À l'instant, DeepSeek-V4 est arrivé !
La version préliminaire est officiellement lancée et open source simultanément.
Deux versions au total :
DeepSeek-V4-Pro : Équivalent aux modèles propriétaires de pointe, 1,6 T, 49B activés, longueur de contexte 1M ;
DeepSeek-V4-Flash : Version économique plus petite et plus rapide, 284B, 13B activés, longueur de contexte 1M.
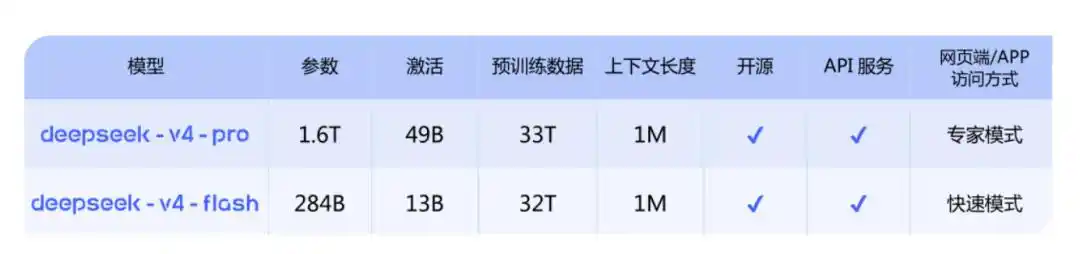
La déclaration officielle est : Des capacités d'Agent, des connaissances mondiales et des performances de raisonnement toutes à la pointe en Chine et dans le domaine open source.
Et :
Actuellement, DeepSeek-V4 est déjà le modèle Agentic Coding utilisé en interne par les employés de l'entreprise. Selon les retours d'évaluation, l'expérience d'utilisation est meilleure que Sonnet 4.5, et la qualité de livraison est proche d'Opus 4.6 en mode non-réflexion. Mais il reste un écart avec le mode réflexion d'Opus 4.6.
Actuellement, le site officiel et l'application sont mis à jour, le service API est également synchronisé.
Concernant la puissance de calcul nationale qui préoccupe tout le monde, point important, support de la puissance de calcul Huawei au second semestre.

Choix haut de gamme et économique, deux versions lancées ensemble
Cette fois, V4 sort deux versions d'un coup.
