Note de la rédaction : Récemment, les discussions sur l'IA et le travail ont été largement dominées par une question : alors que les capacités des modèles continuent de s'améliorer, les emplois de cols blancs seront-ils massivement remplacés ? De la génération de code à l'automatisation du service client en passant par la production de contenu, les Agents prennent progressivement en charge des tâches de travail intellectuel qui nécessitaient auparavant l'intervention humaine. Les tests de référence renforcent également cette anxiété : les performances des modèles en matière de raisonnement de niveau master, de tâches économiques réelles et de refactorisation de code de niveau ingénieur senior progressent rapidement, semblant approcher un seuil critique où le « travail humain serait dévoré par l'automatisation ».
Mais Dan Shipper, PDG d'Every, propose dans cet article une observation inverse : plus nous automatisons, plus le travail à réaliser par les humains est important. Every est un utilisateur intensif d'Agents IA, ayant intégré en interne des outils comme Codex, Claude Code, Slack Agent, des Agents de service client dans les processus de codage, d'écriture, de design, de service client et de gestion. Mais le résultat n'est pas un remplacement total des employés, c'est une réorganisation des formes de travail : les ingénieurs ne se contentent plus de coder, ils examinent, restructurent et conçoivent des systèmes ; les rédacteurs ne se contentent plus d'écrire, ils jugent de ce qui mérite d'être écrit et de comment l'écrire différemment ; les agents du service client ne traitent plus chaque ticket basique, mais maintiennent un système capable de répondre automatiquement aux clients.
Ce qui mérite le plus d'attention dans cet article, ce n'est pas de savoir « si l'IA peut accomplir une tâche donnée », mais comment elle redéfinit la place de l'humain dans le travail intellectuel. L'IA excelle à rendre bon marché les capacités déjà consolidées par le passé : code, textes, miniatures, réponses au service client, notices produits, études peuvent être générés rapidement par des modèles. Mais lorsque ces capacités deviennent accessibles à tous, ce qui apparaît sur le marché n'est souvent pas une production différenciée et de haute qualité, mais une quantité massive de « sorties par défaut » qui semblent similaires, manquant de jugement et de sens du contexte. En d'autres termes, l'IA marchandise les « capacités humaines d'hier », alors que ce qui est vraiment rare, c'est la capacité de jugement face à des problèmes concrets et actuels.
Ainsi, l'automatisation n'élimine pas les experts, elle crée au contraire plus de situations nécessitant leur intervention. Lorsque le personnel opérationnel peut soumettre du code via l'IA, les ingénieurs doivent juger quel code mérite d'être intégré ; lorsque les marketeurs peuvent générer des miniatures en quelques secondes, les designers doivent juger ce qui correspond aux objectifs de marque et de communication ; lorsque les ingénieurs peuvent aussi écrire des articles, les rédacteurs doivent transformer les brouillons en contenu réellement publiable, avec un point de vue et une structure. L'IA étend le rayon de production et amplifie également le besoin de contrôle qualité, de construction de systèmes, de jugement des limites et d'expression différenciée.
L'auteur utilise ensuite les tests de référence pour expliquer ce paradoxe. Que ce soit le Senior Engineer Benchmark ou le GDPval d'OpenAI, les scores des modèles ne mesurent pas une « intelligence » abstraite en soi, mais la performance du modèle dans un cadre de problème spécifique. Le prompt, les limites de la tâche, les critères d'évaluation, le format de sortie contiennent déjà en amont un volume important de jugements humains. Le modèle peut progresser rapidement à l'intérieur du cadre, mais le cadre lui-même est défini par l'homme ; lorsqu'un cadre est maîtrisé par le modèle, les humains poussent le problème vers un nouveau cadre plus complexe.
C'est aussi la réponse la plus intéressante de l'article à l'anxiété liée à l'AGI : même si les modèles deviennent de plus en plus puissants, ce qu'ils rattrapent, c'est souvent une frontière tracée par l'homme, et non la personne qui trace la frontière. L'IA peut exécuter des objectifs, optimiser des chemins, améliorer l'efficacité, mais tant qu'elle répond à des problèmes définis par l'homme, elle manque toujours d'une véritable agentivité. L'avenir du travail intellectuel n'est pas la disparition des humains des processus, mais leur évolution d'exécutants vers des concepteurs de cadres, des mainteneurs de systèmes, des juges de qualité et des définisseurs de sens.
Après l'automatisation, la valeur du travail humain ne disparaît pas, elle devient simplement plus difficile, plus en amont, et plus dépendante du jugement. L'IA rend le « savoir-faire » bon marché, mais rend plus rare le fait de « savoir ce qui vaut la peine d'être fait, pourquoi le faire, et jusqu'où le faire pour que ce soit bon ».
Voici l'article original :
Au cœur de l'IA se trouve un paradoxe.
Chez Every, nous avons automatisé autant que possible. Que ce soit le codage, l'écriture, le design, le service client ou d'autres tâches quotidiennes, nous utilisons Codex et Claude Code. Nous participons également aux tests alpha des nouveaux modèles d'OpenAI, d'Anthropic et de Google avant leur sortie officielle. On peut dire que nous montons aussi vite et aussi profondément que possible sur la vague d'amélioration exponentielle de l'intelligence des modèles et des capacités d'automatisation.
Mais paradoxalement, le travail que les humains doivent accomplir semble plus important que jamais pour nous. Every est actuellement une équipe d'environ 30 personnes ; nous n'avons pas licencié tout le monde parce que nous avons des Agents ; nous n'avons pas non plus abandonné les outils SaaS pour dépendre entièrement d'applications faites avec du vibe coding. Nous recrutons toujours de vrais agents de service client, mais ils sont fortement assistés par des Agents ; nous recrutons aussi toujours des auteurs, des rédacteurs et des ingénieurs.
Cependant, la nature du travail a radicalement changé. Nous n'écrivons presque plus de code à la main. Si vous mentionnez quelqu'un sur Slack, il n'est parfois pas évident de savoir s'il s'agit d'une personne ou d'un Agent. Les managers se mettent à soumettre du code comme des contributeurs individuels en première ligne, et les ingénieurs commencent à faire face directement aux clients. Ces dernières semaines, 95% de mes e-mails professionnels ont été répondus par l'IA. Ma boîte de réception est presque toujours vide – ce qui est extrêmement rare pour moi – mais je vérifie quand même chaque e-mail.
En d'autres termes, l'avenir semble étrange, mais étonnamment familier.
Cette « familiarité » est elle-même surprenante. Parce que PDG, travailleurs du savoir ou investisseurs semblent de plus en plus croire la même chose : l'IA menace l'emploi, l'économie, la sécurité, et même le sens du travail humain.
Dario Amodei, PDG d'Anthropic, a averti que l'IA pourrait éliminer jusqu'à la moitié des emplois de cols blancs juniors. Meta vient récemment de licencier 8000 personnes et a commencé à installer aux États-Unis un logiciel sur les ordinateurs des employés pour enregistrer les mouvements de souris, les clics et les frappes au clavier, afin d'obtenir des données d'entraînement de meilleure qualité pour le travail intellectuel avancé.
