Auteur : Li Hailun, Su Yang
Le 6 janvier, heure de Pékin, le PDG de NVIDIA, Huang Renxun, vêtu de sa veste en cuir emblématique, est à nouveau monté sur la scène principale du CES2026.
Lors du CES 2025, NVIDIA avait présenté la puce Blackwell en production et une pile technologique complète d'IA physique. Lors de cette conférence, Huang Renxun avait souligné qu'une "ère de l'IA physique" était en train de s'ouvrir. Il avait décrit un futur plein d'imagination : des voitures autonomes dotées de capacités de raisonnement, des robots capables de comprendre et de penser, et des agents IA capables de traiter des tâches contextuelles longues impliquant des millions de tokens.
Une année s'est écoulée, et l'industrie de l'IA a connu une évolution et des changements considérables. En revenant sur ces changements lors de la conférence, Huang Renxun a notamment mentionné les modèles open source.
Il a déclaré que des modèles de raisonnement open source comme DeepSeek R1 ont fait prendre conscience à toute l'industrie que lorsque la collaboration ouverte et mondiale se met véritablement en marche, la diffusion de l'IA est extrêmement rapide. Bien que les modèles open source soient toujours en retard d'environ six mois sur les modèles les plus avancés en termes de capacités globales, ils se rapprochent tous les six mois, et leurs téléchargements et leur utilisation ont déjà connu une croissance explosive.

Comparé à 2025 où il s'agissait davantage de présenter une vision et des possibilités, NVIDIA commence cette fois-ci à s'attaquer systématiquement au problème du "comment y parvenir" : autour de l'IA de raisonnement, en complétant l'infrastructure de calcul, de réseau et de stockage nécessaire pour un fonctionnement à long terme, en réduisant significativement les coûts d'inférence, et en intégrant ces capacités directement dans des scénarios réels comme la conduite autonome et la robotique.
Le discours de Huang Renxun au CES cette année s'articule autour de trois axes principaux :
● Au niveau des systèmes et de l'infrastructure, NVIDIA a repensé l'architecture de calcul, de réseau et de stockage autour des besoins d'inférence à long terme. Avec la plateforme Rubin, NVLink 6, Spectrum-X Ethernet et la plateforme de stockage mémoire contextuelle pour l'inférence comme éléments centraux, ces mises à jour ciblent directement les goulots d'étranglement que sont le coût élevé de l'inférence, la difficulté à maintenir le contexte et les limitations de mise à l'échelle, résolvant les problèmes de "réflexion prolongée de l'IA", de "calcul abordable" et d'"exécution durable".
● Au niveau des modèles, NVIDIA place l'IA de raisonnement (Reasoning / Agentic AI) au cœur de sa stratégie. Grâce à des modèles et des outils comme Alpamayo, Nemotron, Cosmos Reason, etc., l'IA évolue de la "génération de contenu" vers une capacité de "réflexion continue", passant d'un "modèle à réponse ponctuelle" à un "agent intelligent capable de travailler à long terme".
● Au niveau des applications et du déploiement, ces capacités sont directement introduites dans des scénarios d'IA physique comme la conduite autonome et la robotique. Que ce soit l'écosystème de conduite autonome propulsé par Alpamayo ou l'écosystème robotique GR00T avec Jetson, tous deux collaborent avec des fournisseurs de cloud et des plateformes d'entreprise pour promouvoir un déploiement à grande échelle.

01 De la feuille de route à la production : Rubin révèle pour la première fois ses données de performance complètes
Lors de ce CES, NVIDIA a divulgué pour la première fois les détails techniques complets de l'architecture Rubin.
Dans son discours, Huang Renxun a commencé par évoquer le Test-time Scaling (mise à l'échelle au moment de l'inférence). Ce concept peut être compris ainsi : pour rendre l'IA plus intelligente, il ne s'agit plus seulement de lui faire "lire plus de livres", mais de lui permettre de "réfléchir un peu plus longtemps lorsqu'elle rencontre un problème".
Par le passé, l'amélioration des capacités de l'IA reposait principalement sur l'utilisation de plus de puissance de calcul pendant la phase d'entraînement, en rendant les modèles de plus en plus grands ; désormais, le nouveau changement est que même si le modèle n'augmente plus en taille, simplement en lui donnant un peu plus de temps et de puissance de calcul pour réfléchir à chaque utilisation, les résultats peuvent s'améliorer significativement.
