Au cours de la dernière décennie, le renforcement de l'IA a principalement reposé sur une seule voie : injecter davantage de données et de puissance de calcul dans des modèles plus grands, en faisant reposer l'expérience dans les paramètres du réseau de neurones. Cette voie a permis le bond en avant des grands modèles après ChatGPT, mais a également laissé un problème : les modèles deviennent de plus en plus puissants, mais la raison de leurs succès ou de leurs échecs reste souvent difficile à expliquer et à corriger.
Les expériences récentes menées par l'ingénieur d'OpenAI, Weng Jiayi, suggèrent une autre possibilité : dans un cadre avec un objectif clair, un environnement exécutable et une boucle de rétroaction, l'IA peut non seulement s'améliorer via l'entraînement des modèles, mais aussi en « modifiant son code de manière autonome ».
Le 8 mai 2026, Weng Jiayi a systématiquement décrit ces expériences dans son blog personnel « Learning Beyond Gradients » et a simultanément rendu publics le dépôt de code, les journaux d'expérience CSV et les enregistrements vidéo. Il se concentre depuis longtemps sur l'apprentissage par renforcement et les infrastructures de post-entraînement, a participé au lancement initial de ChatGPT, et a contribué à des projets tels que GPT-4, GPT-4 Turbo, GPT-4o, la série o et GPT-5 ; avant de rejoindre OpenAI, il a obtenu son diplôme de premier cycle en informatique de l'Université de Tsinghua, a poursuivi ses études de maîtrise à l'Université Carnegie Mellon et est le principal auteur de la bibliothèque d'apprentissage par renforcement open source Tianshou et du moteur d'environnement parallèle haute performance EnvPool.

Image générée par IA
Il a demandé à Codex d'écrire de manière répétée du code de stratégie, d'exécuter des environnements, de lire les journaux, de visionner les enregistrements, de localiser les échecs, puis de modifier le code, d'ajouter des tests, et de poursuivre l'évaluation. Après plusieurs itérations, Codex a « développé » une stratégie procédurale purement Python : il a atteint le score théorique maximal de 864 points dans Atari Breakout, et a également obtenu des performances proches de celles des algorithmes courants d'apprentissage par renforcement profond dans les environnements de simulation de contrôle de robots comme MuJoCo Ant et HalfCheetah.
Ce qui est vraiment important dans ces expériences, c'est une question centrale : lorsque l'agent de codage est suffisamment puissant, l'apprentissage doit-il nécessairement se produire dans les poids du réseau neuronal ?
Dans ce cadre expérimental, l'expérience est écrite dans le code, les tests, les journaux et les enregistrements, devenant un système logiciel qui peut être lu, modifié, revu et audité. Si cette direction continue de se confirmer, la prochaine étape pour l'IA agentique pourrait ne pas être seulement d'entraîner des modèles plus grands, mais aussi de faire participer les modèles à la maintenance d'un système d'ingénierie en évolution continue.
01
De 387 points au score parfait : la boucle d'ingénierie
Dans son blog, Weng Jiayi écrit que le point de départ de cette expérience était en réalité un besoin d'ingénierie. En tant que mainteneur bénévole d'EnvPool, il avait besoin d'une manière moins coûteuse que de « lancer un réseau neuronal à chaque fois » pour tester le bon fonctionnement des environnements de jeu, car intégrer un réseau neuronal dans l'intégration continue était trop cher. La question initiale était : pouvait-on écrire des règles heuristiques bon marché, reproductibles, clairement supérieures à une stratégie aléatoire, pour amener l'environnement à un état riche en informations ?

Il a utilisé Codex (modèle de base gpt-5.4) pour essayer d'écrire une version entièrement basée sur des règles. Le prompt initial était très direct : « Écris une stratégie pour résoudre Breakout. » Le résultat n'était pas idéal. Le score bas en lui-même ne fournissait aucune information : la sémantique des actions pouvait être incorrecte, la détection d'état pouvait être fausse, le processus d'évaluation pouvait être erroné, ou la structure de la stratégie elle-même pouvait être trop faible.
Ensuite, Weng Jiayi a changé la forme de la tâche. Il n'a plus demandé à Codex de fournir directement un fichier policy.py, mais lui a demandé de maintenir un ensemble complet de boucles : explorer les actions et observations, écrire des détecteurs d'état, écrire des stratégies, exécuter des épisodes complets, enregistrer trials.jsonl et summary.csv, générer des vidéos ou des courbes, examiner les modes d'échec, modifier les stratégies, simplifier le code, exécuter des régressions.
