Rédigé par : KarenZ, Foresight News
Titre original : Explication simple du nouvel algorithme de recommandation de X : De la « récupération de données » à la « notation »
Est-ce que Musk a modifié le système de recommandation de Twitter, passant de « l'empilement manuel de règles et d'algorithmes heuristiques majoritaires » à « une pure dépendance à l'IA et aux grands modèles pour deviner vos préférences » ?
Le 20 janvier, Twitter (X) a officiellement dévoilé son nouvel algorithme de recommandation, c'est-à-dire la logique derrière le fil chronologique « Pour vous » (For You) de la page d'accueil.
En termes simples, l'algorithme actuel est le suivant : il mélange le « contenu publié par les personnes que vous suivez » et le « contenu de l'ensemble du réseau susceptible de vous plaire », le trie selon l'ordre d'attractivité pour vous en se basant sur votre série d'actions précédentes sur X (j'aime, commentaires, etc.), subit deux filtrages, et devient finalement le flux d'informations recommandées que vous consultez.
Voici la logique centrale traduite en langage simple :
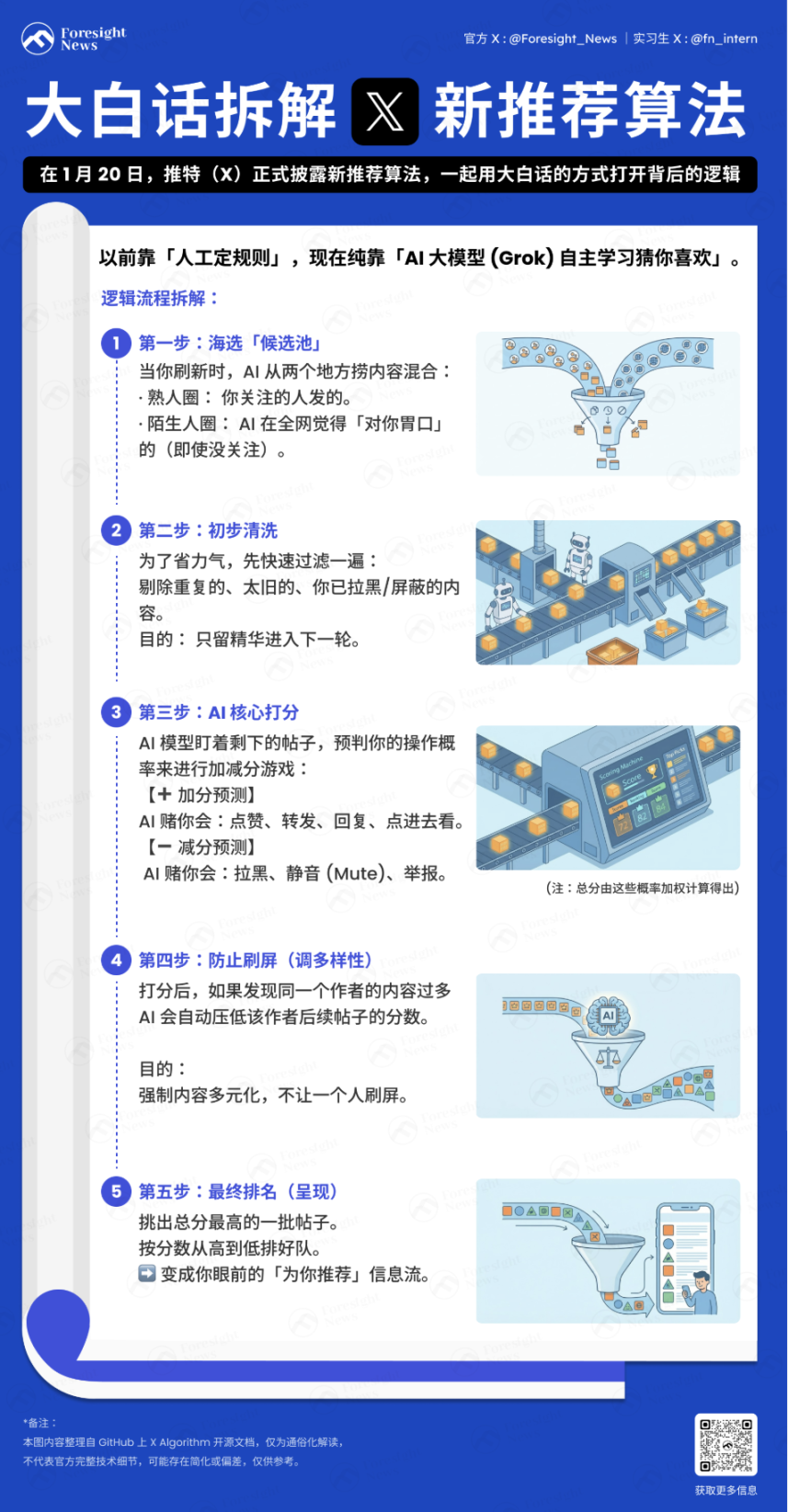
Établissement du profil
Le système collecte d'abord les informations contextuelles de l'utilisateur pour établir un « profil » en vue des recommandations ultérieures :
-
Séquence de comportement de l'utilisateur : Historique des interactions (j'aime, retweets, durée de consultation, etc.).