Comment rendre économiquement viable le fait de "laisser l'IA réfléchir plus longtemps" ? La nouvelle plateforme de calcul IA de l'architecture Rubin est là pour résoudre ce problème.
Huang Renxun a présenté il s'agit d'un système de calcul IA de nouvelle génération complet, conçu de manière synergique avec le CPU Vera, le GPU Rubin, NVLink 6, ConnectX-9, BlueField-4 et Spectrum-6, afin de réaliser une baisse révolutionnaire des coûts d'inférence.

Le GPU Rubin NVIDIA est la puce centrale responsable du calcul IA dans l'architecture Rubin, avec pour objectif de réduire significativement le coût unitaire de l'inférence et de l'entraînement.
En clair, la mission principale du GPU Rubin est de "rendre l'IA moins chère à utiliser et plus intelligente".
La capacité clé du GPU Rubin réside dans le fait qu'un même GPU peut accomplir plus de travail. Il peut traiter plus de tâches d'inférence en une fois, mémoriser un contexte plus long, et communiquer plus rapidement avec les autres GPU, ce qui signifie que de nombreux scénarios qui nécessitaient auparavant un "empilement de plusieurs cartes" peuvent maintenant être réalisés avec moins de GPU.
Le résultat est que l'inférence est non seulement plus rapide, mais aussi nettement moins chère.
Huang Renxun a rappelé sur scène les spécifications matérielles du NVL72 de l'architecture Rubin : il contient 220 billions de transistors, une bande passante de 260 To/s, et est la première plateforme au monde à prendre en charge le calcul confidentiel à l'échelle d'un baie.

Dans l'ensemble, par rapport à Blackwell, le GPU Rubin réalise un bond générationnel sur les indicateurs clés : les performances d'inférence NVFP4 passent à 50 PFLOPS (x5), les performances d'entraînement à 35 PFLOPS (x3.5), la bande passante mémoire HBM4 à 22 To/s (x2.8), et la bande passante d'interconnexion NVLink par GPU double pour atteindre 3,6 To/s.
Ces améliorations combinées permettent à un seul GPU de traiter plus de tâches d'inférence et un contexte plus long, réduisant fondamentalement la dépendance au nombre de GPU.

Le CPU Vera est un composant central conçu spécifiquement pour le mouvement des données et le traitement agentique. Il utilise 88 cœurs Olympus conçus par NVIDIA, est équipé de 1,5 To de mémoire système (3 fois plus que le CPU Grace précédent), et permet un accès mémoire cohérent entre le CPU et le GPU grâce à la technologie NVLink-C2C à 1,8 To/s.
Contrairement aux CPU universels traditionnels, Vera se concentre sur la planification des données et le traitement de la logique de raisonnement à plusieurs étapes dans les scénarios d'inférence IA, étant essentiellement le coordinateur système qui permet à "l'IA de réfléchir plus longtemps" de fonctionner efficacement.
NVLink 6, avec sa bande passante de 3,6 To/s et sa capacité de calcul en réseau, permet aux 72 GPU de l'architecture Rubin de travailler ensemble comme un seul super GPU, ce qui est une infrastructure clé pour réduire les coûts d'inférence.
Ainsi, les données et résultats intermédiaires dont l'IA a besoin pendant l'inférence peuvent circuler rapidement entre les GPU, sans avoir à attendre, copier ou recalculer de manière répétée.


Dans l'architecture Rubin, NVLink-6 est responsable de la collaboration de calcul interne des GPU, BlueField-4 de la planification du contexte et des données, et ConnectX-9 assume la connexion réseau externe haute vitesse du système. Il assure que le système Rubin peut communiquer efficacement avec d'autres baies, centres de données et plateformes cloud, condition préalable au bon fonctionnement des tâches d'entraînement et d'inférence à grande échelle.