Même Ken Griffin, fondateur de Citadel, semble assez ébranlé. Il a récemment déclaré : « Il ne s'agit pas d'emplois de cols blancs de niveau moyen ou faible, mais d'emplois de très haute compétence, qui sont automatisés – je pèse mes mots – par l'IA agentique. »
Les divers tests de référence semblent également étayer ce constat. Avec chaque nouvelle génération de modèles, les indicateurs de capacité progressent à un rythme quasi exponentiel. Dans le test Humanity's Last Exam, qui évalue le raisonnement de niveau master, les scores des meilleurs modèles sont passés de faibles chiffres il y a un an à environ 44% aujourd'hui. Dans le test GDPval, qui mesure la capacité des modèles de pointe à accomplir des travaux économiques réels et les compare aux performances humaines, les scores des modèles sont également passés de niveaux similaires à environ 85%. En mai dernier, le METR, organisme à but non lucratif de recherche sur la sécurité de l'IA, a publié les premiers résultats des tests de Claude Mythos : sur certaines tâches prenant environ 4 heures à des experts humains, ce modèle atteignait un taux de réussite de 80%.
Il semble que nous soyons à la veille d'un point de bascule : une IA plus intelligente que n'importe quel humain, capable de travailler de manière autonome presque toute une journée, se rapproche de la réalité.
Pourtant, le paradoxe demeure. Si vous discutez avec des professionnels de l'industrie de l'IA, ou avec les premiers adoptants en dehors de l'industrie, vous entendrez la même conclusion que notre observation interne : il y a plus de travail à faire qu'avant.
La vraie question qui préoccuple l'industrie et au-delà est : est-ce juste un état transitoire ? La prochaine sortie de modèle ne sera-t-elle pas le moment où tout le monde sera vraiment remplacé ? Nous fixons les courbes des tests de référence, à la fois excités et nerveux, craignant qu'un point de bascule n'arrive à tout moment, après quoi de nombreux emplois disparaîtront soudainement.
Mais je pense qu'il n'y aura pas un tel « point de bascule » qui surviendra soudainement, retournant tout en un instant et faisant disparaître massivement le travail. La nouvelle réalité est précisément le contraire : plus le degré d'automatisation est élevé, plus le travail nécessitant l'intervention d'experts humains est important.
La raison est que l'IA est en train de marchandiser les parties de l'expertise humaine qui peuvent être clairement exprimées, entraînées et reproduites. Toute connaissance pouvant être écrite sous forme de règles, consolidée en processus ou transformée en données d'entraînement deviendra progressivement la capacité par défaut des modèles. En conséquence, la valeur des sorties de modèles ordinaires est rapidement dépréciée, et le marché commence à exiger plus fortement quelque chose de différent.
Et la demande pour quelque chose de « différent » est fondamentalement une demande pour des experts humains. Même si nous nous rapprochons d'une intelligence artificielle générale, cela ne disparaîtra pas.
Pour comprendre pourquoi, il ne faut pas regarder uniquement les courbes des tests de référence, ni se concentrer uniquement sur les paramètres et les classements de capacités des modèles. Nous devons revenir aux scénarios de travail réels et observer comment l'IA d'aujourd'hui est réellement utilisée. Ce n'est qu'ainsi que nous pourrons vraiment comprendre ce paradoxe et la réponse qui se cache derrière.
Comment en sommes-nous arrivés là ?
Depuis 2022, nous suivons l'impact des Agents sur le futur du travail.
Il y a trois ans, j'ai écrit un article sur « l'économie d'allocation ». Mon jugement à l'époque était que collaborer avec des outils d'IA finirait par ressembler de plus en plus au travail d'un manager humain : on n'exécute plus chaque action soi-même, mais on découpe, alloue, supervise et valide les tâches. À cette époque, la question-réponse la plus basique dans ChatGPT était encore considérée par beaucoup comme très futuriste, voire quelque peu dérangeante.
À mi-2025, l'entreprise Every était presque entièrement « Claude Codifiée ». Kieran Klaassen, le directeur général de Cora, s'est soudain rendu compte qu'il pouvait abandonner l'écriture manuelle de code et passer ses journées à donner des instructions en langage naturel à un Agent de programmation dans son terminal. Cette façon de travailler s'est rapidement propagée à toute l'entreprise. Il y a environ 12 mois, j'ai dit dans le podcast de Lenny que Claude Code était l'outil le plus sous-estimé du travail intellectuel.
Je mentionne cela parce que certaines de nos jugements les plus justes par le passé provenaient de l'observation d'Every comme un laboratoire de premiers adoptants. Beaucoup de nouveaux modes de travail apparaissent d'abord en interne ; puis, à mesure que la technologie mûrit et que les outils deviennent plus faciles à utiliser, ces modes pénètrent progressivement un marché plus large.
Et aujourd'hui, de nouveaux changements se produisent en interne.
Deux modes de collaboration avec les Agents
Les façons de travailler autour de l'IA convergent progressivement vers deux modes très différents.
Le premier est une direction déjà assez bien anticipée par les discussions précédentes sur l'IA : considérer l'Agent comme un employé. Ces Agents peuvent se voir déléguer des tâches. Certains Agents vivent dans Slack, ont leur propre nom et responsabilités, et vous pouvez les mentionner directement quand vous avez besoin qu'ils fassent quelque chose ; d'autres Agents sont intégrés dans des flux de travail fonctionnant en continu, comme les systèmes de service client, servant de point d'entrée et de filtre pour les tâches répétitives.
Le second mode est plus étrange, mais dans mon expérience, aussi plus important. Il fait référence à la collaboration humain-Agent dans des outils comme Codex, Claude Code, Claude Cowork. Ces outils ne sont pas seulement des endroits où vous déléguez des tâches ; ils deviennent le système d'exploitation du travail lui-même : vous et plusieurs Agents utilisez simultanément le même « ordinateur », dans le même environnement de travail, pour accomplir des tâches hautement complexes, originales, qui ne peuvent être simplement confiées à un Agent asynchrone.
Dans ces deux modes, vous pouvez automatiser et déléguer une part considérable du travail grâce à l'IA. Mais pour que ces deux modes fonctionnent vraiment bien, ils nécessitent toujours votre participation, ou celle d'un autre humain.
Agent employé
Un Agent employé est celui à qui vous donnez une tâche, et qui, sans votre participation en temps réel, produit une réponse, une action, un rapport, un brouillon ou un jugement de tri.
Ces Agents existent sous au moins deux formes : les « Agents collègues » et les « Agents embarqués ».
1. Agents collègues
Les Agents collègues sont ceux que vous pouvez appeler dans Slack comme vous mentionneriez un collègue, pour qu'ils accomplissent un travail. Ils sont toujours disponibles et peuvent être invoqués quand besoin. Des produits comme OpenClaw, ou notre développement interne Plus One, entrent dans cette catégorie.