-
Caractéristiques de l'utilisateur : Liste des abonnements, préférences personnelles, etc.
D'où vient le contenu ?
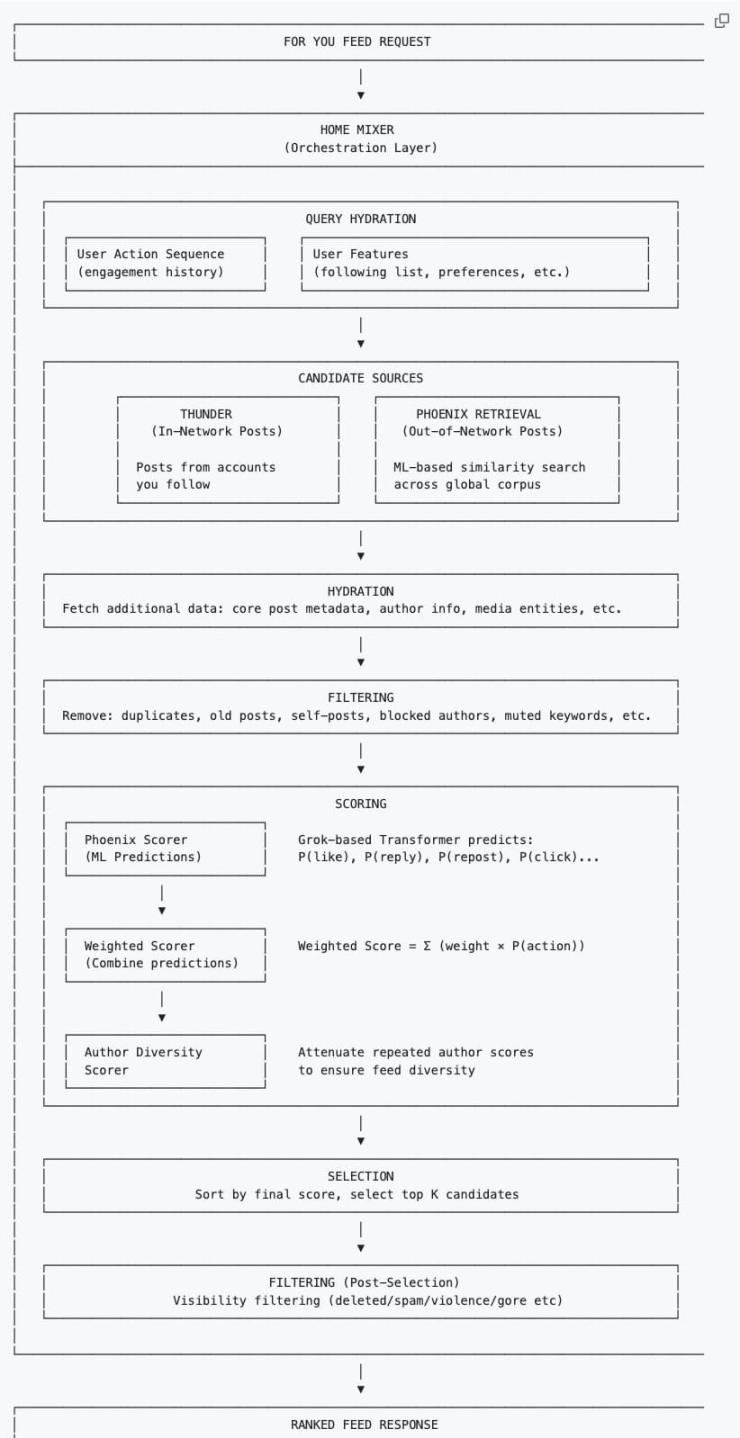
Chaque fois que vous actualisez le fil chronologique « Pour vous », l'algorithme va chercher du contenu dans les deux endroits suivants :
-
Cercle des connaissances (Thunder) : Les tweets publiés par les personnes que vous suivez.
-
Cercle des inconnus (Phoenix) : Des personnes que vous ne suivez pas, mais dont l'IA, selon vos goûts, va extraire des publications qui pourraient vous intéresser (même si vous ne suivez pas l'auteur) du vaste monde.
Ces deux piles de contenu sont mélangées pour former les tweets candidats.