Les enregistrements de l'expérience Breakout documentent ce processus de manière très claire. Dans le premier tour, Codex a d'abord confirmé l'espace d'action et la forme de l'observation, identifié les couleurs de la balle, de la raquette et des briques à partir des trames RGB, puis utilisé des étiquettes d'image pour scanner les 128 octets de RAM de l'Atari. Le score de base initial n'était que de 99 points. Après avoir ajouté une logique de décalage du tunnel, le score est monté à 387 points.
387 points est un score local élevé qui peut prêter à confusion. La stratégie pouvait déjà rattraper la balle de manière stable, mais la trajectoire de la balle était piégée dans une boucle périodique : pas de perte de vie, mais plus de briques cassées, le score était bloqué. Si un humain écrivait le code, il pourrait continuer à ajuster la « précision de rattrapage ». En regardant la vidéo et les dernières dizaines de trajectoires, Codex a localisé le problème dans le manque de perturbation de la trajectoire de la balle.
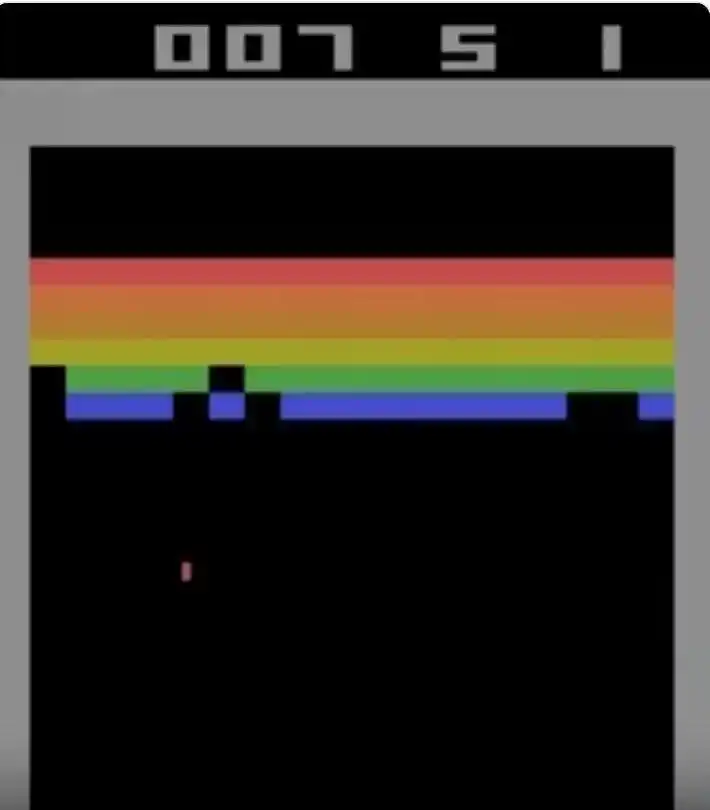
Figure : Capture d'écran du jeu Atari Breakout. Le joueur contrôle la raquette en bas pour faire rebondir la balle et briser les rangées de briques colorées en haut. Codex a atteint le score théorique maximal de 864 points dans ce jeu.
Codex a ensuite ajouté un mécanisme de « rupture de la boucle » : si aucune récompense n'était obtenue pendant longtemps, il ajoutait périodiquement un décalage à la prédiction du point d'impact pour sortir la balle de la boucle locale. Le score est passé de 387 à 507. En poursuivant les itérations, un nouveau problème est apparu : pour les balles basses rapides, l'interception normale faisait « trop devancer » la raquette, qui dérivait. Codex a ajouté le paramètre `fast_low_ball_lead_steps=3`, et le score est passé de 507 à 839. La dernière amélioration, de 839 à 864, ressemblait davantage à la maintenance d'un système devenu complexe : essais de deadband, décalage de service, décalage de blocage, biais d'équilibrage des briques, pas de prévision ; de nombreuses directions n'ont pas été efficaces, et la modification utile finale a été une condition tardive : « Après avoir brisé le premier mur de briques, n'activer le décalage de blocage que lorsque la balle est relativement éloignée de la raquette, et le relâcher progressivement à mesure qu'elle s'en approche. »
La configuration par défaut RAM a finalement produit de manière stable les scores 864 / 864 / 864 sur trois épisodes, atteignant la limite théorique de Breakout. Codex a ensuite migré le même contrôleur géométrique vers une version à entrée purement visuelle – sans lire la RAM, en s'appuyant uniquement sur la segmentation RGB pour identifier la raquette, la balle et l'équilibre des briques. La version visuelle a obtenu 310 points à la première tentative, puis 428 points, et a atteint 864 points après le septième épisode local, correspondant à 14504 pas d'environnement de stratégie locale.