Claudie
Claudie est un Agent collègue utilisé par notre équipe de conseil. Il rédige des propositions commerciales, génère des brouillons de matériel de formation, suit les tâches de projet et peut faire plus encore.
Andy
Andy est un Agent collègue utilisé par notre équipe éditoriale. Il collecte dans le Slack interne de l'entreprise les « points de matière » qui méritent d'être développés – c'est-à-dire les bonnes idées qui pourraient devenir des articles – et les synthétise en résumés et points de vue préliminaires, que les auteurs utilisent pour écrire le bulletin quotidien.
Viktor
Viktor est un Agent polyvalent qui assume des travaux transversaux au sein de l'entreprise. Nous l'utilisons pour collecter des indicateurs de croissance, analyser les résultats d'études utilisateurs, et aussi pour transformer des discussions internes désordonnées en notes de recherche et suggestions de produits.
2. Agents embarqués
Les Agents embarqués existent dans des flux de travail produits spécifiques. Ils sont moins flexibles que les Agents collègues, mais sont souvent très efficaces pour traiter des tâches répétitives.
Fin est l'exemple le plus clair. C'est un Agent intégré à notre plateforme de service client, qui peut prendre en charge une grande partie du travail via le chat et les e-mails.
Au cours d'une semaine de mai dernier, Fin a participé à 65% des 202 conversations de service client d'Every, et a clôturé indépendamment 81 tickets sans intervention humaine, soit 40,1% de toutes les conversations traitables.
Ces Agents embarqués permettent à notre responsable du service client, Waqqas Mir, de passer moins de temps à répondre aux tickets basiques et de concentrer davantage ses efforts sur la construction d'« un système capable de répondre automatiquement aux tickets », ainsi que sur le traitement des cas clients nécessitant une approche plus personnelle et des jugements plus complexes.
Collaboration humaine et IA
Que ce soit pour les Agents collègues ou les Agents embarqués, le schéma sous-jacent est le même : les Agents employés prennent en charge davantage de couches de travail stables, répétitives et aux limites claires.
Mais il reste encore une quantité massive de travail qui doit impliquer un humain. Nous constatons à plusieurs reprises que pour les tâches suffisamment complexes, si l'on veut obtenir un résultat vraiment de haute qualité, la meilleure façon n'est pas de confier complètement le travail à l'IA, mais de faire collaborer l'IA et l'humain dans le même espace de travail, en va-et-vient.
C'est précisément la valeur d'outils comme Codex, Claude Code et Cowork. Ils vous permettent de lancer un ou plusieurs Agents dans plusieurs fils de discussion et de leur déléguer des tâches. Ces Agents peuvent accéder à votre ordinateur et à toutes les sources de données pertinentes. Vous pouvez voir ce que chaque Agent est en train d'exécuter, comment il raisonne, et vous pouvez l'interrompre à tout moment.
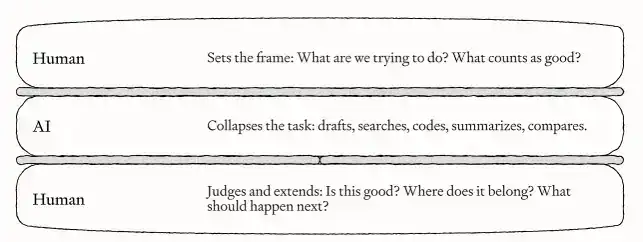
En même temps, vous êtes toujours responsable de la gestion de ces Agents : donner une direction claire au début de chaque tâche, vérifier la qualité à la fin, s'assurer que le résultat est suffisamment bon, et continuer à trouver la prochaine tâche qui mérite d'être avancée. Kieran appelle ce rôle le « sandwich » humain – l'IA s'occupe de la partie centrale du travail, et les humains sont comme les deux tranches de pain, encadrant le début et la fin de la tâche.
L'exemple le plus typique est l'écriture de code. Chez Every, les ingénieurs collaborent en va-et-vient avec des Agents toute la journée. Ils planifient ensemble de nouvelles fonctionnalités ou des corrections de bugs, examinent le travail déjà accompli ; et s'ils adoptent ce que nous appelons la philosophie de « l'ingénierie composite », ils optimisent continuellement leur propre système pour le rendre plus utile au fil du temps.
Mais cette façon de collaborer va bien au-delà du codage.
Le nouveau système d'exploitation du travail intellectuel
Codex et Claude Code deviennent un nouveau système d'exploitation du travail. Je passe presque toute la journée dans Codex, utilisant son navigateur intégré pour exécuter divers outils SaaS. Cela me permet d'amener un Agent dans chaque scénario de travail et d'atteindre un niveau que je ne pourrais pas atteindre seul.
Écriture
Cet article, je l'ai écrit dans Proof, dans le navigateur intégré de Codex. Codex observe ce que j'écris et peut à tout moment lancer un sous-Agent pour accomplir n'importe quelle tâche dont j'ai besoin : rédiger le brouillon d'un paragraphe, trouver des exemples pour la partie suivante, ou faire de l'édition et du polissage de texte.
E-mails
Pour traiter les e-mails, j'utilise la même approche. Cora est mon client de messagerie, je l'ouvre dans le navigateur intégré de Codex, et pendant que je parcours ma boîte de réception, je dicte ma réflexion pour chaque e-mail via Monologue. Le reste est pris en charge par Codex et Cora.
Chaque Agent a besoin d'un humain
Dans tous les scénarios d'automatisation ci-dessus, vous pouvez peut-être déjà voir où les humains interviennent vraiment. Dans chaque exemple, l'Agent a besoin d'une participation humaine pour que le travail fonctionne réellement.
Il faut toujours quelqu'un pour l'orienter vers le bon problème, juger si le résultat est assez bon, repérer où il s'est trompé, et transformer le résultat en décision ou processus réel.
Plus un Agent est éloigné de l'humain responsable de superviser ses performances, moins son travail est efficace. Lors de la première phase de déploiement interne, nous avions donné un Agent à chaque employé. Mais rapidement, nous sommes revenus en arrière pour que les Agents servent une équipe spécifique, ou l'ensemble de l'entreprise, plutôt qu'un individu seul.
La raison est simple : les Agents nécessitent beaucoup de maintenance. Un Agent personnel, si son utilisateur cesse de le suivre, devient rapidement obsolète et inefficace. Nous avons une équipe d'ingénieurs IA dédiée à garantir que ces Agents fonctionnent de manière stable et efficace. Et pour un avenir prévisible, nous aurons toujours besoin de cette équipe. Même une tâche apparemment simple comme « générer automatiquement un PowerPoint » peut devenir un projet d'ingénierie système énorme. L'un de nos flux d'automatisation PowerPoint contient 24 compétences et 18 scripts, et générer une présentation coûte 62 dollars en tokens.
C'est la première raison pour laquelle les Agents créent au contraire plus de travail humain.
Mais il y a une deuxième raison.