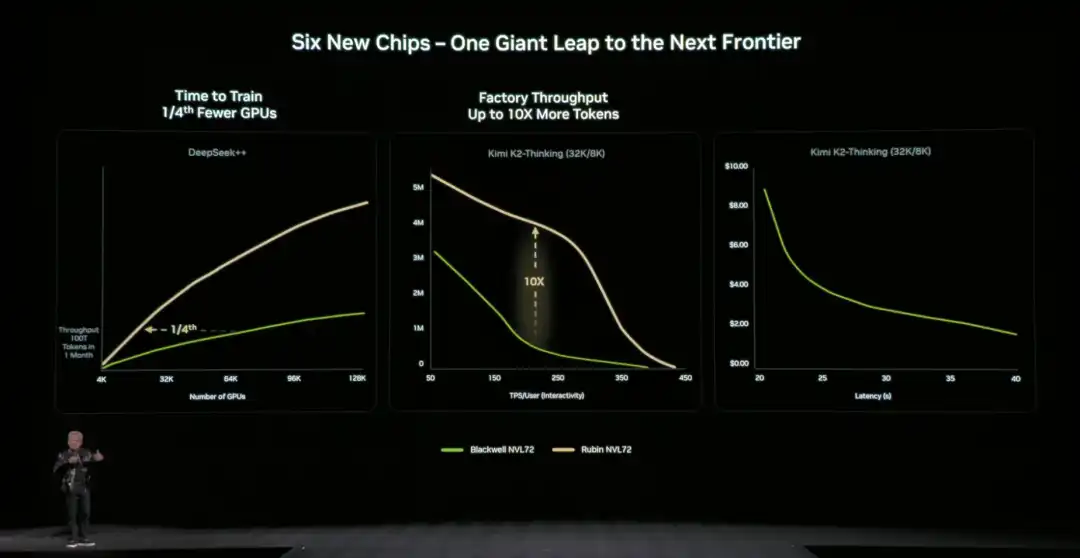
Comparé à l'architecture précédente, NVIDIA fournit également des données concrètes et直观 : par rapport à la plateforme NVIDIA Blackwell, elle peut réduire le coût par token lors de la phase d'inférence jusqu'à 10 fois, et réduire le nombre de GPU requis pour entraîner des modèles mixtes d'experts (MoE) à un quart de ce qu'il était.
NVIDIA a officiellement déclaré que Microsoft s'est déjà engagé à déployer des centaines de milliers de puces Vera Rubin dans sa prochaine usine super intelligente Fairwater, et que des fournisseurs de services cloud comme CoreWeave proposeront des instances Rubin au second semestre 2026. Cette infrastructure permettant à "l'IA de réfléchir plus longtemps" passe de la démonstration technique à la commercialisation à grande échelle.

02 Comment résoudre le "goulot d'étranglement du stockage" ?
Le fait de laisser l'IA "réfléchir plus longtemps" rencontre également un défi technique clé : où stocker les données contextuelles ?
Lorsque l'IA traite des tâches complexes nécessitant des conversations à plusieurs tours ou un raisonnement à plusieurs étapes, elle génère une grande quantité de données contextuelles (KV Cache). L'architecture traditionnelle soit les entasse dans la mémoire GPU, coûteuse et de capacité limitée, soit les place dans un stockage ordinaire (accès trop lent). Si ce "goulot d'étranglement du stockage" n'est pas résolu, même le GPU le plus puissant sera ralenti.
Pour résoudre ce problème, NVIDIA a divulgué pour la première fois de manière complète lors de ce CES la plateforme de stockage mémoire contextuelle pour l'inférence (Inference Context Memory Storage Platform) propulsée par BlueField-4, avec pour objectif principal de créer une "troisième couche" entre la mémoire GPU et le stockage traditionnel. Assez rapide, avec une capacité suffisante, et capable de supporter le fonctionnement à long terme de l'IA.
D'un point de vue technique, cette plateforme ne repose pas sur un seul composant, mais sur le résultat d'une conception collaborative :
- BlueField-4 est responsable de l'accélération matérielle de la gestion et de l'accès aux données contextuelles, réduisant le mouvement des données et la surcharge système ;
- Spectrum-X Ethernet fournit un réseau haute performance, prenant en charge le partage de données haute vitesse basé sur RDMA ;
- Les composants logiciels tels que DOCA, NIXL et Dynamo sont responsables de l'optimisation de la planification au niveau système, de la réduction de la latence et de l'amélioration du débit global.