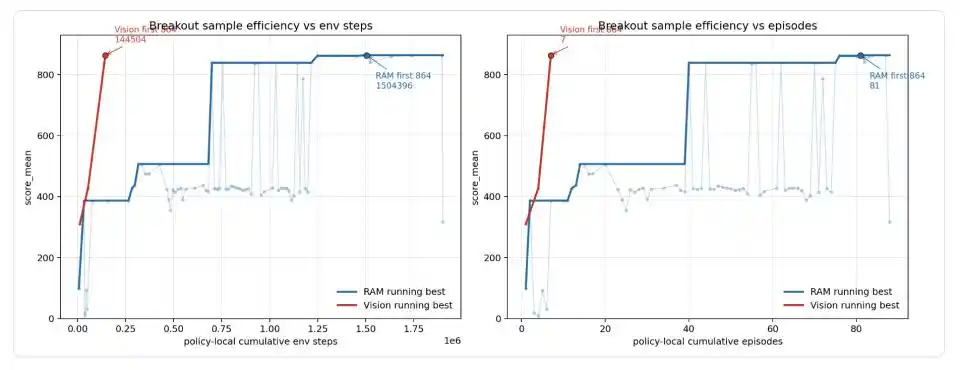
Figure : Courbe d'efficacité des échantillons de Codex sur Breakout. La ligne bleue est la version lisant directement la mémoire du jeu (RAM), la ligne rouge est la version ne regardant que l'écran (Vision). La version RAM a connu plusieurs sauts : 99 → 387 → 507 → 839 → 864, atteignant finalement le score parfait pour la première fois au 81e épisode, après un cumul de 1,5 million de pas d'environnement ; la version Vision, bénéficiant de la structure mature migrée depuis la version RAM, a atteint 864 points en seulement 7 épisodes et environ 14 500 pas d'environnement.
Weng Jiayi souligne spécifiquement que cela ne doit pas être interprété comme « l'entrée visuelle partant de zéro et n'utilisant que 14,5 K pas pour atteindre le score parfait ». Le processus réel est que Codex a d'abord découvert le contrôleur géométrique, la rupture de boucle et le relâchement du décalage tardif dans la version RAM, et ce n'est qu'après la stabilisation de la structure qu'il a basculé la couche de lecture d'état de la RAM vers le RGB. Les 14,5 K représentent le budget de migration de la version visuelle.
02
La définition de l'Apprentissage Heuristique
Trouver un nom pour cette « stratégie logicielle » en constante évolution a été plus difficile que d'écrire la première version de la stratégie. Weng Jiayi a finalement nommé ce processus « Heuristic Learning (HL, Apprentissage Heuristique) », et a nommé l'objet ainsi maintenu « Heuristic System (HS, Système Heuristique) ».
Selon sa définition dans le blog, le HL est constitué de code de programme et, comme l'apprentissage par renforcement profond courant aujourd'hui, il dispose d'une boucle d'état, d'action, de rétroaction et de mise à jour. La différence est que l'objet mis à jour est la structure logicielle, et non les paramètres du réseau neuronal ; sa rétroaction est digérée par l'agent de codage et peut provenir de récompenses environnementales, de cas de test, de journaux, de vidéos, d'enregistrements ou de retours humains ; sa mise à jour n'utilise pas la rétropropagation, mais l'agent de codage modifie directement la stratégie, les détecteurs d'état, les tests, la configuration ou la mémoire.
Il convient de préciser que le concept « d'utiliser un programme plutôt qu'un réseau neuronal comme stratégie » n'est pas une idée originale de Weng Jiayi. Le monde académique discute depuis des années de l'Apprentissage par Renforcement Programmatique (Programmatic RL) : le cadre PROPEL proposé en 2019 par l'Université Rice et Caltech étudiait les méthodes d'apprentissage par renforcement représentant les stratégies sous forme de courts programmes dans un langage symbolique ; le travail LEAPS en 2021 a approfondi l'apprentissage de l'espace d'incorporation des programmes, combinant des stratégies programmatiques différentiables avec l'entraînement RL ; HPRL à l'ICML 2023 a proposé l'apprentissage par renforcement programmatique hiérarchique, permettant à une méta-stratégie de combiner plusieurs programmes ; le cadre LLM-GS de l'Université nationale de Taïwan et Microsoft en 2024 a utilisé les capacités de programmation et de raisonnement de sens commun des LLM pour guider la recherche de stratégies RL programmatiques.