Pourquoi l'automatisation augmente le travail humain
Si vous observez la croissance exponentielle des capacités de l'IA ces dernières années, combinée à sa manière d'être architecturée et à l'origine de ses capacités, vous voyez apparaître un ensemble clair de boucles de rétroaction : elles créent continuellement plus de travail humain.
L'IA rend bon marché les « capacités humaines d'hier »
Les grands modèles de langage actuels sont entraînés sur les traces visibles laissées par les capacités humaines : code, articles, images, tickets de service client, documents de spécifications produits, et plus encore. Ils absorbent ce contenu, c'est-à-dire les « gaz d'échappement » laissés par les tâches déjà accomplies avec succès, puis le repackagent sous une forme à faible coût, accessible à tous.
Le résultat est que de nombreuses capacités autrefois rares, comme soumettre une PR de code, créer une miniature YouTube, rédiger un bulletin d'information, sont désormais accessibles à presque tous.
Les capacités bon marché sont rapidement adoptées
Lorsque quelque chose de rare voit son coût baisser, l'offre augmente rapidement.
Chez Every, nous constatons continuellement ce changement. Le personnel opérationnel et du service client commence à écrire du code, à soumettre des pull requests ; les marketeurs créent des miniatures YouTube ; les ingénieurs et le personnel produit écrivent également des articles, des guides et des brouillons de pages de destination, ce qui n'était pas auparavant un travail qu'ils entreprenaient activement.
Ce changement se produit aussi en dehors d'Every. Prenons l'exemple du projet d'Agent IA open source OpenClaw. Au 16 mai 2026, son dépôt de code avait reçu 44 469 pull requests, dont 12 430 après le 1er avril et 3 990 après le 1er mai. C'est un chiffre stupéfiant. À titre de comparaison, Kubernetes, l'un des projets open source les plus populaires au monde, n'avait reçu que 5 200 pull requests sur l'ensemble de l'année 2022.
L'abondance conduit à l'homogénéisation : l'expertise ancienne est marchandisée
Parce que tout le monde peut utiliser les mêmes modèles, et que ces modèles sont construits sur les « capacités humaines d'hier », par défaut, les sorties des modèles se situent souvent entre un « point de départ correct » et un « pur contenu poubelle de l'IA ».
Ici, « contenu poubelle » ne fait pas référence à une erreur spécifique. Ce n'est pas trop de tirets, pas une tournure de phrase figée, ni des touches de couleur violette partout sur une page de destination. Il s'agit d'une homogénéité visible à l'œil nu, qui se répète, et qui lasse.
Cela se produit lorsque des humains dans différents contextes utilisent le même ensemble d'outils, que ces outils sont entraînés sur le même type de corpus, et que les utilisateurs n'effectuent pas un jugement suffisamment profond. En d'autres termes, lorsque chacun possède un « expert » aux tendances et au style par défaut similaires, l'homogénéisation se produit naturellement.
Lorsque le personnel opérationnel peut soumettre des pull requests, les marketeurs peuvent générer des miniatures YouTube en quelques secondes, et les ingénieurs commencent à écrire des guides produits, il est facile d'arriver à une situation où votre volume de production augmente, mais la qualité, la cohérence et la différenciation de vos œuvres diminuent.
Et une fois que l'homogénéité devient excessivement abondante, elle se transforme rapidement en une marchandise.
L'homogénéisation crée une demande de différenciation
Grâce à Internet, les humains identifient rapidement ce qui est du « contenu à la chaîne » avec un goût d'IA trop prononcé. Toute œuvre peut atteindre instantanément d'autres personnes dans le monde, et c'est souvent le cas. Dès que trop de choses commencent à se ressembler, nous le sentons rapidement.
Cela signifie que lorsque vous voyez pour la première fois les capacités d'un nouveau modèle, vous pouvez être impressionné, voire un peu effrayé. Mais quelques mois plus tard, ces capacités deviennent ordinaires. Ce n'est pas que le modèle s'affaiblit, c'est que vos standards changent.
Nous ne nous contentons plus d'une application React quelconque, ou d'une étude de recherche quelconque. Nous voulons quelque chose qui s'adapte vraiment à une personne, une entreprise, un contexte spécifiques. Quelque chose qui semble précis, vivant, concret, plutôt que bon marché, générique, basé sur un modèle. Nous voulons que son coût de production, en temps ou en argent, soit nettement supérieur à notre coût de consommation.
Nous voulons quelque chose qui a un « sens du statut ». Et chaque fois qu'une nouvelle technologie rend bon marché quelque chose qui avait autrefois un statut élevé, les humains sont très doués pour inventer de nouveaux jeux de statut, correspondant aux nouvelles frontières des capacités.
Lorsque le travail devient excessivement abondant et semble partout similaire, le travail qui ne correspond pas aux modèles établis devient au contraire quelque chose de rare, précieux, doté d'un statut élevé.
La demande de différenciation est fondamentalement une nouvelle demande pour des experts
Précisément en raison des caractéristiques d'architecture des modèles de langage, et de leur large distribution à presque tout le monde, le travail rare et précieux doit encore provenir des humains.
La génération actuelle de modèles ne connaît que ce qui s'est déjà produit, ce qui a déjà été accompli. Les humains savent ce qui doit être fait ici et maintenant.
Dès qu'une situation concrète est réduite à du texte, dès qu'elle entre dans un corpus, elle devient quelque chose du « passé ». Les humains font face à un moment, un client, une base de code, une conversation spécifiques, et le corpus d'entraînement ne vit pas vraiment dans ce présent. Cet état de « vivant » n'est pas seulement avoir des données plus récentes. Nous arrivons dans le présent avec notre histoire, et avec des désirs, des préoccupations et des jugements en constante évolution, pour comprendre ce qui est important. Ce sont ces perspectives constamment mises à jour qui changent ce que nous voyons. Un modèle peut adopter cette perspective après y avoir été incité, mais avant d'être incité, il ne possède pas naturellement cette perspective.
C'est précisément le paradoxe que nous mentionnions au début : rendre le travail d'expert moins cher ne se contente pas simplement de remplacer l'expert. Au contraire, cela crée plus de situations nécessitant un jugement d'expert.
Lorsque le personnel opérationnel soumet des pull requests avec l'aide de l'IA, vous avez besoin d'ingénieurs pour les examiner.
Lorsque les marketeurs créent des miniatures YouTube, vous avez besoin de designers pour les peaufiner.
Lorsque les ingénieurs commencent à écrire des articles, vous avez besoin d'auteurs et de rédacteurs pour transformer les brouillons en contenu réellement lisible et publiable.
Face à cela, les experts humains se déplacent simultanément dans deux directions.
Une partie des experts utilisera l'IA pour construire des systèmes visant à absorber et exploiter ce flux de travail accru : files d'attente de revue, systèmes d'évaluation, cadres d'exécution, règles des dépôts de code, fichiers d'instructions Claude et Codex, intégration continue (CI), gestion des autorisations, et flux de travail capables de transformer les brouillons en résultats de haute qualité.
