Auteur : Daniel Barabander
Compilation : Deep Tide TechFlow
Introduction de Deep Tide : Il y a trois ans, Cursor était un plugin VS Code fonctionnant sur l'API d'OpenAI. Aujourd'hui, il a publié son propre modèle, surpassant Claude Opus 4.6 sur des benchmarks clés, à un dixième du prix.
Cet article, partant de ce cas, répond systématiquement à la question stratégique la plus importante sur Internet : quand faut-il ouvrir une API, et quand faut-il la fermer ? La conclusion est un avertissement pour tous ceux qui font des plateformes.
Article complet :
Co-écrit avec Elijah Fox(@PossibltyResult).
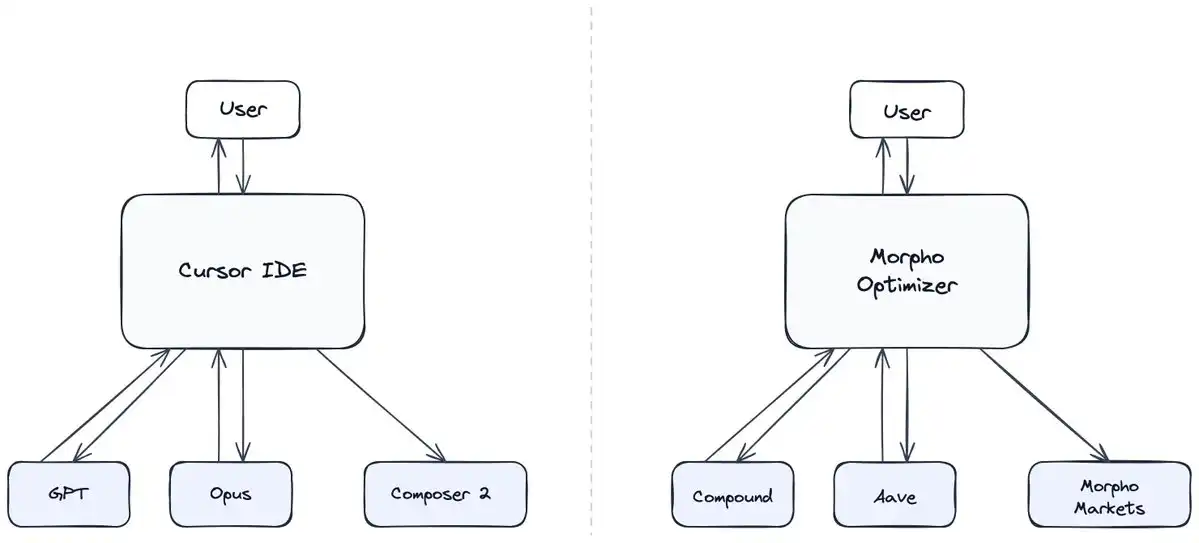
Début mars, Cursor a publié Composer 2 — un modèle propriétaire de programmation construit sur un modèle open source de base, surpassant Claude Opus 4.6 sur des benchmarks clés, pour un dixième du prix. Il y a trois ans, Cursor était une branche de VS Code fonctionnant entièrement sur l'API d'OpenAI.
Le parcours de Cursor, passant d'un client dépendant à un véritable concurrent, est le reflet de la question stratégique la plus importante sur Internet : quand une entreprise devrait-elle ouvrir ses capacités via une API, et quand devrait-elle rester fermée ?
Nous avons développé un cadre pour répondre à cette question, qui dépend de deux choses. Premièrement : l'ouverture de l'API érode-t-elle votre fossé concurrentiel ? Si oui : pouvez-vous trouver un fossé concurrentiel ailleurs ?
Chaque fois qu'une entreprise ouvre sa propriété intellectuelle au public via une API, elle risque d'éroder son fossé concurrentiel par agrégation de la demande. En bref : les concurrents peuvent utiliser cette propriété intellectuelle pour amorcer les premières étapes de leur propre produit, et une fois qu'ils ont accumulé suffisamment de demande, ils peuvent couper l'API par intégration verticale. C'est ce qu'a fait Netflix : d'abord licencier du contenu, puis, une fois une base d'utilisateurs suffisamment grande pour amortir les coûts fixes énormes, produire *House of Cards*.
Mais le vrai danger est lorsque la sortie de l'API peut servir directement d'entrée, améliorant de manière compound la qualité du produit concurrent. C'est un double coup dur, car le concurrent peut à la fois utiliser l'API pour amorcer et agréger la demande, et améliorer directement son propre processus de production. C'est exactement ce qui se passe dans le domaine de l'IA. Bien qu'OpenAI et Anthropic interdisent explicitement dans leurs contrats aux entreprises utilisant leur API d'utiliser les sorties pour entraîner des modèles concurrents, ils ne peuvent pas empêcher des entreprises comme Cursor d'utiliser des modèles de pointe pour amorcer les flux de travail nécessaires à la collecte de données produit propriétaires et d'améliorer leurs propres modèles au fil du temps.