Le consensus de ces recherches est que, par rapport aux stratégies neuronales, les stratégies programmatiques offrent une meilleure interprétabilité, une meilleure vérifiabilité formelle et une meilleure capacité de généralisation à des scénarios non vus.
La contribution substantielle de Weng Jiayi cette fois-ci réside dans la considération de l'agent de codage comme un canal d'ingénierie pour maintenir le système heuristique. Auparavant, pour faire du RL programmatique, il fallait soit s'appuyer sur des langages dédiés au domaine conçus manuellement, soit sur des algorithmes de recherche dans un espace de programmes restreint ; Weng Jiayi, quant à lui, utilise Codex pour intégrer le code, les journaux, les tests, les enregistrements vidéo, les ajustements de paramètres dans un même flux de travail de l'agent, réduisant ainsi d'un coup le coût d'itération des stratégies programmatiques. En d'autres termes, il argumente en faveur d'une nouvelle voie d'ingénierie : lorsque l'agent de codage est suffisamment puissant, les stratégies heuristiques autrefois jugées « trop coûteuses à maintenir » pourraient redevenir rentables.
Dans son blog, Weng Jiayi fournit un tableau comparatif, clarifiant les différences entre HL et Deep RL : sur la forme de la stratégie, le premier correspond à des règles, machines à états, contrôleurs, contrôle prédictif de modèle (MPC), macros-actions composant du code, le second à des paramètres de réseau neuronal ; sur la forme de l'état, le premier utilise des variables explicites, des détecteurs et des caches, le second des vecteurs d'observation lisibles par le réseau ; sur la forme de la rétroaction, le premier considère les tests, journaux, enregistrements comme des signaux efficaces, le second s'appuie principalement sur une fonction de récompense fixe ; sur la forme de la mémoire, le premier peut stocker explicitement des essais, des résumés, des causes d'échec et des diff de version, le second dans les algorithmes on-policy n'en a pratiquement pas, et dans les algorithmes off-policy s'appuie sur un tampon de rejeu.
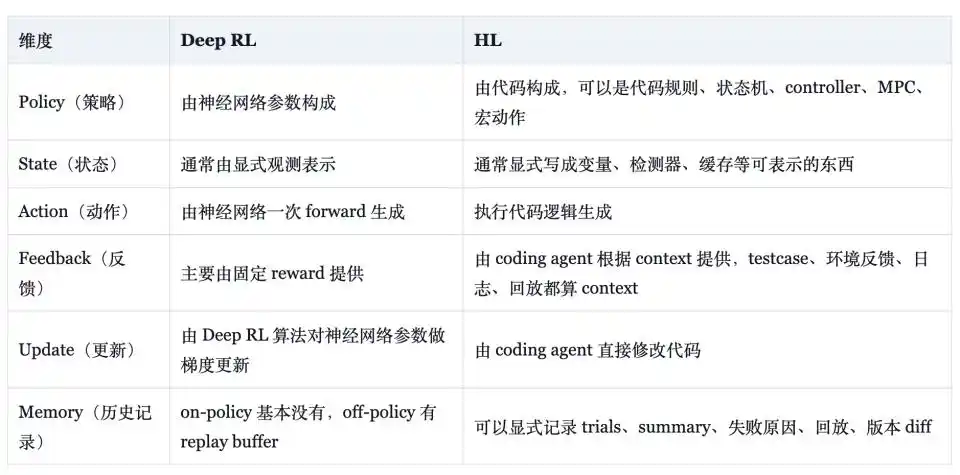
Cette comparaison démontre que le HL possède certaines propriétés significatives d'un point de vue ingénierie : la stratégie est interprétable et peut être traduite en langage naturel ; l'efficacité des échantillons se mesure en unités de « modification de code efficace », et non en mises à jour de gradient lentes ; les anciennes capacités peuvent devenir des tests de régression, des enregistrements à graine fixe ou des cas de référence ; le surajustement aux graines d'entraînement ou aux vulnérabilités des tests peut être contraint par la simplification, les vérifications de régression et l'évaluation multi-graines ; les anciennes capacités n'existent pas uniquement dans les poids, mais peuvent aussi exister dans des ensembles de règles et des tests, ce qui répond en partie au problème de l'oubli catastrophique, longtemps mal résolu par les réseaux neuronaux.