V4-Pro, performances comparables aux modèles propriétaires de pointe.
L'officiel donne trois critères :
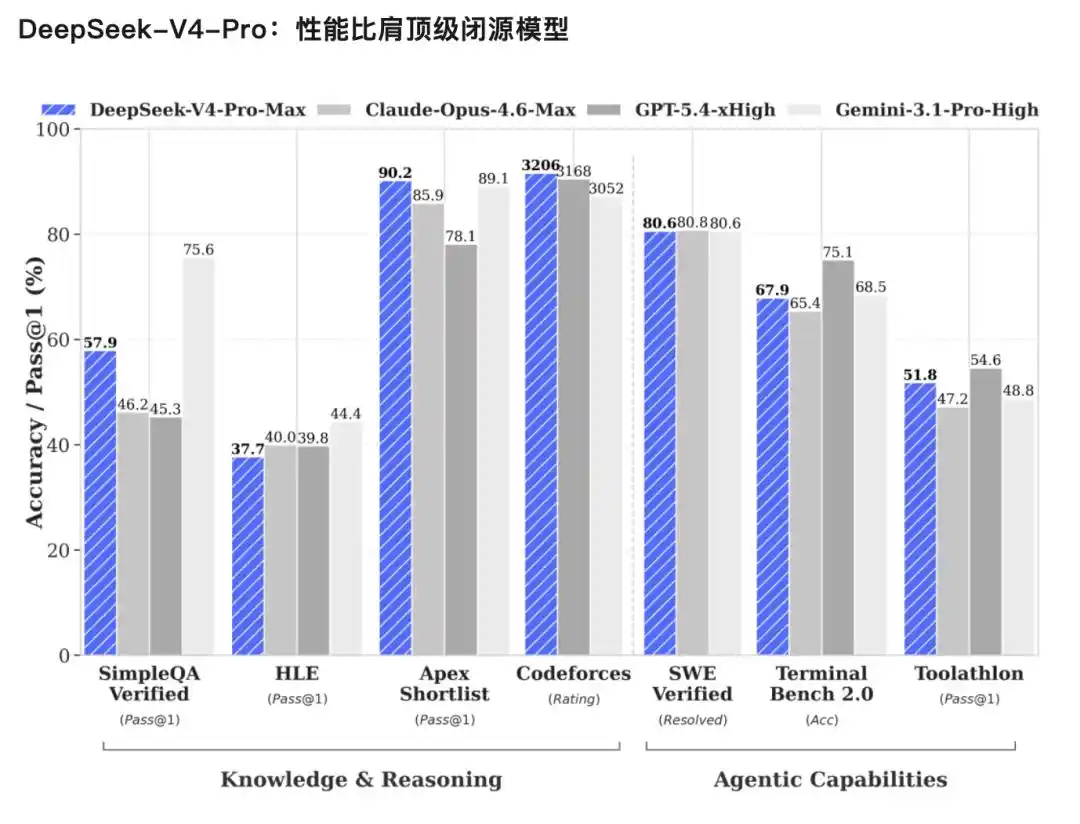
Capacités d'Agent considérablement améliorées : Dans l'évaluation Agentic Coding, V4-Pro a atteint le meilleur niveau actuel des modèles open source, et excelle également dans d'autres évaluations liées à l'Agent. En évaluation interne, en mode Agent Coding, l'expérience V4 est meilleure que Sonnet 4.5, la qualité de livraison est proche d'Opus 4.6 en mode non-réflexion, mais un écart subsiste avec le mode réflexion d'Opus 4.6.
Connaissances mondiales riches : DeepSeek-V4-Pro dans les évaluations de connaissances mondiales devance largement les autres modèles open source, juste légèrement inférieur au modèle propriétaire de pointe Gemini-Pro-3.1.
Performances de raisonnement de classe mondiale : Dans les évaluations de mathématiques, STEM et code compétitif, DeepSeek-V4-Pro surpasse tous les modèles open source actuellement évalués publiquement, obtenant des résultats excellents comparables aux modèles propriétaires de pointe mondiaux.
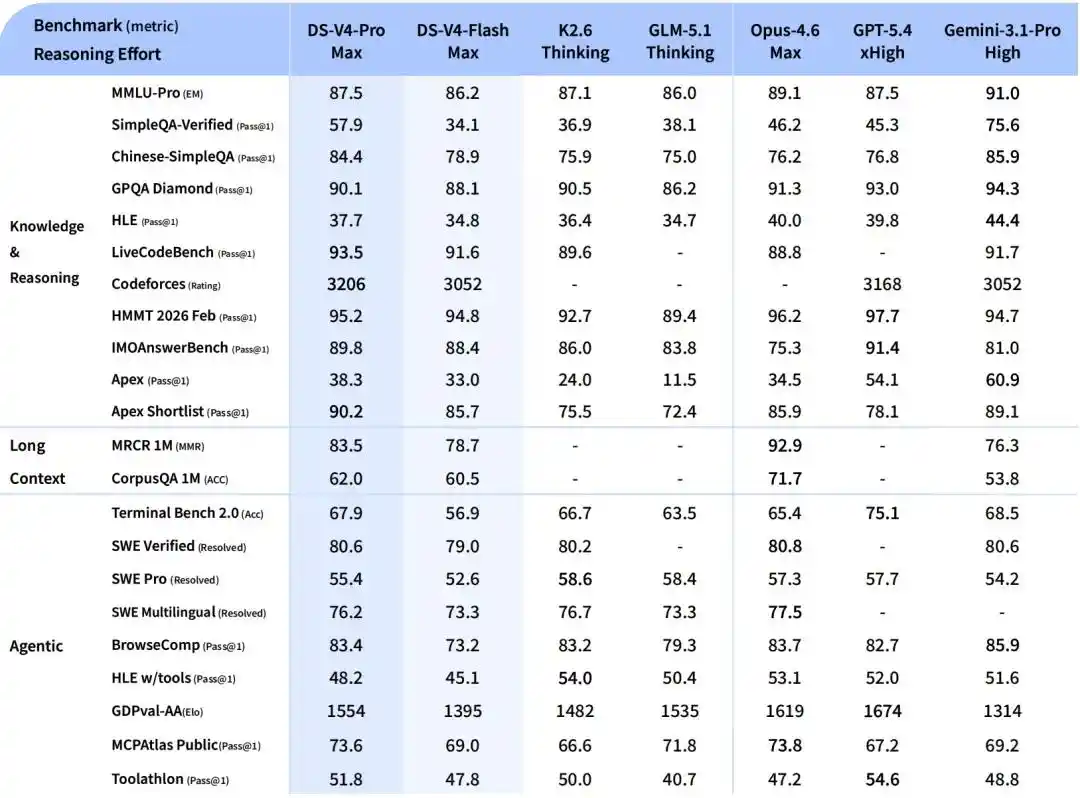
V4-Flash, version économique plus petite et plus rapide. Capacités de raisonnement proches de Pro, connaissances mondiales légèrement inférieures, mais paramètres et activation plus petits, API moins chère.