C'est apparemment exactement ce qui s'est passé derrière Composer 2. Cursor a utilisé des modèles de base comme Claude et GPT pour agréger suffisamment de demande, atteignant un revenu annualisé d'environ 2 milliards de dollars, puis a construit un modèle de programmation de pointe en utilisant le modèle de base open source Kimi K2.5, complété par des données de pré-entraînement continu et d'apprentissage par renforcement provenant de son IDE.
Lorsque cette dynamique sortie/entrée existe, le fournisseur d'API n'a que deux choix : soit fermer l'API pour stopper l'hémorragie, soit la garder ouverte et trouver des actifs complémentaires où exercer son fossé concurrentiel.
Twitter est un cas classique ayant pris la première voie. Il était initialement connu pour son API généreuse et gratuitement accessible — à son apogée, les développeurs pouvaient extraire gratuitement 500 000 tweets par mois. Mais Twitter a fermé la plupart des accès parce que l'API divulguait son fossé concurrentiel : le graphe social propriétaire. Aujourd'hui, l'API est pratiquement fermée : l'accès est strictement limité en débit, cher à une échelle significative, et structurellement, pour construire un produit sérieux, il faut passer par des intégrations B2B strictement contrôlées.
La deuxième voie est de garder l'API ouverte et de la compléter avec une autre source de pouvoir. Aucune industrie ne comprend cela mieux que la crypto — les API y sont obligatoirement ouvertes, et la seule façon d'y survivre est de trouver un fossé concurrentiel ailleurs.
Le protocole de prêt Morpho en est un cas représentatif. Le protocole est né en s'intégrant aux API ouvertes d'Aave et Compound et en construisant un produit optimiseur par-dessus. Ensuite, il a utilisé la sortie de ces protocoles — leur liquidité agrégée — comme entrée pour amorcer sa propre plateforme. On voit ainsi que les chemins de Cursor et Morpho pour utiliser les API afin de construire des produits concurrents sont identiques.
Mais la dynamique vraiment intéressante est ce que Morpho a fait ensuite. Comme Morpho est lui-même une API ouverte, il devait trouver un fossé concurrentiel pour compenser le manque de coûts de changement. Il a donc décidé de rendre le protocole aussi agrégeable que possible, et a plutôt construit son fossé concurrentiel par d'autres moyens — comme l'effet Lindy, et les effets de réseau provenant de la liquidité profonde générée par une multitude de prêteurs et d'emprunteurs.
En projetant ce cadre vers l'avant, nous pouvons faire une prédiction : avec le temps, les entreprises de modèles de base choisiront très probablement la première voie, restreignant progressivement l'accès API à leurs modèles les plus avancés.
Pour croire en la deuxième voie, il faut penser que des modèles comme Opus et GPT sont déjà suffisamment puissants et fiables pour rester ouverts, permettant à des modèles concurrents d'utiliser leur sortie comme entrée, mais que les tiers ne partiront tout de même pas. Cela signifie que les entreprises de modèles parient sur d'autres sources de pouvoir : l'effet Lindy (s'ils pensent que les utilisateurs ne veulent pas construire la confiance envers un nouveau modèle), les effets de réseau des développeurs (s'ils pensent que les utilisateurs construiront un écosystème étroitement dépendant de l'ouverture de leur API), ou les économies d'échelle (s'ils pensent que maximiser le volume d'appels API leur permettra d'amortir les coûts fixes d'entraînement des modèles de pointe).
Mais les preuves actuelles pointent dans la direction opposée. La dynamique du "modèle le plus chaud du mois" reste forte, les utilisateurs n'hésitent pas à migrer vers le meilleur modèle du moment — nous l'avons revu lors du récent pic d'utilisation de Claude après la sortie d'Opus 4.5. Au niveau des modèles, les effets de réseau des développeurs ne sont pas encore évidents non plus — l'interopérabilité entre les API augmente plutôt qu'elle ne diminue, l'écosystème d'outils périphériques lutte activement contre le verrouillage, rendant délibérément le changement de fournisseur facile. Et pour l'instant, les économies d'échelle en phase d'entraînement sont insuffisantes comme fossé concurrentiel, car les techniques de distillation permettent aux concurrents d'entraîner des modèles aux performances équivalentes à un coût bien moindre. Sans source de pouvoir alternative, les entreprises d'IA de base vont très probablement réserver l'accès limité aux amateurs, et se concentrer sur les déploiements B2B avec un contrôle et une surveillance stricts de l'utilisation. De plus en plus, le choix gagnant sera de refuser de jouer à ce jeu.
C'est un résultat inquiétant, car l'explosion actuelle des produits d'IA grand public est construite sur ces fournisseurs de modèles. Cela ouvre également la porte à un positionnement inverse : si les grands laboratoires restreignent de plus en plus l'accès, il y a de la valeur à prendre pour les concurrents choisissant un fossé concurrentiel plus faible mais faisant une promesse forte de rester continuellement ouvert.
Remerciements à @systematicls(@openforage) et @AlexanderLong(@Pluralis) pour leurs retours réfléchis sur cet article.