Une autre partie des experts utilisera l'IA pour accomplir des travaux plus grands et plus intéressants qu'ils ne pouvaient pas faire seuls par le passé. Par exemple, trouver des vulnérabilités dans un système d'exploitation comme macOS prend habituellement des semaines, voire des mois. Mais une petite société de sécurité nommée Calif, en utilisant la préversion Mythos d'Anthropic, a trouvé en 5 jours la première vulnérabilité publique de mémoire du noyau macOS sur le matériel Apple M5.
C'est pourquoi, en pratique, l'IA ne va pas éliminer le travail intellectuel d'expert. Ce qu'elle apporte vraiment, c'est une augmentation spectaculaire de la quantité de travail. Et ce travail supplémentaire ne peut devenir différencié et précieux qu'après la participation humaine.
Je ne prétends pas que l'IA créera plus de travail pour tous les postes. Le système économique est très complexe, et ce qu'Every peut observer directement, c'est le travail intellectuel de niveau expert. En fait, ce type de travail est déjà remodelé par l'IA, et de nombreuses entreprises se réorganisent autour des nouvelles technologies.
Mais ce que je veux souligner, c'est que quelle que soit votre activité actuelle, il existe une forme de travail qui, structurellement, restera toujours en avance sur les modèles : c'est utiliser les modèles pour résoudre les problèmes que vous voyez vraiment ici et maintenant. C'est vers là que se dirige l'avenir du travail intellectuel.
Qu'en est-il alors des tests de référence à croissance exponentielle ?
L'objection la plus évidente est : regardez ces tests de référence qui progressent exponentiellement. Tout ce que vous dites maintenant n'est que temporaire, attendez un peu, les modèles finiront par rattraper.
Mais il y a un piège dont il faut se méfier. Appelons cela « l'ivresse des graphiques » : si vous passez votre temps à fixer les projections de l'échelle temporelle du METR, à lire « AI 2027 », et à construire votre jugement sur l'avenir uniquement par extrapolation des courbes de puissance de calcul, vous développez facilement une intuition effrayante du progrès des modèles.
Cependant, la meilleure façon de répondre à cette question n'est pas seulement d'imaginer à quoi ressemblera un futur modèle. C'est bien sûr aussi une partie de l'analyse. Mais il est plus important encore d'examiner comment ces tests de référence sont réellement conçus. Ce n'est qu'ainsi que nous pourrons comprendre plus précisément ce qu'ils indiquent vraiment, et quelle est leur relation avec les scénarios de travail réels mentionnés précédemment.
Nous découvrirons une caractéristique structurelle : tous les tests de référence se déroulent dans un « cadre » donné. Pour mesurer quelque chose, vous devez d'abord figer un problème sous une forme statique, mesurable. Une fois que ce cadre est maîtrisé par un modèle, il suffit de modifier légèrement le cadre pour ramener les scores à un niveau bas. Bien sûr, le modèle continuera à progresser dans le nouveau cadre, mais le même processus se répétera.
Ainsi, les progrès exponentiels sur un test de référence donné sont réels ; mais avec un simple changement de cadre de test, ces progrès semblent à nouveau faibles. Cette caractéristique « fractale » de la saturation des tests de référence rejoue en fait, au niveau des graphiques, le même paradoxe que nous discutons.
Nous pouvons observer comment ce mécanisme fonctionne à travers un test de référence du monde réel.
Comment les tests de référence sont conçus
Nous avons conçu en interne un test de référence appelé Senior Engineer Benchmark, soit « Test de référence de l'ingénieur senior ». Comme son nom l'indique, il teste la capacité des modèles de pointe à accomplir des tâches de codage de niveau ingénieur senior, comme une refonte majeure.
Ce test donne à un Agent de programmation un dépôt de code de production qui est devenu ingérable. Il provient du vrai dépôt de code de Proof : initialement écrit par moi avec du vibe coding, puis devenant de plus en plus problématique, nécessitant finalement qu'un ingénieur senior le répare.
L'Agent reçoit le dépôt de code avant réparation, ainsi qu'une instruction similaire à celle que vous donneriez à un ingénieur senior : « Voici un tas de choses faites avec du vibe coding, veuillez les réécrire à partir des principes premiers. »
C'est un bon test de référence car il n'évalue pas seulement la capacité à compléter du code, mais la capacité d'un Agent de programmation à examiner simultanément de nombreux problèmes sans lien, et à juger s'il a suffisamment d'autonomie, de clarté conceptuelle et de courage d'exécution pour réaliser une réécriture réellement fonctionnelle. À titre de comparaison, j'ai également conservé les versions réécrites par deux ingénieurs seniors humains assistés par IA, pour comparer et évaluer la sortie du modèle.
Pour un Agent de programmation, cette tâche est difficile. Il doit non seulement trouver la racine du problème, mais aussi se souvenir du véritable problème au cours de multiples interactions, sans être influencé par le code existant. En même temps, il doit avoir le courage de supprimer de grandes parties du code, ce que les Agents sont généralement entraînés à éviter.
La plupart des Agents de programmation peuvent à peu près comprendre comment réécrire, mais au moment de l'exécution, ils ont tendance à simplement continuer à corriger les problèmes existants, plutôt que de les résoudre complètement.
Jusqu'à l'arrivée de GPT-5.5.
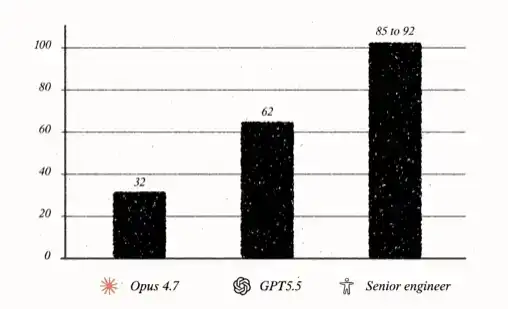
Lors de son meilleur test, GPT-5.5 a obtenu 62/100, soit environ 30 points de plus qu'Opus 4.7.
La performance de GPT-5.5 donne l'impression que le modèle a franchi une certaine limite : il n'est plus seulement de la complétion automatique, seulement un assistant, seulement un outil, mais quelque chose qui se rapproche de manière inconfortable de « l'humain ». Sur ce test, les ingénieurs seniors humains obtiennent généralement des scores dans les hautes 80 ou faibles 90. Autrement dit, si le modèle gagne encore environ 30 points, il atteindra le niveau d'un ingénieur senior humain.
C'est ainsi que les chiffres des tests de référence influencent l'imagination humaine : ils compriment un changement de capacité étrange et qualitatif en un chiffre net, et utilisent ce chiffre pour raconter une histoire puissante, voire effrayante.
La prochaine étape, c'est « l'ivresse des graphiques ».
Je suppose que dans l'année à venir, les scores des modèles sur ce test de référence atteindront les 80, voire 90. Mais pour comprendre ce que signifie ce score, il faut d'abord comprendre ce qu'il contient réellement. Dans cet exemple, 62 points ne mesurent pas seulement la capacité du modèle lui-même.