On peut comprendre que l'approche de cette plateforme est d'étendre les données contextuelles, qui ne pouvaient auparavant être placées que dans la mémoire GPU, à une "couche de mémoire" indépendante, haute vitesse et partageable. D'une part, cela libère la pression sur le GPU, et d'autre part, cela permet de partager rapidement ces informations contextuelles entre plusieurs nœuds et plusieurs agents IA.
En termes d'effet pratique, les données fournies officiellement par NVIDIA sont : dans des scénarios spécifiques, cette méthode peut augmenter le nombre de tokens traités par seconde jusqu'à 5 fois, et réaliser des optimisations d'efficacité énergétique équivalentes.
Huang Renxun a souligné à plusieurs reprises lors de la présentation que l'IA évolue d'un "chatbot conversationnel ponctuel" vers de véritables agents de collaboration intelligents : ils doivent comprendre le monde réel, raisonner de manière continue, utiliser des outils pour accomplir des tâches et conserver une mémoire à court et long terme. C'est précisément la caractéristique centrale de l'IA agentique. La plateforme de stockage mémoire contextuelle pour l'inférence est conçue pour cette forme d'IA fonctionnant à long terme et réfléchissant de manière répétée, en élargissant la capacité contextuelle et en accélérant le partage entre les nœuds, rendant les conversations à plusieurs tours et la collaboration multi-agents plus stables, sans "ralentir progressivement".

03 La nouvelle génération de DGX SuperPOD : faire travailler 576 GPU ensemble
NVIDIA a annoncé lors de ce CES le lancement de la nouvelle génération de DGX SuperPOD (super nœud) basée sur l'architecture Rubin, étendant Rubin d'une seule baie à une solution complète pour l'ensemble du centre de données.
Qu'est-ce que le DGX SuperPOD ?
Si le Rubin NVL72 est une "super baie" contenant 72 GPU, alors le DGX SuperPOD consiste à connecter plusieurs de ces baies pour former un cluster de calcul IA à plus grande échelle. La version annoncée cette fois est composée de 8 baies Vera Rubin NVL72, ce qui équivaut à 576 GPU travaillant en collaboration.
Lorsque l'échelle des tâches IA continue de s'élargir, les 576 GPU d'une seule baie peuvent ne pas suffire. Par exemple, pour entraîner des modèles à très grande échelle, servir simultanément des milliers d'agents IA agentiques, ou traiter des tâches complexes nécessitant un contexte de millions de tokens. C'est alors que plusieurs baies doivent travailler ensemble, et le DGX SuperPOD est conçu pour ce scénario en tant que solution standardisée.
Pour les entreprises et les fournisseurs de services cloud, le DGX SuperPOD offre une solution d'infrastructure IA à grande échelle "prête à l'emploi". Il n'est pas nécessaire de rechercher comment connecter des centaines de GPU, comment configurer le réseau, comment gérer le stockage, etc.
Cinq composants clés de la nouvelle génération de DGX SuperPOD :
○ 8 baies Vera Rubin NVL72 - fournissent la puissance de calcul centrale, chaque baie ayant 72 GPU, totalisant 576 GPU ;
○ Réseau d'extension NVLink 6 - permet aux 576 GPU de ces 8 baies de travailler ensemble comme un seul super GPU ;
○ Réseau d'extension Spectrum-X Ethernet - connecte les différents SuperPOD, ainsi qu'au stockage et au réseau externe ;
○ Plateforme de stockage mémoire contextuelle pour l'inférence - fournit un stockage partagé des données contextuelles pour les tâches d'inférence de longue durée ;
○ Logiciel NVIDIA Mission Control - gère la planification, la surveillance et l'optimisation de l'ensemble du système.
Cette fois, la mise à niveau a pour base le système de baie DGX Vera Rubin NVL72 comme cœur. Chaque NVL72 est lui-même un supercalculateur IA complet, connectant en interne 72 GPU Rubin via NVLink 6, capable d'effectuer des tâches d'inférence et d'entraînement à grande échelle au sein d'une seule baie. Le nouveau DGX SuperPOD est composé de plusieurs NVL72, formant un cluster au niveau du système pouvant fonctionner à long terme.