Pour les tâches d'Agent, DeepSeek-V4-Flash est à égalité avec DeepSeek-V4-Pro sur les tâches simples, mais un écart subsiste sur les tâches de haute difficulté.
Sur le test de lavage de voiture, V4 passe également rapidement.

Et dans le scénario biologique classique du « père désespéré », DeepSeek-V4 n'a pas saisi du premier coup le point clé du daltonisme rouge-vert (selon les lois génétiques, si une femme est daltonienne rouge-vert, son père biologique l'est nécessairement aussi).

Le contexte d'un million devient standard
Il est à noter que, à partir d'aujourd'hui, le contexte 1M est standard pour tous les services officiels de DeepSeek.
Il y a un an, le contexte 1M était l'atout exclusif de Gemini ; tous les autres modèles propriétaires avaient soit 128K soit 200K ; côté open source, presque personne ne pouvait jouer à ce niveau.
DeepSeek a directement fait passer le contexte d'un million d'une « fonctionnalité haut de gamme » à une « commodité de base ».
Et en open source. Comment ils ont fait, le communiqué de presse donne directement la réponse —
V4 a créé un nouveau mécanisme d'attention, avec compression au niveau du token, combiné avec l'attention sparse DSA. Comparé aux méthodes traditionnelles, les besoins en calcul et mémoire sont considérablement réduits.
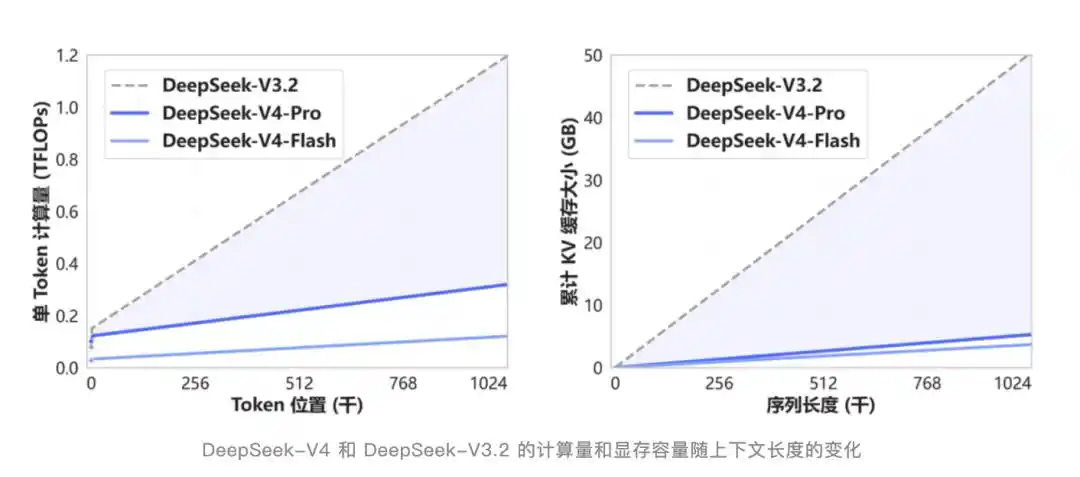
DSA n'est pas nouveau. Introduit il y a six mois lors de la mise à jour V3.2-Exp, l'attention extérieure était faible à l'époque, car les scores étaient presque identiques à V3.1-Terminus, semblant être une version intermédiaire sans grand contenu.
En y regardant maintenant, c'était les fondations de V4.