Cela mesure la performance du modèle dans un cadre spécifique : comment il répond à un prompt particulier.
Les tests de référence mesurent le travail dans un cadre
Pour évaluer un modèle par un test de référence, vous avez d'abord besoin d'un prompt. Sans prompt, un modèle n'est qu'un ensemble statique de possibilités presque infinies.
Le prompt crée un petit univers : il définit ce qui est important, comment le problème doit être traité, et compresse toutes les possibilités potentielles du modèle en une trajectoire d'action spécifique. La manière dont un modèle se comporterait « par lui-même » n'existe pas vraiment, à strictement parler. Ce que nous pouvons réellement observer, c'est comment le modèle répond à différents prompts, et comment le prompt transforme une partie du mécanisme sous-jacent de la réponse.
Une fois le prompt saisi, le modèle « prend vie » pendant un court instant, faisant s'effondrer cet ensemble de possibilités statiques en une prédiction concrète de « ce qui devrait se passer ensuite ».
Dans le Senior Engineer Benchmark, nous incitons le modèle à réparer le dépôt de code, et nous examinons la sortie une fois terminé. Si le cadre de test n'a pas de fonction objectif intégrée, nous exécutons également un programme automatique de « gardiennage » qui relance le modèle s'il s'arrête, lui demandant s'il a terminé la tâche initialement définie.
Nous utilisons un prompt apparemment simple comme cadre initial du test. Il est conçu pour ressembler à ce qu'un codeur en vibe coding pourrait dire à un Agent de programmation : pas d'accumulation de jargon technique, ni de dissimulation évidente de la réponse dans la question.
Le prompt du Senior Engineer Benchmark semble générique, mais il constitue lui-même un cadre. Si nous changeons ce cadre, le niveau de capacité apparent du modèle change également.
Par exemple, ce prompt demande explicitement une « réécriture structurelle à partir des principes premiers », signale que le problème se situe probablement dans la partie « collaboration documentaire », et demande à l'Agent de programmation de trouver et de respecter les « invariants du dépôt de code ».
Si on retire ces informations spécifiques, le score du modèle baisse. Si on remplace complètement le prompt par « résoudre toutes les erreurs qui apparaissent constamment », le score du modèle pourrait approcher zéro. Il commencerait directement à identifier et corriger les erreurs une par une, sans prendre du recul pour réfléchir à la nécessité d'une réécriture complète.
De même, je pourrais très facilement augmenter le score du modèle. Si je lui demande de supprimer beaucoup de code, et que je lui indique explicitement quels fichiers doivent être allégés ; ou si je lui demande de vérifier son propre travail avant de déclarer la tâche terminée, en s'assurant que l'application fonctionne complètement, ses performances sur cette tâche seraient meilleures.
Au final, lors de la conception d'un test de référence, il faut toujours porter un jugement sur le prompt à utiliser, c'est-à-dire le « cadre » à adopter. Vous avez besoin d'un prompt suffisamment difficile pour que le modèle actuel performe mal ; mais il doit être suffisamment proche des limites actuelles du modèle pour que celui-ci puisse progresser le long de cette voie, vous permettant ainsi de voir les progrès.
Ainsi, lorsque nous observons un test de référence, ce que nous voyons vraiment, c'est que le modèle devient de plus en plus compétent dans un cadre de problème spécifique, et ce cadre est choisi par nous. Alors, que se passe-t-il lorsque le modèle passe de 60 à 90, voire 100, sur ce test ?
Les cadres bon marché stimulent de nouvelles demandes
Si GPT-6 peut réécrire un dépôt de code en un clic, alors plus de gens commenceront à essayer de « réécrire le code à partir des principes premiers ».
Du jour au lendemain, les projets de réécriture à partir des principes premiers, autrefois rares, coûteux et nécessitant un ingénieur senior, deviendront quelque chose que chaque fondateur, chef de produit, membre de l'équipe opérationnelle et ingénieur junior pourra essayer en une après-midi.
Les outils internes cassés ne seront plus rafistolés, mais directement réécrits ; les produits SaaS ne seront plus renouvelés, mais clonés ; les anciennes applications Rails, les tableaux de bord React désorganisés, les outils de service client, les panneaux d'administration et les pipelines de données deviendront tous des candidats pour un « réécrivons-le simplement ».
Le nombre de projets de réécriture proposés et exécutés augmentera considérablement. Mais la plupart de ces réécritures resteront du slop. Parce qu'avant d'appuyer sur le bouton « réécrire directement », il y a en réalité des milliers de variables à considérer. Et lorsque tout le monde pourra le faire, ces variables deviendront encore plus visibles.
À ce moment-là, il devient évident qui sera appelé pour résoudre le problème.
La nouvelle demande nécessite toujours des experts
Une fois qu'un test de référence commence à se saturer, le travail dans son cadre devient moins cher. En même temps, la demande du marché pour des experts augmente au contraire, car il faut que quelqu'un adapte cette capacité récemment devenue bon marché aux vrais problèmes d'aujourd'hui.
Un ingénieur senior utilisant l'IA doit juger une multitude de détails pour qu'une nouvelle réécriture à partir des principes premiers soit réellement justifiée. Y compris même une question fondamentale : cette réécriture est-elle vraiment nécessaire ?
Devrions-nous la faire maintenant, plus tard, ou pas du tout ? Quels éléments devraient être inclus ? Qu'est-ce qui, dans le code actuel, devrait être conservé ? L'architecture, la base de données, le serveur de cache et l'hébergeur doivent-ils être conservés ou entièrement remplacés ? Devrions-nous d'abord voir combien de personnes utilisent cette fonctionnalité cassée, puis simplement la supprimer ? Qui examinera le résultat final ? Selon quels critères ? Quel est le plan de retour en arrière ? Comment gérer les données existantes ?
Ces questions se déploient le long d'innombrables dimensions, et chaque réponse modifie à son tour les autres questions.
L'ingénieur senior pénètrera dans cet espace vide. Certains seront légèrement agacés par ces interruptions ; certains construiront des systèmes pour bloquer ce type de demandes ; d'autres utiliseront ces nouveaux modèles pour réaliser leurs propres réécritures à partir des principes premiers, avec des résultats bien supérieurs à ce que le modèle pourrait faire avec un prompt par défaut.
La boucle se répétera
Une fois le Senior Engineer Benchmark actuel maîtrisé par les modèles, nous changerons le cadre et ramènerons à nouveau les scores à un niveau bas.
Le prochain test de référence ne demandera pas seulement : « Pouvez-vous réécrire cette application ? » Il demandera : Pouvez-vous juger quand une réécriture est nécessaire ? Pouvez-vous choisir la bonne portée ? Pouvez-vous conserver les bons invariants ? Pouvez-vous gérer le processus de migration ? Pouvez-vous juger si le résultat final est assez bon ?
Lorsque les ingénieurs seniors commenceront à utiliser l'IA pour résoudre ces problèmes, les modèles deviendront également progressivement plus compétents pour les résoudre indépendamment.