Lorsque l'échelle de calcul passe d'une "baie unique" à "plusieurs baies", de nouveaux goulots d'étranglement apparaissent : comment transmettre de manière stable et efficace des volumes massifs de données entre les baies. Autour de cette question, NVIDIA a simultanément présenté lors de ce CES le nouveau commutateur Ethernet basé sur la puce Spectrum-6, et a introduit pour la première fois la technologie "Co-Packaged Optics" (CPO).
En bref, cela consiste à encapsuler directement les modules optiques, qui étaient auparavant amovibles, à côté de la puce du commutateur, réduisant la distance de transmission du signal de plusieurs mètres à quelques millimètres, ce qui réduit significativement la consommation d'énergie et la latence, et améliore également la stabilité globale du système.
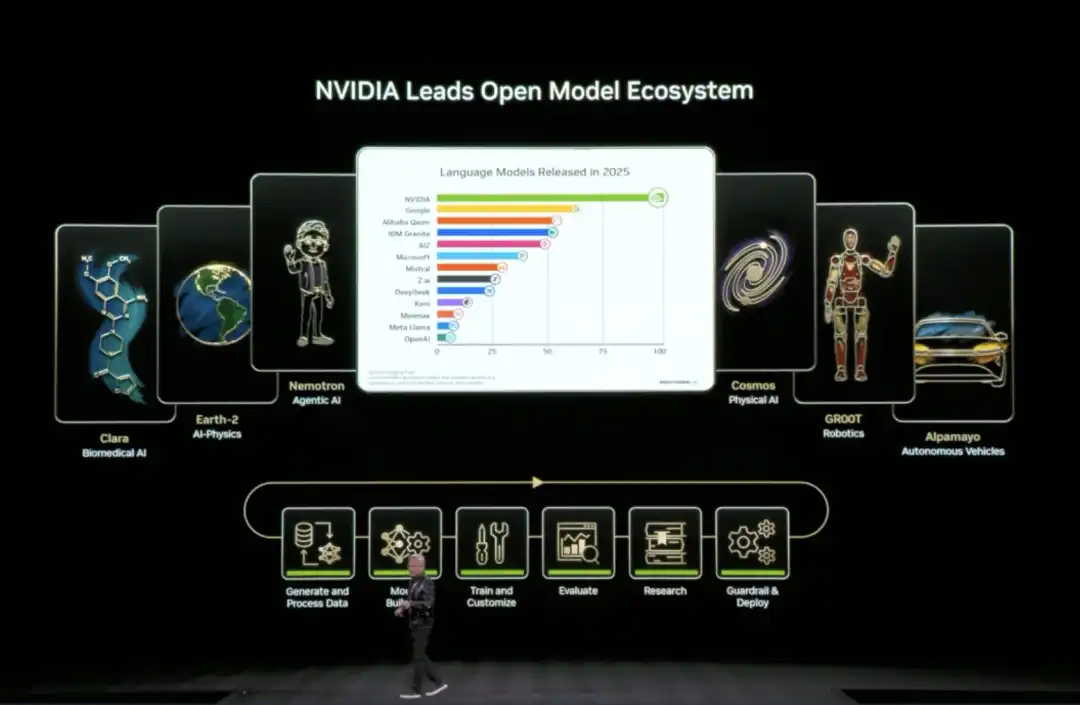
04 La "suite complète" d'IA open source de NVIDIA : des données au code, tout est inclus
Lors de ce CES, Huang Renxun a annoncé l'extension de son écosystème de modèles open source (Open Model Universe), ajoutant et mettant à jour une série de modèles, ensembles de données, bibliothèques de code et outils. Cet écosystème couvre six domaines : l'IA biomédicale (Clara), la simulation physique IA (Earth-2), l'IA agentique (Nemotron), l'IA physique (Cosmos), la robotique (GR00T) et la conduite autonome (Alpamayo).
Entraîner un modèle IA nécessite non seulement de la puissance de calcul, mais aussi des ensembles de données de haute qualité, des modèles pré-entraînés, du code d'entraînement, des outils d'évaluation, etc. - toute une infrastructure. Pour la plupart des entreprises et institutions de recherche, construire tout cela à partir de zéro prend trop de temps.
Concrètement, NVIDIA a ouvert six niveaux de contenu : les plateformes de calcul (DGX, HGX, etc.), les ensembles de données d'entraînement pour divers domaines, les modèles de base pré-entraînés, les bibliothèques de code pour l'inférence et l'entraînement, les scripts complets de flux d'entraînement, et des modèles de solutions de bout en bout.
