prix à payer est que la liberté créative est confinée à 28 cadres. Pour les créateurs qui dépendent d'un style photographique personnel, d'éléments dessinés à la main ou de collages irréguliers, ces squelettes offrent non pas un gain d'efficacité, mais des contraintes de conception.
Concernant la difficulté d'utilisation, la version CLI nécessite l'installation de Playwright, d'un environnement Node, ainsi que l'obtention d'autorisations API pour Claude Code ou Codex. Il existe une version web accessible via xiaohongshu.guizang.ai pour les utilisateurs non développeurs, mais la parité des fonctionnalités avec la version CLI n'est pas clairement documentée. Plusieurs tweets sur X et des mises à jour répétées du README par le développeur indiquent que le projet évolue rapidement.
Les pixels ne viennent pas d'un modèle génératif, mais la conformité n'égale pas la sécurité à long terme
La logique de détection de contenu IA de Xiaohongshu, d'après les informations publiques et l'analyse technique, repose principalement sur des modèles de reconnaissance audio-visuelle. Ces modèles analysent les caractéristiques de distribution des pixels pour déterminer si le contenu provient d'un modèle génératif d'IA. Les modèles de diffusion et les GAN laissent des empreintes statistiques spécifiques au niveau des pixels lors de la génération d'images, empreintes qui diffèrent des modèles de lumière naturelle, de distorsion d'objectif ou de bruit capturés par les capteurs d'appareils photo. L'objectif d'entraînement des modèles de reconnaissance est précisément de détecter cette incohérence statistique.
La logique d'évitement du Skill de Cang Shifu repose sur une distinction clé : les pixels des images de sortie ne proviennent d'aucun modèle génératif. Le moteur de rendu HTML rastérise les styles CSS, produisant des caractéristiques de distribution de pixels plus proches d'une capture d'écran de navigateur ou d'un logiciel de PAO. La partie photographique provient de banques d'images réelles comme Unsplash, images capturées par des appareils photo, traitées manuellement, sans empreintes de modèles de diffusion.

Mais cette distinction n'est valable que si la définition du "contenu synthétique généré par IA" par la plateforme s'arrête précisément à la ligne "génération de pixels par un modèle d'IA". L'annonce officielle de Xiaohongshu utilise l'expression "contenu synthétique généré par IA", une formulation qui n'est pas étroite. Si la plateforme étend sa définition à la "sortie rendue par programme avec assistance IA", ou incorpore les caractéristiques de rendu de navigateur des images rastérisées HTML dans les jeux de données d'entraînement des modèles de reconnaissance, l'avantage technique actuel de cette solution disparaîtra.
La plateforme a la base technique et la motivation de gouvernance pour étendre la définition. Les modèles de reconnaissance audio-visuelle évoluent en permanence. Si des échantillons comparatifs d'images rendues HTML et d'images générées IA sont incorporés aux données d'entraînement, les modèles peuvent apprendre à distinguer les "caractéristiques d'anticrénelage subpixel du rendu de polices du navigateur" des "blocs de pixels irréguliers des GAN lors de la génération de texte". Aucune information publique n'indique que Xiaohongshu ait lancé un entraînement dans cette direction, mais du point de vue des capacités du modèle, cette extension est techniquement faisable.
Un fait plus notable concerne les exigences de conformité liées aux mini-programmes. Aucun document officiel n'indique que ce Skill est connecté à un numéro d'enregistrement de modèle ou a effectué les démarches de conformité associées. Si la plateforme ajoute des exigences de traçabilité de la chaîne d'outils de génération d'images dans son processus de modération, l'absence d'informations d'enregistrement pourrait devenir un nouveau point de blocage.
Moteur de templates API, outils dédiés aux plateformes et rendu HTML, trois voies qui divergent
En observant les outils de génération d'images pour les réseaux sociaux sur le marché, on constate qu'ils divergent en trois voies techniques distinctes. Chacune fait face à une structure de risque de modération différente.