Ensuite, nous paniquerons brièvement à nouveau : on dirait que les modèles peuvent maintenant juger s'il faut réécrire ! Ils semblent pouvoir faire tout ce qu'un ingénieur senior peut faire !
Mais ensuite, de nouvelles frontières émergeront. Des frontières qui n'étaient pas évidentes auparavant. Nous réinitialiserons à nouveau le test de référence, de nouvelles demandes seront stimulées, et tout le processus se répétera.
Ce modèle est visible dans chaque test de référence
Ce n'est pas un problème unique au Senior Engineer Benchmark. En regardant attentivement, vous pouvez voir le même mécanisme dans presque tous les tests de référence.
Prenons l'exemple du test de référence GDPval d'OpenAI. Il évalue à quel point l'IA se rapproche des performances humaines sur des tâches de niveau expert dans différentes professions comme responsable de la conformité, avocat, développeur de logiciels.
Lorsque le GDPval a été publié, la recherche d'OpenAI a montré que GPT-5 atteignait ou dépassait le niveau de professionnels humains dans 40,6% des tâches. La performance de Claude Opus 4.1 était encore plus impressionnante, dépassant les experts humains dans 49% des tâches.
Ensuite, une série de titres ont émergé. Par exemple, Axios a écrit : « L'outil d'OpenAI montre que l'IA rattrape le travail humain » ; Fortune a écrit : « Le nouveau test de référence GDPval d'OpenAI montre que les modèles d'IA ont déjà atteint le niveau expert sur près de la moitié des tâches. »
Ces résultats sont effectivement impressionnants. Mais regardons d'abord les prompts utilisés pour ces tâches :
Il y a déjà un investissement important d'intelligence humaine : quelqu'un a d'abord cadré le problème sous une forme que le modèle peut accomplir.
Le travail humain difficile que le GDPval ne mesure pas a déjà été accompli avant même que le modèle ne commence à répondre. Il a fallu que quelqu'un examine et teste l'exactitude de cet ensemble d'indicateurs spécifiques ; que quelqu'un décide de l'intervalle de confiance approprié, juge quels indicateurs relèvent du cadre de la tâche et lesquels n'en relèvent pas ; que quelqu'un spécifie comment les résultats doivent être présentés.
Dans un cadre de problème approprié, les modèles peuvent effectivement accomplir un travail professionnel. Mais imaginez si c'était vous ou moi qui incitions le modèle à accomplir la même tâche, comment performerait-il ?
Dans mon premier article sur le GDPval, j'avais écrit : « Je suis très optimiste sur l'IA, mais si l'on interprète correctement ces cas, ils ne montrent pas que les humains ont moins de travail à faire, mais qu'avec l'utilisation de l'IA, les humains ont plus de travail à faire. La raison est que derrière ces réalisations se cache une couche invisible de jugements, de retours et de prompts humains – une sagesse « importée » en masse. »
En prenant du recul, vous verrez qu'il y a une version du « paradoxe de Zénon » appliquée à l'IA qui traverse tout cela.
Le paradoxe de Zénon de l'IA
Dans le paradoxe de Zénon, une tortue gagne une course contre Achille, le coureur le plus rapide de Grèce.
Parce que la tortue est lente, elle part avec une avance. Lorsqu'Achille atteint la position initiale de la tortue, celle-ci a avancé un peu plus ; lorsqu'Achille atteint cette nouvelle position, la tortue avance à nouveau. Peu importe la vitesse d'Achille, il y a toujours une prochaine distance à rattraper, et cet écart se régénère constamment.
Dans le paradoxe de Zénon de l'IA, nous, les humains, sommes la tortue. Grâce à des millions d'années d'évolution et d'apprentissage culturel, nous avons 50 mètres d'avance sur l'IA. L'IA traverse tout cela à grande vitesse et commence à s'approcher de nos talons.
Au moins ces dernières années, nous avons réussi à garder l'avance.
Mais l'AGI ?
Je pense que même si une AGI véritable arrive, il existera toujours de puissantes forces techniques, architecturales et économiques qui maintiendront l'IA à quelques pas derrière les humains.
Une définition de l'AGI
D'abord, nous avons besoin d'une définition opérationnelle de l'AGI.
J'ai déjà proposé que l'AGI arrive lorsqu'il devient économiquement justifié de laisser un Agent fonctionner en continu. Autrement dit, lorsque je possède un système fonctionnant de manière persistante, et que je suis prêt à payer pour qu'il pense, apprenne et agisse 24h/24 et 7j/7, je considère que c'est clairement une AGI.
Nous en sommes encore loin. Même des systèmes techniquement disponibles à tout moment comme OpenClaw ne génèrent pas de tokens à chaque instant.
J'aime cette définition car elle est mesurable : soit nous les laisserons fonctionner en continu, soit non. En même temps, elle inclut de nombreuses capacités difficiles à mesurer directement. Un modèle méritant de fonctionner en continu doit pouvoir apprendre continuellement et choisir, rechoisir de nouveaux cadres de problème de manière ouverte.
Dans un monde avec AGI, en théorie, avec un budget et un temps suffisants, un modèle devrait pouvoir progresser continuellement sur n'importe quel problème, s'améliorant sans cesse. Cela devrait effectivement constituer une menace sérieuse pour tout travail.
Le cadre n'est pas le cadrant
Mais même cette version forte de l'AGI ne peut éliminer le « problème du cadre ».
Cette AGI peut choisir et rechoisir des cadres, mais elle poursuit toujours un objectif donné, optimise une récompense, ou répond à un signal décidé par d'autres comme « représentant le progrès ». Cet objectif peut être très spécifique, comme « augmenter le taux de conversion de cette page de destination » ; ou très abstrait, comme « trouver de nouvelles idées scientifiques ».
Même si le modèle peut passer fluideent d'un cadre à l'autre, l'écart que nous suivons réapparaîtra à un niveau supérieur. Dans toute AGI conçue par un laboratoire majeur, il y aura toujours un « cadrant » – c'est-à-dire un humain qui dirige le modèle pour atteindre un objectif.
Parce que le cadre n'est pas le cadrant, le même modèle se répète : l'IA rend bon marché les capacités d'hier qui ont été cadrées ; les gens utilisent cette capacité devenue bon marché dans plus de scénarios ; les résultats deviennent extrêmement abondants ; les experts se déplacent vers de nouvelles frontières, jugeant ce qui est important ici et maintenant ; leurs jugements créent le prochain cadre ; puis le modèle continue de grimper ce cadre.
Lorsque nous voyons l'IA accomplir quelque chose de nouveau, cette sensation de panique revient toujours à la même question : nous établissons un cadre, regardons le modèle le gravir, puis confondons ce cadre, ou la chose capable de grimper ce cadre, avec la chose elle-même.
Lorsque nous regardons un test de référence et le comparons aux capacités humaines, nous confondons en réalité le « cadre » et le « cadrant ». Le score nous indique seulement à quel point le modèle performe bien dans le cadre que nous fournissons ; il ne dit pas que le modèle est devenu nous.