La série Nemotron est le point focal de cette mise à jour, couvrant quatre directions d'application.
Dans la direction du raisonnement, cela inclut des modèles d'inférence de petite taille comme Nemotron 3 Nano, Nemotron 2 Nano VL, ainsi que des outils d'entraînement par renforcement comme NeMo RL, NeMo Gym. Dans la direction RAG (Génération Augmentée par Retrieval), sont fournis Nemotron Embed VL (modèle d'embedding vectoriel), Nemotron Rerank VL (modèle de reclassement), les ensembles de données associés et la NeMo Retriever Library (bibliothèque de retrieval). Dans la direction de la sécurité, il y a le modèle de sécurité de contenu Nemotron Content Safety et son ensemble de données, ainsi que la bibliothèque de garde-fous NeMo Guardrails.
Dans la direction de la voix, sont inclus la reconnaissance automatique de la parole Nemotron ASR, l'ensemble de données vocales Granary Dataset et la bibliothèque de traitement vocal NeMo Library. Cela signifie qu'une entreprise souhaitant créer un système de service client IA avec RAG n'a pas besoin d'entraîner elle-même des modèles d'embedding et de reclassement, elle peut directement utiliser le code déjà entraîné et open source par NVIDIA.
05 Dans le domaine de l'IA physique, vers la commercialisation
Le domaine de l'IA physique a également connu des mises à jour de modèles - Cosmos pour comprendre et générer des vidéos du monde physique, le modèle de base robotique universel Isaac GR00T, et le modèle vision-langage-action pour la conduite autonome Alpamayo.

Huang Renxun a déclaré au CES que le "moment ChatGPT" de l'IA physique arrive bientôt, mais les défis sont nombreux : le monde physique est trop complexe et changeant, collecter des données réelles est lent, cher et jamais suffisant.
Que faire ? Les données synthétiques sont une voie. NVIDIA a donc lancé Cosmos.
Il s'agit d'un modèle de base open source pour le monde de l'IA physique, qui a déjà été pré-entraîné avec des quantités massives de vidéos, de données réelles de conduite et robotiques, ainsi que des simulations 3D. Il peut comprendre comment le monde fonctionne, et relier le langage, les images, la 3D et l'action.
Huang Renxun a indiqué que Cosmos peut réaliser plusieurs compétences d'IA physique, comme générer du contenu, faire du raisonnement, prédire des trajectoires (même si on ne lui donne qu'une image). Il peut générer des vidéos réalistes basées sur des scènes 3D, générer des mouvements conformes aux lois physiques à partir de données de conduite, et générer des vidéos panoramiques à partir de simulateurs, de flux multi-caméras ou de descriptions textuelles. Même les scènes rares peuvent être reproduites.
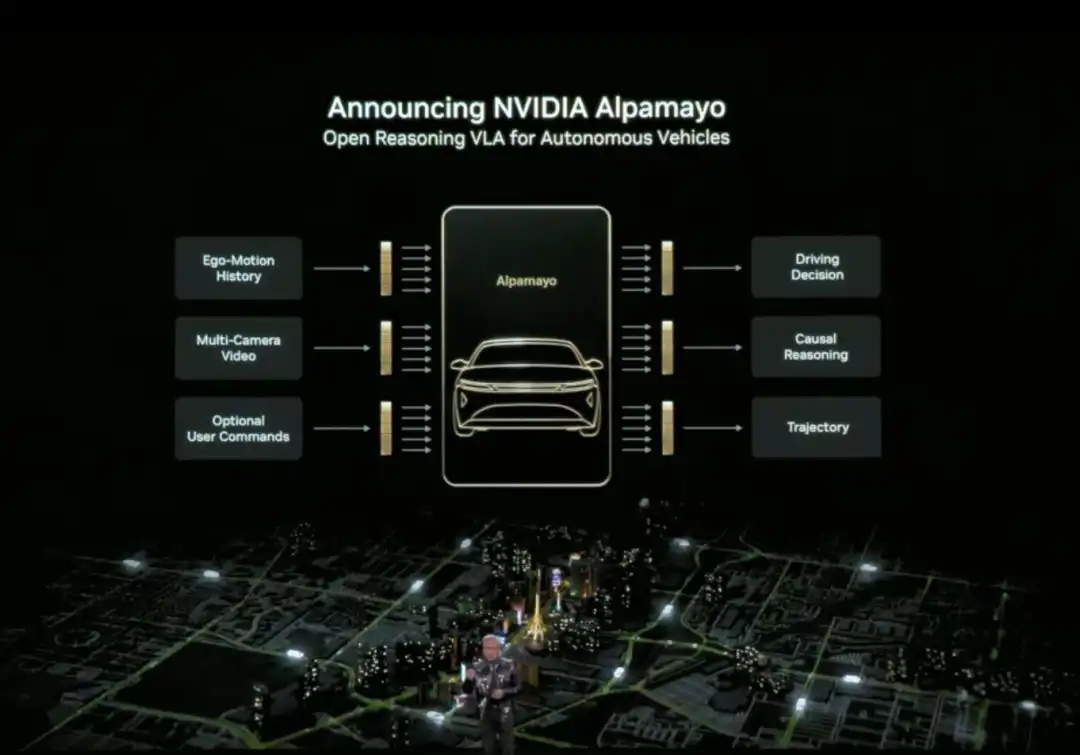
Huang Renxun a également officiellement présenté Alpamayo. Alpamayo est une chaîne d'outils open source pour le domaine de la conduite autonome, et également le premier modèle de raisonnement vision-langage-action (VLA) open source. Contrairement aux précédentes ouvertures de seulement du code, NVIDIA a cette fois-ci ouvert l'ensemble des ressources de développement, des données au déploiement.