Complétion des données et filtrage préliminaire
Après avoir extrait des milliers de publications, le système récupère les métadonnées complètes des publications (informations sur l'auteur, fichiers multimédias, texte principal), un processus appelé Hydration. Ensuite, un nettoyage rapide est effectué pour éliminer le contenu en double, les anciens posts, les posts que vous avez vous-même publiés, le contenu d'auteurs bloqués ou les contenus avec des mots-clés masqués.
Cette étape vise à économiser les ressources de calcul et à éviter que du contenu non valide n'entre dans l'étape centrale de notation.
Comment noter ?
C'est la partie la plus cruciale. Le modèle Transformer basé sur Phoenix Grok examine chaque tweet candidat restant après filtrage et calcule la probabilité que vous effectuiez diverses actions sur celui-ci. C'est un jeu d'ajouts et de retraits de points :
Points positifs (retour positif) : L'IA estime que vous pourriez aimer, retweeter, répondre, cliquer sur l'image ou consulter le profil.
Points négatifs (retour négatif) : L'IA estime que vous pourriez bloquer l'auteur, le masquer (Mute), ou signaler.

Score final = (Probabilité de like × poids) + (Probabilité de réponse × poids) – (Probabilité de blocage × poids)...
Il est à noter que dans le nouvel algorithme de recommandation, l'Author Diversity Scorer (Outil de notation de la diversité des auteurs) intervient généralement après que l'IA a calculé le score final. Lorsqu'il détecte que dans un lot de tweets candidats, il y a plusieurs contenus du même auteur, cet outil « réduit » automatiquement le score des publications suivantes de cet auteur, afin que les auteurs que vous voyez soient plus diversifiés.
Enfin, les publications sont triées selon leur score, et un lot des publications ayant les scores les plus élevés est sélectionné.
Filtrage secondaire
Le système vérifie à nouveau les premières publications ayant les scores les plus élevés, filtre celles qui sont non conformes (comme le spam, les contenus violents), supprime les doublons provenant d'un même fil de discussion (thread), et enfin les trie du score le plus élevé au plus bas pour former le flux d'informations que vous voyez.
Résumé
X a déjà éliminé toutes les fonctionnalités conçues manuellement et la plupart des algorithmes heuristiques de son système de recommandation. Le progrès central du nouvel algorithme réside dans le fait de « laisser l'IA apprendre automatiquement les préférences des utilisateurs », réalisant ainsi le passage de « dire à la machine quoi faire » à « laisser la machine apprendre elle-même comment faire ».
Tout d'abord, les recommandations sont plus précises, la « prédiction multidimensionnelle » correspond mieux aux besoins réels. Le nouvel algorithme repose sur le grand modèle Grok pour prédire divers comportements des utilisateurs — il ne calcule pas seulement « est-ce que l'utilisateur va aimer/retweeter », mais aussi « est-ce qu'il va cliquer sur le lien », « comment va être le temps de consultation », « est-ce qu'il va suivre l'auteur », et même prédit « est-ce qu'il va signaler/bloquer ». Cette analyse fine permet au contenu recommandé d'atteindre un niveau de correspondance avec les besoins subconscients de l'utilisateur sans précédent.
Ensuite, le mécanisme de l'algorithme est relativement plus équitable, pouvant dans une certaine mesure briser le sort de la « monopolisation par les grands comptes », et donner plus d'opportunités aux nouveaux comptes et petits comptes : Les anciens « algorithmes heuristiques » avaient un problème fatal : les grands comptes, grâce à leur historique d'interactions élevé, obtenaient une forte exposition quel que soit le contenu publié, tandis que les nouveaux comptes, même avec un contenu de qualité, étaient enterrés faute « d'accumulation de données ». Le mécanisme d'isolement des candidats permet à chaque publication d'être notée indépendamment, sans rapport avec le fait que « d'autres contenus du même lot soient viraux ou non ». Parallèlement, l'Author Diversity Scorer réduit également le phénomène de flood (envoi massif) des publications suivantes d'un même auteur dans le même lot.
Pour la société X : Il s'agit d'une mesure de réduction des coûts et d'amélioration de l'efficacité, utilisant la puissance de calcul à la place de la main-d'œuvre, et l'IA pour améliorer la rétention. Pour les utilisateurs, nous faisons face à un « super cerveau » qui scrute constamment nos esprits. Plus il nous comprend, plus nous dépendons de lui, mais précisément parce qu'il nous comprend trop, nous sombrerons plus profondément dans la « bulle informationnelle » tissée par l'algorithme, et serons plus facilement la cible précise de contenus émotionnels.
Twitter : https://twitter.com/BitpushNewsCN
Groupe de discussion TG de Bitpush : https://t.me/BitPushCommunity
Abonnement TG de Bitpush : https://t.me/bitpush