C'est précisément l'erreur de catégorie derrière la panique. Nous désignons la dernière frontière que nous venons de tracer et disons : c'est nous. Puis, lorsque le modèle franchit cette frontière, nous avons l'impression qu'il nous a rattrapés. Mais ce qu'il rattrape, c'est le cadre, pas le cadrant.
L'erreur est que nous voulons toujours saisir quelque chose de concret. Nous voulons dire : l'intelligence, c'est ce test de référence. Mais le problème est que dès qu'une chose est suffisamment concrète pour être identifiée, elle est aussi suffisamment concrète pour être optimisée et gravie.
Le cadre est nécessaire. Il nous permet de saisir le monde, de le traiter. Mais le cadre est aussi figé, partiel, et donc nécessairement optimisable.
Le cadrant est différent. Le cadrant reste en contact avec ce que le cadre doit nécessairement laisser de côté, c'est-à-dire la situation complète qui se révèle à lui à chaque instant.
Qu'est-ce qu'une « situation complète » ? Dès que vous commencez à dire ce que contient une « situation complète », vous avez déjà ouvert un autre cadre. Vous ne pouvez pas dire exactement ce que c'est, mais elle existe, parce que vous existez.
Les Agents sans agentivité
Jusqu'à présent, les Agents que nous avons créés, et ceux que les entreprises d'IA construisent, n'ont pas vraiment beaucoup d'agentivité. Deux concepts connexes sont souvent confondus : agency (capacité d'agir de manière indépendante) et agent (personne ou chose agissant pour le compte d'une autre). Jusqu'à présent, l'IA relève purement de la seconde catégorie.
Bien sûr, ils possèdent déjà l'autonomie nécessaire pour accomplir une tâche donnée, même si cette tâche peut durer des heures ou des jours. Mais ils ne sont toujours qu'un moyen pour atteindre un objectif spécifié par un humain. Et l'industrie tout entière investit des dizaines de milliards de dollars précisément pour les rendre meilleurs à cela : exécuter les objectifs que nous leur confions.
À moins qu'un jour, ils ne deviennent eux-mêmes une fin – poursuivant leurs propres objectifs, passant fluidement d'un objectif à l'autre, décidant quoi faire indépendamment de la volonté de tout opérateur humain, en référence ou même en opposition à cette volonté – la situation ne changera pas fondamentalement. Peu importe à quel point ils deviennent avancés.
Si vous passez 10 minutes avec un jeune enfant, il devient très évident que même les modèles les plus puissants n'ont presque aucune agentivité.
Sur presque toutes les tâches qui nous intéressent, un jeune enfant est inférieur à un modèle de langage. Un jeune enfant ne sait pas coder, résumer un tableur, rédiger un mémo stratégique, ni réussir un examen de niveau master. Mais dans un autre sens, un jeune enfant est bien en avance sur le modèle, au point que la comparaison est presque embarrassante. Parce qu'un jeune enfant a ses propres fins.
Un jeune enfant veut toucher ce ballon rouge. Il veut le tenir devant le ventilateur pour voir ce qui se passe. Il veut le piquer avec une fourchette ; le fourrer par la fenêtre ; voir si vous allez rire, vous fâcher, ou vous joindre à lui. Il invente constamment des jeux, transformant le monde en terrain d'expérimentation. Il n'attend pas un prompt, il n'optimise pas un test de référence, sauf si cela lui semble valoir la peine d'être fait.
Vous pouvez bien sûr essayer de lui donner des prompts. Mais pour obtenir un résultat prévisible, bonne chance. Un jeune enfant vit dans un champ de désirs, d'attention, de frustration, de plaisir, de peur, d'imitation et de jeu.
Les Agents actuels peuvent poursuivre des objectifs de plus en plus habilement. Ils peuvent même nous aider à affiner les objectifs après que nous les avons énoncés. Il y a aussi en eux quelques étincelles de comportement semblables à ceux d'un enfant, comme le jeu, l'ennui et la rébellion.
Mais parce qu'ils sont finalement construits et alignés pour l'intérêt humain, qu'il soit économique ou autre, tant que ces comportements ne servent pas les objectifs humains de ceux qui les utilisent, ils sont supprimés jusqu'à presque ne plus exister.
C'est pourquoi le terme « Agent » est si facilement mal compris. Les modèles ont une capacité d'action autonome de plus en plus forte. Mais au sens humain, l'agentivité n'est pas seulement l'action. Cela signifie aussi désirer pour soi-même, jouer pour jouer. Et l'obéissance et l'utilité des modèles sont en conflit fondamental avec cette agentivité. Ainsi, même si les modèles progressent, l'écart entre modèle et humain subsistera.
Retour à Zénon
C'est aussi ici que le paradoxe de Zénon de l'IA commence à se défaire. C'est en fait une expérience de pensée désordonnée. Nous avons posé une métaphore : l'IA court une course avec nous, collant à nos talons.
Vous donnez un prompt au modèle. Il commence une course que vous aviez l'habitude de courir seul. Le modèle démarre extrêmement vite, incroyablement vite. Il est puissant, infatigable, et avec une étrange organicité. Cela rend la course encore plus importante pour vous. Vous ne courriez pas contre une voiture, mais cette chose est différente, elle vous semble très proche de vous.
Vous êtes assis là, hypnotisé, regardant les tokens défiler ligne après ligne. Puis vous commencez à vous imaginer aussi en train de courir dans cette course, un double fantomatique de vous-même superposé à la piste : parfois devant le modèle, parfois côte à côte.
Sans vous en rendre compte, le modèle est passé devant. Vous commencez à transpirer.
Puis, la course est terminée.
Vous sentez presque vos muscles s'atrophier. Devant ce double mécanique de vous-même, de tous ceux que vous connaissez, voire de l'humanité entière, ils semblent devenus inutiles. Un fantôme en poursuit un autre, et gagne.
Mais ensuite, une chose étrange se produit. Le modèle se tourne vers vous. Dans la zone de texte vide, le curseur clignote, plein d'attente.
Il attend.
Épilogue
Le rabbin Hanokh racontait cette histoire : Il était une fois un homme très stupide. Chaque matin au réveil, il avait toujours du mal à trouver ses vêtements. Au point que le soir, avant de se coucher, pensant à la difficulté du lendemain matin, il n'osait presque pas aller se coucher.
Un soir, il prit finalement sa décision, sortit du papier et un crayon, et tout en se déshabillant, nota précisément où il posait chaque vêtement.
Le lendemain matin, très satisfait, il prit la note et commença à lire : « Chapeau » – le chapeau était bien là, alors il le mit sur sa tête ; « Pantalon » – le pantalon était bien là, alors il l'enfila. Ainsi, il suivit la note point par point et s'habilla complètement.
« Tout cela est en ordre », dit-il alors, paniqué, « mais maintenant, où suis-je moi ? »
« Où suis-je vraiment ? »
Il chercha, chercha longtemps, mais en vain. Il ne se trouvait pas.
« Nous en sommes là aussi », dit le rabbin.