Génération d'images directe par modèle IA. La fonction Magic Design lancée par Canva AI en avril 2026 en est un représentant, générant des maquettes avec des éléments visuels IA directement à partir d'une invite textuelle. Les images générées par Midjourney, DALL·E, etc., relèvent également de cette catégorie. Le problème est clair : ces images sont la cible principale des modèles de reconnaissance audio-visuelle. L'approche de Canva est d'encourager l'étiquetage transparent, pas d'éviter la détection. Sur Xiaohongshu, on ignore si les publications utilisant des images IA étiquetées voient leur poids de recommandation réduit, mais la politique de "distribution limitée des contenus IA non identifiés" est établie. Chaque mise à jour des modèles de diffusion modifie potentiellement les caractéristiques statistiques des pixels, et les modèles de détection évoluent en conséquence. Les créateurs visent une cible mouvante.
Rendu par moteur de templates API. Bannerbear en est l'exemple typique. L'utilisateur crée un template dans un designer, modifie les variables de calques via une API REST avec des données JSON, et le rendu côté serveur produit un PNG ou JPG. Son cœur est également un "rendu programmatique" et non une "génération de pixels par modèle", la sortie ne contenant pas d'empreintes de modèle de diffusion. La différence avec le Skill de Cang Shifu : les templates de Bannerbear dépendent d'une conception humaine, l'IA ne participe pas aux décisions de mise en page ; le Skill de Cang Shifu laisse Claude lire/écrire directement le HTML, confiant le choix de mise en page à l'IA. Le risque de la solution Bannerbear est ailleurs : lorsque de nombreux comptes utilisent les mêmes templates, couleurs, polices, même si chaque image n'est pas générée par IA, cela peut déclencher la reconnaissance de "production programmatique en masse" du côté de la plateforme. Les règles anti-spam ne sont pas identiques à la détection IA, mais pour les créateurs gérant des comptes en masse, le résultat est similaire : une distribution limitée.
Génération personnalisée par plateforme. Pin Generator est conçu spécifiquement pour Pinterest, générant automatiquement des images Pin alignées avec les préférences de l'algorithme. Le cœur de cette approche n'est pas l'évitement, mais l'adaptation totale — dimensions, style visuel, rythme de publication alignés sur les règles de la plateforme. L'avantage est un risque de modération minimal, l'inconvénient est évident : les capacités de l'outil sont liées aux règles de la plateforme. Si Pinterest modifie son algorithme ou restreint l'accès API tiers, l'outil devient inutilisable. Comparé au Skill de Cang Shifu, le premier est un outil dédié, le second une solution générique multiplateforme. Le dédié est plus sûr mais plus fragile, le générique plus flexible mais plus complexe — un dilemme récurrent dans le domaine des outils IA.
Les structures de risque des trois voies diffèrent. La génération IA est la plus libre mais répond à chaque fois à de nouveaux modèles de détection. Le moteur de templates est le plus stable mais peut être affecté par les règles anti-spam. Le rendu HTML se situe entre les deux : la mise en page est contrôlée de manière flexible par l'IA, les pixels sont confiés au navigateur et à des images réelles, évitant la détection au niveau "génération de pixels IA", mais incapable de faire face à une extension sémantique des règles par la plateforme.
La limite du système de mise en page n'est pas dans le code mais dans le type de contenu
Les 28 squelettes de mise en page couvrent deux systèmes visuels dominants, magazine et suisse. Pour les blogueurs de voyage présentant des itinéraires cartographiques, des chronologies, des programmes multi-jours, ce système correspond bien. L'annotation cartographique et les tracés d'itinéraires sont l'information centrale, les squelettes structurent cette information tout en maintenant un aspect professionnel.
Mais l'écosystème de contenu de Xiaohongshu est bien plus riche. Les notes sur la mode dépendent d'un style photographique personnel et d'une palette de couleurs, les tests de maquillage nécessitent des photos macro haute définition et des comparaisons de produits, les contenus sur le mode de vie utilisent abondamment le collage d'images multiples et les annotations manuscrites. La "mise en page" pour ces types de contenu n'est pas une présentation structurée d'informations, mais une expression d'esthétique et d'émotion personnelle. Dans ces scénarios, les 28 squelettes ne sont pas un outil, mais une contrainte.