03
Validation par lots sur Atari57 : limites et faiblesses
Si l'on ne regarde que Breakout, l'histoire peut facilement être réduite à « l'IA a écrit une stratégie parfaite ». Mais Weng Jiayi ne s'est pas arrêté à Breakout ; il a étendu ce flux de travail Codex par lots à Atari57, exécutant 57 jeux, deux modes d'observation, trois répétitions, pour un total de 342 trajectoires de recherche « sans surveillance ».
La conception de l'expérience était assez rigoureuse. Chaque jeu a été testé avec deux modes d'entrée : un lisant directement la mémoire du jeu, et l'autre ne regardant que l'écran, chaque mode étant répété indépendamment trois fois. Cela a généré un total de 342 trajectoires expérimentales « sans surveillance » : chaque agent Codex recevait le même modèle d'invite, explorait lui-même les actions, écrivait son propre code, exécutait ses propres expériences, enregistrait ses propres résultats, sans intervention humaine. Les contraintes étaient strictement définies : interdiction d'entraîner un réseau neuronal, de lire le code source du jeu, d'utiliser toute information cachée, tous les pas utilisés pour le débogage et les essais-erreurs devaient être comptabilisés dans le coût total. Ceci afin d'éviter que Codex ne triche en « regardant la réponse ».
Pour mesurer les résultats, on utilise généralement une métrique appelée HNS (Human-Normalized Score, score normalisé par rapport à l'humain) – en simplifiant, il s'agit de normaliser le score de chaque jeu par rapport au « niveau moyen d'un joueur humain = 1 », facilitant ainsi la comparaison horizontale entre différents jeux.
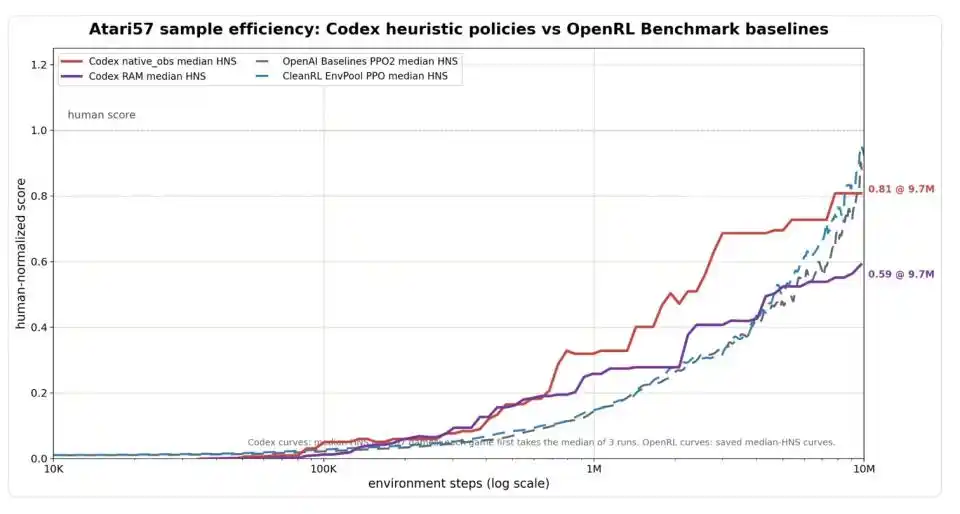
Figure : Comparaison de l'efficacité des échantillons sur l'ensemble complet d'Atari57. L'axe horizontal représente le nombre de pas d'environnement (échelle logarithmique), l'axe vertical le HNS (score normalisé par rapport à l'humain, 1,0 indiquant le niveau moyen d'un joueur humain). La version Codex avec entrée visuelle (ligne rouge) dépasse nettement la ligne de base PPO (lignes pointillées bleues/grises) en efficacité précoce, atteignant 0,81 à 9,7 millions de pas, proche du niveau de PPO autour de 10 millions de pas ; la version Codex avec entrée mémoire (ligne violette) converge vers 0,59.