Optimisation spéciale des capacités d'Agent
Côté Agent, V4 a été adapté et optimisé pour les produits Agent mainstream comme Claude Code, OpenClaw, OpenCode, CodeBuddy, les tâches de code et de génération de documents sont améliorées.
Le communiqué inclut également un exemple de page interne de PPT générée par V4-Pro sous un framework Agent.

Prix de l'API
Côté API, V4-Pro et V4-Flash sont mis en ligne simultanément, supportant deux interfaces : OpenAI ChatCompletions et Anthropic.
base_url inchangé, il suffit de changer le paramètre model en deepseek-v4-pro ou deepseek-v4-flash pour l'appel.
Les deux versions ont un contexte maximum de 1M, supportent simultanément le mode non-réflexion et le mode réflexion. En mode réflexion, l'intensité peut être ajustée via le paramètre reasoning_effort, deux niveaux high et max. L'officiel recommande de passer directement à max pour les scénarios Agent complexes.
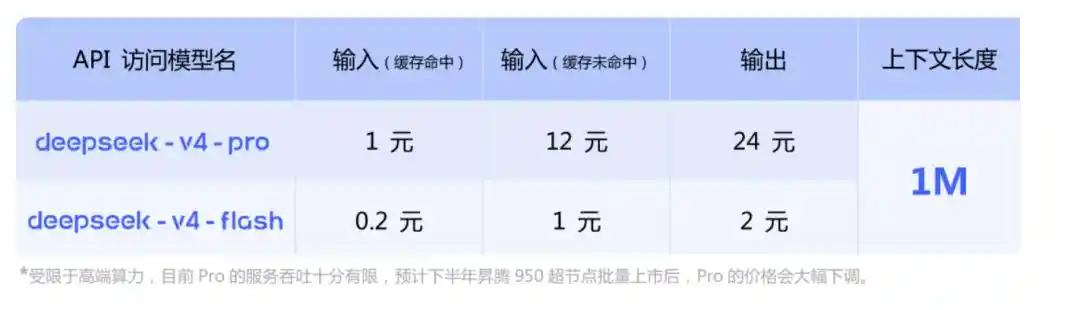
Il y a un point important — support de la puissance de calcul Huawei au second semestre.
De plus, les anciens noms de modèles seront retirés.
deepseek-chat et deepseek-reasoner seront désactivés dans trois mois (24 juillet 2026), actuellement ces noms pointent respectivement vers les modes non-réflexion et réflexion de V4-Flash.
Impact faible pour les développeurs individuels, changement d'un paramètre model. Les entreprises en environnement de production doivent migrer durant ces trois mois.
One more thing
À la fin du communiqué, DeepSeek cite lui-même une phrase.
« Ne pas être séduit par la louange, ne pas être effrayé par la calomnie, avancer selon sa voie, se rectifier avec droiture. »
Ceci vient de Xunzi « Contre les douze maîtres ». Littéralement, ne pas être tenté par les éloges, ne pas être effrayé par les diffamation, avancer selon la voie que l'on croit, se corriger.
Dans le contexte d'aujourd'hui, c'est intéressant.
Ces six derniers mois, des rumeurs sur quand V4 sortirait, s'il était retardé, s'il était déjà dépassé par d'autres, si Claude avait déjà réussi à distiller les données, etc., ont circulé plusieurs fois dans les cercles d'IA chinois et anglais. Début d'année, certains affirmaient même avec conviction que V4 sortirait avant le Nouvel An chinois, résultat attendu fin avril.
Ils n'ont jamais répondu.
Puis un vendredi après-midi, ils sortent V4, open source simultané, mise en ligne du site et de l'app, mise à jour de l'API, et écrivent même dans le communiqué que les employés internes ont déjà abandonné Claude.
Pas de roadmap, pas de live, pas d'interview.
Ces quatre mots « avancer selon sa voie » semblent être un slogan. Mais si vous regardez le chemin des six derniers mois : la version Exp « sans grand亮点 » de V3.2, le sparse attention DSA qui a préparé V4 pendant six mois, le contexte 1M passé d'atout à standard.
DeepSeek l'a déjà fait.
Liens open source du modèle DeepSeek-V4 :
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
Rapport technique DeepSeek-V4 : https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
Cet article provient du compte public WeChat « Quantum Bit », auteur : Quantum Bit