Les limitations techniques sont également réelles. Actuellement, trois formats sont supportés : 1080×1440 (3:4 Xiaohongshu), 2100×900 (21:9 comptes publics) et 1080×1080 (1:1 comptes publics). Les formats 9:16 portrait pour les couvertures Douyin ou 16:9 paysage pour Bilibili ne sont pas supportés. Les banques d'images dépendent d'Unsplash et Pexels, dont les contenus penchent vers la photographie de qualité, adaptés aux besoins d'illustration pour le voyage, les paysages, l'architecture urbaine. Mais la couverture d'éléments clés comme les gros plans culinaires, les photos de produits cosmétiques, les vêtements, est limitée dans ces banques. La priorité aux images utilisateur peut partiellement atténuer ce problème, à condition que le créateur dispose d'un stock suffisant de photos réelles.
Le mécanisme de validation est à double tranchant. Le script validate-social-deck.mjs peut intercepter les erreurs de mise en page avant la génération, garantissant zéro erreur sur 100 rendus par lots. C'est une assurance d'efficacité pour les scénarios de production quotidienne de dizaines d'images. Mais cela signifie aussi que toute conception ne respectant pas les règles prédéfinies sera rejetée par le script. Un créateur souhaitant ajouter une décoration textuelle inclinée ou des marges personnalisées dans un squelette standard ne pourra pas simplement glisser-déposer comme sur Canva, mais devra modifier directement le code source HTML et CSS.
Le seuil de déploiement local est un autre facteur de segmentation. Les créateurs capables d'exécuter Playwright et les scripts Node peuvent personnaliser en profondeur les squelettes et scripts de rendu. Mais pour la majorité des blogueurs Xiaohongshu, l'accès se limite à un sous-ensemble fonctionnel via l'interface web. La valeur pratique retirée de ce Skill diffère grandement entre ces deux types d'utilisateurs. Le public principal d'un projet open-source est les créateurs et développeurs techniques prêts à bidouiller, pas le besoin de "génération en un clic" du producteur de contenu moyen.
Pas de réponse universelle, mais la divergence des voies techniques est en soi révélatrice
Un blogueur de voyage sur Xiaohongshu a trois choix : utiliser Midjourney pour générer des illustrations de voyage, assumer le risque d'étiquetage et de déclassement ; utiliser Bannerbear avec un template et alimenter des données quotidiennement, assumer le risque d'homogénéité lié aux règles anti-spam ; ou utiliser le Skill de Cang Shifu, laisser l'IA choisir la mise en page puis générer une image via HTML, assumer le risque d'extension de la définition de "contenu synthétique" par la plateforme. Aucune carte sûre, seulement différentes combinaisons de risques.
Cette situation même transmet un message : l'itération antagoniste entre plateforme et outils IA a commencé. Chaque mise à jour du modèle de détection par la plateforme met fin à la période de rentabilité technique d'un ensemble d'outils. Chaque fois qu'un nouvel outil trouve une voie de contournement, la plateforme ajuste sa stratégie. Ce n'est pas un processus qui converge vers un état stable. La durée de validité de la solution de rendu HTML dépend de l'orientation de l'entraînement des modèles de reconnaissance audio-visuelle de Xiaohongshu : continuer à se concentrer sur les "caractéristiques de pixels des modèles de diffusion" ou s'étendre à "tous les pixels non issus de la photographie native".
Pour les créateurs de contenu, distinguer "assistance IA" et "remplacement IA" prend un sens pratique. L'attitude de la plateforme est claire : encourager l'IA comme amplificateur de créativité, s'opposer à l'utilisation de l'IA pour une production de masse de faible qualité. Dans le Skill de Cang Shifu, l'IA prend des décisions de mise en page, pas de génération de contenu, les photos sont réelles, les mises en page sont des squelettes prédéfinis par des designers humains. Cela tombe précisément dans la catégorie "assistance IA". Les publications utilisant des modèles génératifs à la fois pour le texte et l'image sont clairement les cibles de la plateforme.
On ignore encore si cette distinction deviendra un critère opérationnel de modération pour la plateforme. Mais les développeurs d'outils y répondent déjà par leurs choix techniques.