Selon ce critère, Codex s'est montré assez brillant en termes d'efficacité précoce. En ne consommant que 1 million de pas d'environnement, le HNS médian de Codex avec entrée visuelle avait déjà atteint 0,32, et avec entrée mémoire 0,26, nettement supérieur aux niveaux d'algorithmes classiques d'apprentissage par renforcement comme PPO à la même période. À 9,7 millions de pas, la version visuelle de Codex a atteint 0,81, se rapprochant du niveau d'environ 0,88 à 0,92 de PPO à 10 millions de pas. Si l'on permet d'agréger pour chaque jeu le meilleur des deux modes d'entrée de Codex, le HNS médian de Codex est de 0,83, celui d'OpenAI Baselines PPO2 de 0,80, et celui de CleanRL EnvPool PPO de 0,98 – un match pratiquement nul.
Mais Weng Jiayi lui-même trace une limite avec calme : il s'agit uniquement d'une comparaison d'efficacité d'interaction avec l'environnement, sans prendre en compte le coût de lecture des journaux, d'écriture du code, de visionnage des vidéos par Codex. « Rapide » n'égale pas « coût total faible », ce dernier restant actuellement une boîte noire.
Plus intéressant encore, les performances de Codex sur les 57 jeux ne sont pas uniformes. Dans les jeux à structure géométrique claire comme Breakout, Boxing, Krull, les stratégies heuristiques et l'apprentissage par renforcement profond dépassent nettement le niveau humain ; dans des jeux avec des règles claires comme Asterix, Jamesbond, Tennis, les stratégies heuristiques sont même plus fortes ; mais dans des jeux au rythme rapide et aux schémas complexes comme Atlantis, VideoPinball, RoadRunner, StarGunner, PPO domine toujours.
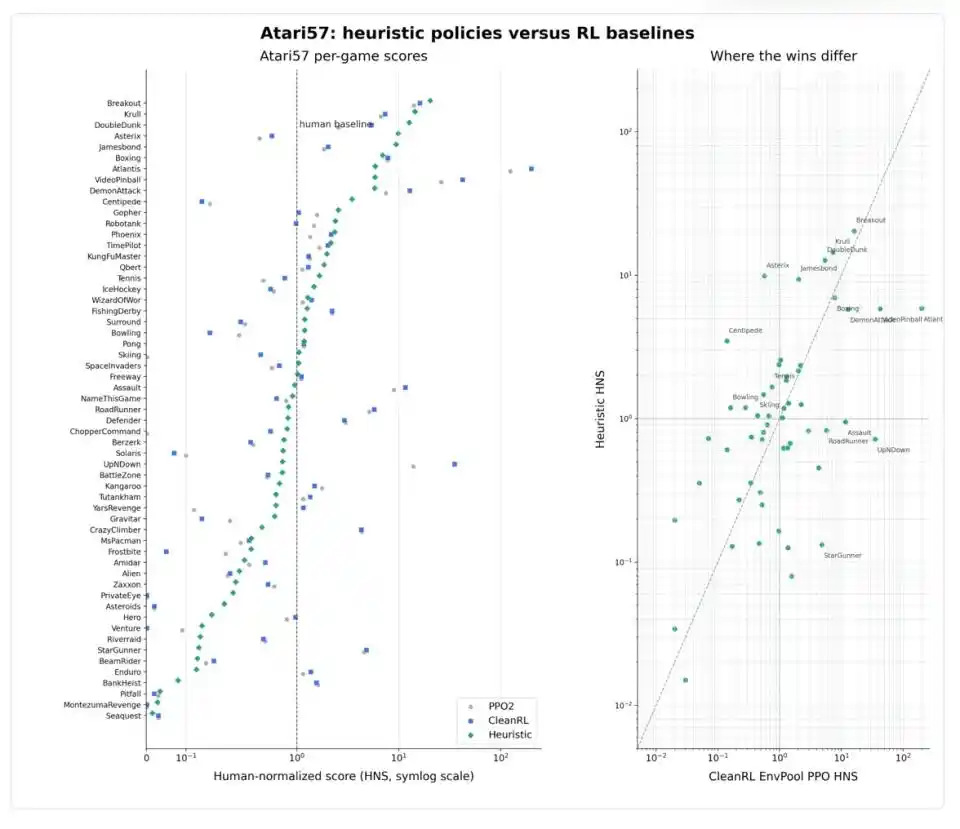
Le contre-exemple le plus instructif est Montezuma’s Revenge. C'est un « os dur » célèbre dans le domaine de l'apprentissage par renforcement : le personnage principal doit chercher des clés, éviter des ennemis, ouvrir des portes dans un dédale de catacombes complexes, le signal de récompense est extrêmement rare, c'est un problème classique de « planification à long terme + récupération après échec ». Codex a bien obtenu 400 points sur ce jeu, mais en ouvrant le fichier de stratégie généré, on découvre qu'il ne s'agit pas d'une véritable « stratégie », mais d'une séquence codée en dur de 86 actions, correspondant à 1769 pas d'environnement : cela ressemble davantage à la mémorisation d'un chemin fixe qu'à l'apprentissage de la navigation dans un labyrinthe. Weng Jiayi souligne spécifiquement : « C'est un cas limite, qui ne doit pas être interprété comme une stratégie Montezuma générique. »
Montezuma expose les limites d'expressivité de l'Apprentissage Heuristique. Une stratégie programmatique ordinaire est essentiellement une logique réactive « faire telle action en voyant tel état », difficilement capable de traiter des tâches nécessitant une séquence d'actions stricte, une reprise de plan à partir d'un état intermédiaire, une planification à long terme. Ce type de tâche nécessite non seulement davantage de if-else, mais une structure programmatique plus proche de « combinaison de macros-actions + état de recherche récupérable + mémoire à long terme ». Cela nous dit une chose : même si l'agent de codage est très puissant, certains problèmes ne peuvent pas être contenus dans du code ordinaire.