La plus grande percée d'Alpamayo est qu'il s'agit d'un modèle de conduite autonome "raisonnant". Les systèmes de conduite autonome traditionnels suivent une architecture en pipeline "perception-planification-contrôle" : voir un feu rouge et freiner, voir un piéton et ralentir, suivant des règles prédéfinies. Alpamayo introduit une capacité de "raisonnement", comprenant les relations de cause à effet dans des scènes complexes, prédisant les intentions des autres véhicules et piétons, et pouvant même traiter des décisions nécessitant une réflexion à plusieurs étapes.
Par exemple, à une intersection, il ne se contente pas de reconnaître "il y a une voiture devant", mais peut raisonner "cette voiture va probablement tourner à gauche, donc je devrais attendre qu'elle passe d'abord". Cette capacité fait passer la conduite autonome de "conduite selon des règles" à "penser comme un humain".
Huang Renxun a annoncé que le système NVIDIA DRIVE entre officiellement en phase de production, la première application étant la nouvelle Mercedes-Benz CLA, prévue pour circuler aux États-Unis en 2026. Cette voiture sera équipée d'un système de conduite autonome de niveau L2++, adoptant une architecture hybride "modèle IA de bout en bout + pipeline traditionnel".
Le domaine de la robotique connaît également des progrès substantiels.
Huang Renxun a déclaré que des entreprises leaders mondiales de la robotique, dont Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics et XRlabs, développent des produits basés sur la plateforme Isaac et le modèle de base GR00T de NVIDIA, couvrant plusieurs domaines allant des robots industriels et chirurgicaux aux robots humanoïdes et robots grand public.

Lors de la conférence, Huang Renxun avait derrière lui une foule de robots de différentes formes et用途, présentés sur une scène à plusieurs niveaux : des robots humanoïdes, des robots de service bipèdes et à roues, aux bras robotiques industriels, engins de chantier, drones et équipements chirurgicaux assistés, présentant une "cartographie de l'écosystème robotique".
Des applications d'IA physique à la plateforme de calcul RubinAI, en passant par la plateforme de stockage mémoire contextuelle pour l'inférence et la "suite complète" d'IA open source.
Les actions présentées par NVIDIA au CES constituent sa narration pour l'infrastructure IA de l'ère du raisonnement. Comme Huang Renxun l'a souligné à plusieurs reprises, lorsque l'IA physique a besoin de réfléchir continuellement, de fonctionner à long terme et d'entrer véritablement dans le monde réel, la question n'est plus de savoir si la puissance de calcul est suffisante, mais qui peut véritablement mettre en place l'ensemble du système.
Au CES 2026, NVIDIA a déjà apporté une réponse.