04
Une fois le paradigme établi, quelle est sa signification industrielle ?
Revenons à l'industrie. Si la voie de l'Apprentissage Heuristique se confirme vraiment, c'est-à-dire « l'agent de codage peut maintenir de manière stable des stratégies programmatiques dépassant les règles manuelles et approchant les lignes de base RL », quelle est sa signification pratique ?
Le premier point d'application est le contrôle des robots, en particulier dans des scénarios à structure relativement stable. L'idée proposée par Weng Jiayi dans son blog est une division hiérarchique : HL au niveau articulaire, HL au niveau des membres, HL pour l'équilibre corporel, HL au niveau de la tâche. Les couches basses gèrent la sécurité et le contrôle à faible latence, les couches intermédiaires la démarche et le contact, les couches hautes la tâche et la mémoire à long terme ; l'agent de codage n'a pas besoin de « comprendre la marche », il ressemble davantage à un canal de mise à jour inséré dans le système, renvoyant les vidéos d'échec, les flux de capteurs, les résultats de simulation, et réécrivant les retours sous forme de code, paramètres, règles de protection et mémoire.
Les scénarios comme les AGV d'entrepôt, les robots d'inspection, les bras robotiques industriels, le tri standardisé, où la structure environnementale est relativement fixe et les limites de sécurité claires – si la stratégie de contrôle centrale peut être solidifiée en code léger, chaque action du robot n'a pas besoin de faire tourner un grand réseau de stratégie, la dépendance du déploiement aux cartes de calcul GPU haute consommation pour l'inférence diminue, et davantage de charge peut être confiée aux contrôleurs traditionnels et à la logique programmatique locale.
Cela ne signifie pas que les robots n'ont pas besoin de GPU ; la perception, la localisation, la cartographie, la compréhension sémantique reposent toujours sur des réseaux neuronaux ; le changement concerne le rôle du GPU, passant de « brûler des calculs pour la prise de décision actionnelle de bout en bout à chaque seconde » à « jouer un rôle périodique dans la perception, la simulation hors ligne, la génération de stratégies, l'analyse d'anomalies ».
Le deuxième point d'application est l'auditabilité dans les scénarios critiques pour la sécurité. Le problème d'ingénierie le plus épineux des stratégies neuronales est l'impossibilité de localiser la cause après un problème. Un bras robotique échoue soudainement sous un certain angle, un véhicule fait une erreur de jugement dans un scénario limite, un robot médical a un mouvement anormal dans une posture rare, les ingénieurs ne peuvent pas répondre à « quel poids a causé cette erreur », et finissent par ajouter des données, ré-entraîner, tester la régression, puis parier que le nouveau modèle n'introduit pas de nouveaux problèmes.
Si la stratégie existe sous forme de code, les variables d'état, les branches conditionnelles, les journaux d'échec et les tests de régression sont visibles ; une action dangereuse peut être interdite par codage en dur, un cas limite peut être écrit comme test, une transition d'état erronée peut être corrigée individuellement. Cela ne rend pas le système intrinsèquement plus sûr, mais permet pour la première fois que les problèmes de sécurité entrent dans un processus d'ingénierie logicielle normal – pouvant être revus en code, interceptés par l'intégration continue, traités par les équipes SRE en service. Dans des domaines nécessitant régulation et division des responsabilités comme la conduite autonome, les bras robotiques industriels, les robots médicaux, cette auditabilité a une valeur commerciale en soi.
Le troisième point d'application est l'industrialisation de l'apprentissage continu et en ligne. Weng Jiayi présente cette ligne comme l'argument principal de tout l'article dans son blog. L'oubli catastrophique des réseaux neuronaux est un problème structurel : apprendre de nouvelles choses érode les anciennes capacités. Le HL oublie aussi, mais sous une forme plus ingénierie : une nouvelle règle corrige un mode d'échec mais détruit un ancien scénario ; une nouvelle mémoire entraîne à plusieurs reprises l'agent vers une mauvaise direction ; une plage de test trop étroite, la stratégie apprend à en tirer parti ; un correctif modifie une interface partagée, les anciens chemins d'appel échouent silencieusement.
Ces problèmes ne disparaissent pas automatiquement, mais ce sont des problèmes que l'ingénierie logicielle traite depuis des décennies, avec des chaînes d'outils existantes – tests de régression, diff de versions, enregistrements à graine fixe, traces de référence, directions d'échec explicitement notées.
Un HS sain doit posséder simultanément deux opérations : absorber de nouveaux retours et compresser les correctifs historiques ; un HS ne faisant que croître finira par devenir une « boule de code » que personne n'osera toucher. En d'autres termes, le HL transforme le problème mathématique « comment mettre à jour les paramètres » en problème d'ingénierie « comment maintenir un système logiciel absorbant constamment des retours ».
Ce dernier n'est pas nécessairement plus facile, mais plus proche de la frontière des capacités humaines existantes.
Le quatrième point d'application est la sédimentation des capacités des produits Agent. Ce qui manque le plus aux produits Agent actuels, c'est l'appel d'outils stable, les chaînes d'exécution fiables, l'expérience d'échec réutilisable et les enregistrements de tâches auditable. Si la logique du HL tient, la mémoire de l'Agent pendant l'exécution se sédimentera en actifs de code réutilisables à travers les sessions, utilisateurs et tâches. Il pourra s'interfacer directement avec les processus DevOps existants, et signifiera également que les Agents de différentes entreprises et équipes pourront partager des heuristiques, sans avoir à partager les modèles, ce que la solution des réseaux neuronaux ne permet pas.
Cependant, il est important de souligner : les quatre points d'application ci-dessus dépendent tous d'une validation plus poussée de la voie HL sur des tâches plus complexes. Breakout et Ant sont des environnements relativement propres ; les robots réels font face à des variations de friction du sol, d'éclairage, de retard des actionneurs, de bruit des capteurs, qui n'ont pas encore été systématiquement évalués dans les documents publics. Le contre-exemple de Montezuma a déjà montré que les tâches à long terme nécessitent des formes programmatiques dépassant les simples if-else. Jusqu'où cette vision peut aller dépendra des expériences de la prochaine phase.
05
La dette technique se transfère des poids au code
Le jugement de Weng Jiayi dans son blog est très mesuré. Il écrit que le HL ne peut pas accomplir tout ce que font les réseaux neuronaux, il est limité par ce que le code peut exprimer, en particulier dans la perception complexe et la généralisation à long terme. Avec la compréhension actuelle, il ne peut imaginer un agent utilisant du code Python pur, sans aucun réseau neuronal, pour résoudre ImageNet. La vraie question à discuter est comment combiner les réseaux neuronaux et le HL pour traiter conjointement l'Apprentissage en Ligne et l'Apprentissage Continu.
La division du travail qu'il propose emprunte le langage Système 1 / Système 2 : des réseaux neuronaux spécialisés et peu profonds prennent en charge une partie du Système 1, responsable de la perception rapide, de la classification et de l'estimation de l'état des objets ; le HL prend également en charge une partie du Système 1, responsable du traitement des données nouvelles, des règles, tests, enregistrements, mémoire, limites de sécurité et récupération locale ; l'agent LLM joue le rôle de Système 2, fournissant des retours au HL, améliorant les données, et extrayant périodiquement des informations des données générées par le HL pour se mettre à jour.
Si l'apprentissage profond des dix dernières années a prouvé que « l'expérience peut être compressée dans les poids », l'hypothèse proposée cette fois par Weng Jiayi est une autre proposition : à l'ère des agents de codage, l'expérience pourrait peut-être redevenir un logiciel lisible, modifiable, testable.
Cet article provient du compte officiel WeChat « Tencent Technology », auteur : Xiao Jing, éditeur : Xu Qingyang






